CogVideoX ------ 基于 Expert Transformer 的文本生成视频扩散模型
1. 这篇论文在做什么?
这篇论文提出了 CogVideoX,一个大规模文本生成视频模型。它的目标是生成更长、更清晰、更连贯的视频。
论文中给出的能力是:
- 可以生成 10 秒连续视频
- 帧率为 16 fps
- 分辨率最高达到 768 × 1360
- 支持文本生成视频,也支持图像生成视频
- 发布了 2B 和 5B 两个规模的模型
过去很多 text-to-video 模型的问题是:
- 视频时间短,通常只有几秒;
- 动作幅度小,经常像"动图"而不是真正的视频;
- 长时间生成时,主体容易漂移、变形、不一致;
- 文本和视频的语义对齐不够好;
- 视频训练数据质量差,caption 太短或不准确。
CogVideoX 的核心目标就是解决这些问题:
生成长时长、高分辨率、动作丰富、语义对齐更好的视频。
2. 一句话总结 CogVideoX
CogVideoX 的核心可以概括为:
用 3D VAE 把视频压缩到更短的 latent 序列,用 Expert Transformer 深度融合文本和视频 token,再通过多分辨率、多时长的训练策略,让模型能稳定生成长视频。
它不是单纯把图片扩散模型改成视频模型,而是从以下几个方面都做了专门设计:
- 视频压缩:3D Causal VAE
- 主干模型:Expert Transformer
- 位置编码:3D RoPE
- 注意力机制:3D Full Attention
- 训练策略:Multi-Resolution Frame Pack + Progressive Training
- 数据处理:视频过滤 + 稠密视频 caption 生成
- 扩散目标:使用 v-prediction + zero SNR
3. 整体架构
CogVideoX 的整体架构如下:
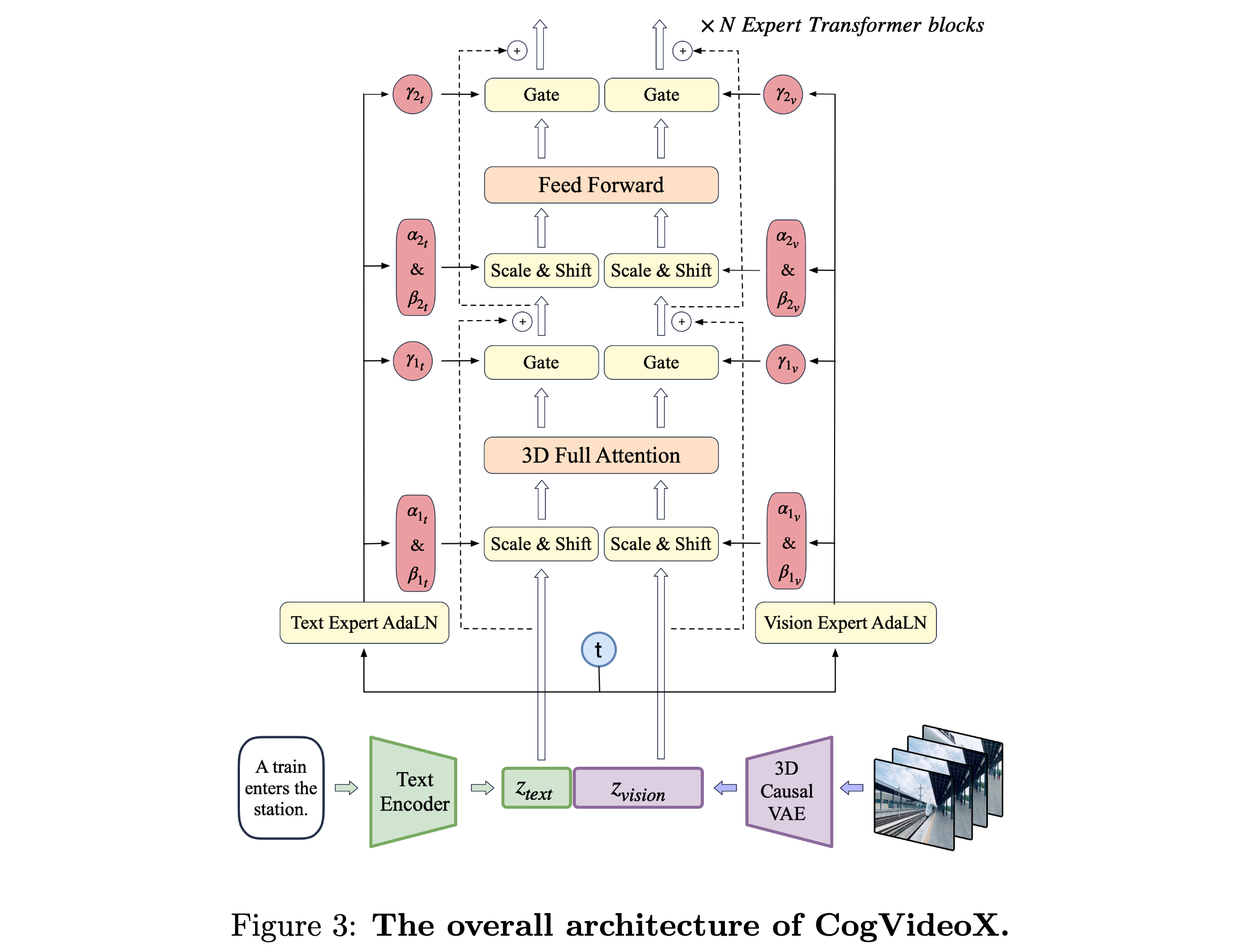
文本和视频 latent 会被拼接成一个长序列,然后一起送进 Transformer 里建模。
这里有两个关键点:
- 视频不是直接在像素空间建模,而是先通过 VAE 压缩到 latent space;
- 文本和视频 token 不是通过简单 cross-attention 融合,而是在同一个序列里进行深度融合。
4. 3D Causal VAE:为什么视频需要专门的 VAE?
4.1 传统 2D VAE 的问题
在图像生成模型里,常见做法是使用 2D VAE,把图片压缩到 latent space。
但是视频不仅有空间维度,还有时间维度。
如果直接对每一帧使用 2D VAE,就会有两个问题:
-
没有利用时间冗余
相邻帧之间通常很相似,如果只按单帧压缩,会浪费大量计算。
-
容易出现闪烁 flickering
因为每一帧单独编码和解码,帧与帧之间的连续性不一定好。
所以 CogVideoX 使用了 3D Causal VAE。
4.2 3D VAE 做了什么?
3D VAE 同时在空间和时间维度上压缩视频。
论文中采用的压缩比例是:
text
8 × 8 × 4也就是:
- 高度压缩 8 倍
- 宽度压缩 8 倍
- 时间维度压缩 4 倍
这样可以显著减少视频 latent 的长度,从而降低 Transformer 的计算压力。
4.3 为什么是 Causal?
CogVideoX 的 VAE 使用了 temporally causal convolution。
Causal 的意思是:
当前时刻的表示不能看到未来帧的信息。
这类似语言模型里的 causal attention:
生成当前 token 时不能偷看未来 token。
在视频里这样做的好处是:
- 保证时间方向上的一致性;
- 避免未来帧信息泄漏到当前帧;
- 更适合长视频建模。
4.4 VAE 实验结论
论文比较了不同 3D VAE 设置,发现:
- 使用 3D 结构后,视频重建的 flickering 明显降低;
- 增加 latent channel 可以提升重建质量;
- 但过度压缩,例如
16 × 16 × 8,会让模型很难收敛。
所以 CogVideoX 最终选择了一个折中方案:
text
Compression: 8 × 8 × 4
Latent channel: 16我的理解是:
视频生成模型的 VAE 不只是为了压缩,更重要的是要保证时间连续性。
如果 VAE 本身重建出来的视频就会抖动,那么后面的 diffusion model 再强也会受到影响。
5. Expert Transformer:文本和视频怎么融合?
论文提出了 Expert Transformer。
它的核心设计包括:
- Patchify
- 3D RoPE
- Expert Adaptive LayerNorm
- 3D Full Attention
6. Patchify:把视频 latent 变成 token 序列
3D VAE 输出的视频 latent 形状可以表示为:
text
T × H × W × C其中:
T是时间长度;H和W是空间尺寸;C是 latent channel 数。
接着模型会把这个 latent patchify 成一个长序列:
text
z_vision文本则通过 T5 encoder 得到:
text
z_text最后把两者拼接起来:
text
[z_text, z_vision]然后送入 Transformer。
7. 3D RoPE:视频位置编码不能只看二维
普通图像模型只需要处理二维空间位置,例如:
text
x, y但视频还有时间维度,所以每个 video token 的位置其实是:
text
x, y, tCogVideoX 把 RoPE 扩展到了三维,称为 3D-RoPE。
它把 hidden dimension 分成三部分,分别建模:
- x 方向位置
- y 方向位置
- t 时间位置
论文中的比例是:
text
x : y : t = 3/8 : 3/8 : 2/8这样模型就能同时知道:
- 这个 patch 在画面中的哪个位置;
- 它属于视频的哪一帧;
- 不同帧之间的相对时间关系。
8. Expert AdaLN:为什么要给文本和视频不同的 LayerNorm?
CogVideoX 把文本 token 和视频 token 拼在同一个序列里,这样可以增强文本和视频的融合。
但问题是:
文本 embedding 和视频 latent embedding 来自完全不同的模态,它们的特征空间和数值分布可能差异很大。
如果直接混在一起过同一个 LayerNorm,可能不够合适。
所以论文提出了 Expert Adaptive LayerNorm。
简单理解就是:
text
文本 token 用 Text Expert AdaLN
视频 token 用 Vision Expert AdaLN它们共享 Transformer 的主体结构,但在归一化和调制时分别处理不同模态。
这和 MMDiT 有点像,都是为了处理多模态特征差异。
但 CogVideoX 的做法更轻量,不需要为文本和图像分别搞两套完整 Transformer。
我的理解:
Expert AdaLN 的核心作用是:
保留文本和视频 token 的深度融合,同时又避免两种模态在特征分布上的冲突。
9. 3D Full Attention:为什么不用空间注意力 + 时间注意力拆开做?
很多视频生成模型为了省计算,会把注意力拆成:
text
空间注意力 + 时间注意力也就是先在每一帧内部做空间 attention,再跨帧做 temporal attention。
这种方法计算更省,但论文认为它有一个重要问题:
对于大幅度运动,拆分注意力会让相邻帧中的同一物体难以直接对齐。
比如一个人从左边移动到右边,如果用分离的空间/时间注意力,模型可能需要通过背景 patch 间接传递信息。
这会增加学习难度,也容易导致主体不一致。
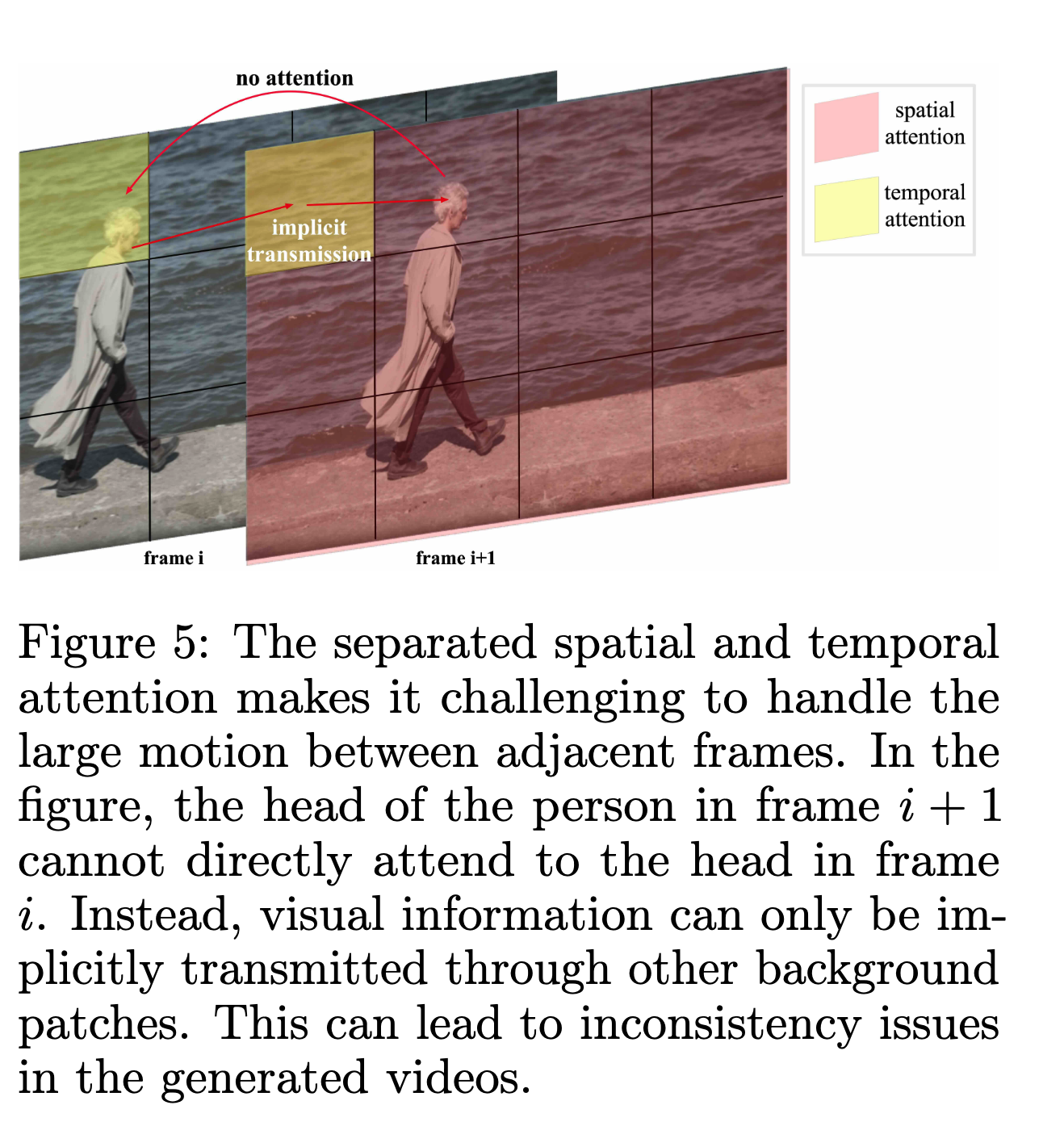
所以 CogVideoX 选择使用 3D Full Attention。
也就是说,视频 token 在时间和空间维度上一起做 attention。
优点:
- 更适合大动作视频;
- 更容易保持主体一致性;
- 有助于建模复杂动态变化。
缺点也很明显:
- 计算量更大;
- 序列长度非常长;
- 需要 FlashAttention 等优化技术支持。
论文的实验也显示,3D Full Attention 比 2D + 1D attention 更稳定,后者甚至容易训练崩掉。
我的理解:
视频生成不是简单地让图片"动起来",而是要建模时空连续变化。
如果动作幅度很大,拆开的空间/时间注意力可能不够直接,3D Full Attention 虽然贵,但更符合视频建模需求。
10. 训练目标:v-prediction + zero SNR
论文中提到 CogVideoX 采用了:
text
v-prediction + zero SNR在 diffusion 里,如果:
text
x_t = α_t x_0 + σ_t ε那么 v-prediction 通常预测的是:
text
v = α_t ε - σ_t x_0也就是说,模型不直接预测噪声 ε,也不直接预测干净样本 x_0,而是预测二者的一个组合。
这样做的好处是:
- 在不同噪声强度下训练更稳定;
- 高噪声和低噪声阶段的目标尺度更平衡;
- 在图像和视频扩散模型里都比较常见。
11. Multi-Resolution Frame Pack:解决不同时长、不同分辨率视频训练问题

视频数据有一个很麻烦的问题:
- 有的视频很短;
- 有的视频很长;
- 有的是横屏;
- 有的是竖屏;
- 分辨率也不一样。
如果训练时固定帧数,就会导致:
- 短视频需要 padding;
- 长视频需要截断;
- 很多视频数据不能被充分利用;
- 图像和视频的 token 数差异太大,模型可能学成两种模式。
CogVideoX 提出了 Multi-Resolution Frame Pack。
它的思路类似把不同长度、不同分辨率的视频 pack 到同一个 batch 里,让 batch 内的 token 形状更统一。
简单理解:
text
image + short video + medium video + long video
↓
pack 到一个 batch 里训练这样做的好处是:
- 可以同时训练图像和视频;
- 可以充分利用不同时长的视频;
- 不需要简单粗暴地裁剪所有视频;
- 增强模型对不同分辨率和不同时长的泛化能力。
12. Progressive Training:从低分辨率到高分辨率
直接训练高分辨率视频非常贵,而且互联网上很多视频本来质量就不高。
所以 CogVideoX 使用了渐进式训练:
text
256px → 512px → 768px低分辨率阶段主要学习:
- 语义
- 动作
- 粗粒度结构
- 低频信息
高分辨率阶段主要学习:
- 细节
- 纹理
- 清晰度
- 高频信息
最后还会用高质量数据进行 fine-tuning。
论文中提到,高质量 fine-tuning 可以减少字幕、水印、低码率视频带来的问题,并略微提升视觉质量。
但同时也观察到语义能力会有轻微下降。
这个现象很有意思:
高质量数据往往更干净,但可能分布更窄,所以模型的语义泛化能力可能会稍微变弱。
13. Explicit Uniform Sampling:让 timestep 采样更均匀
扩散模型训练时需要随机采样 timestep。
通常做法是每个 GPU rank 独立从 [1, T] 中均匀采样。
理论上这是均匀的,但实际训练中,因为每个 batch 样本有限,采样可能不够稳定。
而不同 timestep 的 loss 数值差异比较大,所以如果 timestep 采样波动较大,训练 loss 也会波动。
CogVideoX 提出 Explicit Uniform Sampling:
假设有 n 个 data parallel rank,就把 timestep 区间分成 n 段:
text
rank 1 采样区间 1
rank 2 采样区间 2
...
rank n 采样区间 n这样每个 step 里,整体 timestep 覆盖会更加均匀。
论文实验显示,这种方式可以:
- 让 loss 曲线更稳定;
- 加速收敛;
- 在不同 timestep 上都取得更低 loss。
我的理解:
这是一个很工程化但很实用的技巧。
它没有改变 diffusion 的理论目标,而是减少了分布式训练中的采样随机性。
14. 数据处理:视频过滤和视频 Caption 非常重要
我觉得这篇论文另一个很重要的点是:
它不只是讲模型结构,也花了很多篇幅讲数据。
14.1 视频过滤
原始互联网视频质量很复杂,包括:
- 人工剪辑视频;
- 静态图片拼接视频;
- 低清晰度视频;
- 镜头晃动严重的视频;
- 讲座、直播类视频;
- 大量文字或字幕的视频;
- 手机/电脑录屏视频。
这些数据对视频生成模型不一定有帮助,甚至可能有害。
CogVideoX 定义了多个负面标签:
text
Editing
Lack of Motion Connectivity
Low Quality
Lecture Type
Text Dominated
Noisy Screenshots然后用 Video-LLaMA 训练分类器来过滤低质量视频。
最终得到约:
text
35M single-shot clips平均长度约 6 秒。
此外,它还使用了:
text
2B images来自 LAION-5B 和 COYO-700M,用于辅助训练。
14.2 视频 Caption 生成
视频生成模型高度依赖 text-video pair。
但互联网视频的 caption 往往很短,比如:
text
A dog is running.这种 caption 对训练高质量 text-to-video 模型是不够的,因为它没有描述:
- 主体外观;
- 动作过程;
- 背景环境;
- 镜头运动;
- 时间变化;
- 物体交互。
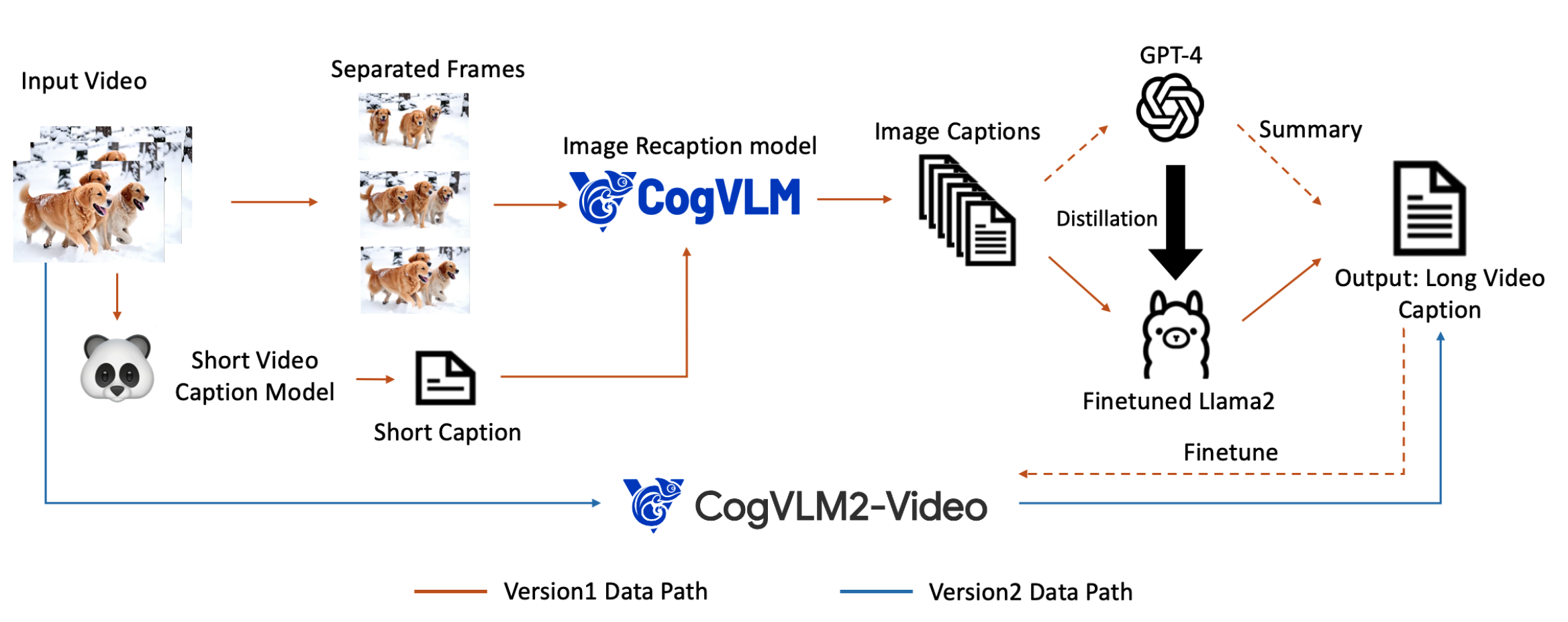
CogVideoX 构建了一个 dense video caption pipeline:
- 使用 Panda70M 模型生成短视频 caption;
- 抽取视频帧;
- 使用 CogVLM 生成每一帧的详细 image caption;
- 使用 GPT-4 总结成最终 video caption;
- 再用 GPT-4 生成的数据 fine-tune LLaMA2,加速大规模 caption 生成;
- 进一步训练 CogVLM2-Caption,做端到端视频理解和 caption。
15. 实验结果
论文主要从自动指标和人工评估两个方面进行实验。
15.1 自动评估
使用的指标包括:
- Human Action
- Scene
- Dynamic Degree
- Multiple Objects
- Appearance Style
- Dynamic Quality
- GPT4o-MTScore
这些指标主要关注视频生成中的:
- 动作能力
- 场景质量
- 动态程度
- 多物体生成
- 风格表现
- 时间变化幅度
论文中 CogVideoX-5B 在 7 个指标中的 5 个上达到最优,另外两个也有竞争力。
特别值得注意的是,CogVideoX 在动态相关指标上表现较好。
这说明它不是单纯生成清晰但静态的视频,而是更强调 motion 和 temporal consistency。
15.2 人工评估
论文还和闭源模型 Kling 做了人工对比。
人工评估维度包括:
- Sensory Quality:感官质量
- Instruction Following:指令遵循
- Physics Simulation:物理模拟
- Cover Quality:封面质量
结果显示 CogVideoX-5B 在这些维度上都优于 Kling。