我说个情况,不知道你有没有遇到:
"暗部提上来,亮部又炸了;动态物体一跑,满屏鬼影;风光片调好了,人像又翻车了。"
一提到HDR融合,满脑子都是鬼影、暗部噪点、边缘崩边。
怎么感觉就像,谁让你把空调调到个不冷不热的状态,然后调来调去,也不知道什么样。
有点玄学了这。0x 开头的寄存器改了一个又一个,效果还这个场景行了,那个场景崩了。
我看到还能AI 辅助 HDR 融合,怎么回事呢,让我捋捋

传统 HDR 融合加权融合,到底在干什么,大概逻辑是这样的:
result = (短曝光 * 权重A + 正常曝光 * 权重B + 长曝光 * 权重C) / 总权重
像是把三碗面搅一起了
这个权重怎么算的?
通常是看亮度------亮的地方用短曝光,暗的地方用长曝光。

这样就会有三个问题
1.公式是死的,场景是活的
不会根据场景自适应,逆光、顺光、风光、人像------用的都是同一套。同一把钥匙开所有锁一样,开门锁可以,车锁不行,开保险柜那更离谱。
2.人工特征不够聪明
传统方法靠什么判断权重呢?梯度、纹理、亮度差。
这些手工特征在简单场景有效,碰到复杂光照就拉胯。大光比、运动物体、多语义区域,就比较拉垮了。
3.调参像买彩票
要是参数改了 1% 没反应,又改了 5% 直接崩了

这里面核心的思路是什么呢,不玩加权公式了,直接让网络学会怎么融合。从以前的计算,一下子变成了学习。这才是本质区别。
传统方法想,这个像素该给多少权重?神经网络直接看这像素该从哪一帧薅数据
可以理解这样理解,
传统方法 = 手动挡司机,死记硬背换挡时机
AI 方法 = 自动挡 + 人工智能,它自己知道什么时候该升什么时候该降
AI HDR 的工作流
大概这么回事:
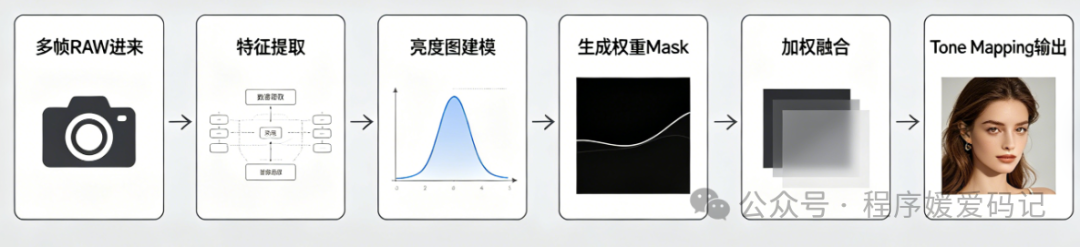
亮度图建模 和 权重生成,是 AI 介入最有效的两个环节
亮度图建模:全局光照估计
亮度图有什么用?
简单说,是要告诉相机是什么场景,现在光线是个啥情况"。
传统方法只能看到局部像素值,不知道这个区域在场景中的语义是什么。
亮度图建模网络要做的,就是给每个像素一个上下文,让它知道自己处在什么样的光照环境下。

AI 为啥这么聪明?因为它见过太多例子了。训练数据里说了
它虽然不知道什么是天空,但它知道这种pattern通常是天空。
想起来,我奶奶看电视剧,不用看剧情就知道谁是反派说,这个人长得贼眉鼠眼的,肯定不是好角色。
AI 也是这么判断的。
权重生成:学习最佳融合策略
有了亮度估计,下一步是生成权重图
传统方法:设计一个公式,代入参数,算出权重
AI 方法:让神经网络自己看例子,学会什么时候该怎么分配
某区域在短曝光过曝 + 长曝光噪点多,传统方法会很纠结。但网络会学到:
取短曝光的结构信息 + 长曝光的细节信息 + 时域滤波平滑过渡,这是最优解。
怎么训练的呢?
通过大量好结果当监督信号。网络看到足够多的正确融合案例后,自然学会在各种场景下做出正确选择。
数据从哪来?
三个主要来源:
-
合成数据:电脑上渲染各种奇怪场景,模拟多曝光
-
真实采集:找个 HDR 设备拍一堆正确答案
-
自监督:直接用多帧 RAW 互相监督,连标注都不用
第三种产品卖出去之后还能持续优化,堪称端侧 AI 的核心竞争力。

先想想问什么放在端侧,云端 HDR 延迟大、带宽高、隐私有风险、成本高。
海思 MPP + 昇腾 NPU,就提供了这个能力。
落地也有几个大坑,比如NPU 算力不够,多帧内存压力大,功耗问题,AI 偶尔掉链子。
一个实用的思路是:AI 负责指挥,传统负责执行。
AI 输出 Weight Map , 传统模块读取 ,实际动手混合。

以前都是调寄存器再实际场景测试看效果,改改参数。
以后就是准备数据训练模型再去部署看看效果,补充数据。
这话听起来有点卷,但趋势就是这样。
传统图像那套东西依然有价值,但学会用 AI 的方式表达它、优化它。
痛点永远会在,只是解决痛点的方式变了。