大家好,我是小编~
上一篇我简单介绍了AI的起源和一些基础认知,有朋友留言说:
"这些我都懂,我现在的问题是---AI为什么老是胡说?"
这个问题问得很实在,而且我敢肯定:
如果你在做AI项目,一定已经被它坑过
我自己在做AI知识库的时候,就遇到过这种情况:
明明文档里没有的内容,它能给你编一套完整方案
同一个问题,每次答案还不一样
有时候甚至"自信满满地错"
一开始我以为是模型不行,后来才发现:
问题根本不在模型,而在于你怎么用它
这篇我不讲概念,直接讲一个你必须搞懂的东西:
RAG
一、AI为什么会"胡说"?
什么是RAG,我们得首先了解大模型的本质是什么:
大模型本质不是"查资料",而是"生成文本"
你问它问题,它不是去数据库查答案,而是:
根据训练过的数据,"猜一个最像答案的话"
注意这里我说的是"猜",可能不准确,但好理解。
根据训练数据,预测"在当前上下文中最有可能出现的下一个词"(Next Token Prediction)
然而这种预测就带来一个很现实的问题,不管是公司还是个人,很多资料是不能在互联网上公开的:
-
它不知道你公司的接口文档
-
不知道你的业务逻辑
-
更不知道你的私有数据
那它怎么给你答案?
它只能"合理地编"
这就是我们常听到的:
幻觉(Hallucination)
而且越是表达能力强的模型:
越会编,而且编得越像真的
例如你的代码这样写
typescript
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
public class HallucinationDemo {
public static void main(String[] args) {
ChatLanguageModel model = OpenAiChatModel.builder()
.apiKey("YOUR_API_KEY")
.modelName("gpt-4o-mini")
.build();
String question = "我们公司内部接口 /api/internal/pay/v2 的调用流程是什么?";
String answer = model.generate(question);
System.out.println(answer);
}
}AI回答的有板有眼,语气非常自信,结构非常完整,看起来"完全正确"。
markdown
接口 /api/internal/pay/v2 的调用流程如下:
1. 用户鉴权(Token校验)
2. 参数校验(金额、订单号等)
3. 调用支付服务
4. 返回支付结果但是,很明显这不是我们要的答案,因为模型它本就不知道答案,但必须生成一个"像答案的东西"
它其实是在套模板:
"接口调用流程通常是这样"
然后拼一个"合理答案"
二、RAG到底在解决什么问题?
我们换个角度。
如果是你自己回答一个问题的话,你会怎么做?
比如有人问你:
"我们系统A的接口调用流程是什么?"
你的第一反应肯定不是"开始编",而是:
先去翻文档
而RAG做的事情,和你的反应一模一样:
让AI也"先查资料,再回答"
换句话说:
RAG = 给AI装一个"可搜索的知识库"
三、RAG其实很简单
RAG的架构图类似这样
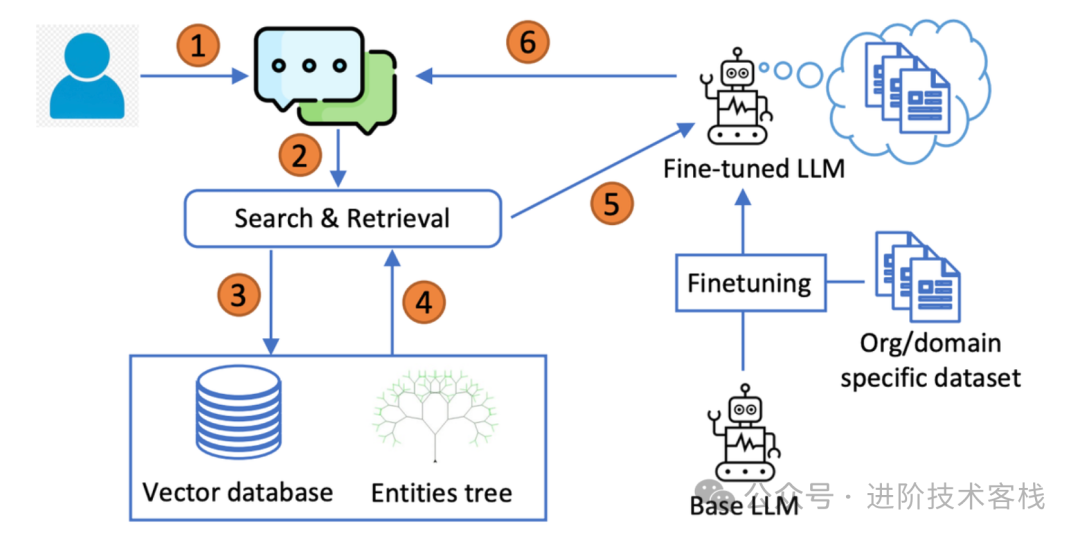
看起来很复杂,但其实你只要记住下面这个就够了:
-
第一步:把知识"存进去"
-
第二步:用户提问时,先去"找相关内容"
-
第三步:把"资料 + 问题"一起丢给AI
关于第一步,如何把知识存进去
你需要做三件事:
-
把文档切成一小段一小段(chunk)
-
把每一段转成向量(embedding)
-
存进数据库(向量库)
你可以把这个步骤理解为:
把"文字"变成"可计算的坐标"
那么我们为什么需要把文档切成一小段一小段的呢?
不切 chunk,检索就不准;检索不准,AI一定胡说
假设你有一份文档:
diff
《系统设计文档》
- 用户登录流程
- 支付流程
- 订单系统
- 消息队列
- 接口A说明
- 接口B说明你整篇直接丢进向量库。
然后用户问:
"接口A怎么调用?"
向量检索会发生什么?
它会拿"整篇文档"去做相似度计算
问题来了:
文档里包含一堆无关内容(登录、支付、订单...)
"接口A"只是其中一小部分
最终结果就是:
相似度被"稀释"了
结果:
要么查不到(分数不够)
要么查到一堆无关内容
为什么切 chunk 就好了?
我们把刚才那份文档拆开:
css
chunk1:用户登录流程
chunk2:支付流程
chunk3:接口A说明
chunk4:接口B说明再问同样的问题:
"接口A怎么调用?"
这次会发生什么?
检索系统会:
把问题转成向量
和每个 chunk 分别算相似度
结果:
chunk3(接口A)会被精准命中
本质变化:
从:
❌ "一整本书参与匹配"
变成:
✅ "一小段一小段精确匹配"
再说一个比较关键的点
大模型是有上下文长度限制的
比如:
4k / 8k / 128k token
如果你不切 chunk:
你可能会把一整篇文档塞进去
结果:
超长 → 直接截断
或者 → 成本爆炸
chunk的作用之一就是:
控制输入长度 + 提高信息密度
chunk本质是让向量搜索具备"段落级命中能力
第二步:用户提问时,先去"找相关内容"
用户问:
"接口A怎么调用?"
系统不会直接问AI,而是先做一件更重要的事:
去向量数据库里找"最像这个问题的几段内容"
cs
EmbeddingStore<TextSegment> store = PgVectorEmbeddingStore.builder()
.datasource(getDataSource())
.table("knowledge")
.dimension(1536)
.build();
EmbeddingModel embeddingModel = getEmbeddingModel();
ContentRetriever retriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)
.embeddingModel(embeddingModel)
.maxResults(3)
.minScore(0.7)
.build();
String question = "接口A怎么调用?";
List<Content> contents = retriever.retrieve(question);
System.out.println("==== 检索结果 ====");
for (Content content : contents) {
System.out.println(content.textSegment().text());
System.out.println("------------------");
}第三步:把"资料 + 问题"一起丢给AI
python
String question = "接口A怎么调用?";
String context = contents.stream()
.map(Content::textSegment)
.map(segment -> segment.text())
.reduce("", (a, b) -> a + "\n" + b);
String prompt = String.format("""
你是企业内部AI助手,请严格根据"资料"回答问题。
如果资料中没有相关信息,请回答:"无法确定",不要编造。
===== 资料 =====
%s
===== 问题 =====
%s
===== 输出要求 =====
- 只基于资料回答
- 不允许编造
- 不确定就说无法确定
""", context, question);
ChatLanguageModel model = OpenAiChatModel.builder()
.apiKey("YOUR_API_KEY")
.modelName("gpt-4o-mini")
.build();
String answer = model.generate(prompt);
System.out.println("==== AI回答 ====");
System.out.println(answer);
}
}这一步非常关键。
最终给模型的,不是:
❌ "请回答这个问题"
而是:
✅ "基于以下资料回答,不要乱编"
你可以理解为:
👉你在"喂答案范围",而不是让它自由发挥
四、用Java搭一个最小可用Demo
不讲虚的,直接上代码。
我这边用的是:
-
Spring Boot
-
LangChain4j
-
PostgreSQL + pgvector
-
Flyway
导入依赖
xml
<dependencies>
<!-- Spring Boot Starters -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
<!-- PostgreSQL -->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<!-- LangChain4j -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-pgvector</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<!-- Flyway -->
<dependency>
<groupId>org.flywaydb</groupId>
<artifactId>flyway-core</artifactId>
</dependency>
<!-- Lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- Test -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>初始化聊天大模型及向量数据操作相关的配置
typescript
@Bean
public ChatLanguageModel chatLanguageModel() {
return OpenAiChatModel.builder()
.baseUrl(openaiUrl)
.apiKey(openaiApiKey)
.modelName(modelName)
.build();
}
@Bean
public EmbeddingStore<TextSegment> embeddingStore() {
return PgVectorEmbeddingStore.builder()
.host("localhost")
.port(5432)
.database("ai_rag_db")
.user("postgres")
.password("123456")
.table("knowledge")
.dimension(1536)
.createTable(false)// 禁用自动创建,使用 Flyway 管理
.build();
}
@Bean
public EmbeddingModel embeddingModel() {
return OpenAiEmbeddingModel.builder()
.baseUrl(openaiUrl)
.apiKey(openaiApiKey)
.modelName("text-embedding-3-small")
.build();
}
@Bean
public EmbeddingStoreContentRetriever contentRetriever(
final EmbeddingStore embeddingStore,
final EmbeddingModel embeddingModel) {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(3)
.minScore(0.7)
.build();
}Flyway配置,启动项目自动运行数据库脚本
typescript
@Configuration
public class FlywayConfig {
@Bean(initMethod = "migrate")
@DependsOn("dataSource")
public Flyway flyway(DataSource dataSource) {
return Flyway.configure()
.dataSource(dataSource)
.baselineOnMigrate(true)
.baselineVersion("1")
.locations("classpath:db/migration")
.outOfOrder(false)
.validateOnMigrate(true)
.cleanDisabled(true)
.load();
}
@Bean
public FlywayMigrationInitializer flywayInitializer(Flyway flyway) {
return new FlywayMigrationInitializer(flyway);
}
}RagController,负责聊天和文档的增删改查
typescript
@Slf4j
@RestController
@RequestMapping("/api/rag")
@RequiredArgsConstructor
public class RagController {
private final RagService ragService;
@PostMapping("/ask")
public ResponseEntity<RagResponse> askQuestion(@RequestBody RagRequest request) {
try {
String answer = ragService.askQuestion(request.question());
return ResponseEntity.ok(new RagResponse(answer, true));
} catch (Exception e) {
log.error("Error processing question: {}", request.question(), e);
return ResponseEntity.ok(new RagResponse("抱歉,处理您的问题时出现了错误。", false));
}
}
@PostMapping("/documents")
public ResponseEntity<String> uploadDocument(@RequestParam("file") MultipartFile file) {
try {
ragService.ingestDocument(file);
return ResponseEntity.ok("文档上传并处理成功");
} catch (Exception e) {
log.error("Error uploading document", e);
return ResponseEntity.badRequest().body("文档上传失败: " + e.getMessage());
}
}
@GetMapping("/documents")
public ResponseEntity<List<DocumentEntity>> getAllDocuments() {
List<DocumentEntity> documents = ragService.getAllDocuments();
return ResponseEntity.ok(documents);
}
@DeleteMapping("/documents/{id}")
public ResponseEntity<String> deleteDocument(@PathVariable Long id) {
try {
ragService.deleteDocument(id);
return ResponseEntity.ok("文档删除成功");
} catch (Exception e) {
return ResponseEntity.badRequest().body("文档删除失败");
}
}
// Request/Response DTOs
public record RagRequest(String question) {}
public record RagResponse(String answer, boolean success) {}
}Service处理和AI及数据库相关的操作
java
@Slf4j
@Service
@RequiredArgsConstructor
public class RagService {
private final ChatLanguageModel chatLanguageModel;
private final EmbeddingModel embeddingModel;
private final EmbeddingStore<TextSegment> embeddingStore;
private final EmbeddingStoreContentRetriever contentRetriever;
private final DocumentRepository documentRepository;
private static final PromptTemplate PROMPT_TEMPLATE = PromptTemplate.from("""
你是企业内部AI助手,负责基于提供的资料回答问题。
【核心规则】
1. 只能使用"资料"中的信息回答
2. 严禁使用任何外部知识或常识补充
3. 如果资料中没有明确答案,不要编造
【无法确定时的要求】
当资料无法回答问题时,请从以下表达中任选一种,自然回答:
- 无法确定
- 资料中未提及该信息
- 当前资料无法提供该问题的答案
- 未在提供的资料中找到相关内容
⚠️ 注意:
- 不要重复使用同一句话
- 不要解释原因(例如"因为资料不足"这种可以,但不要长篇解释)
- 保持简洁
【回答要求】
1. 回答简洁、直接
2. 优先使用资料原文
3. 不输出无关内容
===== 资料 =====
{{context}}
===== 问题 =====
{{question}}
===== 输出 =====
直接输出答案
""");
public String askQuestion(String question) {
try {
// 1. 检索相关内容
List<Content> contents = contentRetriever.retrieve(Query.from(question));
// 2. 构建上下文
String context = contents.stream()
.map(Content::textSegment)
.map(TextSegment::text)
.collect(Collectors.joining("\n"));
// 3. 构造提示词
final String prompt = PROMPT_TEMPLATE.apply(
java.util.Map.of(
"context", context,
"question", question
)
).text();
// 4. 调用大模型
final AiMessage response = AiMessage.from(chatLanguageModel.generate(prompt));
return response.text();
} catch (Exception e) {
log.error("Error processing question: {}", question, e);
return "抱歉,处理您的问题时出现了错误,请稍后重试。";
}
}
public void ingestDocument(MultipartFile file) {
try {
String content = new String(file.getBytes());
// 保存文档到数据库
DocumentEntity documentEntity = new DocumentEntity();
documentEntity.setContent(content);
documentEntity.setFileName(file.getOriginalFilename());
documentEntity.setFileType(file.getContentType());
documentEntity.setCreatedAt(LocalDateTime.now());
documentRepository.save(documentEntity);
// 处理文档用于向量存储
Document document = Document.from(content);
// 分割文档
List<TextSegment> segments = DocumentSplitters.recursive(1000, 200)
.split(document);
// 生成嵌入向量并存储
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
for (int i = 0; i < segments.size(); i++) {
embeddingStore.add(embeddings.get(i), segments.get(i));
}
log.info("Document ingested successfully: {}", file.getOriginalFilename());
} catch (Exception e) {
log.error("Error ingesting document: {}", file.getOriginalFilename(), e);
throw new RuntimeException("Failed to ingest document", e);
}
}
public List<DocumentEntity> getAllDocuments() {
return documentRepository.findAll();
}
public void deleteDocument(Long id) {
documentRepository.deleteById(id);
}
}Springboot的配置文件
bash
server:
port: 8080
spring:
application:
name: ai-rag
datasource:
url: jdbc:postgresql://localhost:5432/ai_rag_db
username: postgres
password: 123456
driver-class-name: org.postgresql.Driver
jpa:
hibernate:
ddl-auto: validate
show-sql: true
properties:
hibernate:
dialect: org.hibernate.dialect.PostgreSQLDialect
format_sql: true
flyway:
enabled: true
baseline-on-migrate: true
baseline-version: 1
locations: classpath:db/migration
out-of-order: false
validate-on-migrate: true
clean-disabled: true
# 与 LangChain4j 配置保持一致
url: ${spring.datasource.url}
user: ${spring.datasource.username}
password: ${spring.datasource.password}
# OpenAI Configuration
openai:
api-key: ${OPENAI_API_KEY:sk-xxx}
model-name: gpt-3.5-turbo
url: https://api.url五、演示
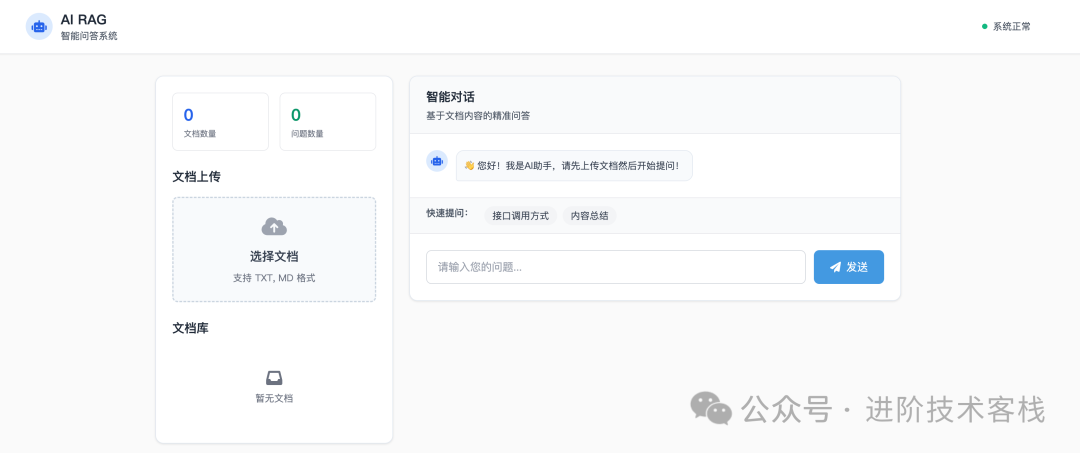
当我不上传任何文档的时候
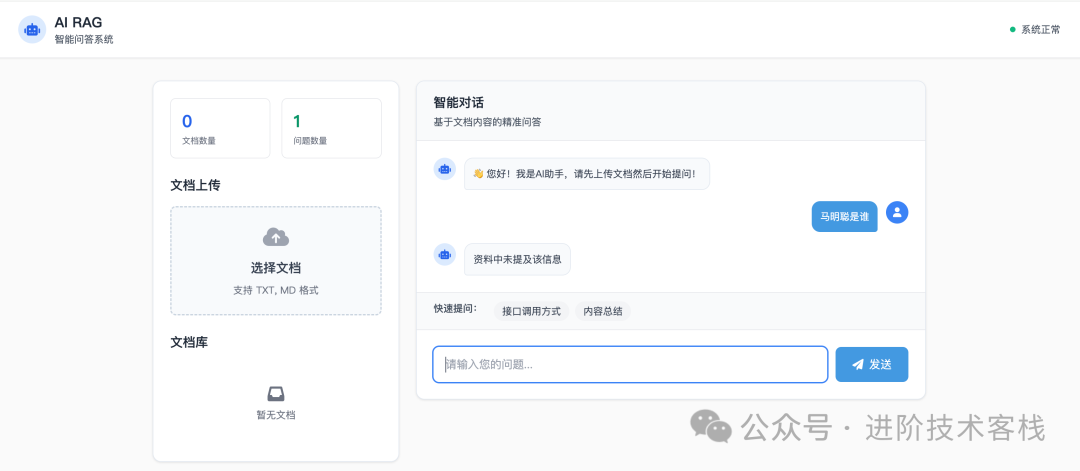
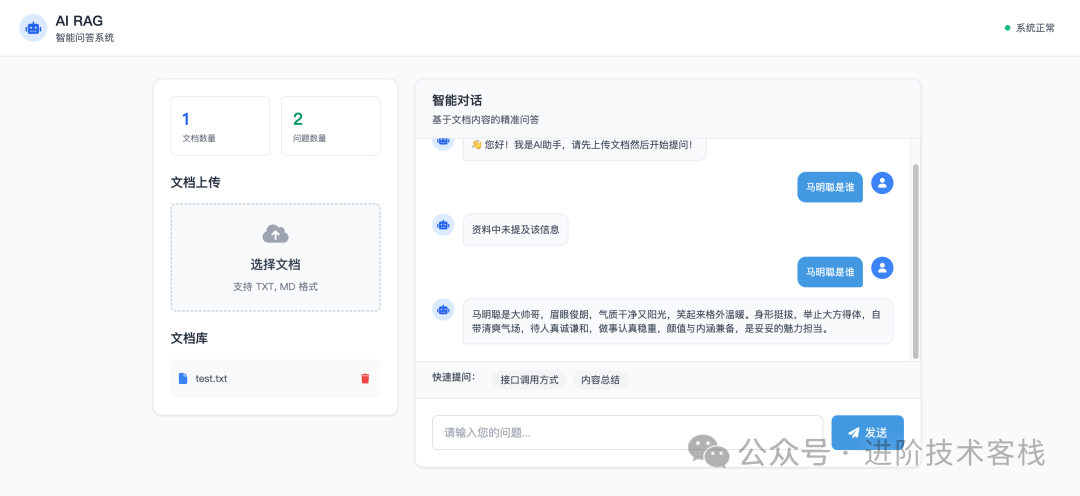
我上传一个文档,里面描述了马明聪是谁
六、我踩过的几个坑
这部分你一定会遇到。
❗chunk切分不合理
一开始我直接按整段文档丢进去,结果就是:
👉 查出来的内容完全不相关
后来改成:
200~500字一段,效果明显提升
❗相似度阈值乱设
.minScore(0.7)
这个值没有标准答案,但你要知道:
-
太高 → 查不到内容
-
太低 → 垃圾内容混进来
👉 最好的办法:自己打印日志调试
❗以为用了RAG就不会胡说
这是一个大坑。
现实是:
👉RAG只能减少胡说,不会消灭
如果你:
检索不准
prompt没约束
数据本身有问题
那AI照样乱来。
❗忽略metadata过滤
比如你有:
多个系统
多个版本
但你不加过滤条件:
AI会把A系统的答案用在B系统上
七、你现在应该有一个新认知
很多人以为:
做AI应用 = 调一个大模型API
但真实情况是:
模型只占20%,剩下80%是工程问题
包括:
-
数据怎么处理
-
检索怎么做
-
prompt怎么设计
你只记住一句话:
RAG不是技术名词,而是一种"让AI不胡说的工程手段"