本文基于官方文档:https://swift.readthedocs.io/zh-cn/latest/Customization/Custom-dataset.html
结合医疗对话数据集实战,手把手教你正确配置
dataset_info.json,一次跑通不报错。
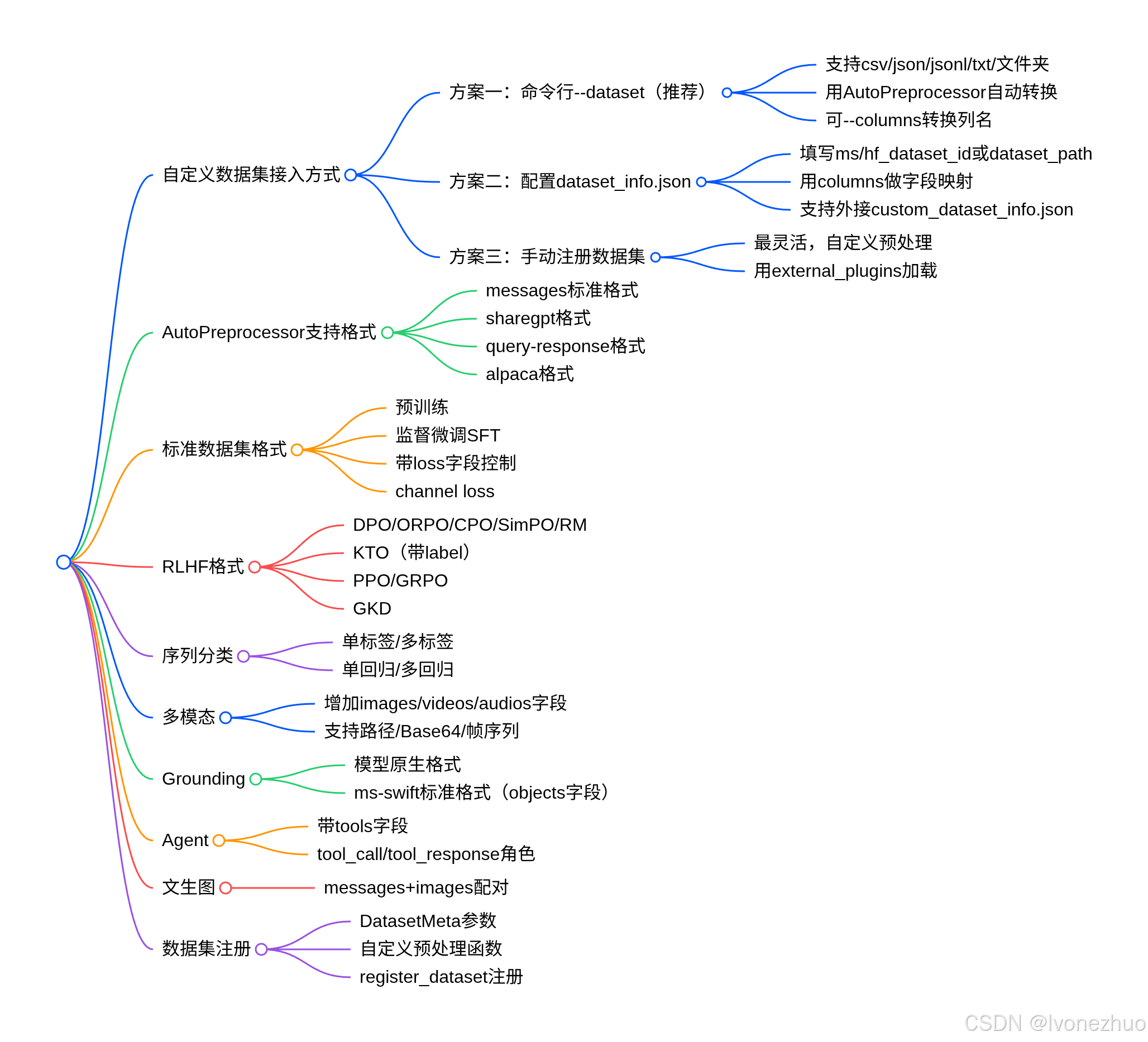
一、前言:MS-Swift 数据集为什么要这么配?
MS-Swift 是魔搭 ModelScope 开源的大模型轻量化微调框架,支持几乎所有常见对话/指令格式 ,但它有一套内部标准格式 ,所有外部数据集最终都会被 AutoPreprocessor 自动对齐到这套标准。
你只需要做两件事:
- 确保你的 JSON/JSONL 结构合法
- 在
dataset_info.json里做字段映射
本文会覆盖:
- 3 种数据集接入方式
- 4 类自动兼容的数据格式
- messages / sharegpt / alpaca / query-response 格式详解
- 医疗多轮对话数据集实战配置
- 你自己的两份数据集 正确 dataset_info 写法
二、MS-Swift 支持的数据集格式(核心必看)
Swift 内置自动预处理,支持以下 4 大类格式,不需要写代码即可加载。
1. Standard Messages 格式(官方最推荐)
json
{
"messages": [
{"role": "system", "content": "你是医疗助手"},
{"role": "user", "content": "足部骨折恢复要注意什么"},
{"role": "assistant", "content": "需要注意休息..."}
]
}2. ShareGPT / Multi-turn Conversation 格式
和你数据集1完全一致:
json
{
"conversation": [
{"role": "user", "content": "..."},
{"role": "assistant", "content": "..."}
]
}3. Alpaca 格式(指令微调)
和你数据集2完全一致:
json
{
"instruction": "你是谁?",
"input": "",
"output": "我是医疗助手..."
}4. Query-Response 格式(单轮问答)
json
{
"query": "颈椎病术后怎么睡觉?",
"response": "仰卧可以不用枕头...",
"system": "...",
"history": []
}三、自定义数据集的 3 种接入方式
方式1:命令行直接指定(最简单)
bash
--dataset data.json支持:json / jsonl / csv / txt / 文件夹
方式2:使用 dataset_info.json(推荐,企业/多数据集常用)
- 统一管理多个数据集
- 支持字段映射
- 可混合训练
使用方法:
bash
--dataset_info dataset_info.json方式3:手动注册数据集(高级自定义)
适合复杂预处理、特殊格式,通过 register_dataset 实现。
四、字段映射规则(columns 怎么写?)
columns 的作用:
把你的 JSON 字段名 → 映射成 Swift 内部标准字段名
固定规则:
- messages 格式 →
"messages": "你的字段名" - alpaca 格式 →
"prompt": "instruction", "response": "output" - query-response →
"query": "用户问题字段", "response": "回答字段"
五、你的真实数据集 + 正确 dataset_info.json(实战)
你的数据集1:med-disc(医疗多轮对话)
结构:
json
{
"_id": "01-1704633",
"source": "meddial",
"conversation": [
{"role": "user", "content": "..."},
{"role": "assistant", "content": "..."}
]
}字段映射:
conversation → messages
你的数据集2:med-self-cog(模型身份认知)
结构:
json
{
"instruction":"你是谁?",
"output":"我是专业医疗助手..."
}字段映射:
instruction → prompt
output → response
最终完整版 dataset_info.json
你原来写的完全正确,我帮你规范化并加注释:
json
[
{
"dataset_name": "med-disc",
"dataset_path": "/root/data1/MyProject/AIDoctor/llm/train_data/DISC-Med-SFT/DISC-Med-SFT_released.jsonl",
"columns": {
"messages": "conversation"
}
},
{
"dataset_name": "med-self-cog",
"dataset_path": "/root/data1/MyProject/AIDoctor/llm/train_data/Model-Self-cog/med_self_cog.jsonl",
"columns": {
"prompt": "instruction",
"response": "output"
}
}
]100% 可直接训练 ✅
六、训练命令怎么写?
bash
CUDA_VISIBLE_DEVICES=0,1 NPROC_PER_NODE=2 swift sft \
--model_type qwen1_5 \
--model ./Qwen1_5-1_8B-Chat \
--train_type lora \
--dataset_info dataset_info.json \
--dataset med-disc med-self-cog \
--load_in_4bit true \
--gradient_checkpointing true \
--max_length 2048 \
--output_dir ./output七、常见格式问题与避坑
1. JSON/JSONL 必须严格合法
- 每行一个 JSON
- 不要尾逗号
- 字符串必须双引号
2. 多轮对话必须用 messages/conversation 格式
不能混用 alpaca 和多轮。
3. system 提示词优先级
数据内 system > 命令行 --system > 模板默认
4. 数据集路径必须绝对路径
避免相对路径找不到文件。
5. 字段名写错会直接报错
例如把 conversation 写成 conversations
八、支持的更多高级格式(扩展)
1. RLHF 系列格式(DPO/ORPO/KTO/SimPO)
json
{
"messages": [...],
"rejected_response": "..."
}2. 多模态格式
json
{
"messages": [...],
"images": ["1.jpg"]
}3. Agent 工具调用格式
json
{
"tools": "...",
"messages": [...]
}4. 带 loss 控制格式
json
{"role": "assistant", "content": "...", "loss": false}九、总结(最精简版)
- 多轮对话(ShareGPT) :
columns: {"messages": "conversation"} - 指令微调(Alpaca) :
columns: {"prompt":"instruction","response":"output"} - dataset_info.json 统一管理多数据集
- 你的医疗数据集 配置完全正确
- Swift 自动预处理,不用改原始数据