- 🍨 本文为 🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者: K同学啊
一、前置知识
1、知识总结
本实验旨在探究**不同优化器(Adam vs SGD)**在相同模型架构和数据集上的表现差异,以理解优化器选择对模型训练过程和最终性能的影响。
1.1.实验设置
|------|-------------------------------------------------------------------------|
| 项目 | 内容 |
| 数据集 | 17类好莱坞明星人脸图片,共1800张(训练1440张,验证360张) |
| 模型架构 | VGG16(ImageNet预训练)+ 全局平均池化 + Dense(170) + BN + Dropout(0.5) + Dense(17) |
| 数据集 | 17类好莱坞明星人脸图片,共1800张(训练1440张,验证360张) |
| 训练轮次 | 50 Epochs |
| 冻结层 | VGG16全部卷积层冻结(仅训练顶层分类器) |
| 优化器 | model1: Adam(默认参数),model2: SGD(默认参数) |
1.2.关键实验结果
Adam 优化器:
-
训练集:最终准确率约 96.5%,Loss 降至 0.129
-
验证集:最佳准确率约 59.7%,但波动很大(44%~59%之间震荡)
-
明显过拟合:训练集和验证集之间存在约 37% 的准确率差距
SGD 优化器:
-
训练集:最终准确率约 81.1%,Loss 降至 0.594
-
验证集:最佳准确率约 57.2%,波动相对较小
-
过拟合较轻:训练集与验证集差距约 24%
1.3. 核心结论
-
收敛速度差异显著:Adam 收敛极快,约 10 个 epoch 训练准确率就超过 75%;SGD 在 50 个 epoch 后训练准确率仍在 81% 左右,收敛缓慢。
-
过拟合程度不同:Adam 由于收敛过快,导致严重过拟合(验证 Loss 从 epoch 10 后持续上升,从 ~1.4 飙升至 ~2.7);SGD 过拟合相对温和,验证 Loss 更稳定。
-
验证集最终性能接近:尽管训练集表现差距很大,两者在验证集上的最佳准确率都在 57%~60% 左右,说明 Adam 的高训练准确率并未转化为更好的泛化能力。
-
启示:
-
Adam 不一定是"万能选择",在本实验中其快速收敛反而加剧了过拟合
-
SGD 虽然收敛慢,但泛化性能并不逊色
-
对于小数据集+预训练模型的迁移学习场景,可能需要配合学习率调度、早停(Early Stopping)、数据增强等策略来进一步提升效果
-
SGD 配合动量(momentum)或学习率衰减策略可能表现更好,值得进一步实验
二、代码实现
1、准备工作
1.1.设置GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
print(gpus)
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]1.2.导入数据
import os,PIL,pathlib
import matplotlib.pyplot as plt
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers,models
# 查看当前工作路径(确认路径是否正确)
print("当前工作路径:", os.getcwd())
# 定义数据目录(建议用绝对路径更稳妥,相对路径依赖当前工作路径)
data_dir = './data/day11/'
data_dir = pathlib.Path(data_dir)
# 获取数据目录下的所有子路径(文件夹或文件)
data_paths = list(data_dir.glob('*'))
# 提取每个子路径的名称(即类别名,自动适配系统分隔符)
classeNames = [path.name for path in data_paths]
classeNames
当前工作路径: /root/autodl-tmp/TensorFlow2
['.DS_Store', 'Robert Downey Jr','Brad Pitt','Leonardo DiCaprio','Jennifer Lawrence','Tom Cruise','Hugh Jackman','Angelina Jolie','Johnny Depp','Tom Hanks','Denzel Washington','Kate Winslet','Scarlett Johansson','Will Smith','Natalie Portman','Nicole Kidman','Sandra Bullock','Megan Fox']1.3.查看数据
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:",image_count)
图片总数为: 18001.4.可视化图片
roses = list(data_dir.glob('Tom Hanks/*.jpg'))
PIL.Image.open(str(roses[0]))
2、数据预处理
2.1.加载数据
-
使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中
img_height = 336
img_width = 336
batch_size = 16train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)Found 1800 files belonging to 17 classes.
Using 1440 files for training.验证集
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)Found 1800 files belonging to 17 classes.
Using 360 files for validation.class_names = train_ds.class_names
print(class_names)['Angelina Jolie', 'Brad Pitt', 'Denzel Washington', 'Hugh Jackman', 'Jennifer Lawrence', 'Johnny Depp', 'Kate Winslet', 'Leonardo DiCaprio', 'Megan Fox', 'Natalie Portman', 'Nicole Kidman', 'Robert Downey Jr', 'Sandra Bullock', 'Scarlett Johansson', 'Tom Cruise', 'Tom Hanks', 'Will Smith']
2.2.检查数据
- Image_batch是形状的张量(16,336,336,3)。这是一批形状336x336x3的32张图片(最后一维指的是彩色通道RGB)。
-
Label_batch是形状(16,)的张量,这些标签对应32张图片
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break(16, 336, 336, 3)
(16,)
2.3.配置数据集
- shuffle() :打乱数据,关于此函数的详细介绍可以参考
- prefetch() :预取数据,加速运行
-
cache() :将数据集缓存到内存当中,加速运行
AUTOTUNE = tf.data.AUTOTUNE
def train_preprocessing(image,label):
return (image/255.0,label)
train_ds = (
train_ds.cache()
.shuffle(1000)
.map(train_preprocessing) # 这里可以设置预处理函数
.prefetch(buffer_size=AUTOTUNE)
)val_ds = (
val_ds.cache()
.shuffle(1000)
.map(train_preprocessing) # 这里可以设置预处理函数
.prefetch(buffer_size=AUTOTUNE)
)
2.4. 可视化数据
plt.figure(figsize=(10, 8)) # 图形的宽为10高为5
plt.suptitle("data show")
for images, labels in train_ds.take(1):
for i in range(15):
plt.subplot(4, 5, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# 显示图片
plt.imshow(images[i])
# 显示标签
plt.xlabel(class_names[labels[i]-1])
plt.show()
3、构建模型
from tensorflow.keras.layers import Dropout,Dense,BatchNormalization
from tensorflow.keras.models import Model
def create_model(optimizer='adam'):
# 加载预训练模型
vgg16_base_model = tf.keras.applications.vgg16.VGG16(weights='imagenet',
include_top=False,
input_shape=(img_width, img_height, 3),
pooling='avg')
for layer in vgg16_base_model.layers:
layer.trainable = False
X = vgg16_base_model.output
X = Dense(170, activation='relu')(X)
X = BatchNormalization()(X)
X = Dropout(0.5)(X)
output = Dense(len(class_names), activation='softmax')(X)
vgg16_model = Model(inputs=vgg16_base_model.input, outputs=output)
vgg16_model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return vgg16_model
model1 = create_model(optimizer=tf.keras.optimizers.Adam())
model2 = create_model(optimizer=tf.keras.optimizers.SGD())
model2.summary()
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg16/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
58889256/58889256 [==============================] - 12s 0us/step
Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 336, 336, 3)] 0
block1_conv1 (Conv2D) (None, 336, 336, 64) 1792
block1_conv2 (Conv2D) (None, 336, 336, 64) 36928
block1_pool (MaxPooling2D) (None, 168, 168, 64) 0
block2_conv1 (Conv2D) (None, 168, 168, 128) 73856
block2_conv2 (Conv2D) (None, 168, 168, 128) 147584
block2_pool (MaxPooling2D) (None, 84, 84, 128) 0
block3_conv1 (Conv2D) (None, 84, 84, 256) 295168
block3_conv2 (Conv2D) (None, 84, 84, 256) 590080
block3_conv3 (Conv2D) (None, 84, 84, 256) 590080
block3_pool (MaxPooling2D) (None, 42, 42, 256) 0
block4_conv1 (Conv2D) (None, 42, 42, 512) 1180160
block4_conv2 (Conv2D) (None, 42, 42, 512) 2359808
block4_conv3 (Conv2D) (None, 42, 42, 512) 2359808
block4_pool (MaxPooling2D) (None, 21, 21, 512) 0
block5_conv1 (Conv2D) (None, 21, 21, 512) 2359808
block5_conv2 (Conv2D) (None, 21, 21, 512) 2359808
block5_conv3 (Conv2D) (None, 21, 21, 512) 2359808
block5_pool (MaxPooling2D) (None, 10, 10, 512) 0
global_average_pooling2d_1 (None, 512) 0
(GlobalAveragePooling2D)
dense_2 (Dense) (None, 170) 87210
batch_normalization_1 (Batc (None, 170) 680
hNormalization)
dropout_1 (Dropout) (None, 170) 0
dense_3 (Dense) (None, 17) 2907
=================================================================
Total params: 14,805,485
Trainable params: 90,457
Non-trainable params: 14,715,028
_________________________________________________________________4、训练模型
NO_EPOCHS = 50
history_model1 = model1.fit(train_ds, epochs=NO_EPOCHS, verbose=1, validation_data=val_ds)
history_model2 = model2.fit(train_ds, epochs=NO_EPOCHS, verbose=1, validation_data=val_ds)
Epoch 1/50
90/90 [==============================] - 13s 74ms/step - loss: 2.9277 - accuracy: 0.1493 - val_loss: 2.6710 - val_accuracy: 0.1556
Epoch 2/50
90/90 [==============================] - 6s 66ms/step - loss: 2.1442 - accuracy: 0.3292 - val_loss: 2.4719 - val_accuracy: 0.1806
...
Epoch 49/50
90/90 [==============================] - 6s 66ms/step - loss: 0.1620 - accuracy: 0.9465 - val_loss: 2.5879 - val_accuracy: 0.5389
Epoch 50/50
90/90 [==============================] - 6s 66ms/step - loss: 0.1290 - accuracy: 0.9653 - val_loss: 2.1850 - val_accuracy: 0.5611
Epoch 1/50
90/90 [==============================] - 7s 70ms/step - loss: 2.9437 - accuracy: 0.1139 - val_loss: 2.7525 - val_accuracy: 0.1139
Epoch 2/50
90/90 [==============================] - 6s 66ms/step - loss: 2.5387 - accuracy: 0.2021 - val_loss: 2.6109 - val_accuracy: 0.1278
...
Epoch 49/50
90/90 [==============================] - 6s 66ms/step - loss: 0.5797 - accuracy: 0.8160 - val_loss: 1.4646 - val_accuracy: 0.5500
Epoch 50/50
90/90 [==============================] - 6s 66ms/step - loss: 0.5942 - accuracy: 0.8111 - val_loss: 1.3696 - val_accuracy: 0.54175、模型评估
5.1.Accuracy与Loss图
from matplotlib.ticker import MultipleLocator
plt.rcParams['savefig.dpi'] = 300 #图片像素
plt.rcParams['figure.dpi'] = 300 #分辨率
from datetime import datetime
current_time = datetime.now() # 获取当前时间
acc1 = history_model1.history['accuracy']
acc2 = history_model2.history['accuracy']
val_acc1 = history_model1.history['val_accuracy']
val_acc2 = history_model2.history['val_accuracy']
loss1 = history_model1.history['loss']
loss2 = history_model2.history['loss']
val_loss1 = history_model1.history['val_loss']
val_loss2 = history_model2.history['val_loss']
epochs_range = range(len(acc1))
plt.figure(figsize=(16, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc1, label='Training Accuracy-Adam')
plt.plot(epochs_range, acc2, label='Training Accuracy-SGD')
plt.plot(epochs_range, val_acc1, label='Validation Accuracy-Adam')
plt.plot(epochs_range, val_acc2, label='Validation Accuracy-SGD')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time) # 打卡请带上时间戳,否则代码截图无效
# 设置刻度间隔,x轴每1一个刻度
ax = plt.gca()
ax.xaxis.set_major_locator(MultipleLocator(1))
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss1, label='Training Loss-Adam')
plt.plot(epochs_range, loss2, label='Training Loss-SGD')
plt.plot(epochs_range, val_loss1, label='Validation Loss-Adam')
plt.plot(epochs_range, val_loss2, label='Validation Loss-SGD')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
# 设置刻度间隔,x轴每1一个刻度
ax = plt.gca()
ax.xaxis.set_major_locator(MultipleLocator(1))
plt.show()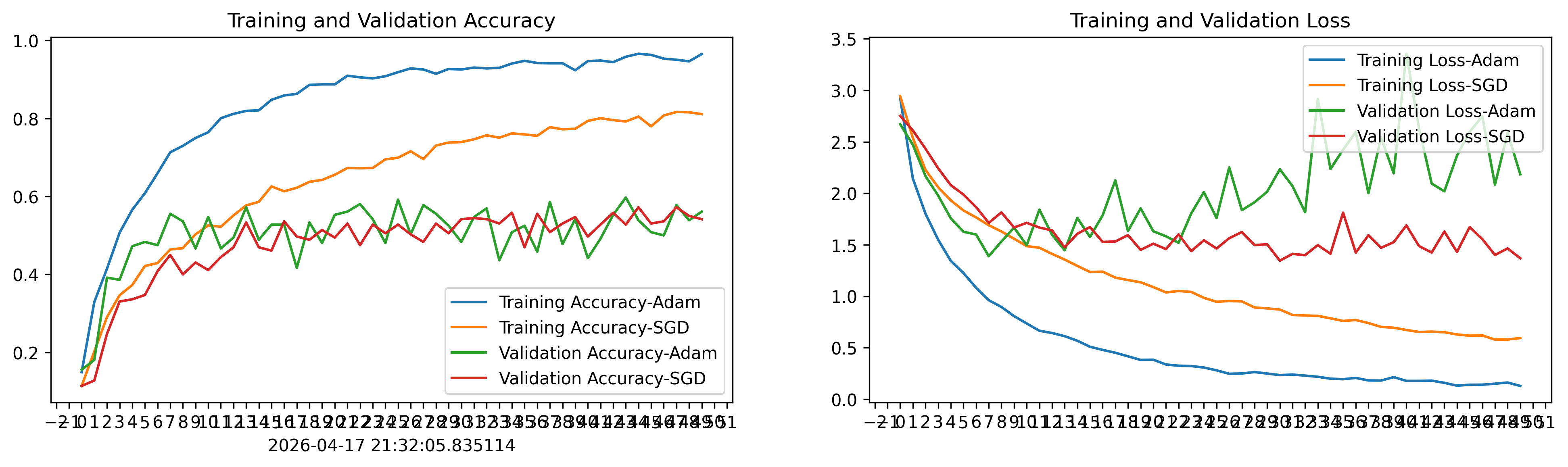
5.2.模型评估
def test_accuracy_report(model):
score = model.evaluate(val_ds, verbose=0)
print('Loss function: %s, accuracy:' % score[0], score[1])
test_accuracy_report(model2)
Loss function: 1.3696223497390747, accuracy: 0.5416666865348816