去年公司做数据合规改造,审计要求"IP查询数据不能离开内网"。我们当时依赖第三方API,一夜之间面临停摆。最终我从零搭建了一套私有化IP查询平台,把整条链路跑通。本文记录这个过程中的核心环节和踩过的坑,希望能帮到同样需要内网IP服务的团队。
核心结论:自建IP查询平台的核心链路是"数据采集 → 清洗建库 → 索引优化 → API封装 → 定期更新"。通过采购商业IP离线库作为数据基底,配合内存映射和轻量级HTTP服务,一天内就能搭建出满足内网合规要求的私有化IP查询服务,查询延迟0.2ms以内,单机QPS可达250万以上。
一、通过商业离线库解决数据源问题
数据采集是自建平台最费劲的一环。公开数据源虽然免费,但质量参差不齐,需要大量清洗和校验。生产环境推荐直接采购商业IP离线库。
以IP数据云为例,其离线库提供20+维度的完整数据(地理位置、网络类型、风险评分、代理标签等),体积仅几MB,日更机制保证数据新鲜度。拿到离线库文件后,后续的建库和查询工作就变成了纯工程问题。
选择商业库的理由:
- 省去采集清洗的复杂链路,避免数据冲突和错误
- 内置代理识别、风险评分等高价值字段
- 支持私有化部署,数据完全闭环,满足合规审计
二、过程:建库与索引优化
拿到离线库文件后,需要将其加载到内存并提供高性能查询接口。
1. 数据结构设计
IP离线库的核心是一个有序的IP段数组,每条记录定长,通过二分查找快速定位。
c
typedef struct {
uint32_t start_ip; // 起始IP(网络字节序)
uint32_t end_ip; // 结束IP
uint16_t geo_id; // 地理位置ID(指向字符串表)
uint8_t net_type; // 网络类型:住宅/数据中心/企业
uint8_t is_proxy; // 代理标记
uint16_t risk_score; // 风险评分
} ip_record_t;每条记录约10-14字节。只保留国内常用段,记录数可压缩至30万条以内,体积控制在3-5MB。
2. 内存加载方式
使用mmap将IP库文件映射到进程地址空间,实现零拷贝加载,多进程共享同一份物理内存,按需加载。
c
#include <sys/mman.h>
#include <fcntl.h>
int load_ip_db(const char *path) {
int fd = open(path, O_RDONLY);
struct stat st;
fstat(fd, &st);
void *addr = mmap(NULL, st.st_size, PROT_READ, MAP_SHARED, fd, 0);
close(fd);
if (addr == MAP_FAILED) return -1;
g_records = (ip_record_t *)addr;
g_count = st.st_size / sizeof(ip_record_t);
return 0;
}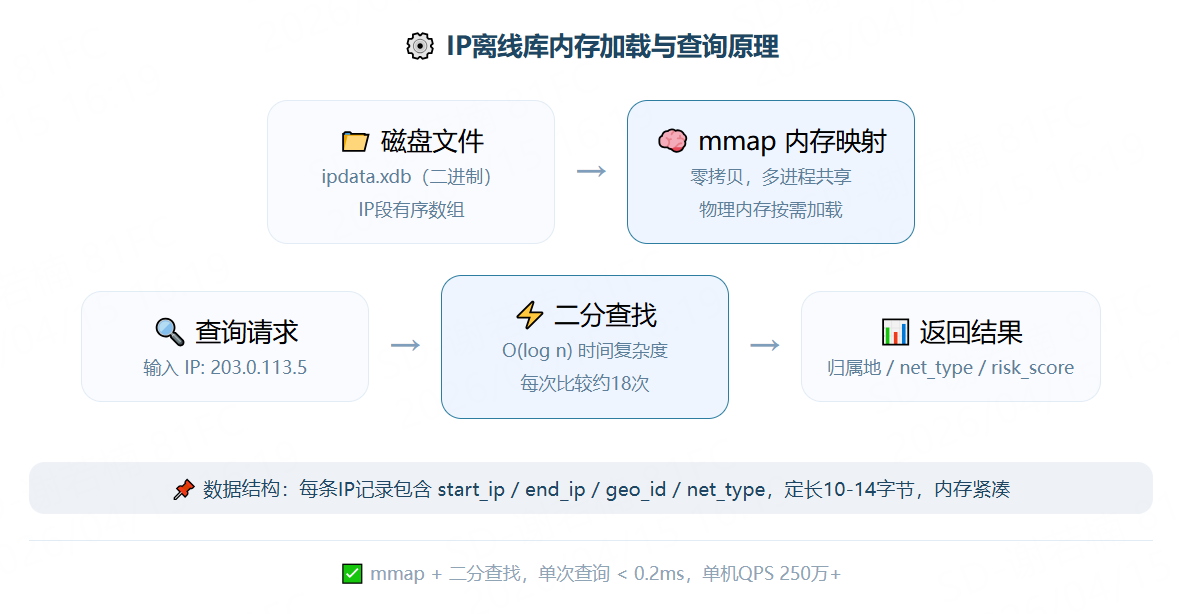
3. 二分查找实现
c
uint16_t lookup_ip(uint32_t ip) {
int left = 0, right = g_count - 1;
while (left <= right) {
int mid = (left + right) >> 1;
if (ip < g_records[mid].start_ip)
right = mid - 1;
else if (ip > g_records[mid].end_ip)
left = mid + 1;
else
return g_records[mid].geo_id;
}
return 0;
}三、解决:封装成API服务
将内存查询能力封装成HTTP API,供业务系统调用。
Python Flask 示例:
python
import ipdatacloud # IP数据云 SDK
from flask import Flask, request, jsonify
app = Flask(__name__)
# 服务启动时加载离线库到内存
db = ipdatacloud.IPDatabase.load("/data/ipdb/ipdata.xdb")
@app.route('/ip/query', methods=['GET'])
def query_ip():
ip = request.args.get('ip')
if not ip:
return jsonify({'error': 'ip required'}), 400
result = db.query(ip)
if not result:
return jsonify({'status': 'not_found'}), 404
return jsonify({
'ip': ip,
'country': result.country,
'province': result.province,
'city': result.city,
'net_type': result.net_type,
'risk_score': result.risk_score,
'threat_tags': result.threat_tags
})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8080)性能表现:
- 单次查询耗时 < 0.2ms
- 单机QPS 25万+(纯内存,无网络开销)
- 数据完全内网闭环,满足合规审计
四、过程:更新机制保持数据新鲜
IP段分配是动态变化的,需要定期更新离线库。
- 自动化脚本:每日凌晨从IP数据云获取最新离线库文件,校验完整性后替换旧文件
- 双区热切换:保留A/B两个版本,更新时写入备用分区,验证后原子切换符号链接,查询不中断
- 增量更新支持:只同步变化的部分,减少带宽和更新耗时
五、解决:完整的技术架构
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 业务服务器 │────▶│ HTTP API │────▶│ 内存离线库 │
│ (内网调用) │ │ (Flask) │ │ (mmap加载) │
└─────────────┘ └─────────────┘ └─────────────┘
│
▼
┌─────────────┐
│ 每日更新 │
│ (自动化) │
└─────────────┘所有组件部署在内网,IP查询不依赖外部网络,原始IP数据不出域。

六、总结
通过"采购商业离线库 + 内存加载 + HTTP封装"的路径,我们一天内就搭建了私有化IP查询平台,彻底解决了数据合规问题。
关键经验:
- 数据源选型决定项目成败,生产环境推荐直接使用商业IP离线库
- mmap内存加载 + 二分查找可实现0.2ms以内查询
- 双区热切换保证更新不中断
- 整体方案满足等保三级"数据本地化"要求
如果你也面临类似的合规需求或内网部署要求,不妨从采购一份IP数据云离线库开始,花一天时间把服务跑起来。剩下的,就是享受内网毫秒级查询的畅快。