前言
上篇聊了 CC 的启动模式、CLAUDE.md 配置和多任务并发协同,都属于"怎么用"的层面。
这篇下篇深入一层,聊的是"怎么让 CC 更符合你的工作习惯":
- 记忆机制:让 CC 记住你的偏好,不用每次重复说
- 规则约束:给 CC 立规矩,让团队的编码规范落地
- 配置作用域:理解哪些配置是全局的,哪些是项目的
- 权限管理:在安全和效率之间找到平衡
- 快捷操作:一批能显著提升交互体验的快捷命令
记忆机制:让 CC 记住你的偏好
场景还原
假设你用 Python 开发一个项目,CC 每次执行代码时总是调用系统 Python,但你希望它在 conda 虚拟环境中运行,以保证隔离性。
你可以直接告诉 CC:"记住,这个项目始终使用 conda 环境中的 Python"。
CC 会把这个偏好保存到项目的 MEMORY 文件中。此后每次对话开始时,CC 都会读取这份记忆,作为提示词的一部分------它真的会"记住"。
记忆的工作原理
markdown
用户告诉 CC 偏好
│
▼
CC 将偏好写入 MEMORY 文件(项目级或全局级)
│
▼
下次对话开始时,CC 自动读取 MEMORY 文件
│
▼
记忆内容成为上下文的一部分,影响 CC 的行为什么适合存入记忆
- 环境偏好(用哪个 Python 环境、哪个 Node 版本)
- 命名习惯(变量命名风格、文件命名规则)
- 个人工作习惯(提交信息的格式偏好)
- 工具链选择(用 yarn 还是 npm,用 pytest 还是 unittest)
记忆是个人级或项目级的,不要把敏感信息(如 API key、密码)存入记忆文件。
规则约束:给 CC 立规矩
CLAUDE.md vs Rules:两本不同的书
前面说过 CLAUDE.md 是工程说明书,告诉 CC"这个工程是什么"。而 Rules 是另一本书------团队规范手册,告诉 CC"在这个工程里应该怎么做"。
类比:
- CLAUDE.md = 工程交接文档(讲工程结构、技术栈、构建命令)
- Rules = 团队代码规范(讲编码规则、测试要求、提交规范)
文件组织结构
bash
your-repo/
├─ CLAUDE.md # 项目事实(技术栈、常用命令、约束)
└─ .claude/
└─ rules/ # 底线规则(拆成小文件,按职责分类)
├─ security.md # 安全底线
├─ testing.md # 测试底线
└─ coding-style.md # 代码风格底线拆成小文件的好处:职责清晰、维护方便、便于团队分工管理。
规则文件示例
markdown
# 测试规范
## 单元测试
- 覆盖率:> 80%
- 框架:Jest + Testing Library
- 每个公共函数必须有测试
- 测试用例命名:`should ... when ...`
## 集成测试
- 工具:Cypress / Playwright
- 覆盖:关键用户流程
- 运行时机:PR 合并前
## TDD 流程
- RED:先写失败的测试
- GREEN:实现最小代码让测试通过
- REFACTOR:重构优化代码规则是团队共享资产
规则文件建议作为代码仓的一部分提交。如果在过程中发现 CC 做了与团队规范相冲突的事,**有义务**把对应约束加入 rules,并提交共享给团队。
这样做的价值:每个人接手项目后,CC 的行为都是一致的,不会因为个人使用习惯不同而产生差异。
配置作用域:知道配置生效在哪儿
CC 的各类配置(CLAUDE.md、Rules、Settings 等)都有作用域,不同作用域的配置有优先级关系。
作用域层级
bash
全局配置(~/.claude/) ← 最低优先级,影响所有项目
│
▼
项目配置(项目根目录/.claude/) ← 中等优先级,影响当前项目
│
▼
会话级配置(当前对话中指定) ← 最高优先级,仅当前会话有效实践建议
| 配置类型 | 建议放在哪里 | 原因 |
|---|---|---|
| 个人工具链偏好(conda、nvm 等) | 全局 ~/.claude/ |
所有项目通用 |
| 编码规范、测试规范 | 项目 .claude/rules/ |
团队共享,随仓提交 |
| 特定任务的一次性约束 | 会话中直接说明 | 不需要持久化 |
| 项目特定的权限配置 | 项目 settings.json |
按项目隔离 |
理解作用域之后,你就不会因为在全局配了某个规则、结果影响了所有项目而困惑,也不会在项目规则里写了全局都需要的东西却每个项目都得重复配一遍。
权限管理:在安全和效率之间找平衡
两个极端都不好
- 启动时加
--dangerously-skip-permissions:完全授权,CC 可以做任何事,高效但有风险 - 什么都不配置:每次读文件都要来问你,安全但极其烦人
真正好用的方式是精细化权限配置。
在 CC 中配置权限
在 CC 会话中输入 /permissions,可以在三类工具中做配置:
- 允许(Allow):直接执行,不询问
- 需要确认(Ask):每次执行前询问
- 禁止(Deny):永远不允许执行
Bash 命令的格式:Bash(命令:参数),* 代表所有参数。
直接修改 settings.json
json
{
"permissions": {
"allow": [
"Bash(cat:*)",
"Bash(ls:*)",
"Bash(grep:*)",
"Bash(git:status)",
"Bash(git:log:*)",
"Bash(git:diff:*)",
"Bash(npm:test)",
"Bash(npm:run:lint)"
],
"deny": [
"Bash(rm:-rf:*)",
"Bash(sudo:*)",
"Bash(mkfs:*)",
"Bash(dd:*)",
"Bash(curl:*:|:bash)",
"Bash(wget:*:|:sh)",
"Bash(reboot)",
"Bash(shutdown:*)"
]
}
}
json
{
"permissions": {
"allow": [
"Bash(npm:*)",
"Bash(yarn:*)",
"Bash(git:*)",
"Bash(docker:ps)",
"Bash(docker:logs:*)"
],
"deny": [
"Bash(docker:rm:*)",
"Bash(docker:rmi:*)"
]
}
}权限配置也要区分作用域:读写文件、运行测试这类操作放全局;特定项目的构建命令、容器操作放项目级,互不干扰。
快捷操作全览
这部分是工具性内容,记下来随时查用。
! ------ 不退出 CC 直接执行 Bash 命令
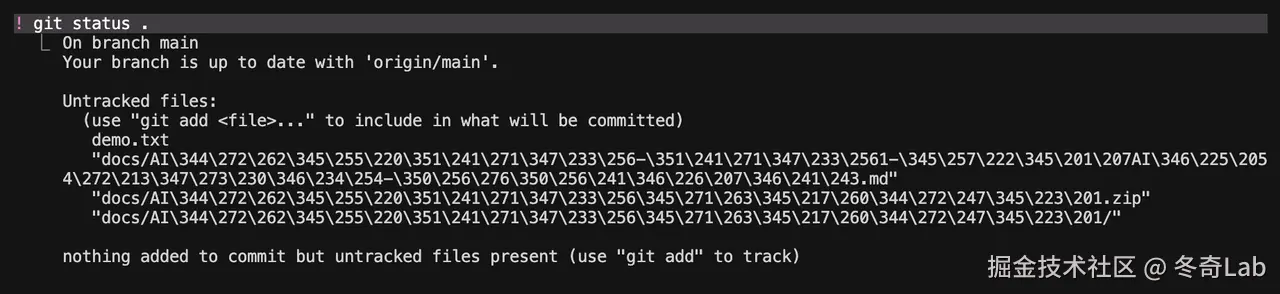
diff
! ls -la
! git status
! cat package.json不需要退出 CC 打开新终端,直接在 CC 内运行本地命令,结果立刻可见。
@ ------ 指定参考文件
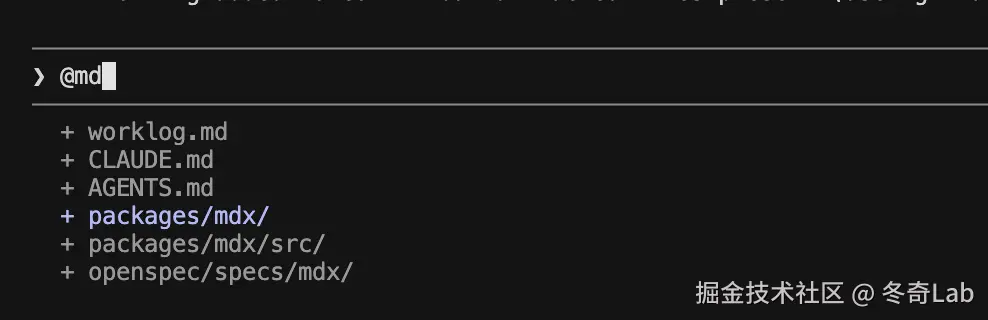
less
@src/components/Button.tsx 帮我给这个组件加上 loading 状态
@docs/api.md 按照这份 API 文档生成对应的 TypeScript 类型定义告诉 CC 精确去看哪个文件,支持路径匹配。比直接说文件名要准确,适合文件名不唯一或路径较深的场景。
/model ------ 按需切换模型
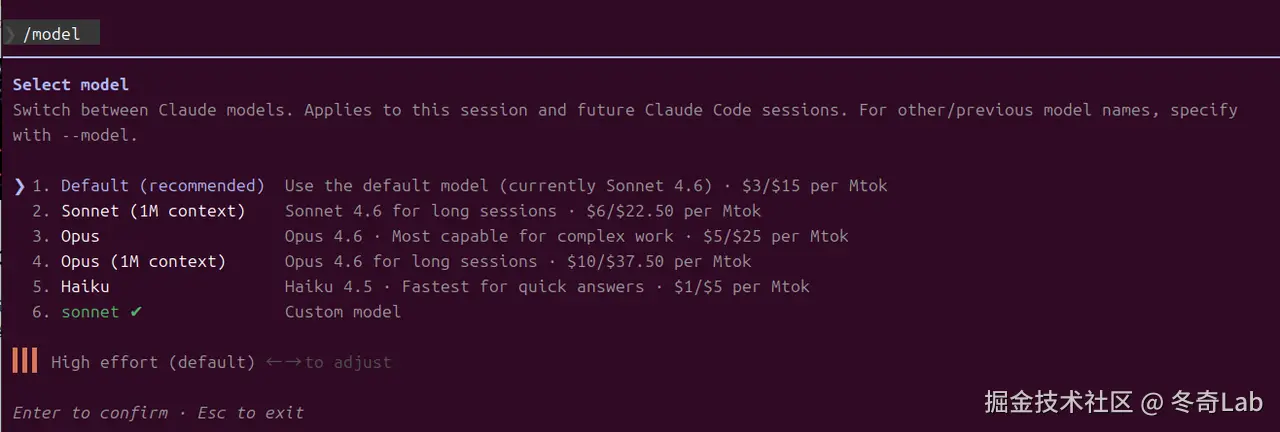
bash
/model打开模型选择菜单,可以切换模型以及配置思考等级。
三个思考等级:
| 等级 | 适用场景 |
|---|---|
| low | 简单问答、代码补全、文案修改 |
| medium | 一般功能开发、日常调试 |
| high | 复杂架构设计、难以复现的 Bug 分析、多模块联动 |
Opus 4.6 引入了 Adaptive Thinking(自适应思考) ------CC 会根据任务复杂度自动决定是否使用深度推理以及使用多少。你通过 effort level 来控制推理深度,而不再需要在提示词里写 think hard 或 ultrathink。
三种配置方式:
bash
# 方式 1:在 /model 菜单中用 ← → 箭头键调节滑块
/model
# 方式 2:环境变量
export CLAUDE_CODE_EFFORT_LEVEL=low # low | medium | high
# 方式 3:settings.json
# { "effortLevel": "high" }/cost ------ 查看本次任务的费用
bash
/cost显示当前会话消耗的 token 数量、调用的模型以及花费金额。
实际案例:分析一个 150MB 的黑屏日志,使用 Opus 模型,费用 1.9。如果换成Sonnet模型,相同任务可节省约401.18。
成本敏感的场景(比如长日志分析)优先考虑 Sonnet 而非 Opus,通常质量够用,成本显著降低。
/context ------ 查看 token 都用在哪儿了
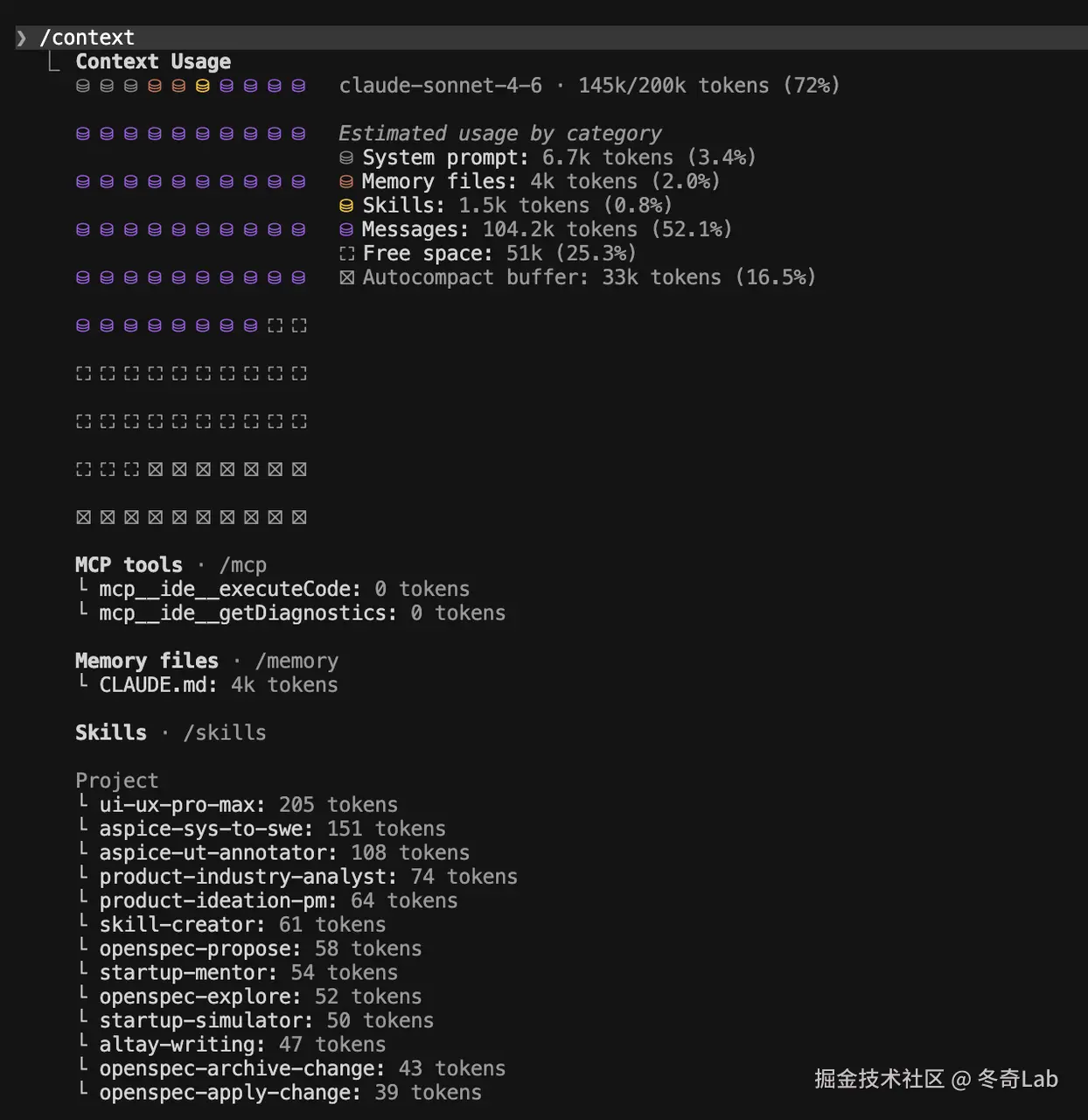
bash
/context详细展示当前 context 中各部分的 token 占用情况。在 skill 开发、Agent 开发和调试场景中特别有用------帮你找到"context 吃去哪了"。
Ctrl + S ------ 暂存当前输入
场景:正在输入一条长消息,突然想先切换个模型,但不想删掉已经写的内容。
Ctrl + S 暂存当前输入,执行完其他操作后,再次按 Ctrl + S 恢复输入内容。
/btw ------ 顺便问一下,不影响主对话
bash
/btw 刚才你用的那个 grep 命令,-P 参数是什么意思?这条提问会在一个"旁路"中处理,不会影响主对话的上下文和记忆 。看到回答后,按 Space、Enter 或 ESC 回到主对话继续进行。
适合临时查个命令用法、确认一个概念,不想污染主对话的场景。
/export ------ 导出对话内容
arduino
/export将当前对话导出到文件。适用于:保存一次有价值的调试过程、导出生成的文档或代码片段、记录一次复杂问题的分析结果。
Ctrl + R ------ 翻历史提示词
按 Ctrl + R 后输入关键词,可以在历史提示词中搜索,快速翻出之前用过的 prompt。
适用场景:找回一条复杂 prompt 复用或微调,避免重复编写。
配置全景图
总结一下所有配置项和它们的位置关系:
bash
~/.claude/
├─ settings.json # 全局设置(通知 hooks、全局权限、模型偏好)
├─ CLAUDE.md # 全局偏好(跨项目通用说明)
└─ rules/ # 全局规则(跨项目通用规范,较少用)
your-repo/
├─ CLAUDE.md # 项目说明书(技术栈、命令、约束)
└─ .claude/
├─ settings.json # 项目权限配置
└─ rules/ # 项目规范(随仓提交,团队共享)
├─ security.md
├─ testing.md
└─ coding-style.md总结
下篇补完了 CC 配置体系的另一半:
- 记忆机制:告诉 CC 你的偏好,它会记住并在每次对话中应用
- 规则约束:把团队规范写入 Rules,CC 的行为有了底线,且随仓共享
- 配置作用域:分清全局、项目、会话三个层级,配置放对地方
- 权限管理:精细化配置 allow/deny,比"全权限"和"全询问"都更好用
- 快捷操作 :
!、@、/model、/cost、/context、Ctrl+S、/btw、/export、Ctrl+R------每一个都能在对的场景下省不少事
上下两篇加在一起,基本覆盖了 CC 日常使用中"知道但不一定用好了"的那些点。工具的价值在于用,建议挑 1-2 个今天就能上手的点实际试一下。
如有问题或更好的用法,欢迎留言讨论!