YOLO项目训练总共需要三步,你只要跟着一步一步做很简单
1.准备数据集,下载文件解压即可
首先打开网址,打不开的想想办法吧。
https://universe.roboflow.com/helmet-tf/safety-helmet-4mhdt/dataset/4
在里面选择YOLOV8的是我们要的数据集
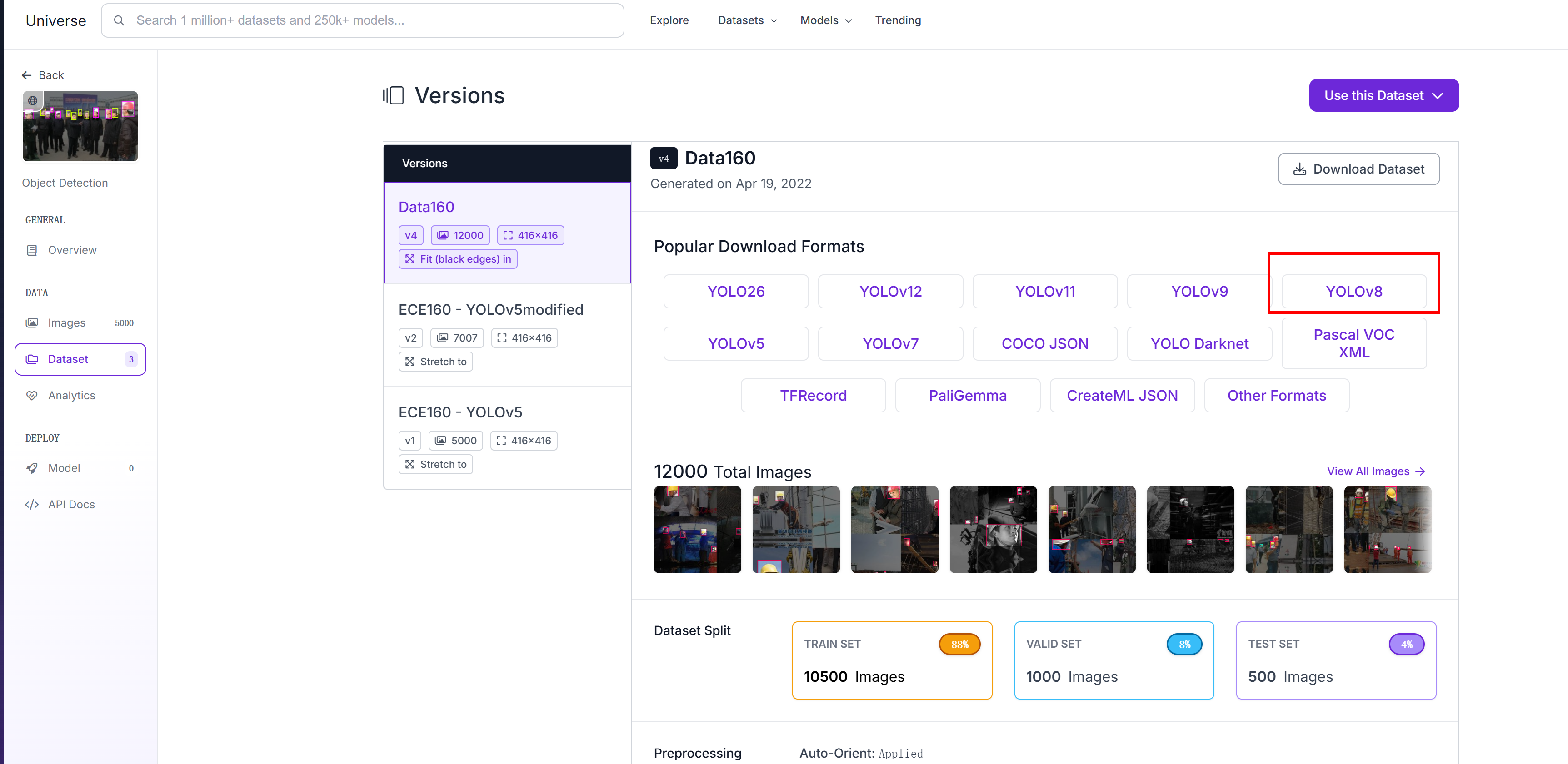
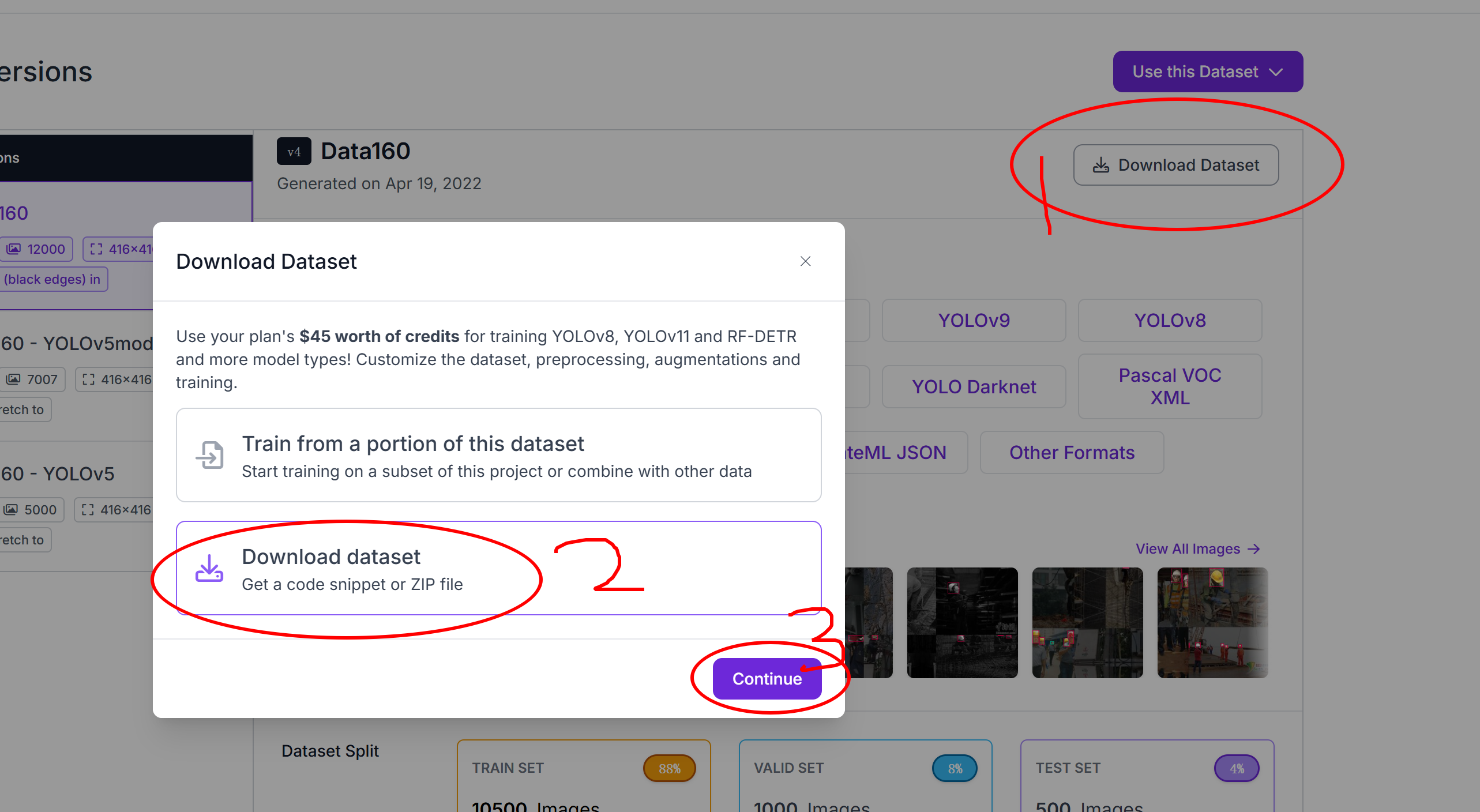
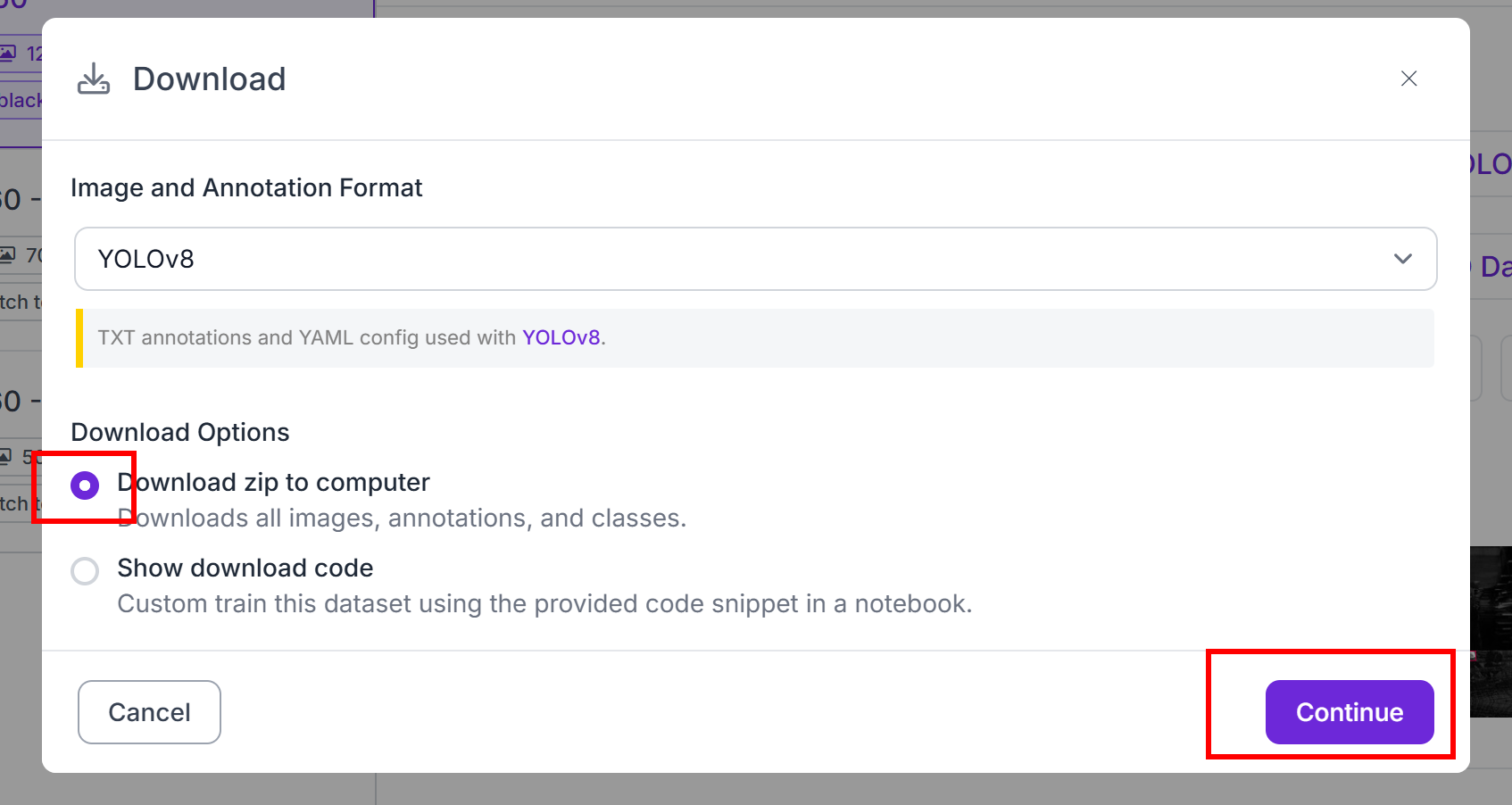
下载数据集就完成了
解压后就是这样,这个数据集是 有两个标签'Helmet', 'No Helmet' 戴了安全帽,没带安全帽
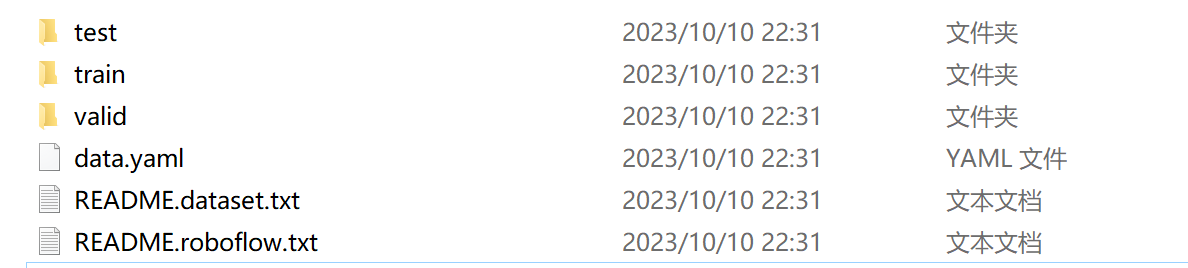
解压后不要被吓到
1.test 测试数据集
2.train 训练数据集
- valid 验证数据集
data.yaml 标签信息,就是数字0代表 戴了头盔, 数字1代表 没戴头盔
数据集就一堆图片和标签
都可以打开看看熟悉一下大致的结构
第一步就准备完成了
第二步,下载github上的项目解压
https://github.com/ultralytics/ultralytics
这是yolo的官方文档,直接整个下载即可
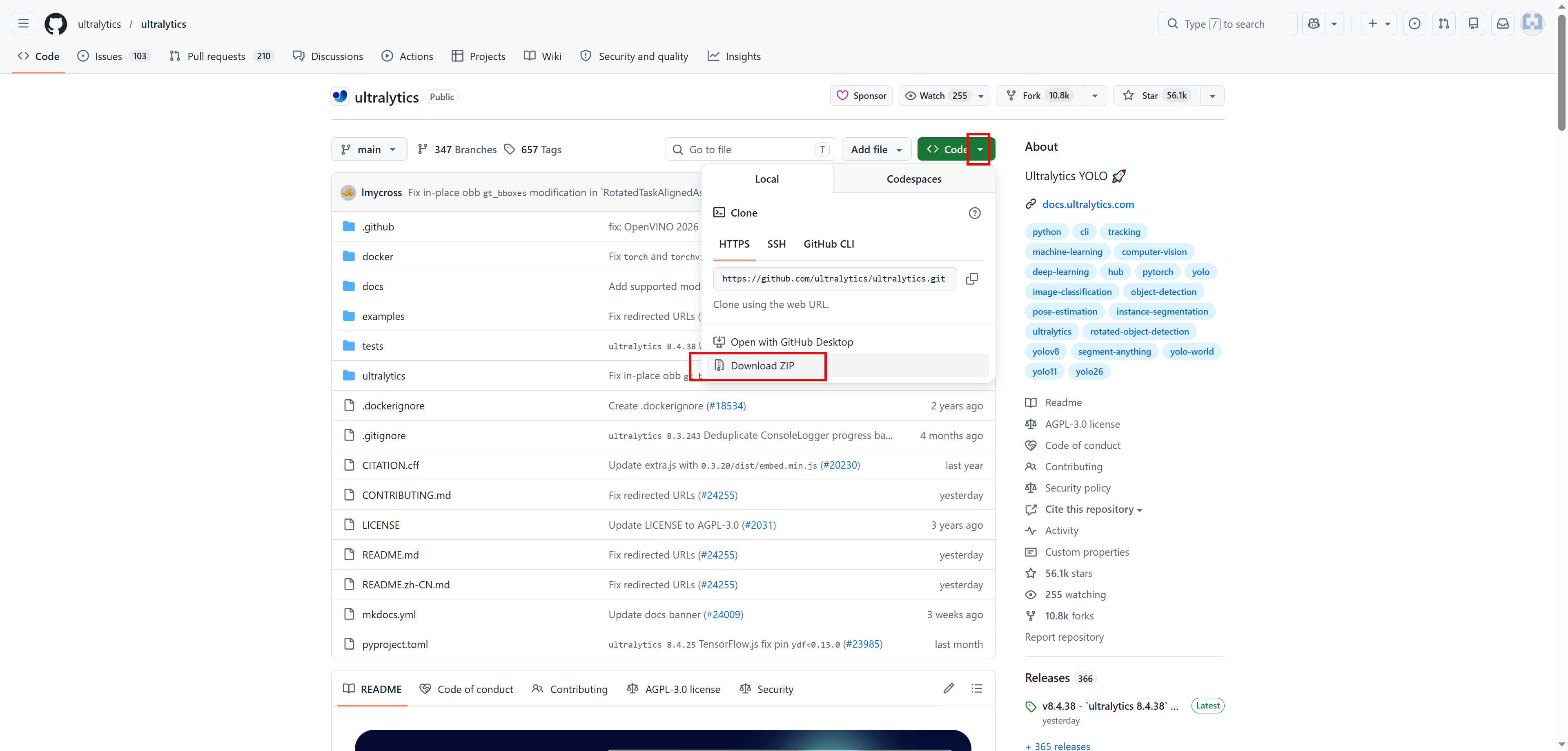
好这已经完成两步了。
第三步,使用pycharm打开项目,设置****路径
在文件夹这右键新建一个代码名字叫训练代码
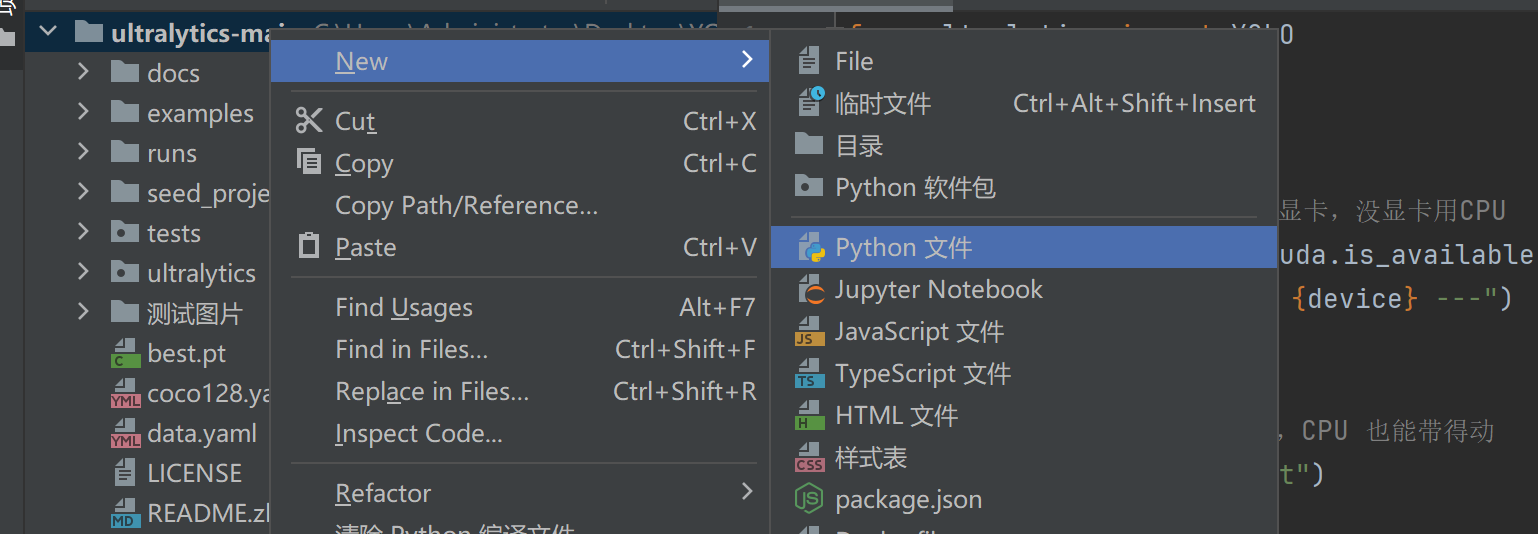
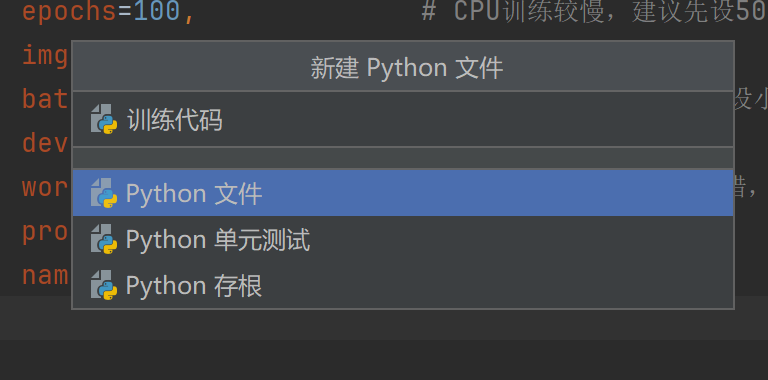
回车
然后双击训练代码,在里面粘贴代码如下
from ultralytics import YOLO
import torch
if __name__ == '__main__':
# 1. 自动检测设备:有显卡用显卡,没显卡用CPU
device = '0' if torch.cuda.is_available() else 'cpu'
print(f"--- 正在使用设备: {device} ---")
# 2. 加载模型
# yolo11n.pt 是最轻量级的,CPU 也能带得动
model = YOLO("yolov8n.pt")
# 3. 开始训练
results = model.train(
data="data.yaml", # 确保你的 yaml 文件在当前目录下
epochs=100, # CPU训练较慢,建议先设50轮测试
imgsz=640, # 图片输入尺寸
batch=8, # CPU训练建议把 batch 设小一点,防止内存溢出
device=device, # 自动匹配到的设备
workers=0, # Windows 系统下如果报错,将 workers 设为 0
project="训练结果",
name="模型结果",
)粘贴上去就可以了,很简单。
然后输入命令
pip install ultralytics
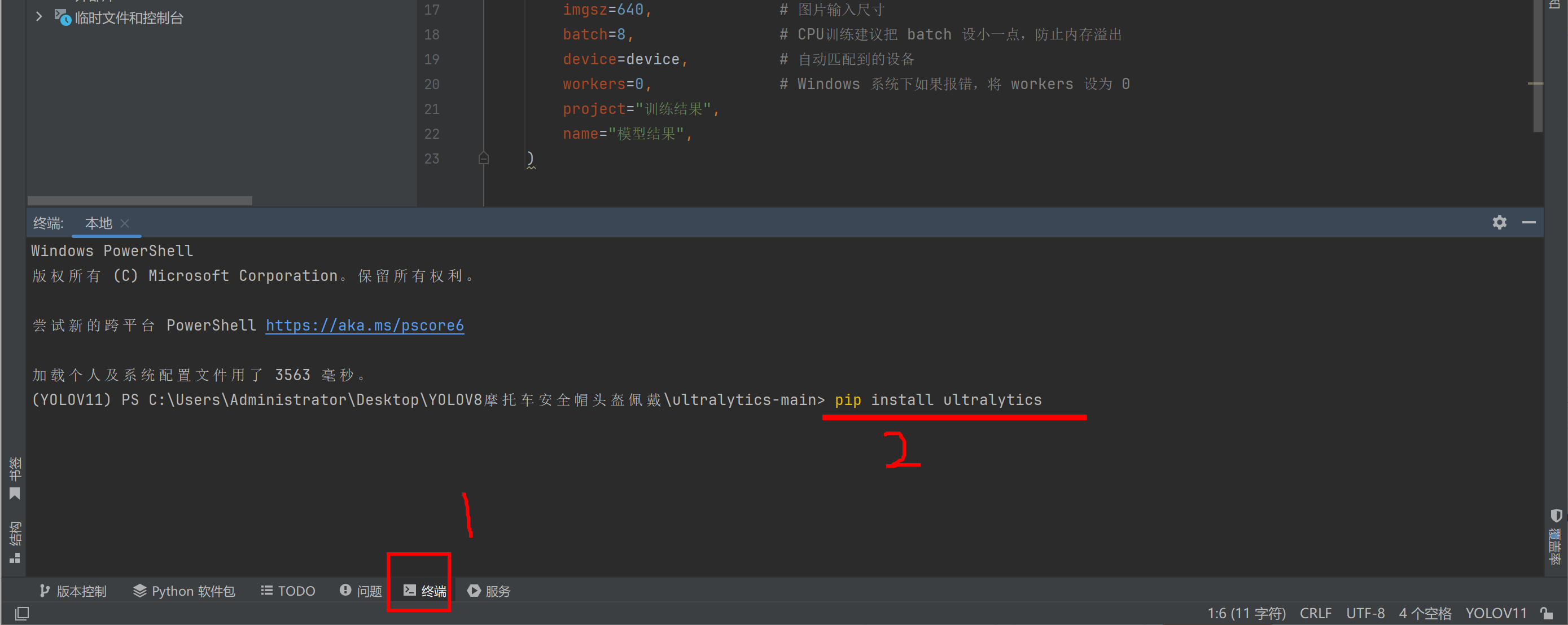
回车
如果太卡,可以关闭这个终端,重新打开终端
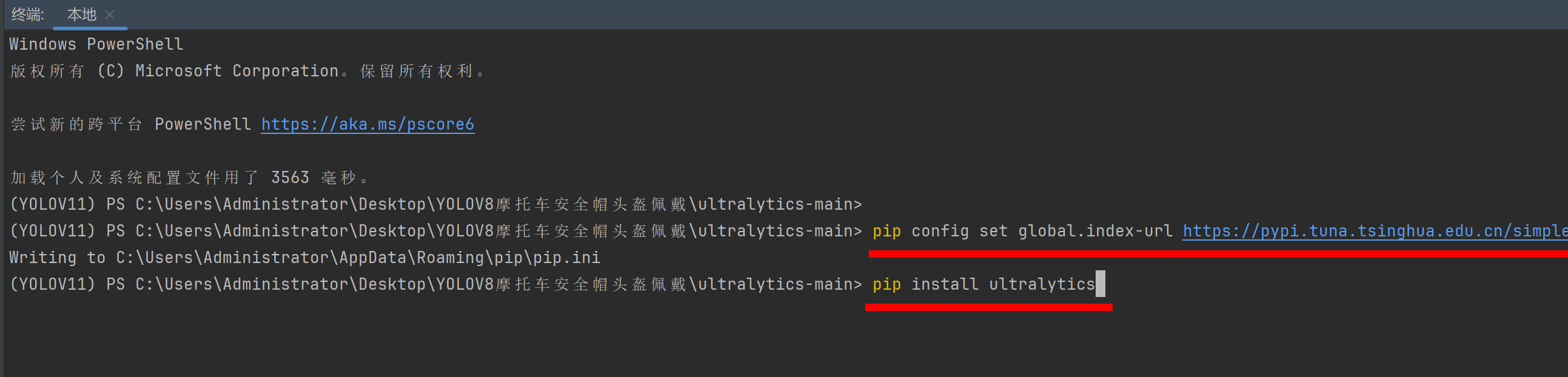
设置清华源,回车再输入这个命令
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install ultralytics
安装上这些库后环境就没问题了
然后设置一下data.yaml,将数据集里面的data.yaml修改为你自己的路径
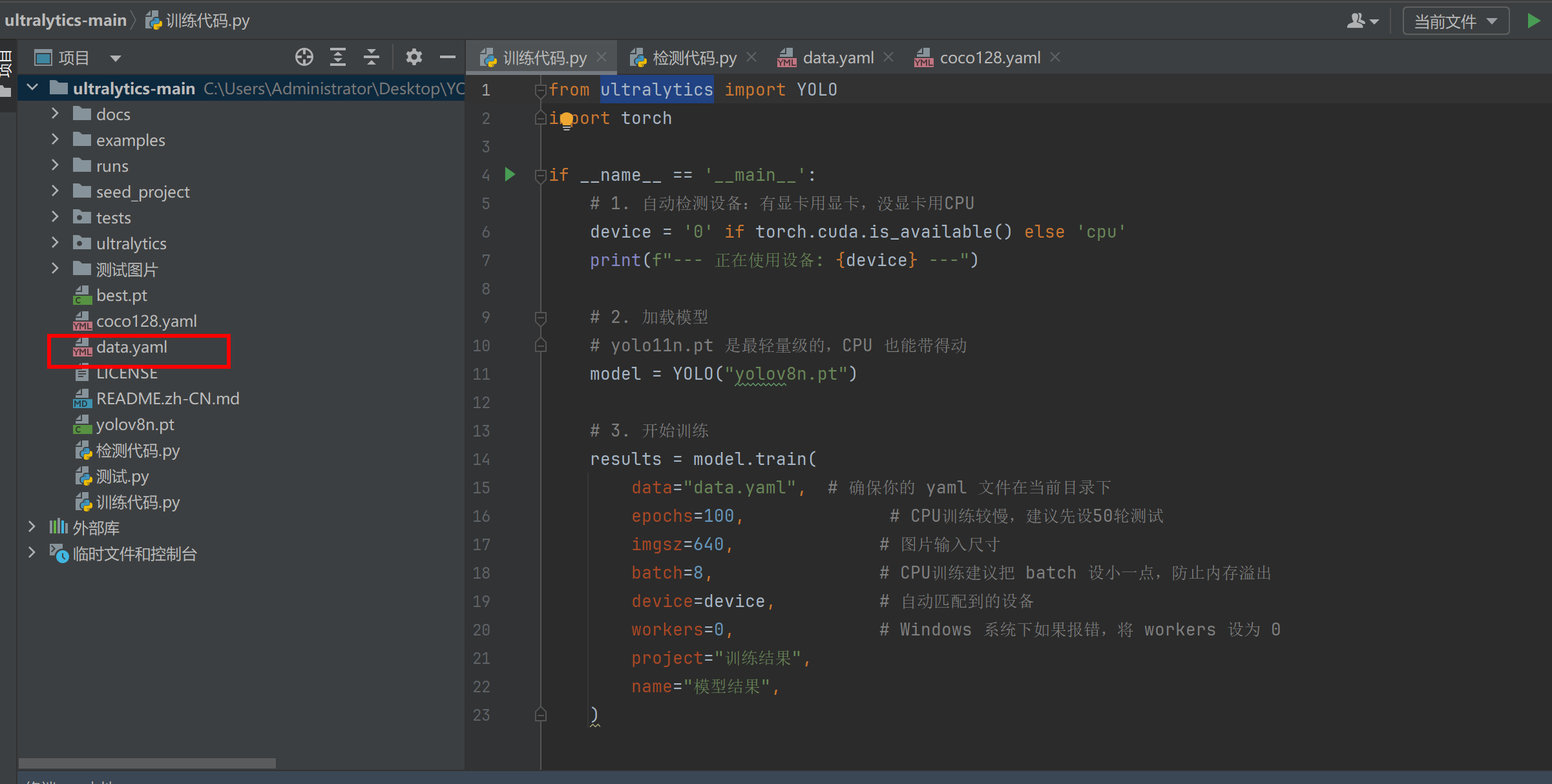
我的是这样的
path: C:/Users/Administrator/Downloads/安全帽检测
train: C:/Users/Administrator/Downloads/安全帽检测/train
val: C:/Users/Administrator/Downloads/安全帽检测/valid
test: C:/Users/Administrator/Downloads/安全帽检测/test
nc: 2
names: ['Helmet', 'No Helmet']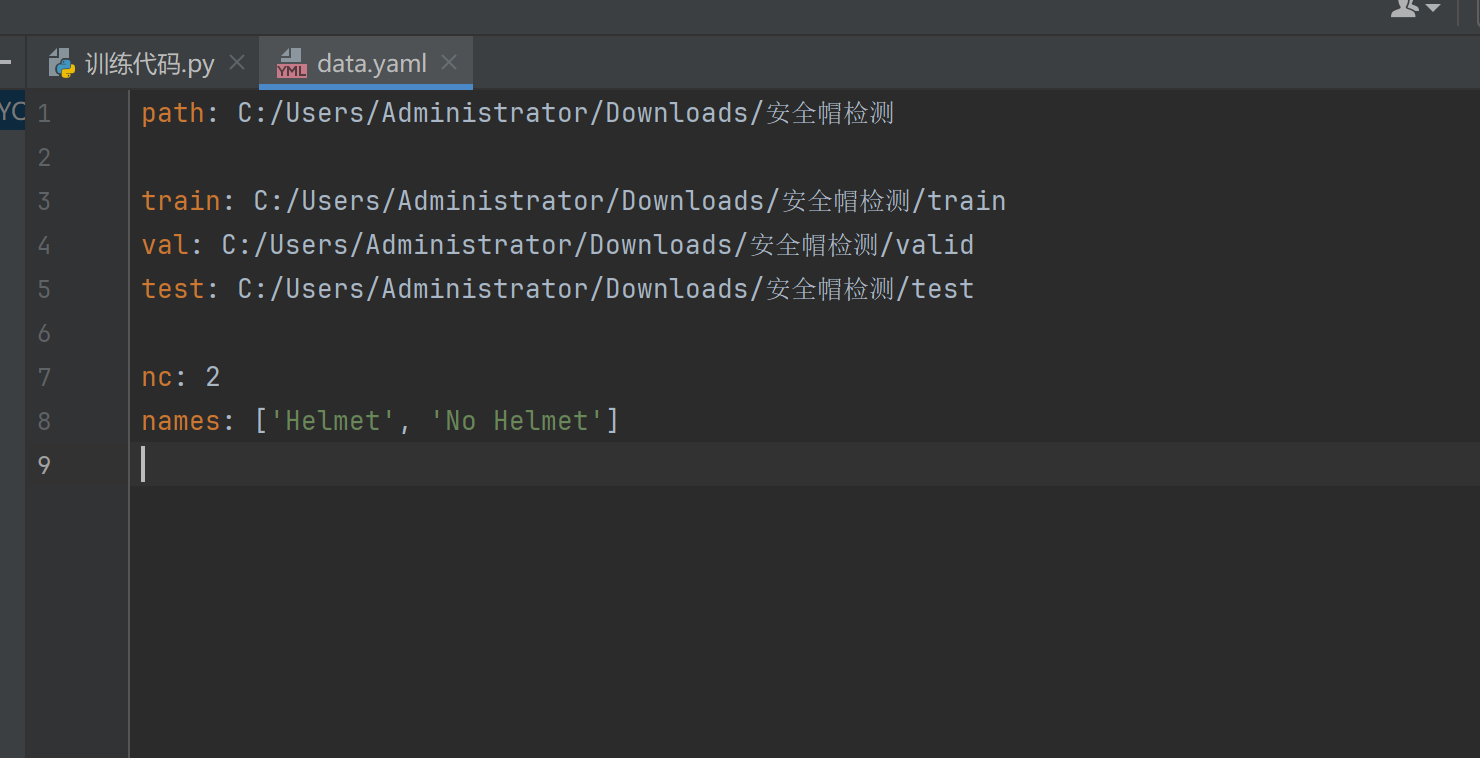
然后运行训练代码。这步比较久,有GPU的一定安装GPU版本的torch
先卸载cpu的torch
pip uninstall torch torchvision 回车
然后输入
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu128
这个命令安装GPU版本的torch大概网速好的话20分钟,网速差就不一定了,热点可能快一些
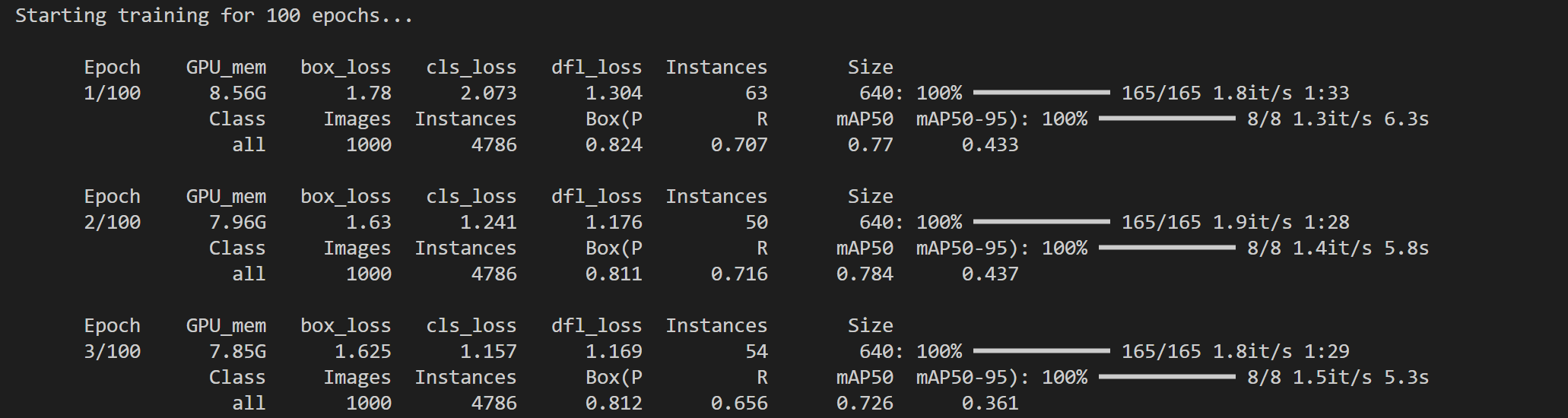
安上后运行这个代码,终端显示这些就是在运行了。
这边是特斯拉V100显卡大概16G 显存,大概运行时间是3小时。
如果是CPU估计训练需要大概2天多,所以最好是下载我已经训练完的结果。
运行完后,在新生成的这个文件夹下找到真正的路径找到里面的文件夹
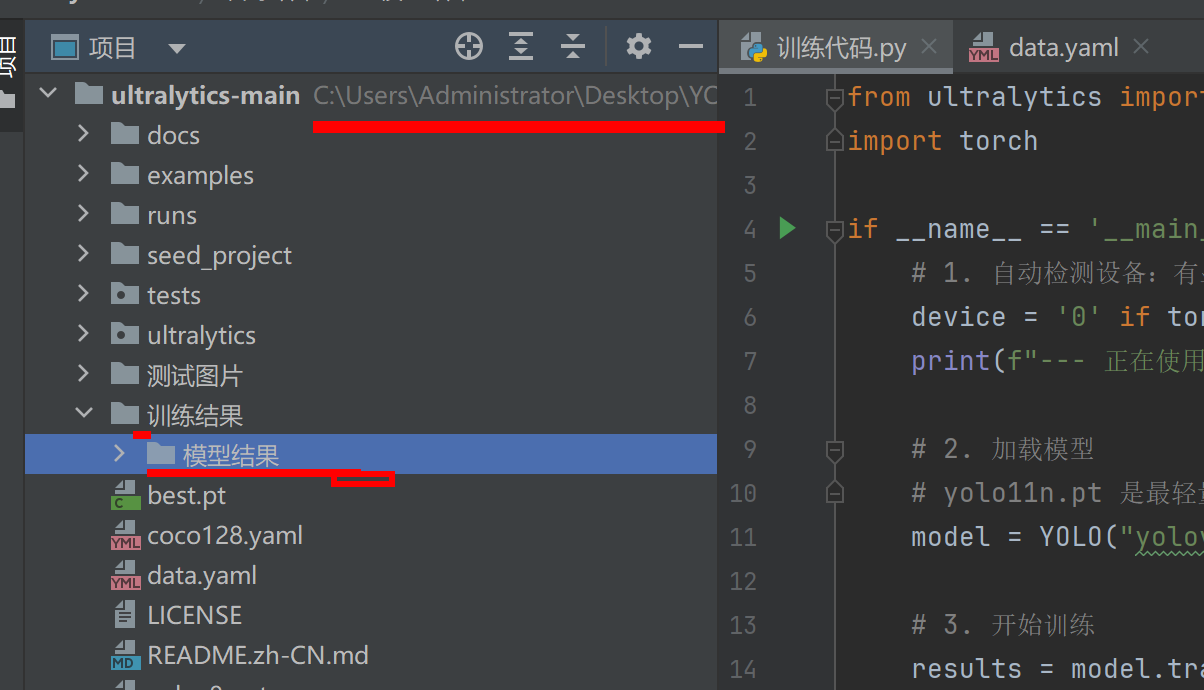
在这里,我的项目在桌面所以是这个位置
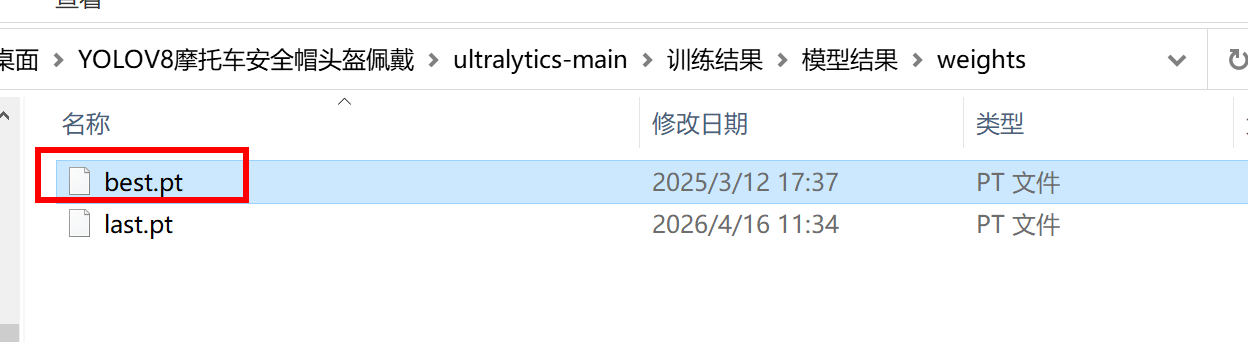
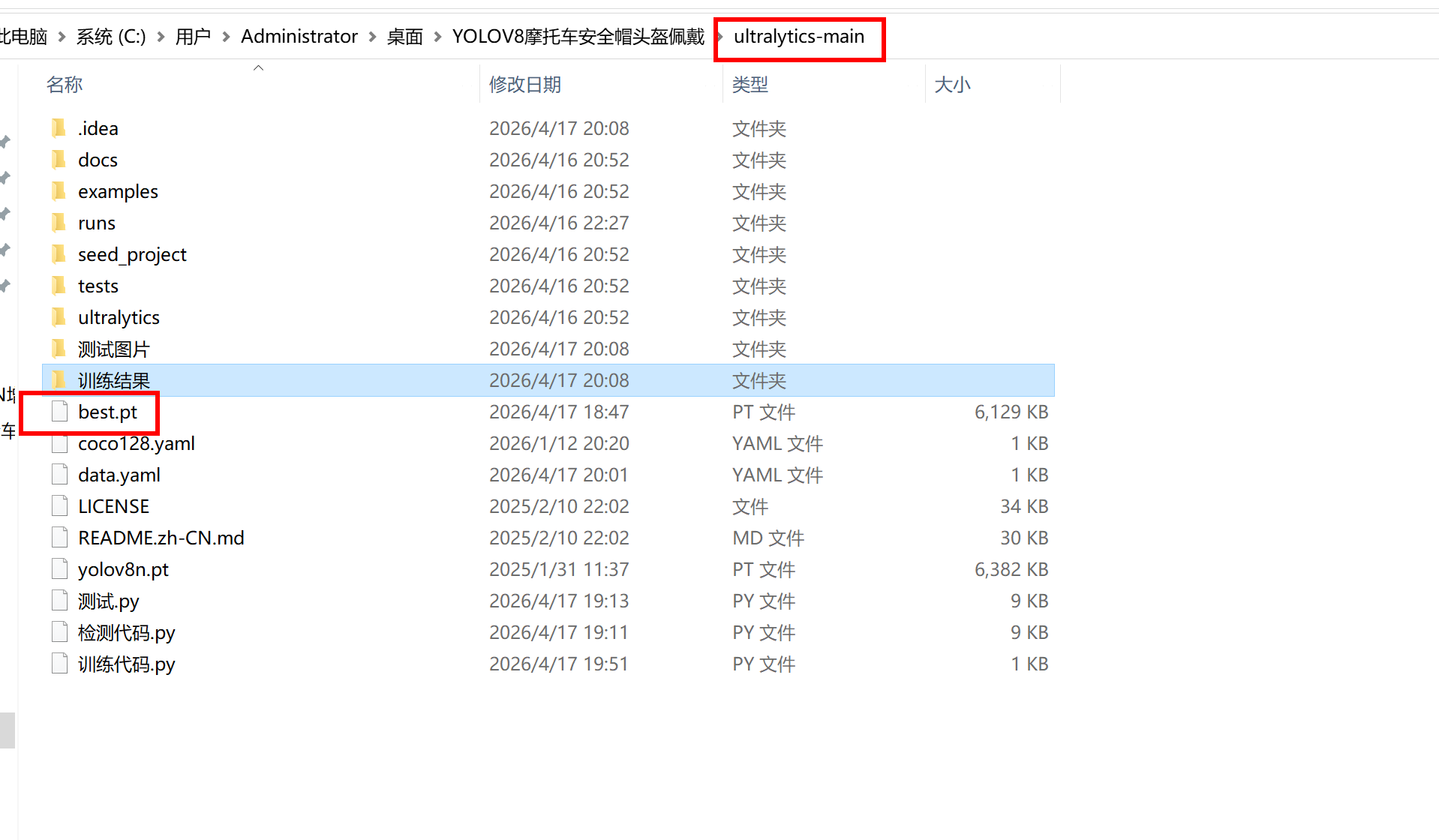
这个模型就是我们得到的最终的模型,只要调用这个模型就可以对目标进行检测了
这里有一个代码
可以调用这个模型,先吧这个模型复制粘贴到这个位置去
import sys
import cv2
import os
import numpy as np
import time
from PyQt5.QtWidgets import (QApplication, QMainWindow, QWidget, QVBoxLayout,
QHBoxLayout, QPushButton, QLabel, QFileDialog,
QSlider, QFrame, QMessageBox)
from PyQt5.QtGui import QImage, QPixmap
from PyQt5.QtCore import Qt, QThread, pyqtSignal
from ultralytics import YOLO
os.environ["QT_LOGGING_RULES"] = "qt.qpa.window=false"
# --- 核心检测逻辑(通用版:自动获取模型标签)---
def process_logic(frame, result, conf_thresh):
"""
通用处理逻辑:
根据模型自带的 names 映射表动态显示标签和统计数量。
"""
if result.boxes is None:
return frame, 0, "等待检测..."
boxes = result.boxes.xyxy.cpu().numpy()
clss = result.boxes.cls.cpu().numpy().astype(int)
confs = result.boxes.conf.cpu().numpy()
names = result.names # 获取模型类别字典 {id: name}
total_count = 0
stats = {} # 用于统计各类别的数量
for i, cls_id in enumerate(clss):
conf = confs[i]
if conf < conf_thresh:
continue
total_count += 1
label = names[cls_id]
stats[label] = stats.get(label, 0) + 1
# 绘制逻辑
x1, y1, x2, y2 = map(int, box := boxes[i])
# 根据类别 ID 生成固定颜色
color = (int((cls_id * 50) % 255), int((cls_id * 80) % 255), int((cls_id * 120) % 255))
cv2.rectangle(frame, (x1, y1), (x2, y2), color, 2)
cv2.putText(frame, f"{label} {conf:.2f}", (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, color, 2)
# 生成统计摘要文字
summary = "<br>".join([f"{k}: {v}" for k, v in stats.items()])
return frame, total_count, summary if summary else "未发现目标"
# --- 异步视频流线程 ---
class DetectionThread(QThread):
# 修改信号:传递 图像, 总数, 统计摘要字符串
update_signal = pyqtSignal(np.ndarray, int, str)
def __init__(self, model, source):
super().__init__()
self.model = model
self.source = source
self.running = True
self.conf = 0.4
def run(self):
# 自动识别摄像头索引或视频路径
backend = cv2.CAP_DSHOW if isinstance(self.source, int) else cv2.CAP_ANY
cap = cv2.VideoCapture(self.source, backend)
while self.running:
ret, frame = cap.read()
if not ret:
break
results = self.model.predict(frame, conf=self.conf, verbose=False)
processed_frame, total_cnt, summary = process_logic(frame, results[0], self.conf)
self.update_signal.emit(processed_frame, total_cnt, summary)
if not isinstance(self.source, int):
time.sleep(0.01)
cap.release()
def stop(self):
self.running = False
self.wait()
# --- GUI 主界面 ---
class GeneralDetectorUI(QMainWindow):
def __init__(self):
super().__init__()
# 加载模型(可以是 yolov8n.pt 或你训练的任何模型)
self.model = YOLO("yolov8n.pt")
self.thread = None
self.init_ui()
def init_ui(self):
self.setWindowTitle(f"AI 通用目标检测系统 - {self.model.task}")
self.resize(1200, 800)
self.setStyleSheet("""
QMainWindow { background-color: #1a1a1b; }
#SideBar { background-color: #252526; border-right: 1px solid #333; padding: 10px; }
#Display { background-color: #000; border-radius: 6px; }
QLabel { color: #dcdcdc; font-family: 'Segoe UI', 'Microsoft YaHei'; }
QPushButton {
background-color: #3e3e42; color: #fff; border: none;
padding: 12px; border-radius: 4px; font-size: 14px; margin: 4px;
}
QPushButton:hover { background-color: #4e4e52; }
QPushButton#Primary { background-color: #007acc; font-weight: bold; }
QPushButton#Stop { background-color: #d83b01; }
QSlider::handle:horizontal { background: #007acc; width: 16px; border-radius: 8px; }
""")
main_layout = QHBoxLayout()
container = QWidget()
container.setLayout(main_layout)
self.setCentralWidget(container)
sidebar = QFrame()
sidebar.setObjectName("SideBar")
sidebar.setFixedWidth(280)
side_vbox = QVBoxLayout(sidebar)
logo = QLabel("<h2>VISION AI</h2>")
logo.setAlignment(Qt.AlignCenter)
side_vbox.addWidget(logo)
self.btn_img = QPushButton("📸 检测单张图片")
self.btn_vid = QPushButton("🎞️ 解析视频文件")
self.btn_cam = QPushButton("📹 开启实时监控")
self.btn_stop = QPushButton("🛑 停止运行")
self.btn_img.setObjectName("Primary")
self.btn_stop.setObjectName("Stop")
for b in [self.btn_img, self.btn_vid, self.btn_cam, self.btn_stop]:
side_vbox.addWidget(b)
side_vbox.addSpacing(30)
side_vbox.addWidget(QLabel("置信度调节"))
self.conf_slider = QSlider(Qt.Horizontal)
self.conf_slider.setRange(1, 99)
self.conf_slider.setValue(45)
side_vbox.addWidget(self.conf_slider)
self.conf_label = QLabel("Confidence: 0.45")
side_vbox.addWidget(self.conf_label)
side_vbox.addStretch()
self.stats_box = QLabel("等待任务...")
self.stats_box.setStyleSheet("background-color: #333; padding: 15px; border-radius: 4px; line-height: 150%;")
side_vbox.addWidget(self.stats_box)
main_layout.addWidget(sidebar)
self.display = QLabel("SYSTEM READY")
self.display.setObjectName("Display")
self.display.setAlignment(Qt.AlignCenter)
main_layout.addWidget(self.display, 1)
self.btn_img.clicked.connect(self.run_image)
self.btn_vid.clicked.connect(self.run_video)
self.btn_cam.clicked.connect(self.run_camera)
self.btn_stop.clicked.connect(self.stop_all)
self.conf_slider.valueChanged.connect(self.sync_conf)
def sync_conf(self):
val = self.conf_slider.value() / 100
self.conf_label.setText(f"Confidence: {val:.2f}")
if self.thread:
self.thread.conf = val
def stop_all(self):
if self.thread:
self.thread.stop()
self.thread = None
self.display.clear()
self.display.setText("已停止")
def run_image(self):
self.stop_all()
path, _ = QFileDialog.getOpenFileName(self, "选择图片", "", "Images (*.jpg *.png *.jpeg *.bmp)")
if not path: return
try:
# 支持中文路径读取
img = cv2.imdecode(np.fromfile(path, dtype=np.uint8), cv2.IMREAD_COLOR)
res = self.model.predict(img, conf=self.conf_slider.value() / 100)
processed_img, total, summary = process_logic(img, res[0], self.conf_slider.value() / 100)
self.refresh_ui(processed_img, total, summary)
except Exception as e:
QMessageBox.warning(self, "错误", f"读取失败: {e}")
def run_video(self):
self.stop_all()
path, _ = QFileDialog.getOpenFileName(self, "选择视频文件", "", "Videos (*.mp4 *.avi *.mkv)")
if path: self.launch_thread(path)
def run_camera(self):
self.stop_all()
self.launch_thread(0)
def launch_thread(self, src):
self.thread = DetectionThread(self.model, src)
self.thread.conf = self.conf_slider.value() / 100
self.thread.update_signal.connect(self.refresh_ui)
self.thread.start()
def refresh_ui(self, frame, total_cnt, summary):
# 更新侧边栏统计信息
self.stats_box.setText(f"<b>检测摘要:</b><br>总计目标: {total_cnt}<br><hr>{summary}")
# 画面渲染
h, w, c = frame.shape
q_img = QImage(frame.data, w, h, w * c, QImage.Format_BGR888)
pixmap = QPixmap.fromImage(q_img)
self.display.setPixmap(pixmap.scaled(self.display.size(), Qt.KeepAspectRatio, Qt.SmoothTransformation))
if __name__ == "__main__":
app = QApplication(sys.argv)
window = GeneralDetectorUI()
window.show()
sys.exit(app.exec_())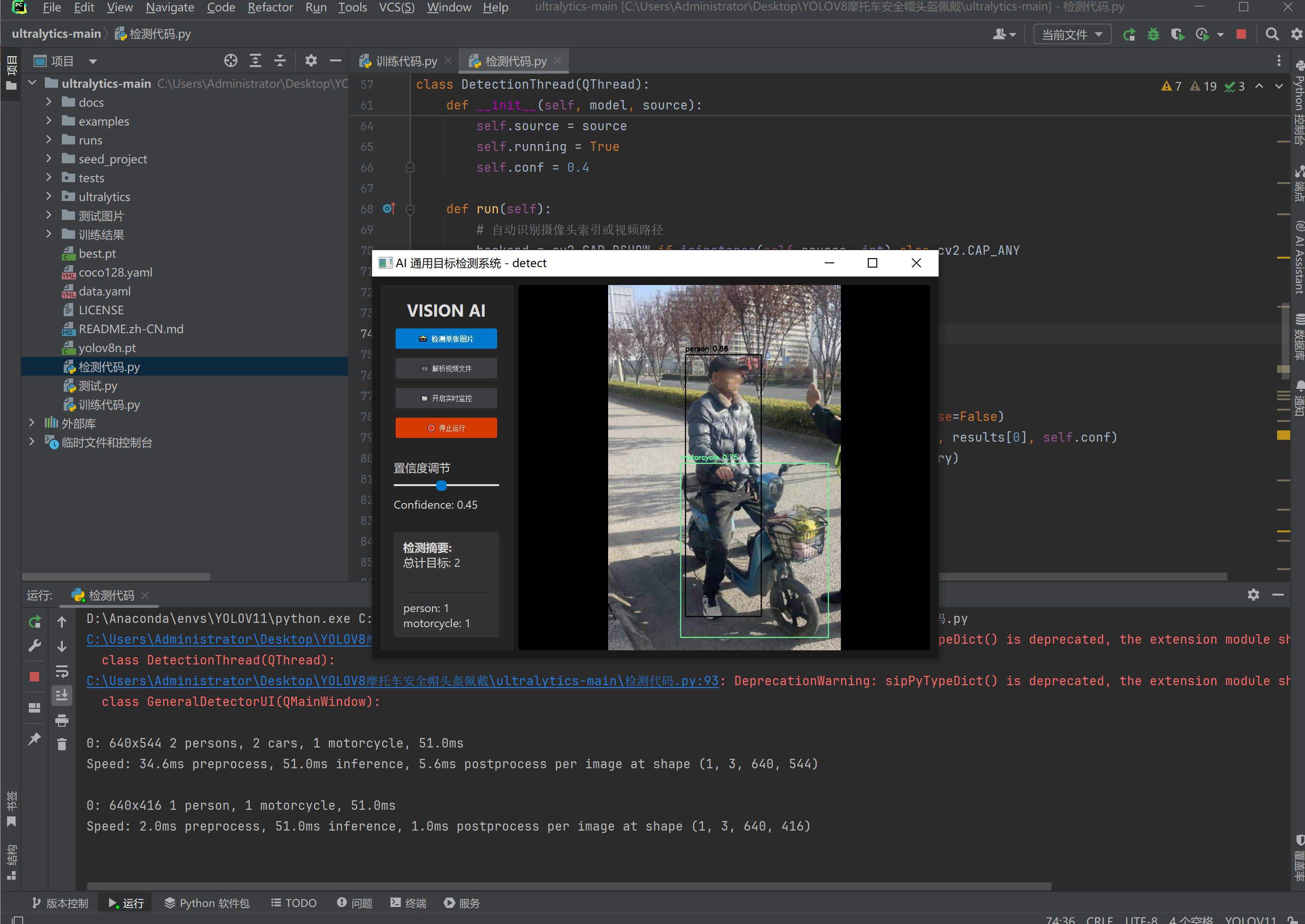
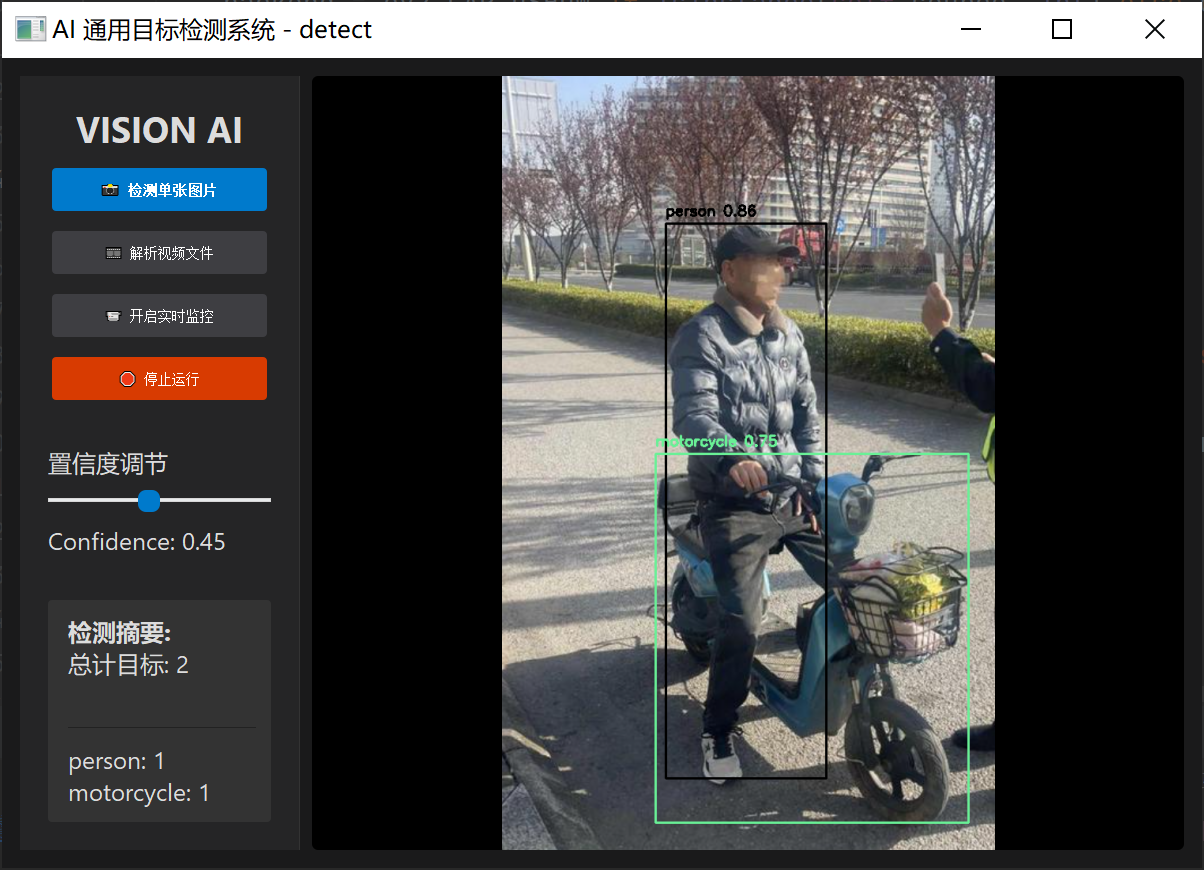
运行后就可以检测到这些图片了,也可以检测视频也可以实时的使用摄像头进行检测。
那么这个项目就完成了。