1 缺陷检测数据集选择
1.1 NEU-DET 数据集
NEU-DET 是一个广泛应用于钢铁表面缺陷检测研究领域的经典数据集,由东北大学发布。它就像目标检测和工业智能质检领域的"入门级教科书",被学术界和工业界广泛采用。
它主要有以下几个核心特点:
数据规模:总计 1800 张灰度图像。
图像尺寸:每张图像的分辨率为 200 x 200 像素。这类似乎工业相机的一个小特写,聚焦在缺陷区域。
缺陷类别:共包含 6 种典型的热轧带钢表面缺陷
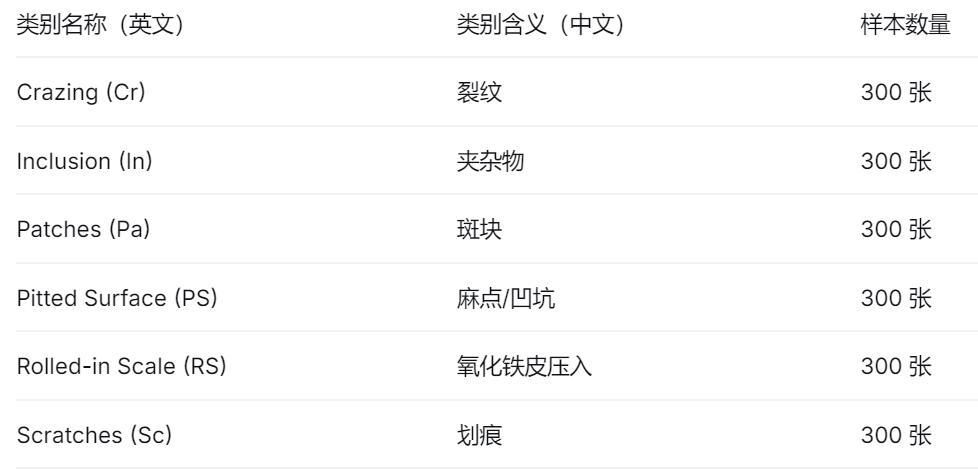
根据近年的一些研究,主流模型在该数据集上的平均精度(mAP@0.5)大致在 78% 到 82% 之间。这个结果说明,虽然经典问题已得到较好解决,但在小目标、模糊特征等难题上,仍有很大的提升空间。
总的来说,NEU-DET 是一个规模不大但"五脏俱全"的高质量工业质检数据集。它是测试新的检测模型、尤其是验证模型在复杂背景和小目标上性能的理想选择。
下载NEU-DET数据集:https://download.csdn.net/download/Cupid_kl/92915445
也可到官方下载:http://faculty.neu.edu.cn/songkechen/zh_CN/zdylm/263270/list
1.2 GC10-DET数据集
GC10-DET 是一个在真实工业场景中采集的大规模金属表面缺陷检测数据集,由天津大学于2020年发布。它旨在解决以往数据集规模小、缺陷类别单一的问题,是该领域的重要基准数据集。
数据集核心特点:
数据规模:总计 3570 张灰度图像(原始采集),部分处理版本约 2283-2293 张。
图像尺寸:原始图像分辨率高达 2048×1000 像素,远高于NEU-DET的200×200像素。
缺陷类别:包含 10 种典型的钢材表面缺陷,覆盖了更复杂的工业缺陷类型:
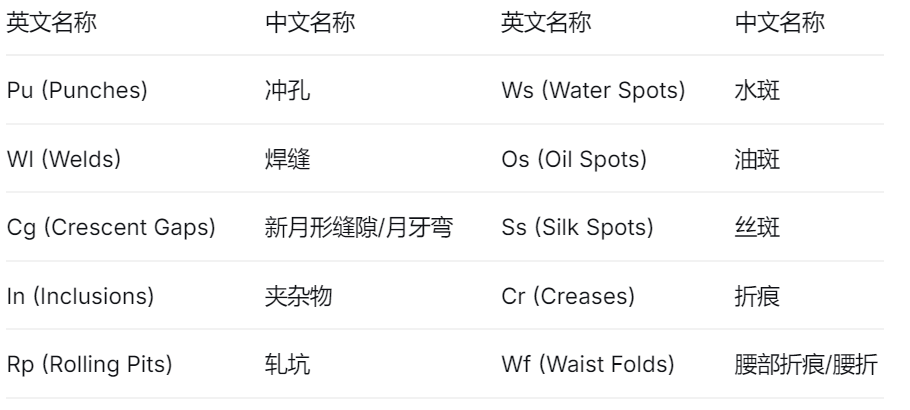
下载GC10-DET数据集:https://download.csdn.net/download/Cupid_kl/92915490
1.3 MVTec_AD数据集
MVTec AD (MVTec Anomaly Detection) 数据集是工业异常检测领域最知名、应用最广泛的基准数据集之一,由德国MVTec Software公司于2019年发布。它最大的特点是专门为"无监督"异常检测设计,训练集只包含正常(无缺陷)样本,这非常贴近实际工业场景中缺陷样本稀少的情况。
数据集类别:
数据集包含 15个 不同的子集,分为纹理和物体两大类,覆盖了多种工业检测场景:
纹理类别 (5种):Carpet (地毯)、Grid (网格)、Leather (皮革)、Tile (瓷砖)、Wood (木材)
物体类别 (10种):Bottle (瓶子)、Cable (电线)、Capsule (胶囊)、Hazelnut (榛子)、Metal Nut (金属螺母)、Pill(药片)、Screw (螺丝钉)、Toothbrush (牙刷)、Transistor (晶体管)、Zipper (拉链)
下载MVTec AD数据集:https://www.mvtec.com/research-teaching/datasets/mvtec-ad
2 将以上数据集转换成YOLO的txt格式
2.1 NEU-DET转换成YOLO的txt格式
转换过程主要包含以下几个步骤:
解析XML文件:提取图片尺寸和每个标注目标的类别、边界框坐标(xmin, ymin, xmax, ymax)
坐标归一化:将像素坐标转换为YOLO所需的归一化中心点坐标和宽高
类别映射:将类别名称映射为对应的数字ID(0-9)
输出TXT文件:每个图片对应一个同名的TXT文件,与图片存放于对应目录
python
"""
VOC XML to YOLO TXT Converter
将Pascal VOC格式(XML)转换为YOLO格式(txt)
适用于NEU-DET和GC10-DET数据集
"""
import xml.etree.ElementTree as ET
from pathlib import Path
import cv2
# ========== 配置 ==========
DATA_ROOT = Path("F:/code/NEU-DET/NEU-DET") # 修改为你的数据集路径
OUTPUT_ROOT = Path("./yolo_format/neu_det") # YOLO格式输出路径
CLASSES = ['crazing', 'inclusion', 'patches', 'pitted_surface',
'rolled-in_scale', 'scratches'] # NEU-DET的6类缺陷
# =========================
def convert_voc_to_yolo(xml_path, img_shape, classes):
"""将单个XML标注转换为YOLO格式"""
tree = ET.parse(xml_path)
root = tree.getroot()
h, w = img_shape[:2]
yolo_labels = []
for obj in root.findall('object'):
class_name = obj.find('name').text
if class_name not in classes:
continue
class_id = classes.index(class_name)
bndbox = obj.find('bndbox')
xmin = int(bndbox.find('xmin').text)
ymin = int(bndbox.find('ymin').text)
xmax = int(bndbox.find('xmax').text)
ymax = int(bndbox.find('ymax').text)
# 转换为YOLO归一化格式
x_center = (xmin + xmax) / 2 / w
y_center = (ymin + ymax) / 2 / h
width = (xmax - xmin) / w
height = (ymax - ymin) / h
yolo_labels.append(f"{class_id} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}")
return yolo_labels
def process_dataset(xml_dir, img_dir, output_dir, classes, train_ratio=0.8):
"""处理整个数据集,划分训练/验证集"""
xml_files = list(xml_dir.glob("*.xml"))
# 划分数据集
import random
random.seed(42)
random.shuffle(xml_files)
split_idx = int(len(xml_files) * train_ratio)
train_files = xml_files[:split_idx]
val_files = xml_files[split_idx:]
# 创建目录
for split in ['train', 'val']:
(output_dir / 'images' / split).mkdir(parents=True, exist_ok=True)
(output_dir / 'labels' / split).mkdir(parents=True, exist_ok=True)
# 处理训练集
for xml_path in train_files:
img_path = img_dir / f"{xml_path.stem}.jpg"
img = cv2.imread(str(img_path))
if img is None:
continue
yolo_labels = convert_voc_to_yolo(xml_path, img.shape, classes)
# 复制图片
cv2.imwrite(str(output_dir / 'images' / 'train' / f"{xml_path.stem}.jpg"), img)
# 保存标签
if yolo_labels:
with open(output_dir / 'labels' / 'train' / f"{xml_path.stem}.txt", 'w') as f:
f.write('\n'.join(yolo_labels))
# 同理处理验证集
for xml_path in val_files:
img_path = img_dir / f"{xml_path.stem}.jpg"
img = cv2.imread(str(img_path))
if img is None:
continue
yolo_labels = convert_voc_to_yolo(xml_path, img.shape, classes)
cv2.imwrite(str(output_dir / 'images' / 'val' / f"{xml_path.stem}.jpg"), img)
if yolo_labels:
with open(output_dir / 'labels' / 'val' / f"{xml_path.stem}.txt", 'w') as f:
f.write('\n'.join(yolo_labels))
print(f"处理完成: 训练集{len(train_files)}张, 验证集{len(val_files)}张")
def create_data_yaml(output_dir, classes):
"""创建YOLO的data.yaml配置文件"""
yaml_content = f"""
path: {output_dir.absolute()}
train: images/train
val: images/val
nc: {len(classes)}
names: {classes}
"""
with open(output_dir / 'data.yaml', 'w') as f:
f.write(yaml_content)
print(f"已创建配置文件: {output_dir / 'data.yaml'}")
if __name__ == "__main__":
# NEU-DET转换
process_dataset(
xml_dir=Path("F:/code/NEU-DET/NEU-DET/ANNOTATIONS"),
img_dir=Path("F:/code/NEU-DET/NEU-DET/IMAGES"),
output_dir=OUTPUT_ROOT,
classes=CLASSES,
train_ratio=0.8
)
create_data_yaml(OUTPUT_ROOT, CLASSES)
print("\n✅ NEU-DET转换完成!")
print(f"输出目录: {OUTPUT_ROOT}")2.2 GC10-DET转换成YOLO的txt格式
python
"""
GC10-DET数据集转YOLO格式
针对目录结构:
- 图片在 1/, 2/, ..., 10/ 文件夹
- XML标注在 lable/ 文件夹
"""
import os
import glob
import random
import shutil
import xml.etree.ElementTree as ET
from pathlib import Path
from typing import Dict, List, Tuple, Optional
class GC10ToYOLOConverter:
"""GC10-DET数据集转YOLO格式转换器"""
# 文件夹编号到YOLO类别ID的映射
FOLDER_TO_CLASS = {
1: 0, # punching_hole (冲孔)
2: 1, # welding_line (焊缝)
3: 2, # crescent_gap (月牙弯)
4: 3, # water_spot (水斑)
5: 4, # oil_spot (油斑)
6: 5, # silk_spot (丝斑)
7: 6, # inclusion (夹杂物)
8: 7, # rolled_pit (轧坑)
9: 8, # crease (折痕)
10: 9, # waist_folding (腰折)
}
# 类别名称
CLASS_NAMES = {
0: "punching_hole",
1: "welding_line",
2: "crescent_gap",
3: "water_spot",
4: "oil_spot",
5: "silk_spot",
6: "inclusion",
7: "rolled_pit",
8: "crease",
9: "waist_folding"
}
def __init__(self, data_root: str, output_root: str = "GC10-DET-YOLO"):
"""
初始化转换器
Args:
data_root: GC10-DET数据集根目录 (包含1-10文件夹和lable文件夹)
output_root: YOLO格式输出目录
"""
self.data_root = Path(data_root)
self.output_root = Path(output_root)
self.image_dirs = {i: self.data_root / str(i) for i in range(1, 11)}
self.xml_dir = self.data_root / "lable"
# 存储转换结果
self.all_samples = []
def check_structure(self):
"""检查目录结构"""
print("="*60)
print("检查数据集结构")
print("="*60)
# 检查图片目录
for folder_id in range(1, 11):
img_dir = self.image_dirs[folder_id]
if img_dir.exists():
img_count = len(list(img_dir.glob("*.jpg")) + list(img_dir.glob("*.jpeg")) + list(img_dir.glob("*.png")))
print(f"✓ 文件夹 {folder_id}: {img_count} 张图片")
else:
print(f"✗ 文件夹 {folder_id}: 不存在")
# 检查XML目录
if self.xml_dir.exists():
xml_count = len(list(self.xml_dir.glob("*.xml")))
print(f"✓ lable文件夹: {xml_count} 个XML文件")
else:
print(f"✗ lable文件夹: 不存在")
return False
return True
def parse_xml(self, xml_path: Path) -> Optional[Dict]:
"""
解析XML文件,提取标注信息
Args:
xml_path: XML文件路径
Returns:
包含图片名和标注框的字典
"""
try:
tree = ET.parse(xml_path)
root = tree.getroot()
# 获取图片文件名
filename = None
for elem in ['filename', 'name']:
if root.find(elem) is not None:
filename = root.find(elem).text
break
if not filename:
# 从XML文件名推断
filename = xml_path.stem + ".jpg"
# 获取图片尺寸
size = root.find('size')
if size is not None:
img_w = int(size.find('width').text)
img_h = int(size.find('height').text)
else:
# 默认GC10-DET图片尺寸
img_w, img_h = 2048, 1000
# 从文件名推断文件夹ID
folder_id = self._get_folder_from_filename(filename)
if folder_id == 0:
print(f"警告: 无法从文件名确定文件夹: {filename}")
return None
# 获取类别ID
class_id = self.FOLDER_TO_CLASS.get(folder_id)
if class_id is None:
print(f"警告: 无效的文件夹ID {folder_id}")
return None
# 解析所有标注框
objects = []
for obj in root.findall('object'):
bndbox = obj.find('bndbox')
if bndbox is None:
continue
xmin = float(bndbox.find('xmin').text)
ymin = float(bndbox.find('ymin').text)
xmax = float(bndbox.find('xmax').text)
ymax = float(bndbox.find('ymax').text)
# 转换为YOLO格式
x_center = (xmin + xmax) / 2.0 / img_w
y_center = (ymin + ymax) / 2.0 / img_h
width = (xmax - xmin) / img_w
height = (ymax - ymin) / img_h
# 边界检查
x_center = min(max(x_center, 0.0), 1.0)
y_center = min(max(y_center, 0.0), 1.0)
width = min(width, 1.0 - x_center)
height = min(height, 1.0 - y_center)
if width > 0 and height > 0:
objects.append(f"{class_id} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}")
if not objects:
return None
return {
'filename': filename,
'folder_id': folder_id,
'class_id': class_id,
'objects': objects,
'img_w': img_w,
'img_h': img_h
}
except Exception as e:
print(f"解析XML失败 {xml_path.name}: {e}")
return None
def _get_folder_from_filename(self, filename: str) -> int:
"""从文件名推断文件夹编号"""
# 文件名格式如: img_01_3402617700_00001.jpg
# 提取第一部分数字
parts = filename.split('_')
if len(parts) >= 2 and parts[1].isdigit():
return int(parts[1])
# 尝试其他格式
for folder_id in range(1, 11):
if filename.startswith(f"{folder_id:02d}_") or filename.startswith(f"{folder_id}_"):
return folder_id
return 0
def find_image_path(self, filename: str, folder_id: int) -> Optional[Path]:
"""查找图片文件路径"""
# 根据文件夹ID查找
img_dir = self.image_dirs.get(folder_id)
if img_dir and img_dir.exists():
# 尝试不同扩展名
for ext in ['.jpg', '.jpeg', '.png']:
img_path = img_dir / filename
if img_path.exists():
return img_path
# 尝试替换扩展名
img_path = img_dir / (Path(filename).stem + ext)
if img_path.exists():
return img_path
# 在所有文件夹中搜索
for folder_id in range(1, 11):
img_dir = self.image_dirs[folder_id]
if img_dir.exists():
for ext in ['.jpg', '.jpeg', '.png']:
img_path = img_dir / (Path(filename).stem + ext)
if img_path.exists():
return img_path
return None
def convert_all(self):
"""转换所有XML文件"""
print("\n" + "="*60)
print("开始转换XML标注文件")
print("="*60)
# 获取所有XML文件
xml_files = list(self.xml_dir.glob("*.xml"))
print(f"找到 {len(xml_files)} 个XML文件")
success_count = 0
failed_count = 0
for i, xml_path in enumerate(xml_files, 1):
# 解析XML
data = self.parse_xml(xml_path)
if not data:
failed_count += 1
continue
# 查找图片文件
img_path = self.find_image_path(data['filename'], data['folder_id'])
if not img_path:
print(f"警告: 找不到图片 {data['filename']}")
failed_count += 1
continue
# 保存转换结果
self.all_samples.append({
'xml_path': xml_path,
'img_path': img_path,
'img_name': img_path.name,
'objects': data['objects'],
'folder_id': data['folder_id']
})
success_count += 1
# 进度显示
if i % 200 == 0:
print(f"进度: {i}/{len(xml_files)} (成功: {success_count}, 失败: {failed_count})")
print(f"\n转换完成: 成功 {success_count}, 失败 {failed_count}")
return success_count
def split_and_save(self, train_ratio=0.7, val_ratio=0.15, test_ratio=0.15):
"""划分数据集并保存YOLO格式文件"""
if not self.all_samples:
print("错误: 没有转换成功的样本")
return
# 随机打乱
random.shuffle(self.all_samples)
# 计算划分点
total = len(self.all_samples)
train_end = int(total * train_ratio)
val_end = int(total * (train_ratio + val_ratio))
splits = {
'train': self.all_samples[:train_end],
'val': self.all_samples[train_end:val_end],
'test': self.all_samples[val_end:]
}
print("\n" + "="*60)
print("数据集划分")
print("="*60)
print(f"训练集: {len(splits['train'])} 张")
print(f"验证集: {len(splits['val'])} 张")
print(f"测试集: {len(splits['test'])} 张")
# 创建目录并保存文件
for split_name, samples in splits.items():
# 创建目录
img_dir = self.output_root / 'images' / split_name
label_dir = self.output_root / 'labels' / split_name
img_dir.mkdir(parents=True, exist_ok=True)
label_dir.mkdir(parents=True, exist_ok=True)
# 保存文件
for sample in samples:
# 复制图片
dst_img = img_dir / sample['img_name']
if not dst_img.exists():
shutil.copy2(sample['img_path'], dst_img)
# 保存标签
label_name = Path(sample['img_name']).stem + '.txt'
dst_label = label_dir / label_name
with open(dst_label, 'w', encoding='utf-8') as f:
f.write('\n'.join(sample['objects']))
print(f"✓ {split_name}: 已保存")
return splits
def generate_data_yaml(self, splits: Dict):
"""生成YOLO配置文件"""
yaml_content = f"""# GC10-DET Dataset for YOLO
# Converted from original VOC format
# Dataset paths
path: {self.output_root.absolute()}
train: images/train
val: images/val
test: images/test
# Number of classes
nc: 10
# Class names
names:
0: punching_hole
1: welding_line
2: crescent_gap
3: water_spot
4: oil_spot
5: silk_spot
6: inclusion
7: rolled_pit
8: crease
9: waist_folding
# Dataset statistics
total_images: {sum(len(v) for v in splits.values())}
train: {len(splits['train'])}
val: {len(splits['val'])}
test: {len(splits['test'])}
"""
yaml_path = self.output_root / 'data.yaml'
with open(yaml_path, 'w', encoding='utf-8') as f:
f.write(yaml_content)
print(f"\n✓ 生成配置文件: {yaml_path}")
def verify_output(self):
"""验证输出结果"""
print("\n" + "="*60)
print("验证输出结果")
print("="*60)
for split in ['train', 'val', 'test']:
img_dir = self.output_root / 'images' / split
label_dir = self.output_root / 'labels' / split
if img_dir.exists():
img_count = len(list(img_dir.glob("*")))
label_count = len(list(label_dir.glob("*.txt"))) if label_dir.exists() else 0
print(f"\n{split}集:")
print(f" 图片: {img_count} 张")
print(f" 标签: {label_count} 个")
if img_count == label_count and img_count > 0:
print(f" ✓ 正常")
elif img_count == 0:
print(f" ⚠ 空目录")
else:
print(f" ⚠ 图片和标签数量不匹配")
else:
print(f"\n{split}集: 目录不存在")
# 显示示例文件
print("\n示例文件结构:")
for split in ['train', 'val', 'test']:
img_dir = self.output_root / 'images' / split
if img_dir.exists():
samples = list(img_dir.glob("*"))[:3]
if samples:
print(f"\n{split}/:")
for s in samples:
label_file = self.output_root / 'labels' / split / (s.stem + '.txt')
label_exists = "✓" if label_file.exists() else "✗"
print(f" {label_exists} {s.name}")
def run(self, train_ratio=0.7, val_ratio=0.15, test_ratio=0.15):
"""执行完整转换流程"""
print("="*60)
print("GC10-DET 数据集转 YOLO 格式")
print("="*60)
print(f"数据根目录: {self.data_root}")
print(f"输出目录: {self.output_root}")
print("="*60)
# 1. 检查目录结构
if not self.check_structure():
print("目录结构检查失败")
return False
# 2. 转换所有XML
success_count = self.convert_all()
if success_count == 0:
print("没有成功转换的样本")
return False
# 3. 划分数据集并保存
splits = self.split_and_save(train_ratio, val_ratio, test_ratio)
# 4. 生成配置文件
self.generate_data_yaml(splits)
# 5. 验证结果
self.verify_output()
print("\n" + "="*60)
print("✓ 转换完成!")
print(f"输出目录: {self.output_root.absolute()}")
print("="*60)
return True
def main():
"""主函数"""
# 请根据你的实际路径修改
data_root = r"F:\code\GC10-DET\GC10-DET" # 你的数据根目录
output_root = r"F:\code\GC10-DET\GC10-DET-YOLO" # 输出目录
# 创建转换器并运行
converter = GC10ToYOLOConverter(data_root, output_root)
success = converter.run(train_ratio=0.7, val_ratio=0.15, test_ratio=0.15)
if not success:
print("\n转换失败,请检查:")
print("1. 图片文件夹(1-10)是否存在?")
print("2. lable文件夹是否存在且包含XML文件?")
print("3. 图片文件名和XML文件名是否匹配?")
if __name__ == "__main__":
main()2.3 MVTec_AD转换成YOLO的txt格式
python
"""
MVTec AD to YOLO Format Converter
"""
import cv2
import numpy as np
from pathlib import Path
import argparse
import random
from tqdm import tqdm
print("="*60)
print("脚本开始运行...")
print("="*60)
def mask_to_bbox(mask_path, img_shape, min_area=25):
"""将掩码转换为YOLO边界框格式"""
try:
mask = cv2.imread(str(mask_path), cv2.IMREAD_GRAYSCALE)
if mask is None:
return []
if np.sum(mask) == 0:
return []
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
h, w = img_shape[:2]
yolo_labels = []
for contour in contours:
area = cv2.contourArea(contour)
if area < min_area:
continue
x, y, bw, bh = cv2.boundingRect(contour)
x_center = (x + bw / 2) / w
y_center = (y + bh / 2) / h
width = bw / w
height = bh / h
x_center = max(0.0, min(1.0, x_center))
y_center = max(0.0, min(1.0, y_center))
width = max(0.0, min(1.0, width))
height = max(0.0, min(1.0, height))
if width > 0 and height > 0:
yolo_labels.append(f"0 {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}")
return yolo_labels
except Exception as e:
print(f"错误 in mask_to_bbox: {e}")
return []
def process_one_category(category_path, output_base, train_ratio=0.8):
"""处理单个类别"""
category_name = category_path.name
print(f"\n处理类别: {category_name}")
try:
# 创建输出目录
category_output = output_base / category_name
train_img_dir = category_output / 'images' / 'train'
train_label_dir = category_output / 'labels' / 'train'
val_img_dir = category_output / 'images' / 'val'
val_label_dir = category_output / 'labels' / 'val'
train_img_dir.mkdir(parents=True, exist_ok=True)
train_label_dir.mkdir(parents=True, exist_ok=True)
val_img_dir.mkdir(parents=True, exist_ok=True)
val_label_dir.mkdir(parents=True, exist_ok=True)
# 收集样本
test_dir = category_path / 'test'
gt_dir = category_path / 'ground_truth'
if not test_dir.exists():
print(f" 警告: {test_dir} 不存在")
return None
if not gt_dir.exists():
print(f" 警告: {gt_dir} 不存在")
return None
samples = []
for defect_dir in test_dir.iterdir():
if not defect_dir.is_dir():
continue
if defect_dir.name == 'good':
continue
for img_file in defect_dir.glob('*.png'):
mask_file = gt_dir / defect_dir.name / img_file.name.replace('.png', '_mask.png')
if mask_file.exists():
samples.append({
'img_path': img_file,
'mask_path': mask_file,
'name': img_file.name
})
if len(samples) == 0:
print(f" 警告: 没有找到缺陷样本")
return None
print(f" 找到 {len(samples)} 个样本")
# 划分数据集
random.seed(42)
random.shuffle(samples)
split_idx = int(len(samples) * train_ratio)
train_samples = samples[:split_idx]
val_samples = samples[split_idx:]
print(f" 训练集: {len(train_samples)}, 验证集: {len(val_samples)}")
# 处理训练集
train_count = 0
for sample in train_samples:
img = cv2.imread(str(sample['img_path']))
if img is None:
continue
labels = mask_to_bbox(sample['mask_path'], img.shape)
cv2.imwrite(str(train_img_dir / sample['name']), img)
if labels:
label_name = sample['name'].replace('.png', '.txt')
with open(train_label_dir / label_name, 'w') as f:
f.write('\n'.join(labels))
train_count += 1
# 处理验证集
val_count = 0
for sample in val_samples:
img = cv2.imread(str(sample['img_path']))
if img is None:
continue
labels = mask_to_bbox(sample['mask_path'], img.shape)
cv2.imwrite(str(val_img_dir / sample['name']), img)
if labels:
label_name = sample['name'].replace('.png', '.txt')
with open(val_label_dir / label_name, 'w') as f:
f.write('\n'.join(labels))
val_count += 1
# 创建配置文件
yaml_content = f"""# MVTec AD - {category_name}
path: {category_output.absolute()}
train: images/train
val: images/val
nc: 1
names: ['defect']
"""
with open(category_output / 'data.yaml', 'w') as f:
f.write(yaml_content)
print(f" ✅ {category_name} 完成: 训练{train_count}, 验证{val_count}")
return {
'name': category_name,
'train': train_count,
'val': val_count,
'total': len(samples)
}
except Exception as e:
print(f" 错误处理 {category_name}: {e}")
return None
def main():
print("进入主函数...")
parser = argparse.ArgumentParser(description='MVTec AD to YOLO Converter')
parser.add_argument('--input', '-i', type=str, required=True, help='MVTec AD根目录')
parser.add_argument('--output', '-o', type=str, default='./mvtec_separate', help='输出目录')
parser.add_argument('--train-ratio', type=float, default=0.8, help='训练集比例')
parser.add_argument('--seed', type=int, default=42, help='随机种子')
print("解析参数...")
args = parser.parse_args()
print(f"参数解析完成:")
print(f" input: {args.input}")
print(f" output: {args.output}")
print(f" train_ratio: {args.train_ratio}")
# 设置随机种子
random.seed(args.seed)
np.random.seed(args.seed)
print(f"\n开始转换...")
print(f"输入目录: {args.input}")
print(f"输出目录: {args.output}")
input_path = Path(args.input)
output_path = Path(args.output)
if not input_path.exists():
print(f"错误: 输入目录不存在: {input_path}")
return
print(f"输入目录存在: {input_path}")
# 创建输出目录
output_path.mkdir(parents=True, exist_ok=True)
print(f"输出目录已创建: {output_path}")
# 获取所有类别
categories = [d for d in input_path.iterdir() if d.is_dir() and not d.name.startswith('.')]
categories.sort()
print(f"\n找到 {len(categories)} 个类别")
for i, cat in enumerate(categories):
print(f" {i+1}. {cat.name}")
if len(categories) == 0:
print("错误: 没有找到任何类别文件夹")
print(f"请检查 {input_path} 目录下是否有子文件夹")
return
# 处理每个类别
results = []
for i, cat in enumerate(categories):
print(f"\n处理进度: {i+1}/{len(categories)}")
result = process_one_category(cat, output_path, args.train_ratio)
if result:
results.append(result)
# 打印总结
print("\n" + "="*60)
print("转换完成!")
print("="*60)
print(f"\n成功处理 {len(results)} 个类别")
print(f"输出目录: {output_path.absolute()}")
# 列出输出目录内容
print(f"\n输出目录内容:")
for item in output_path.iterdir():
if item.is_dir():
print(f" 📁 {item.name}/")
else:
print(f" 📄 {item.name}")
print("\n✅ 转换完成!")
if __name__ == "__main__":
print("脚本启动...")
main()
print("脚本结束...")3 已经转换成YOLO的txt格式的数据集
如果不想自己动手转换,可以直接在这里下载已经转换好的YOLO可使用的数据集。
转换好的NEU_DET数据集:https://download.csdn.net/download/Cupid_kl/92916045
转换好的GC10-DET数据集:https://download.csdn.net/download/Cupid_kl/92916325
转换好的MVTec_AD数据集:https://download.csdn.net/download/Cupid_kl/92916061