文本向量化
文本是由词和字组成的,想将文本转化为向量,首先要能够把词和字转化为向量
所有向量应该由同一维度n,我们可以称这个n维空间是一个语义空间

one - hot 编码
首先统计一个字表或词表,选出n个字或词
在对文本向量化时,也可以考虑词频
不错 0,0,0,1,0
不错不错0,0,0,2,0
有时也可以不事先准备词表,临时构建
如做文本对比任务,成对输入,此时维度可随时变化
one-hot编码 - 缺点:
1.如果有很多词,编码维度会很高,而且向量十分稀疏(大部分位置是零),计算负担很大
2.编码向量不能反映字词之间的语义相似性,只能做到区分



词向量-word2vec
我们希望得到一种词向量,使得向量关系能反映语义关系,比如:
cos(你好,您好)>cos(你好,天气)
即词义的相似性反映在向量的相似性
词向量- 基于语言模型
1.作出假设:
每段文本中的某一个词,由它前面n个词决定
模型是怎么做到输入一段文字,模型能预测出下一个字呢
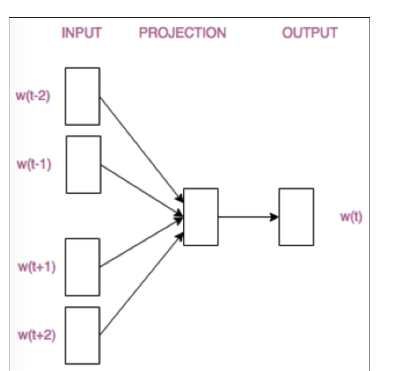
word2vec 基于窗口
1.做出假设:
如果两个词在文本中出现时,它的前后出现的词相似,则这两个词语义相似
不过也有问题 比如 我开心了一天,和我难过了一天·

词如何训练:
基于前述思想,我们尝试用窗口的词(或者说周围此)来表示(预测)中间词
CBOW模型
窗口: 你想(明白)了吗
输入:你想了吗
输出: 明白
或用中间词来表示周围词
SkipGram模型
窗口: 你想(明白)了吗
(输入,输出):
(明白,你)(明白,想) (明白,了)(明白,吗)
基于Huffman树的方法:
什么是Huffman树
不同词编码不同
每个词的编码不会成为另一个词编码的前缀
即如果某个词编码为011,则不能有词的编码是 0111或0110或011001等
- 构造出的词编码总体长度最小,且越高词频编码越短
如何构建
选取词频最低的两个节点,词频更低的放在左侧,较低的放在右侧,形成一个二叉树,顶点的值记录为二者频率之和
选择剩余词中词频最小的,将其与前两个词之和对比,仍然是小的放在左侧,形成树
形成如下

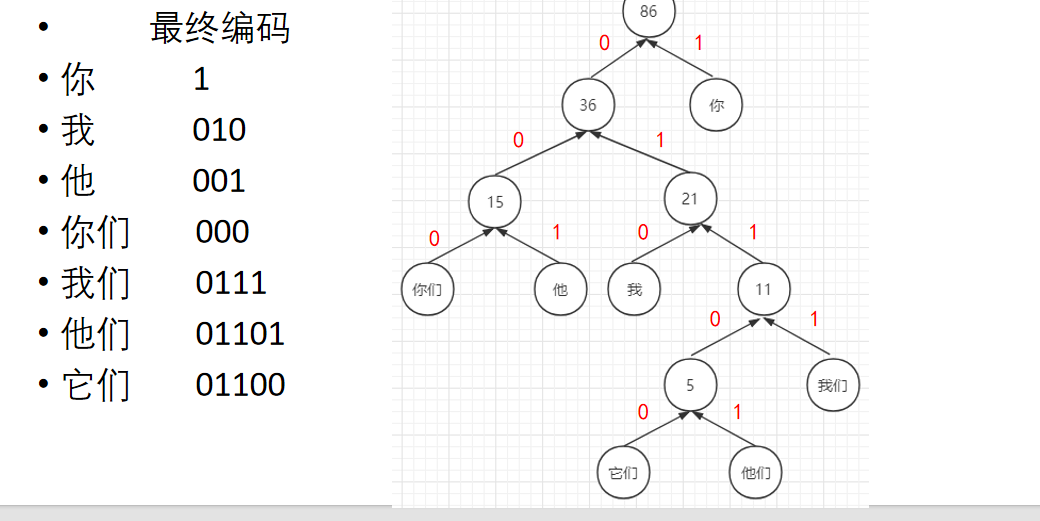
那怎么用于词向量的训练呢
我们之前要找一个,就比如他们,我们需要从7个词或字里面选,但现在只需要进行5次二分类就可以
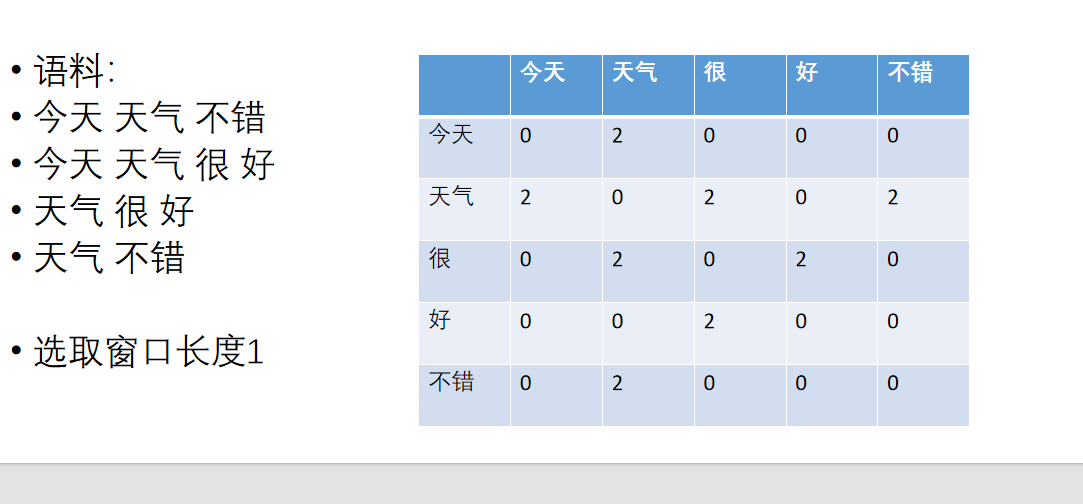
Glove基于共现矩阵
共现概率:
Pij = P(j|i) = xij / xi
词j出现在词i周围的概率,被称为词i和词j的共现概率 P(天气|今天) = 2/2 = 1
空格代表切分

词向量训练总结
一 : 根据词与词之间关系的某种假设,指定训练目标
二: 设定模型,以词向量为输入
三:随机初始化词向量,开始训练
四: 训练过程中词向量作为参数不断调整,获取一定的语义信息
五: 使用训练好的词向量做为下游任务
词向量应用 - 寻找近义词
输入: 红绕肉
注意:
依赖分词正确
与A最接近的词是B,不代表B最接近的是A
有时也会右反义词很相似
总会有很多badcase
词向量应用 - 句向量或文本向量
1.讲一句话或一段文本分成若干个词
- 找到每个词对应的词向量
3.所有词向量加和求平均或通过各种网络模型,得到文本向量
- 使用文本向量计算相似度或进行聚类
词向量应用 - KMeans
KMeans
随机选择k个点作为初始质心
repeat:
将每个点指派到最近的质心,形成k个簇
重新计算每个簇的质心
until
质心不发送变化
KMeans优点:
速度很快,可以支持大量的数据
样本均匀特征明显的情况下,效果不错
KMeans缺点:
人为设定聚类数量
初始化中心影响效果,导致结果不稳定
对于个别特殊样本敏感,会大幅度影响聚类中心位置
不适合多分类或样本较为离散的数据
KMeans一些使用技巧
1.先设定较多的聚类类别
聚类结束后计算类内平均距离
排序后,舍弃类内平均距离较长的类别
计算距离时可以尝试欧式距离,余弦距离或其他距离
短文本的聚类记得先去重,以及其他预处理