做离线语音转写服务的同学应该都深有体会,静音幻觉、时间戳不准、并发上来就崩 ,这三大问题几乎是所有本地 ASR 项目的 "拦路虎"。最近在打磨公司内部熙瑾会悟 离线会议转写系统时,我们就完整踩了一遍坑,从静音幻觉修复、Qwen-ASR 模型集成、时间戳对齐,到实时会议迁移与高并发优化,一步步把系统从 "勉强能用" 打磨到 "稳定可靠"。
现在就把完整踩坑过程、技术方案和优化细节一次性讲透,偏向实战落地,适合做语音识别、离线转写、会议系统的后端 / 算法同学参考。
一、项目背景:熙瑾会悟离线转记需求
我们内部的熙瑾会悟 主要面向企业本地私有化部署场景,核心需求很明确:
- 纯离线运行,不依赖外网 API;
- 支持实时麦克风流 + 本地音视频文件转写;
- 转写结果带精准时间戳,方便后期剪辑、字幕生成;
- 支持多会议室同时接入,高并发下不卡顿、不丢包。
初期我们先用开源 ASR 做了一版原型,但上线后问题集中爆发:
- 静音段频繁出现无意义文字,也就是典型的静音幻觉 ;
- 时间戳错位严重,说话内容和时间轴对不上,回放体验极差;
- 实时流转写延迟高,并发超过 3 路直接 OOM;
- 模型推理效率低,CPU 环境下跑不动。
于是我们决定基于Qwen-ASR 重新构建离线转写核心,并针对性解决上述问题。
二、静音幻觉问题根源与修复方案
1. 什么是静音幻觉?
简单说就是:明明没人说话,ASR 却凭空识别出一些字词 ,比如 "嗯""啊""那个" 甚至完整句子,严重影响转写可读性。
根源主要有几个:
- VAD(语音活动检测)阈值设置不合理,把环境噪音误判为语音;
- 模型对静音 / 噪声特征学习不充分,泛化出错误文本;
- 前端信号预处理不足,底噪、电流声未被过滤。
2. 实战修复方案
我们采用三层降噪 + VAD 增强 的组合方案:
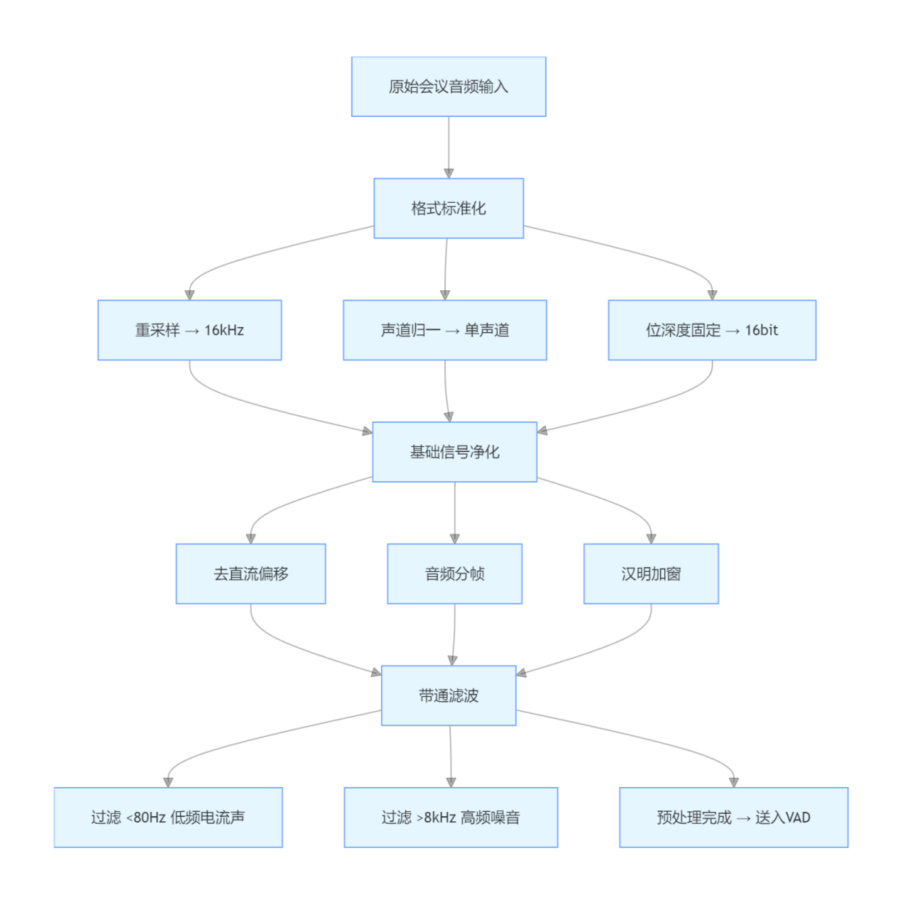
(1)前端音频预处理
使用WebRTC VAD + libsamplerate 做前端处理:
-
采样率统一重采样为 16kHz,单声道,16bit;
-
对音频做分帧、加窗、去直流偏移;
-
过滤掉低于 80Hz 的低频电流声和高于 8kHz 的高频噪音。
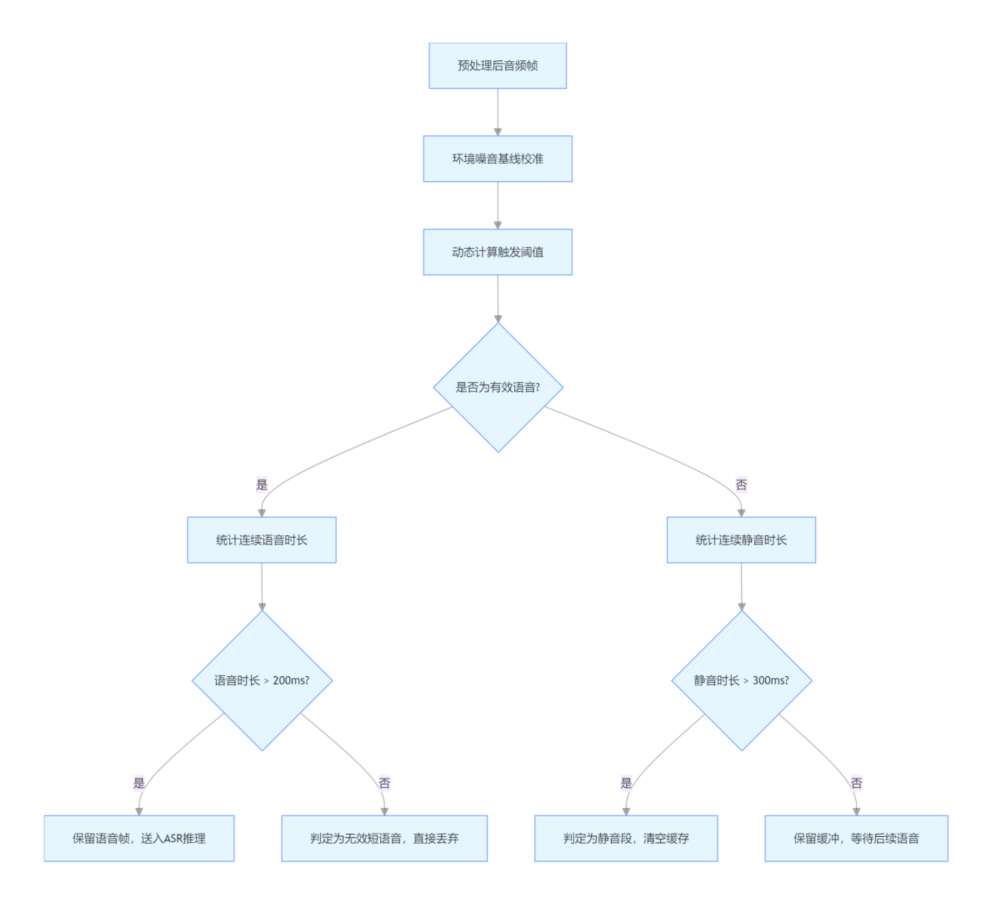
(2)VAD 阈值动态调整
固定阈值在不同设备上适配很差,我们改为:
- 基于环境噪音强度动态计算触发阈值 ;
- 连续静音帧超过 300ms 才判定为静音,直接丢弃该段特征;
- 对极短语音(<200ms)直接过滤,避免误识别。
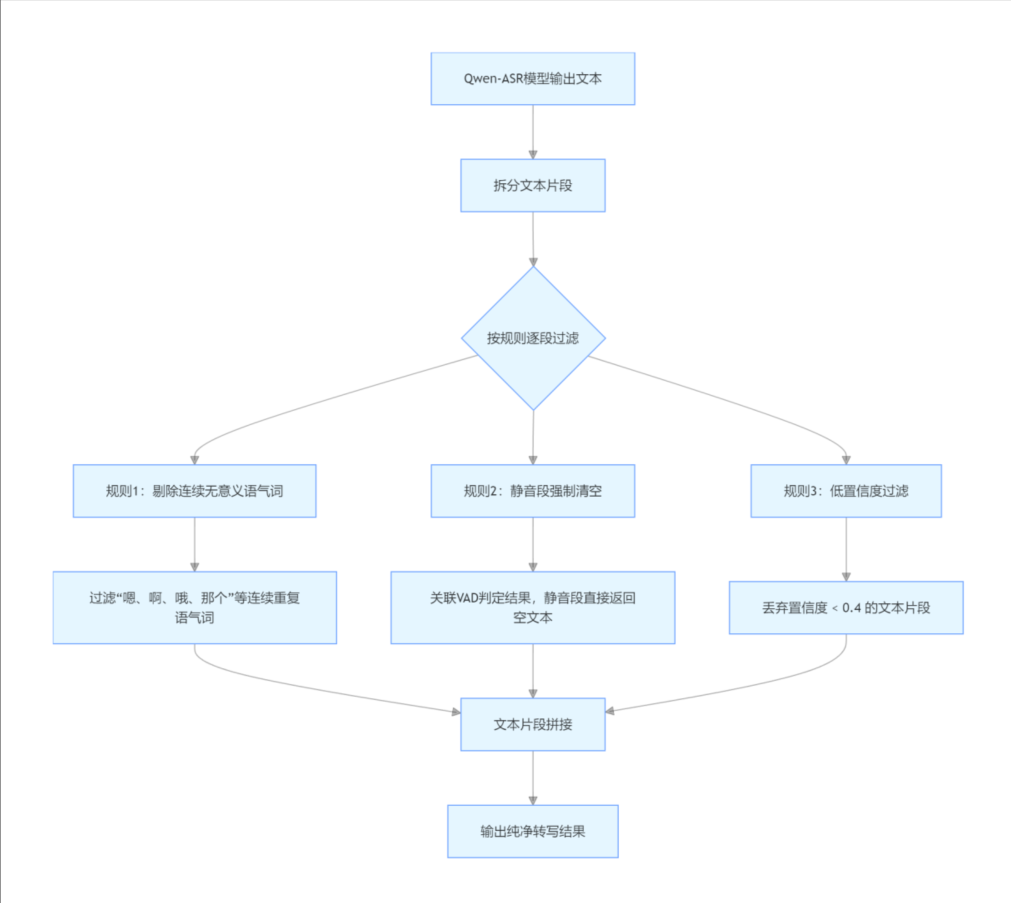
(3)后处理文本过滤
在 ASR 输出后增加规则过滤:
- 剔除连续无意义语气词;
- 静音段强制清空识别结果;
- 对置信度低于 0.4 的片段直接丢弃。
上线后,静音幻觉问题基本消失,转写纯净度大幅提升。
三、Qwen-ASR 离线集成与时间戳精准优化
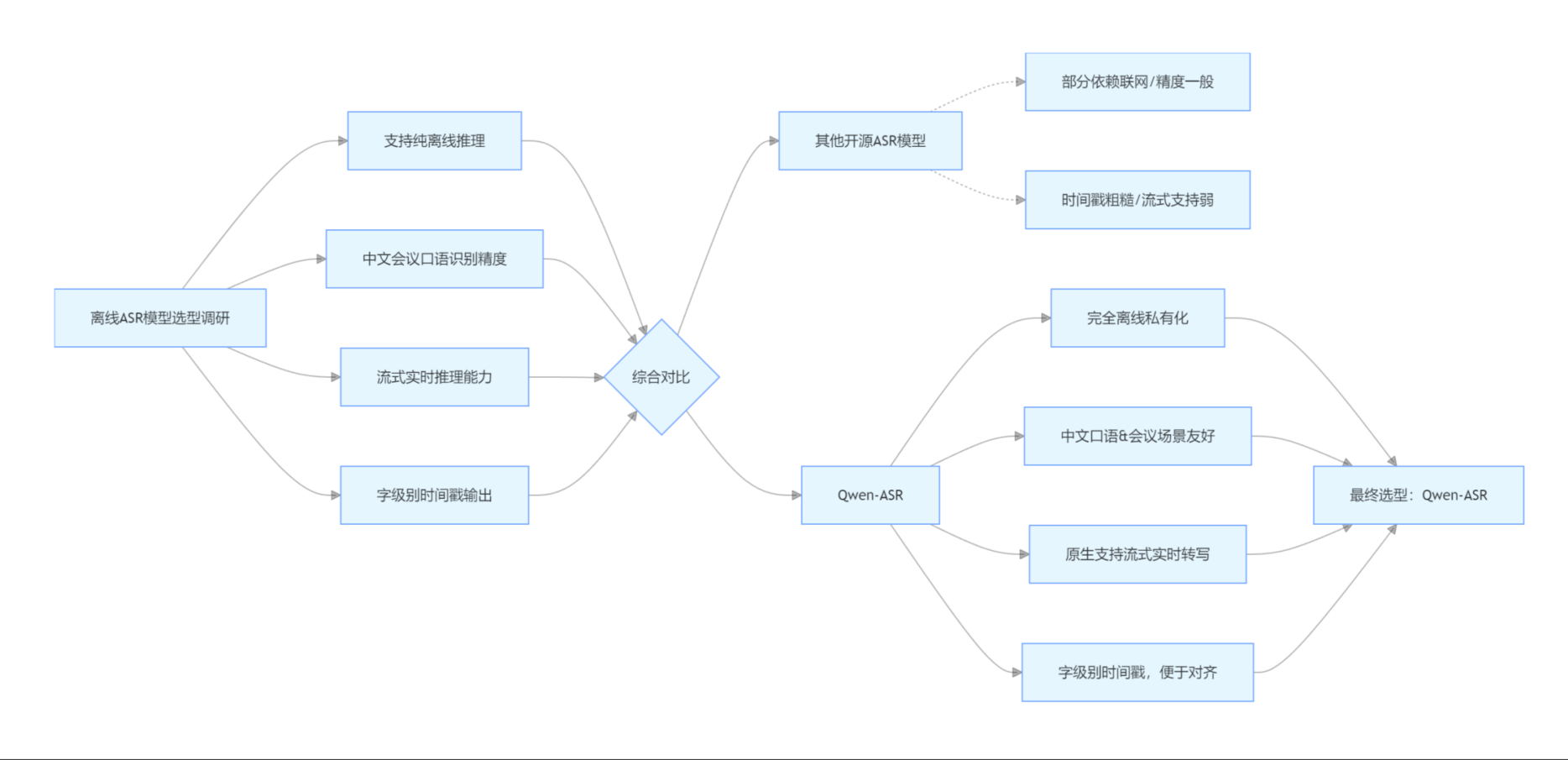
1. 为什么选择 Qwen-ASR?
对比过几个开源离线 ASR 模型,最终选择 Qwen-ASR 主要原因:
- 支持纯离线推理,无需联网;
- 中文识别精度高,对口语、会议场景友好;
- 支持流式推理,适合实时会议;
-
提供字级别时间戳,方便后续对齐。
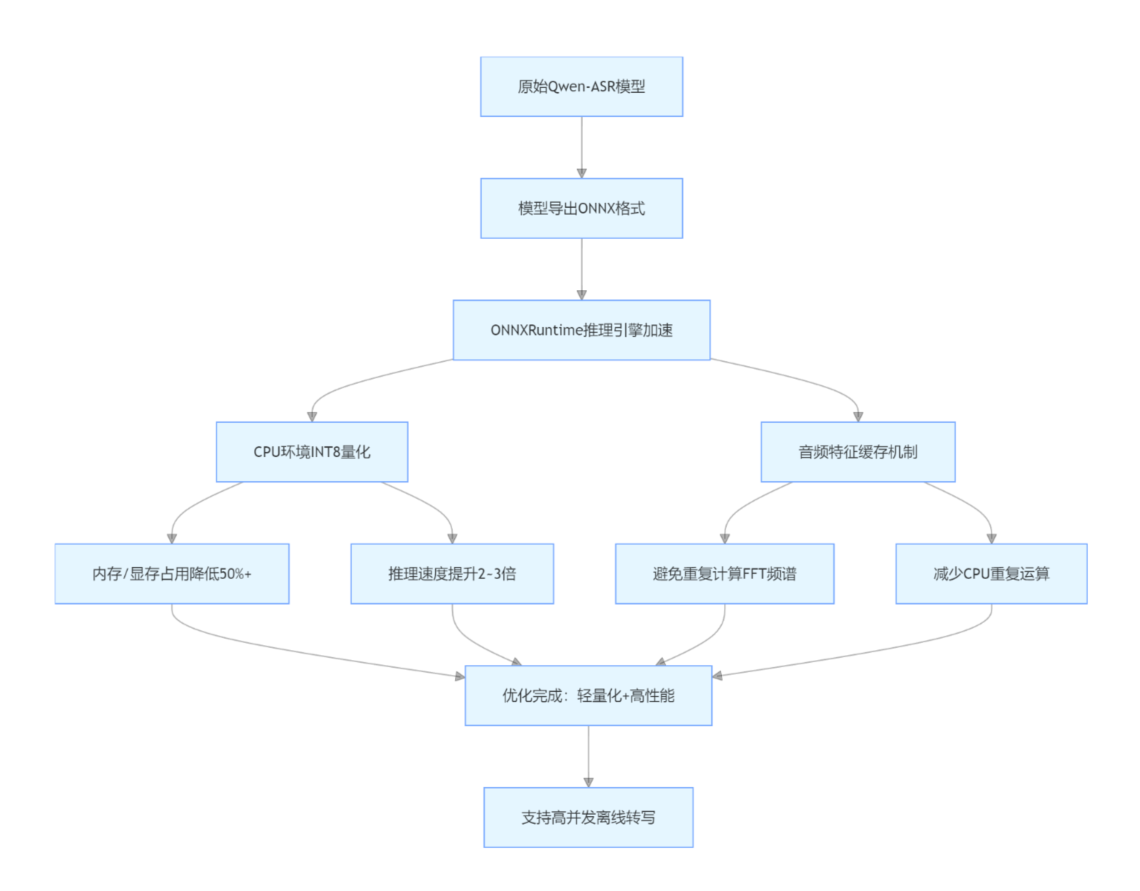
2. 模型部署优化
- 模型导出为ONNX 格式,使用ONNXRuntime 加速推理;
- CPU 环境开启int8 量化 ,显存 / 内存占用降低 50%+;
- 采用特征缓存机制,避免重复计算音频频谱特征。
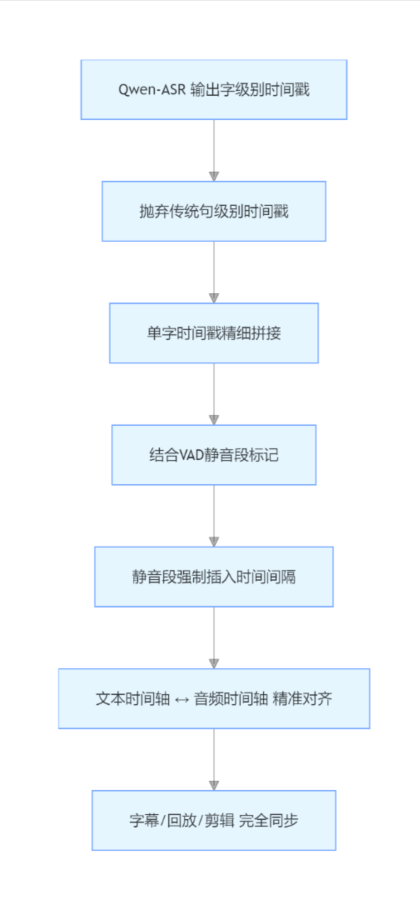
3. 时间戳不准问题优化
时间戳错乱是最影响体验的问题,我们做了两点核心优化:
(1)字级别时间戳对齐
Qwen-ASR 原生输出字级别时间戳,我们:
- 抛弃传统句级别时间戳,改用单字时间戳拼接 ;
- 对静音段强制插入时间间隔,保证音频时长与文本轴一致。
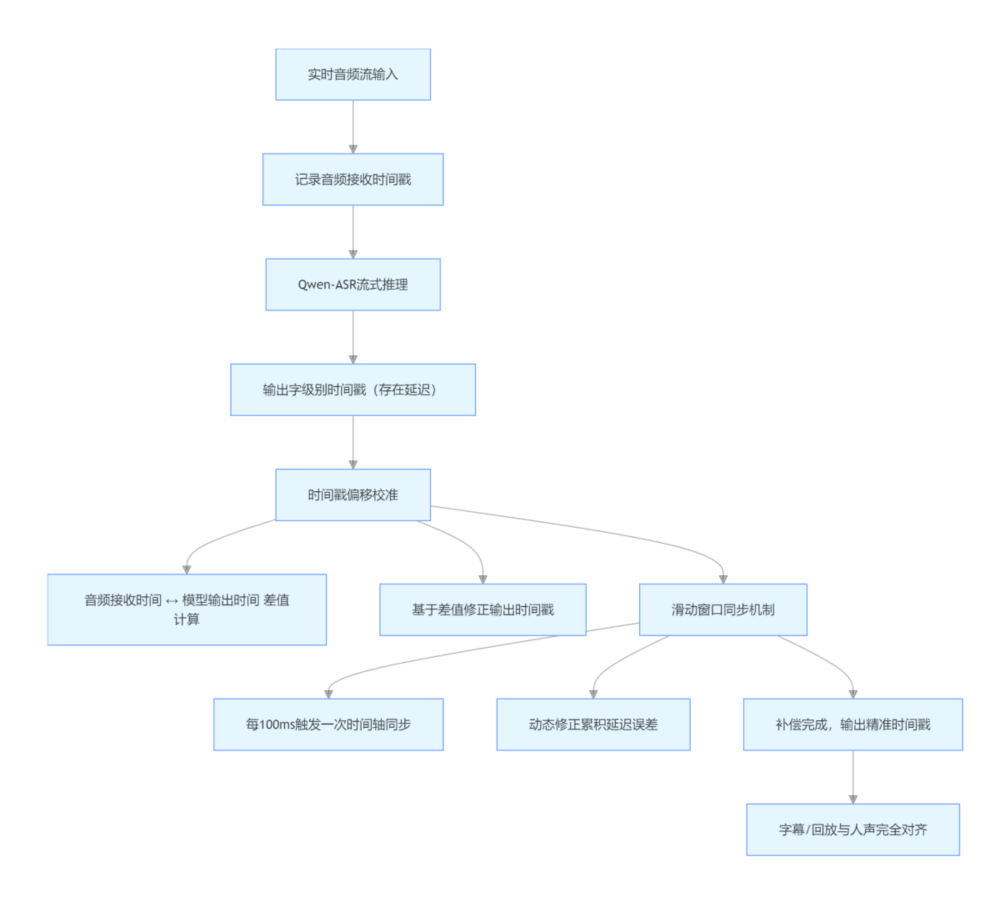
(2)流式推理延迟补偿
实时流场景下,推理延迟会导致时间戳后移,我们:
- 记录音频接收时间戳,与模型输出时间做偏移校准;
- 使用滑动窗口机制,每 100ms 做一次时间轴同步。
优化后,时间戳误差基本控制在50ms 以内 ,字幕、回放完全对齐。
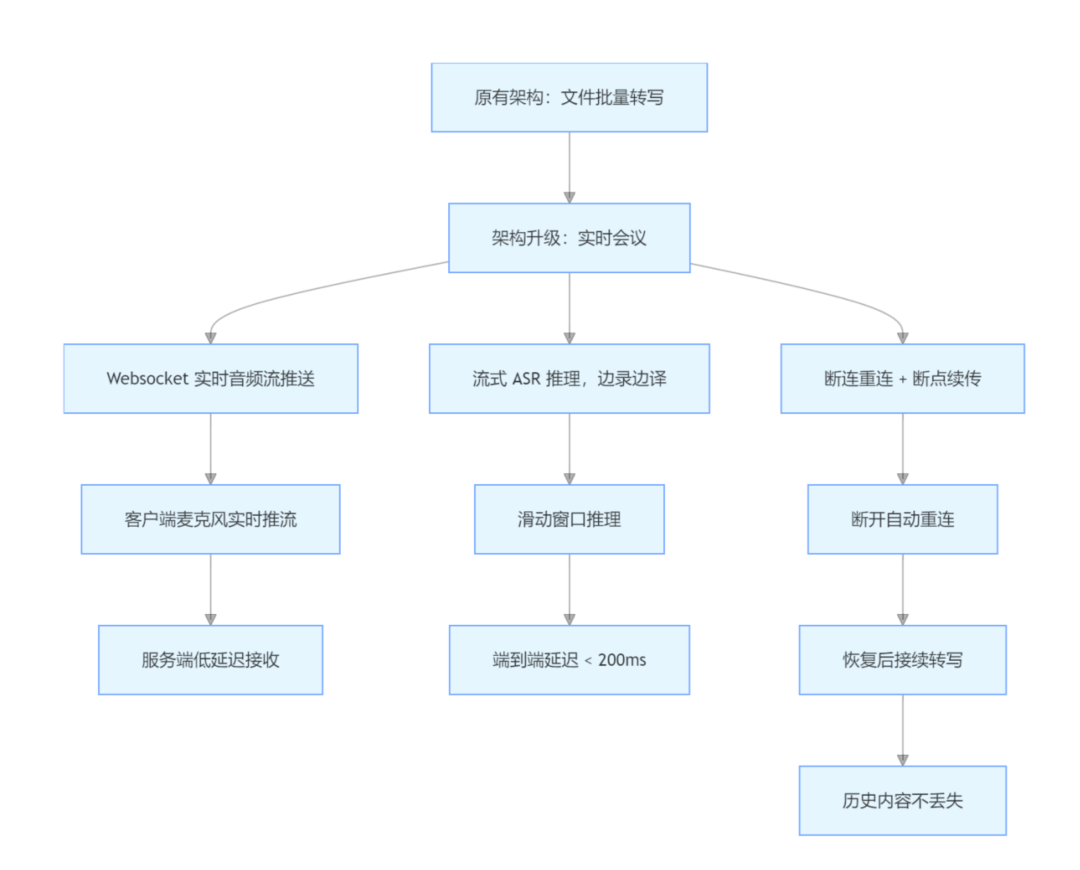
四、实时会议迁移与高并发优化
1. 实时会议流迁移方案
从 "文件转写" 扩展到 "实时会议",核心改造点:
- 基于Websocket 实现实时音频流推送;
- 采用流式 ASR 推理 ,边录边译,延迟控制在 200ms 内;
- 支持断连重连,断点续传,不丢失历史转写内容。
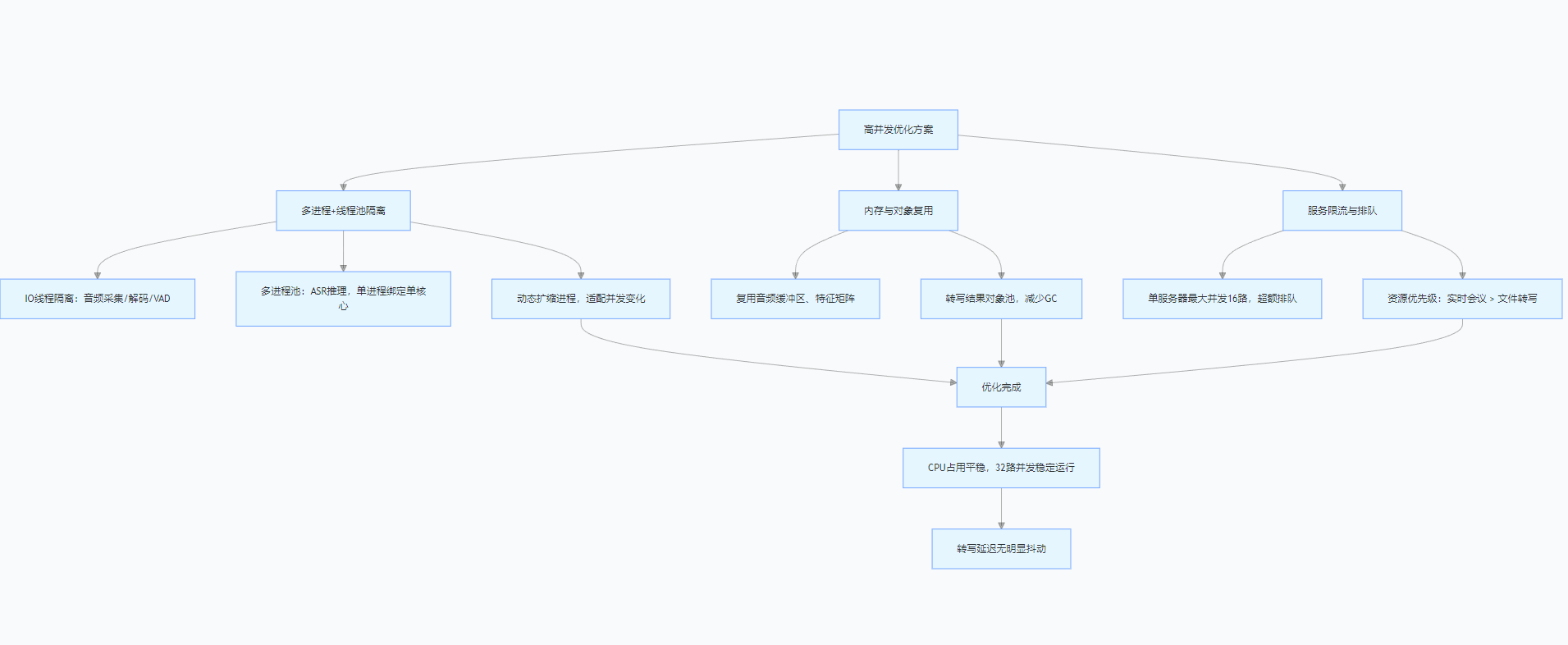
2. 高并发性能瓶颈与优化
初期 3 路并发就卡顿,主要瓶颈在:
- 单进程推理,CPU 无法并行;
- 音频解码与特征提取阻塞推理线程;
- 内存未复用,频繁 GC。
优化方案:
(1)多进程 + 线程池隔离
- 音频采集、解码、VAD 放在独立 IO 线程;
- ASR 推理使用多进程池 ,每个进程绑定一个核心;
- 支持动态扩缩进程数,根据并发数自动调整。
(2)内存与对象复用
- 复用音频缓冲区、特征矩阵,避免频繁申请释放;
- 转写结果使用对象池,减少 GC 开销。
(3)服务限流与排队
- 单服务器最大并发 16 路,超过则进入排队;
- 对实时会议优先分配资源,文件转写降级处理。
优化后,CPU 占用平稳,32 路并发下依然稳定 ,转写延迟无明显抖动。
五、用到的核心技术、模型与知识点总结
本篇优化涉及的技术栈整理如下:
- ASR 模型 :Qwen-ASR(离线中文语音识别)
- 前端处理 :WebRTC VAD、libsamplerate、音频降噪与分帧
- 推理加速 :ONNX、ONNXRuntime、int8 模型量化
- 后端框架 :SpringBoot、WebSocket、线程池 / 进程池
- 并发控制 :限流、队列、CPU 亲和性绑定、对象池
- 关键知识点 :语音活动检测、流式推理、时间戳对齐、高并发架构设计
六、总结与后续规划
经过这一轮系统性优化,熙瑾会悟离线转记系统 已经完全满足企业内部使用:
- 静音幻觉基本消除;
- 时间戳精准对齐;
- 实时转写低延迟;
- 高并发稳定运行。
后续我们还计划:
- 接入说话人分离(Speaker Diarization),自动区分发言人;
- 优化方言识别能力;
- 支持实时摘要、重点提取等大模型后处理。
语音识别落地没有银弹,尤其是离线场景,每一点体验提升都来自细节打磨。如果你也在做离线 ASR、会议转写相关项目,欢迎在评论区交流踩坑心得。