通过本博客,只要具备基础矩阵乘法计算规则,可以清晰的了解搞懂为什么transform里是kv cache不是q cache?同时还可以理解为什么可以流式输出结果?为什么缓存命中价格更低?
transform中的attention
支撑整个 Transformer 架构最核心的运算单元,正是注意力机制(Attention Mechanism)。
Attention 本质上做一件事:
对序列中每个位置 ,计算它与序列所有位置 的关联程度(权重),然后用这些权重对所有位置的信息做加权求和。
在标准 Transformer 中,注意力机制通过**查询(Query)、键(Key)、值(Value)**三个线性变换向量实现。
- Q (Query):查询向量,表示 "当前我在查什么"
- K (Key):键向量,表示 "每个位置有什么信息"
- V (Value):值向量,表示 "每个位置实际要传递的信息"
数学上:,
,
,
- X:输入序列嵌入,形状 (N,
); N:序列长度;
标准 Scaled Dot-Product Attention(缩放点积注意力)公式:
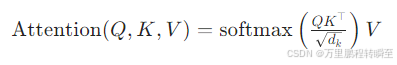
是 Q/K 向量的维度(通常
=
/h,h 为头数);当
很大时,QK点积结果会变得非常大,输入 softmax 后会导致梯度极小(饱和区),会使训练不稳定。
当在自回归生成 时,要防止模型看到未来 token,需要对QK点积结果进行上三角掩码。
在Transformer 结构里有 3 种注意力,需要区分清楚:
| 注意力类型 | 可见范围 | Mask 使用 | 数据来源 | 典型应用场景 |
|---|---|---|---|---|
| Encoder Self-Attention(编码器自注意力) | 双向可见,可关注整个序列所有位置 | 无 Mask | Q、K、V 均来自编码器输入 | 理解整句语义,如 BERT、ViT |
| Decoder Masked Self-Attention(解码器掩码自注意力) | 单向可见,只能看当前及之前的 token | 使用上三角 Mask,屏蔽未来位置 | Q、K、V 均来自解码器输入 | 自回归文本生成,如 GPT 系列模型 |
| Encoder-Decoder Attention(编码器 - 解码器交叉注意力) | 关注编码器全部序列 | 无 Mask | Q 来自解码器,K、V 来自编码器 | 序列到序列任务,如机器翻译、文本摘要 |
Transformer必须用KV Cache么?
首先需要明确,Transformer架构与KV Cache(键值缓存)之间并不存在必然的绑定关系------二者分属不同层面的技术概念,前者是深度学习的基础网络架构 ,后者是针对特定任务推理场景的优化手段,仅在特定类型的模型中才会结合使用。
具体来看,诸多基于Transformer模块构建的模型,均未引入KV Cache的概念。例如:
- 在计算机视觉领域的ViT(Vision Transformer)模型中,其核心组件是Transformer编码器,主要用于对图像分块后的序列进行特征提取与全局关联建模,由于图像数据的处理属于非自回归场景,无需逐token(图像块)生成,因此完全不需要KV Cache来缓存中间计算结果;
- 同样,在生成式图像模型(如Latent Diffusion Model,潜在扩散模型)中,尽管其文本编码器、图像生成器等部分可能包含Transformer结构,但该模型的生成逻辑基于扩散过程,通过迭代去噪完成图像生成,并非自回归生成模式,因此也不存在KV Cache的应用场景。
KV Cache的核心作用,是解决自回归生成过程中的重复计算问题,提升模型推理效率 ,因此其应用场景具有明确的局限性------仅在自回归式的LLM(大语言模型)中才会被广泛采用。如果不在意重复计算,即使在自回归的LLM模型中也不需要kv cache。
自回归LLM的核心特点是逐token生成文本(即后一个token的生成依赖前一个token的输出),在每次生成新token时,都需要基于历史token的键(Key)和值(Value)进行注意力计算,而KV Cache可将历史token的Key和Value缓存起来,避免每次生成新token时重复计算历史序列的注意力分数,从而大幅降低推理延迟、提升生成效率。
LLM中各类模型与kv cache如下
| 模型类型 | 结构 | 生成方式 | 是否需要 KV Cache |
|---|---|---|---|
| BERT / ViT | Encoder-only | 非自回归 | 不需要 |
| 扩散模型 Transformer | 非自回归去噪 | 并行迭代 | 不需要 |
| GPT / LLaMA | Decoder-only | 自回归逐 token | 可以用 KV Cache加速 |
| T5 / 翻译模型 | Encoder-Decoder | 目标端自回归 | 目标端需要 |
为什么没有Q cache?
decoder-only的大模型在进行训练时只进行了单个token的预测,具体可以查看LLM训练基本知识的深入浅出-CSDN博客。在进行实际应用中则是链式生成,输出n个token则需要进行n词推理。输出首个token被称作为prefill阶段(通常用首token耗时指标衡量),输出后续token被称作为decode阶段(通常用每秒输出多少token衡量)。具体可以查阅
大模型推理中Prefill与Decode、KV Cache三者说明_大模型prefill-CSDN博客
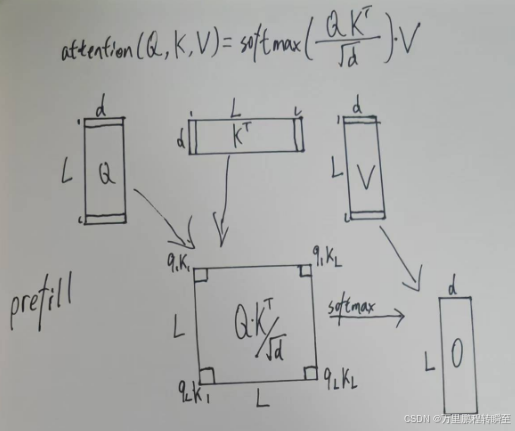
以下是QKV三个值在prefill阶段的运行示意,模型一次性处理L个输入token,通过三个权重矩阵,分别得到,
,
最后通过矩阵乘法得到O,然后计算出下一个token的值,即输出首token。以下示意图忽略了上三角 Mask。
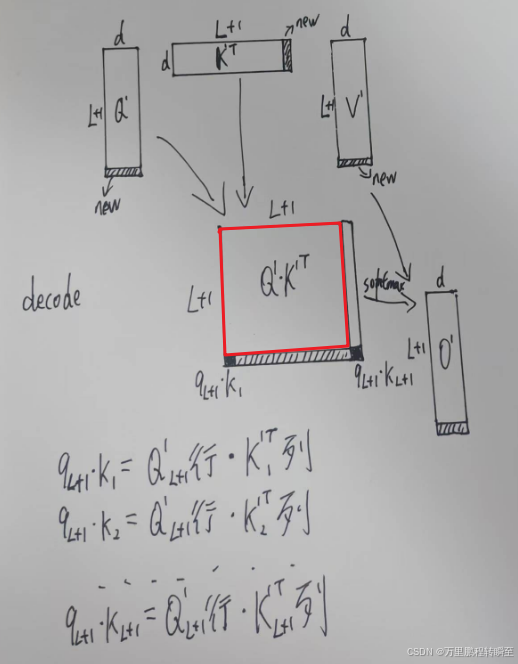
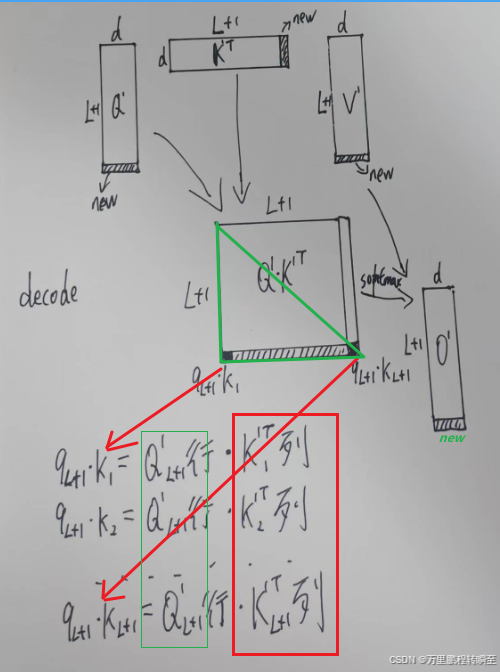
当首token输出后,与输入token拼接在一起(不考虑kv cache),得到,在按照原来的逻辑进行attention计算,此时可以发现新的计算结果里红色框的部分与上一次的输出结果完全相同【按照矩阵乘法规则(S=AB,A为左矩阵,B为右矩阵,S为结果矩阵),A第N+1行的值,只影响S第N+1行的值,B第N+1列的值只影响S第N+1列的值】,也就是说结果矩阵
里面**,只有最下面的一行和最右边的一列是需要重复计算的。**
然后在decoder-only系列大模型里面,对于实际上是有因果mask的,避免当前的qk看到未来的值,因此实际上的结果如下,绿色的三角形部分才有输出值。而最右边的一列(除最后一个值)完全被mask掉, 实际上是不需要参加计算的。此时只有最底下的一行需要重新计算生成。
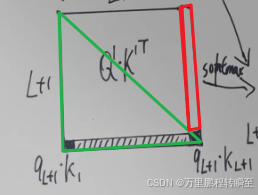
根据矩阵乘法,可以发现最底下一行,只有的L+1(最新)行参与计算,K的所有列全部参与了计算。此时可以发现
的前L行(历史值)是完全不需要参与最新行的计算,因此不需要Q cache,而右矩阵K的所有列都参与了计算,所以需要K cache避免重复计算。没有k cache则需要重新生成K的历史值。同理,在后续与
的矩阵乘法中,
也是作为一个右矩阵参与运算,因此
的所有列都需要参与到最新一行结果的输出中,所以需要V cache避免重复计。
所有决定了只有KV cache没有Q cache的本质原因就是 :decoder-only模型的因果mask约束与矩阵乘法的规则共同影响。生成新的token只需要当前的q,不需要历史q;而kv作为右乘矩阵,每一列的值都影响了最新行(当前要预测的token)的结果,所有需要缓存加速推理。
为什么可以流式输出结果?
在普通的decode-only大模型使用感受中,给定一个任务,模型输出一个答复。用户体验中,模型只推理了一次,而实际在推理代码中,大模型在while True死循环中推理了N次,直到输出结束符。因为因果mask的制约, 未来生成的值是不会影响到当前生成的值,即当前生成第n个token值是确定值,不受第n+1个值的影响。
因此,已经确定的第n个值可以先输出给用户。
生成首个token是处于prefil阶段,模型可以并行处理,算力成本低;但后续token生成时decode阶段,模型只能顺序输出,算力成本高;因此大模型api对于输入token与输出token的计费模式不一样。考虑到这种算力需求差异,当前衍生了PD分离推理的优化策略。具体可以查阅大模型推理中Prefill与Decode、KV Cache三者说明_大模型prefill-CSDN博客
为什么缓存命中价格更低?
缓存命中实际上就是前缀匹配,也就是说我当前的请求输入的前M个字符与上一次请求输入的K个字符,从第0个位置起有N个字符是完全一样的,这N个字符被称为缓存命中,调用的价格会很低很多。
前缀匹配逻辑 :系统自动比对请求前缀,相同部分直接复用缓存,仅处理新增后缀。推荐将静态内容(如系统提示、固定文档)前置 、动态查询后置,最大化匹配长度。
缓存命中的前提条件是**持久化 KV 缓存,**服务器保存了最近输入请求时生成的kv cache,当一个新的请求输入进行后,计算出其与多个历史缓存的共同最大前缀,然后基于共同前缀的长度对KV cache进行复用。节省了这一部分的计算成本,因此价格会有所降低。