VAE 是一种生成模型,它通过学习一个连续的潜在分布(而不是固定编码),使可以从这个分布中采样并生成新数据
VAE(Variational AutoEncoder) = 一种可以"学会生成新数据"的概率模型
输入一个样本 → 学一个"潜在表示 z" → 再生成类似的样本
AutoEncoder(既有编码也有解码)
x → 编码 → z → 解码 → x' 压缩信息,然后还原数据
通过"重建误差"来约束 latent 表示是有意义的,z 的好坏是通过"解码是否能还原 x"来衡量的
普通 AE 做的事:x → 编码 → z → 解码 → x' 目标:让 x' ≈ x
Variational(变分)
不是学一个"确定的 z",而是学一个"分布",即 z ~ N(μ, σ²)
- μ(均值):这个分布的中心在哪
- σ(标准差):这个分布有多"宽"
本质是用"可优化的近似分布"去替代"难以计算的真实分布"
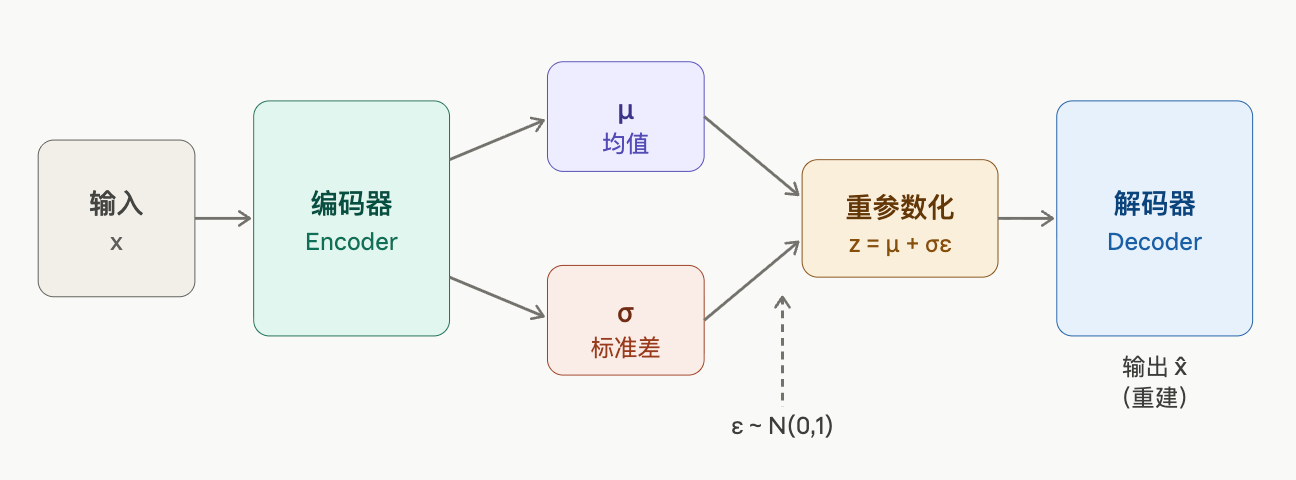
VAE 的核心结构
🔹 编码器(Encoder)
输入x,输出 μ(x), σ(x),表示这个样本在 latent space 的分布
🔹 采样
z = μ + σ * ε(ε ~ N(0,1)),让模型具有"随机性"
🔹 解码器(Decoder)
z → 生成 x'
1️⃣ 如果任务是"生成数据":解码是核心目标
2️⃣ 如果任务是"学表示(representation)":解码主要是一个训练约束
VAE 在做什么
把复杂数据(比如人体、图像)压缩到一个“连续空间 z”
在这个空间里可以: 插值、采样、生成新数据损失函数
VAE 的 loss 有两部分:
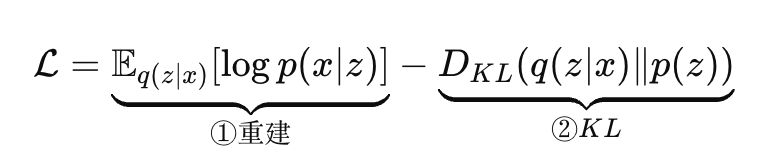
1️⃣ 重建误差
让生成的 x' 接近原始 x,保证z里有信息
让每个 x → 一个"独特的 z"(区分开)
2️⃣ KL 散度(重点)
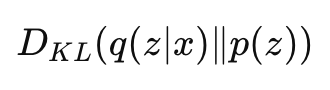
让 z 的分布接近标准正态 N(0,1),让 latent space连续、平滑、可采样'
不同 x 的 q(z|x):不要太分散、要互相重叠、要填满空间
如果没有KL散度的话,就只能重建 不能生成
让所有 z 像标准正态分布 N(0,1)(挤在一起、平滑)
既不能完全分开,也不能完全一样 ,二者共同作用形成一个"连续、可区分但不离散"的空间
核心目标
学一个"连续、可采样"的潜在空间,使可以从中生成新的数据
为什么要让不同x的z在隐空间里连续
VAE 不是为了"区分不同样本",而是为了"建模数据的分布并能生成新样本", 所以 z 的目标不是"彼此远离"(分类任务的目标),而是"形成一个连续、有结构的空间"
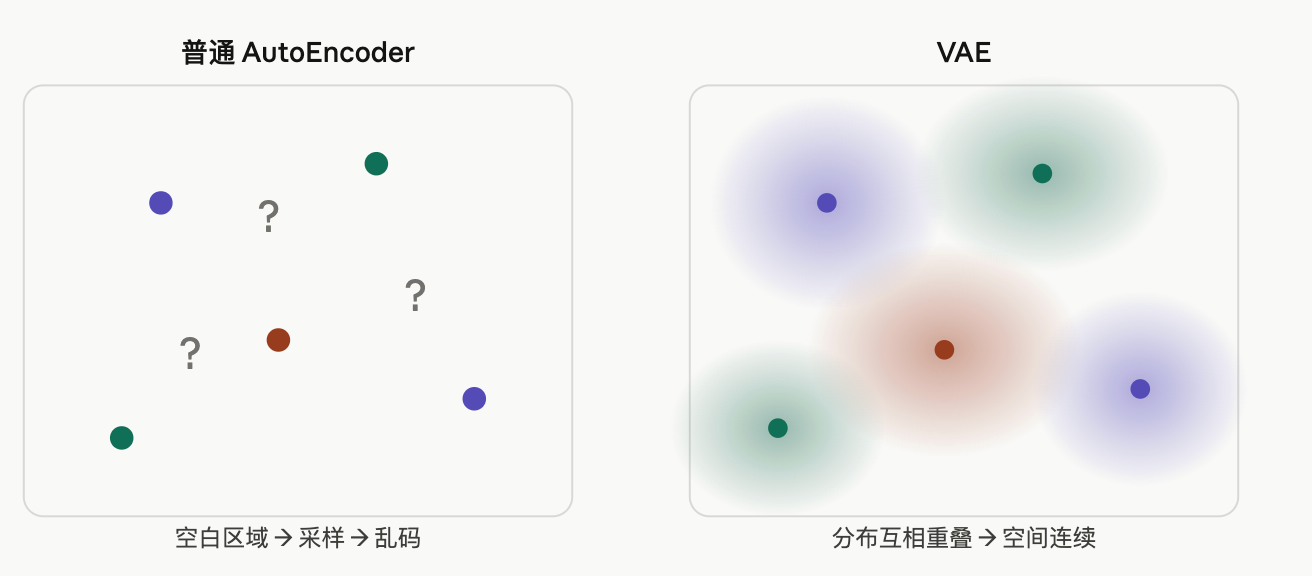
VAE 把每个数据点"涂抹"成一片分布,各个分布互相重叠,把空间填满。这样空间里任意一点解码器都见过(某个分布覆盖到了),采样出来就能得到有意义的结果。
如果每个 x → 一个完全不同、彼此很远的 z,latent space就会变成"离散点集",在几个孤立的点中间随机采样就会落在"空区域",decoder的输出将没有意义,无法生成新样本
举例:
如果:z1(一个人) ------ z2(另一个人)希望中间是"渐变的人"
如果空间不连续:中间没有语义 ❌ → 生成畸形
"z 差别越大越好"适用于判别模型,但 VAE 是生成模型,它需要的是"覆盖空间",而不是"拉开距离"