前言
hello hello💕,这里是洋不写bug~😄,欢迎大家点赞👍👍,关注😍😍,收藏🌹🌹
Java中的线程还是存在比较大的安全问题隐患,这篇博客会对线程的基础安全问题进行解析,具体内容包括执行顺序问题,死锁问题,内存可见性问题,以及如何加锁来保证安全
🎆个人主页:洋不写bug的博客
🎆所属专栏:JavaEE学习
🎆铁汁们对于JavaEE的各种常用核心语法,都可以在上面的前端专栏学习,专栏正在持续更新中🏀,有问题可以写在评论区或者私信我哦~
1,执行顺序问题
铁汁们看下面这段代码,创建两个线程,每个线程中分别让count++,然后启动两个线程,并且在主线程中的等待两个线程都执行完,再打印count(预测打印结果应该是10000)
java
public class demo_10 {
private static int count = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for(int i = 0;i < 50000;i++){
count++;
}
});
Thread t2 = new Thread(() -> {
for(int i = 0;i < 50000;i++){
count++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(count);
}
}但是当运行后会发现,打印的结果是7万多,再运行一次这个代码,打印的结果又变成了六万多,这就是典型的线程安全问题,如下图:

出现这个问题的原因就是t1和t2两个线程,对于count变量的修改不是原子的
count++这个操作,站在cpu的角度上,其实是分为3步:
- load:把内存中的值,加载到cpu寄存器中
- add:把寄存器中的数值进行加1操作
- save:把寄存器中的值写回到内存中
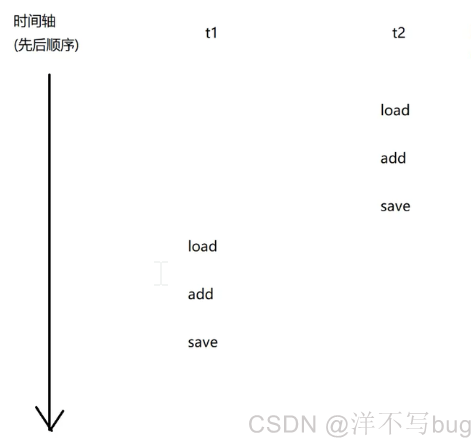
两个线程在执行count++操作时,如果顺序是这样,那肯定最后结果是没问题的
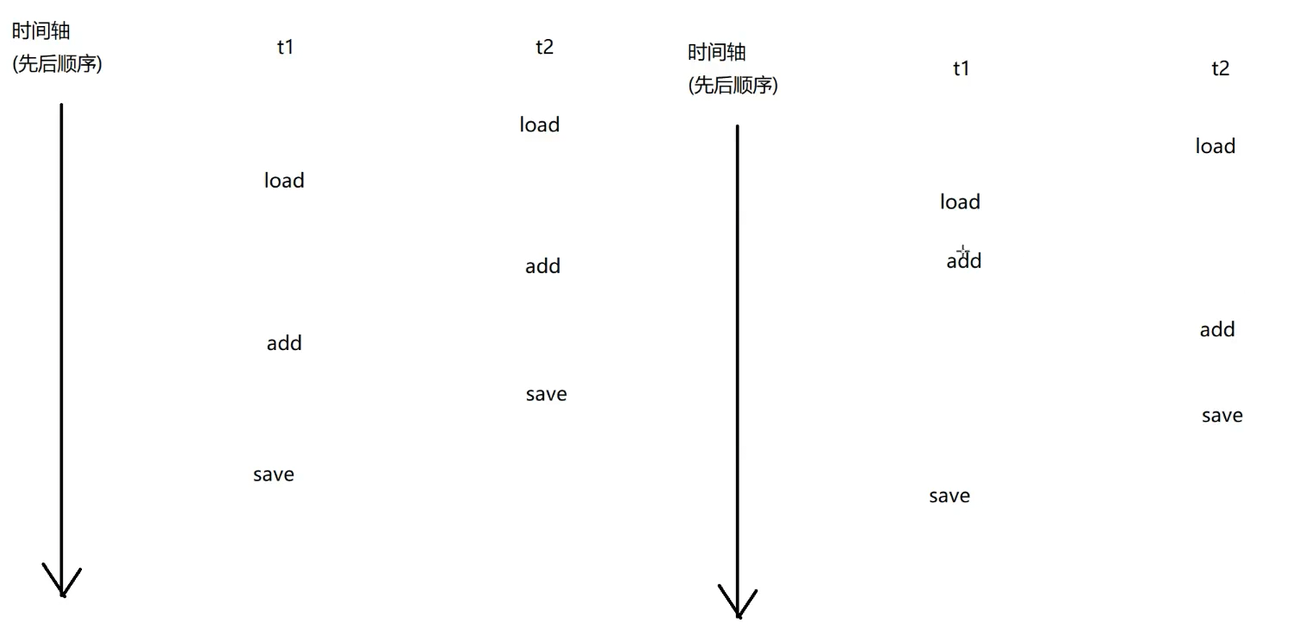
但是cpu上的这三步操作两个线程之间是可以随机组合的,还有很多种可能,如下所示,那这些可能最后的结果是怎么样的呢
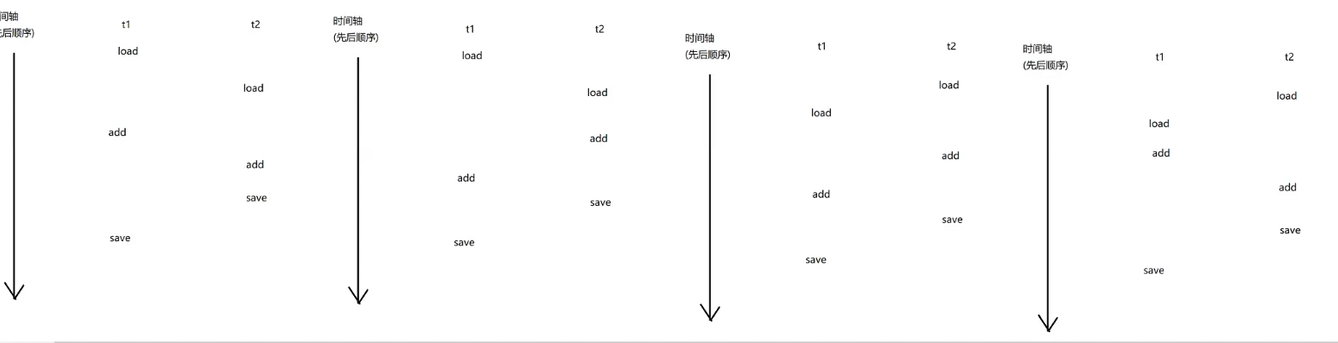
这里随便挑一种情况来模拟下,如下图:
- 首先t1线程load,这时候count = 0,就把0存储到寄存器中
- 接着,t2线程执行三步操作,先把0取到寄存器中,在寄存器中把0加1变成1,再把寄存器中的值保存到内存中
- 接着t1线程执行add操作,t1前面已经读取过count的值了,就不会再读取了(t1线程从cpu上切走的时候会保存上下文),在寄存器中把0加1变成1,再把寄存器中的值保存到内存中,这时候count的值就还是1
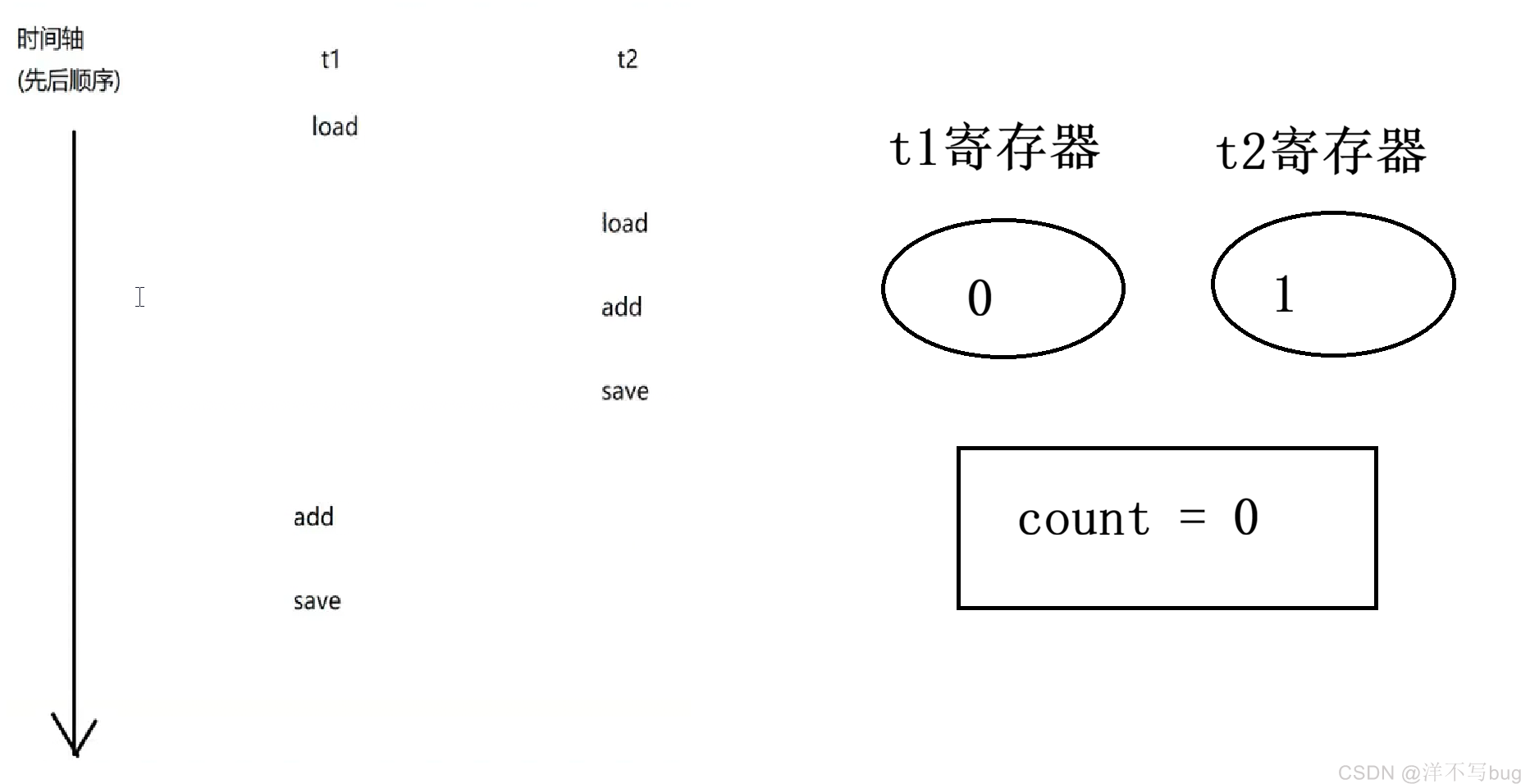
除了前两种组合,后面的几种进行两次count++,但是count的值只加了1
这个地方理解起来不算难,那铁汁们思考一个问题:
这个程序的执行结果是不是一定大于等于5万,有没有可能小于5万?(铁汁们可以在文章底部投下票)
可能很多铁汁的第一印象都是一定大于等于5万,因为可能这个程序运行很多次都是大于5万的,另外前面画的几种指令的排列组合,两个线程执行count++,count最少也能加1
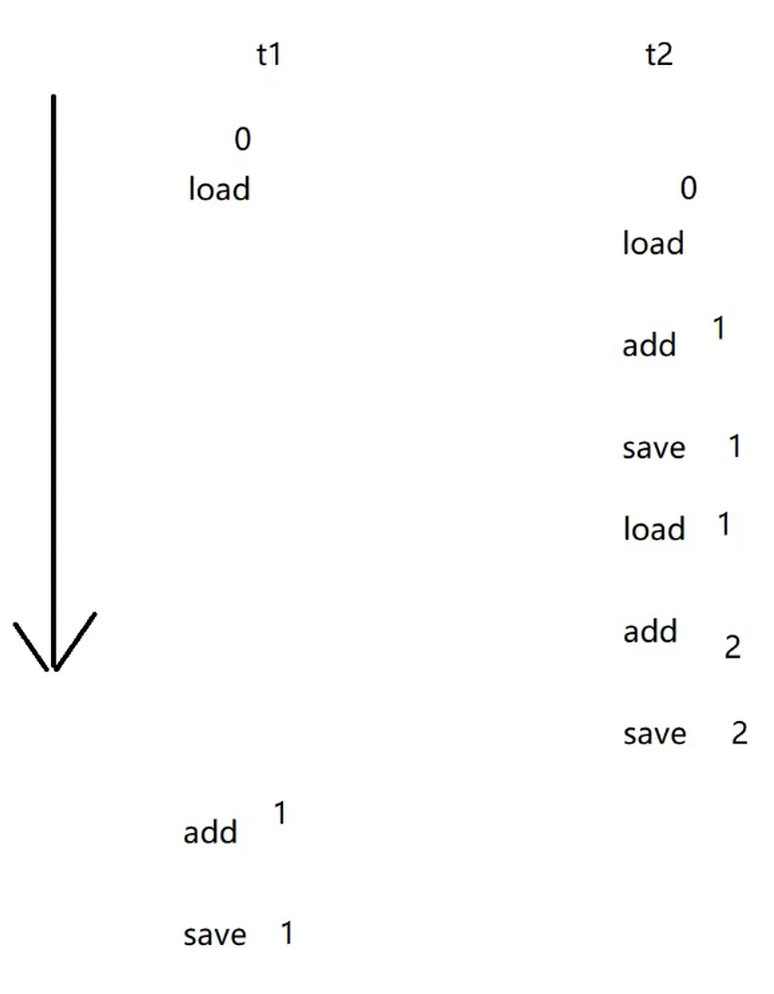
但其实是有可能出现count < 5万的情况出现的,只是概率比较小,如下图所示,t1执行了一次count++,t2执行了两次count++,但是最后count的值只增大了1,类似这种情况概率比较小,但是这个程序确实是有可能运行出来过5万以下的结果的
再补充一个东西,如果把count改为局部变量,程序就会报错,报错翻译是:在lambda表达式(expression)中使用的变量(variable)必须是final类型或者效果等同于final的,如下所示:
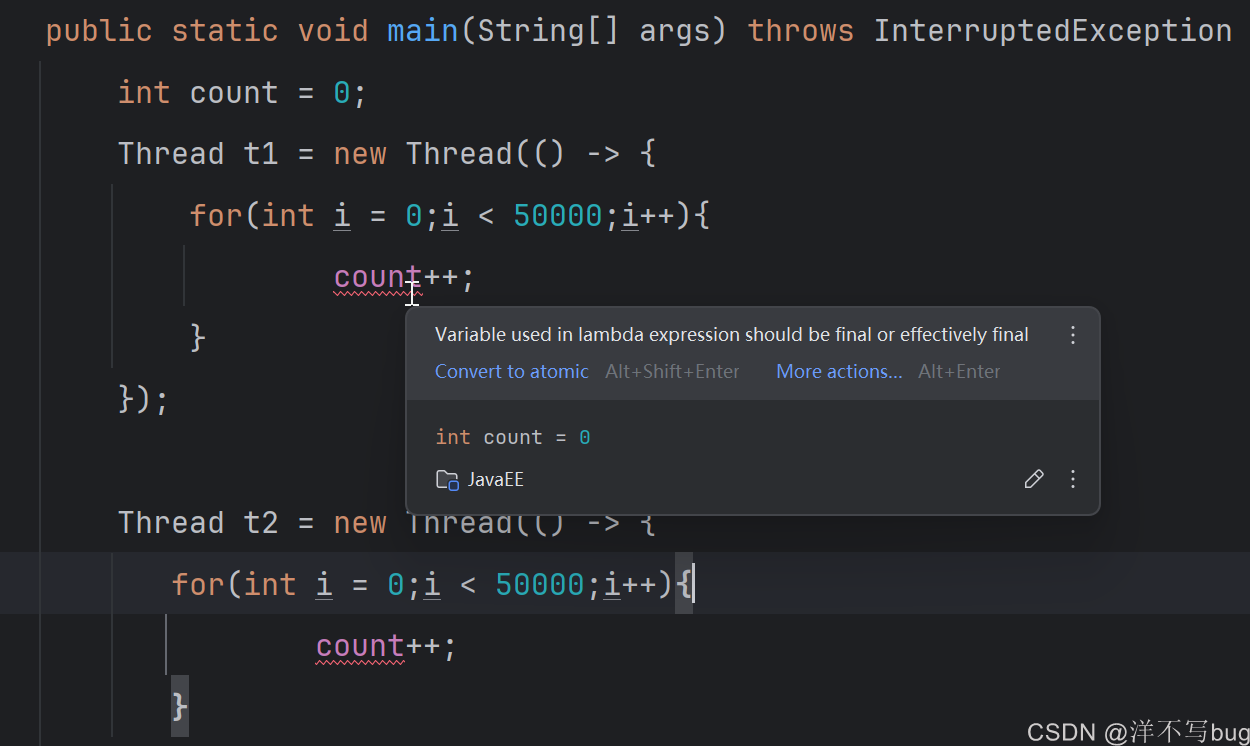
这是因为lambda表达式会对变量进行捕获,捕获的变量必须是fianl或者事实final(虽然不是fianl,但是代码中没有修改),而这里的count两种都不满足,就会报错
写成成员变量,lambda能访问是因为这时候不是通过变量捕获的方式来获取变量的,而是通过内部类访问外部成员变量的方式(lambda本质上就是匿名内部类)
2,加锁操作
出现线程安全问题主要有以下三个原因:
- 根本原因线程的调度执行是随机的
- 多个线程同时修改同一个变量
一个线程修改同一个变量,多个线程同时读取同一个变量,多个线程同时修改多个变量,都没有问题 - 对于变量的修改操作,不是原子的,在cpu上要分三步执行(在Java中,像=(赋值)这样的操作就是原子的)
第一个是操作系统的设定;第二个是存在的客观事实,那就只能从第三点着手,把线程的修改操作变成原子的
采取加锁的方式,把一段代码进行打包,打包成一个整体,这样的话就可以达到原子性的效果(这点类似于数据库中的事务)
加锁就使用synchronized这个关键字,给t1线程对于count的操作加锁,那t1在执行count++的三步cpu操作时,t2的cpu操作就不会插进来
这个就类似于在上厕所的时候加锁,一个滑稽进了厕所,给厕所上了锁
那第二个滑稽这时候就不能使用厕所了,只能等待第一个滑稽开锁出来后再进去
这个等待(阻塞)的过程就称为"锁竞争","锁冲突"
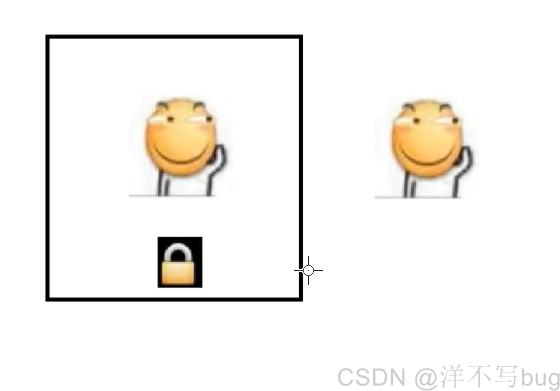
如果厕所有两间,那第二个滑稽就就可以直接进入第二间厕所,就没必要等待(阻塞)第一个滑稽,如下图:
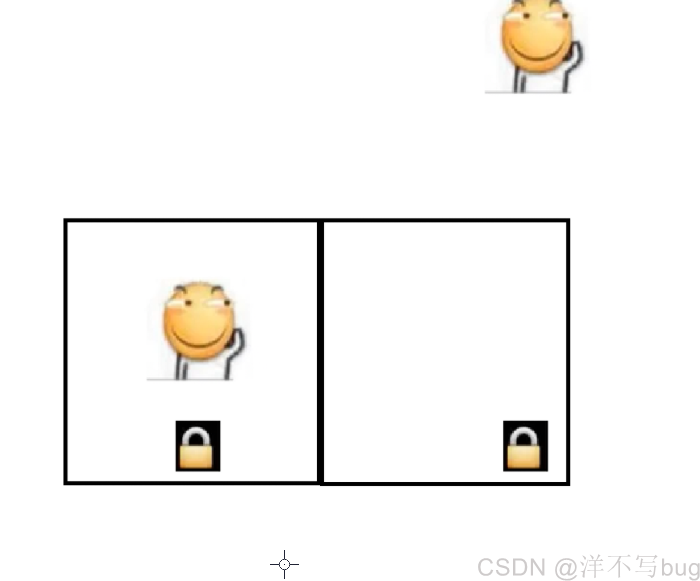
因此,只有当两个线程,同时竞争同一把锁的时候 ,才会产生阻塞,如果竞争的是不同的锁,则没有影响,那如何判断是不是同一把锁呢,就是看锁对象
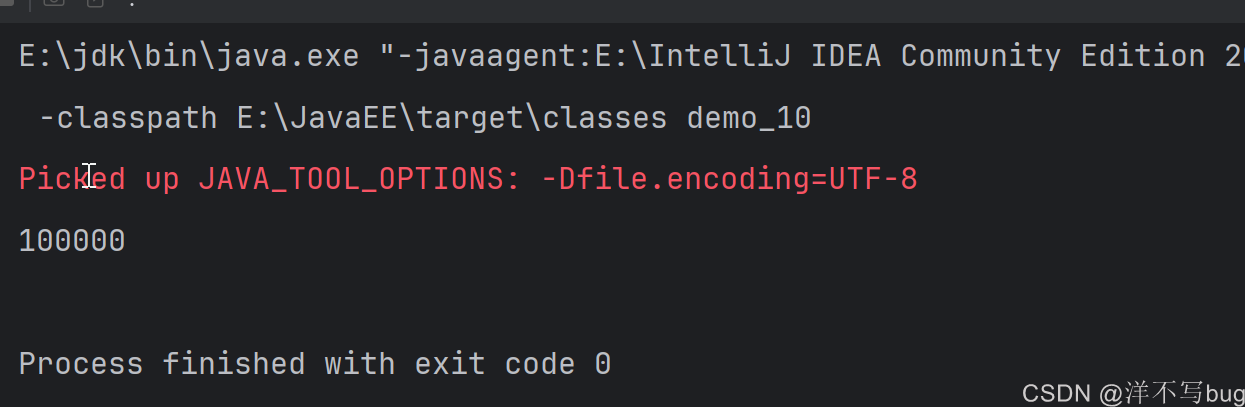
加锁就是使用synchronized (锁对象),锁对象直接在上面创建一个,给两个线程加上同一把锁后,最后的结果就是正确的
java
public class demo_10 {
private static int count = 0;
private static Object locker = new Object();
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for(int i = 0;i < 50000;i++){
synchronized (locker){
count++;
}
}
});
Thread t2 = new Thread(() -> {
for(int i = 0;i < 50000;i++){
synchronized (locker){
count++;
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(count);
}
}
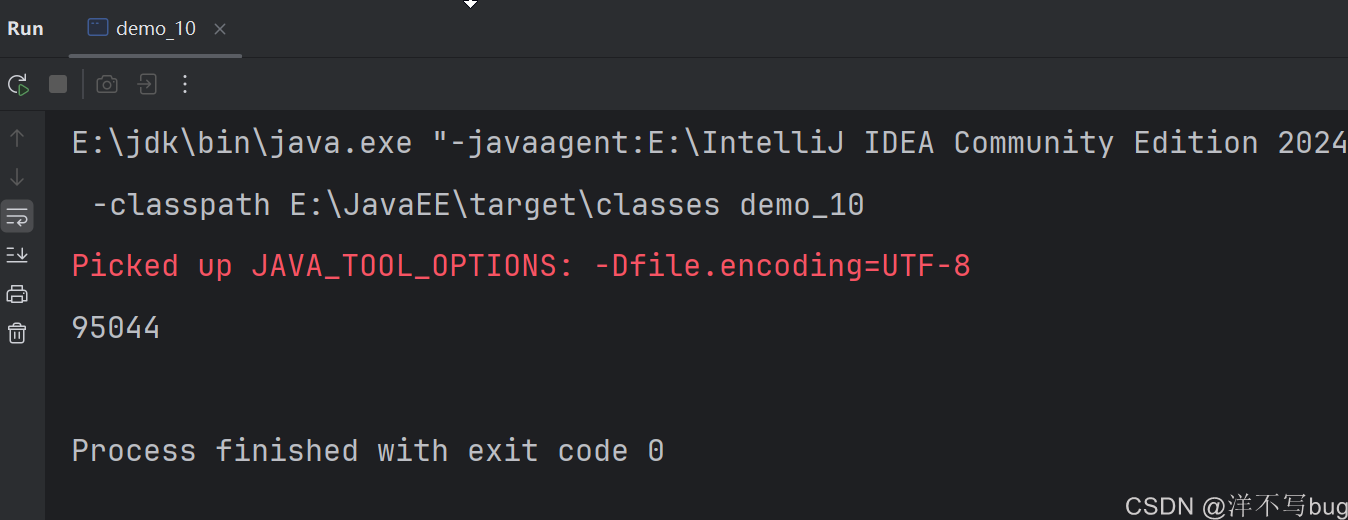
如果两个线程中加不同的锁(不同的锁对象),那就相当于前面有两间厕所的情况,两个线程之间就不会竞争锁,运行后还是错误的结果,测试如下所示:
java
public class demo_10 {
private static int count = 0;
private static Object locker = new Object();
private static Object locker2 = new Object();
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for(int i = 0;i < 50000;i++){
synchronized (locker){
count++;
}
}
});
Thread t2 = new Thread(() -> {
for(int i = 0;i < 50000;i++){
synchronized (locker2){
count++;
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(count);
}
}
可能有的铁汁发现了一个比较奇怪的地方,两个线程加不同锁既然没有用,那为什么最后count的值要比都不加锁时普遍更接近正确值呢?
这是因为当两个线程都不加锁时,cpu会让它们极致并行,丢失的数据就比较多
而当两个线程加了不同的锁时,获取锁对象的监视器释放锁对象的监视器这两步有极微小的耗时和调度延迟,会让两个线程的执行节奏稍微错开,但还是没办法从根本上来解决问题
另外,一个线程加锁,一个线程不加锁,就相当于一个滑稽上厕所加锁,另一个滑稽直接把门踹开了,数据还是会错误(铁汁们可以写代码试下)
因此,这个代码唯一正确的写法就是给两个线程加同一把锁
如下图,当给两个线程加同一把锁的时候,t1在执行load前会先进行lock操作,接着操作完再unlock,这里的加锁和解锁也可以视为是两个cpu指令
假如t1执行完load后,t2想插队,那就要先进行lock,这里的lock就是加锁,这里的加锁不算成功也不算是失败,会使t2一直处于阻塞状态,直到t1unlock后,t2才有可能执行(只是t1unlock完成后,t2有资格继续执行,但是可能还是t1抢到执行权)
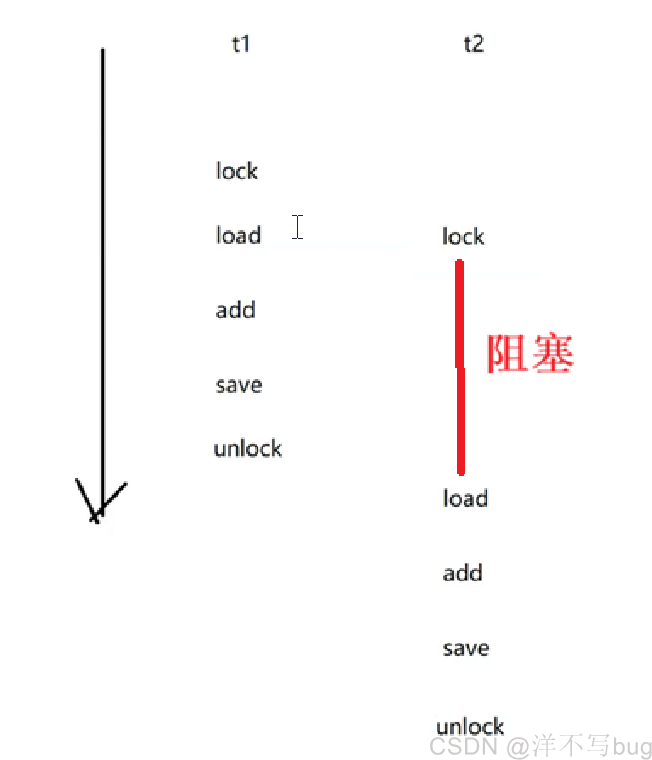
本来load,add,save两个线程是穿插执行的,引入锁之后,就变成串行执行了,这样就能确保结果的正确
还可以把锁加到for循环的外面,运行后结果还是10万,这就相当于t1会不停的执行循环,直到把这5万次循环都执行完,这期间t2会一直阻塞等待,直到t1执行完
这时候这两个线程的执行就完全是串行的
java
Thread t1 = new Thread(() -> {
synchronized (locker){
for(int i = 0;i < 50000;i++){
count++;
}
}
});
Thread t2 = new Thread(() -> {
synchronized (locker){
for(int i = 0;i < 50000;i++){
count++;
}
}
});而如果对count++加锁的话,此时就只有count++是串行的,for循环i的++,i的大小判断,这些都是并行的,这种写法代码的并发程度也就更高
引入线程这个概念,就是为了充分利用cpu上的多核心资源,如果给for加锁,那就完全变成串行的了,就无法利用这个优势了
但是,在这个代码中,如果真的试一下计算程序执行的时间(代码如下所示),发现在for循环外加锁反而比在for循环内加锁要快个十几毫秒,这是因为加锁,解锁操作也需要花费时间,这是因为这个程序的代码太简单了,并行执行的节省的时间反而没有加锁解锁耗费的时间多但是在工作中,使用多线程时,一般代码中都有很复杂的逻辑,让加锁的范围尽量小,让代码能够并发执行的逻辑多一点,这是一定能提升执行效率的
java
long beg = System.currentTimeMillis();
t1.start();
t2.start();
t1.join();
t2.join();
long end = System.currentTimeMillis();
System.out.println(end - beg + "ms");也可以给方法加锁,让同的线程来调用这个方法,同样会产生阻塞效果,如下所示
java
public class demo_11 {
static class Counter{
private int count = 0;
private Object locker = new Object();
public void add(){
synchronized (locker){
count++;
}
}
}
public static void main(String[] args) throws InterruptedException {
Counter counter = new Counter();
Thread t1 = new Thread(() -> {
for(int i = 0;i < 50000;i++){
counter.add();
}
});
Thread t2 = new Thread(() -> {
for(int i = 0;i < 50000;i++){
counter.add();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(counter.count);
}
}
给方法加锁,锁对象就可以省略,如下所示
java
synchronized public void add(){
count++;
}这样写,省略锁对象,就等价于给this加锁
java
public void add(){
synchronized (this){
count++;
}
}省略锁对象,给this加锁,以及创建一个locker对象当作锁对象,三种情况,看起来很复杂的样子
其实,这三种写法没有任何区别,锁对象是啥压根就不重要,重要的是两个线程是否针对同一锁个对象加锁🐵
就好比滑稽A上厕所,把门锁柱,滑稽B在外面等,处于阻塞状态,那这个情况跟锁是个啥样的,没有半毛钱关系(可以是指纹锁,密码锁,钥匙锁...)
在Counter里面写个类方法,也能用 synchronized 来加锁,在类方法中是没有this的,那这里是怎么加的锁呢?
java
synchronized public static void func(){
}此时 synchronized是拿到了类对象来加锁的,这个就是通过反射(程序运行时,拿到类/对象的一些相关的属性)来拿到的
,java编译生成.class,.class被jvm加载到内存中去,就得到了对应的类对象
3,死锁
1,同一线程中相同锁的嵌套
铁汁们看下面这段代码,针对同一个线程,用同一把锁连续加锁两次,如下所示:
java
for(int i = 0;i < 50000;i++){
synchronized (locker){
synchronized (locker){
count++;
}
}
}分析下这个代码会怎么执行,执行到第一处synchronized时,会把锁给锁上,接着往下执行时就会出现阻塞情况,阻塞到第一处sychronized执行完后才会继续往下执行,这里阻塞住,就无法往下执行,第一把锁也不可能解开,因此,按照我们推测的,这个线程就会一直卡在这里
可能有的铁汁会想,正常写代码谁会这样写呀?
但是在这种连续调用的情况下,看起来两个sychronized都在单独的方法中,但是就会出现一把锁套另一把锁的情况

类似这样的代码,放到C++上就是妥妥的死锁
但是在Java中,引入了特别的机制,同一个线程,针对同一把锁,连续加锁多次,就不会触发死锁,这个锁就称为"可重入锁"
"可重入锁"就是当发现一个线程被加了多把同样的锁,并且这些锁还是嵌套的关系,那里面套的锁就不会触发阻塞,例如下面这段代码,第一层锁加上后,下面这层锁并不会产生阻塞,代码还会向下继续运行
java
for(int i = 0;i < 50000;i++){
synchronized (locker){
synchronized (locker){
count++;
}
}
}区分锁看的是锁对象,"重入锁"机制就是让锁对象自身来保存使用该锁的线程的信息
Java中的对象,有一片存储区域保存对象属性,还有一片区域保存"对象头",对象头是由JVM维护的,保存了这个对象的其他一些运行信息(例如加锁状态,哪个线程加了锁)
对于这种多层嵌套锁的情况,铁汁们想下,在下图中用红色圈出这里释放锁资源可以吗?
当然不行,如果这里就释放了锁资源,那外面的两层锁就失效了,可能外面的两层锁包含的还有逻辑,这些逻辑也就不再线程安全了
因此,要到最外层再释放锁资源,那JVM执行代码时,怎么知道哪里是最外层呢JVM引入了一个计数器,初始计数器的值为0,遇到"{",计数器就加1,遇到"}",计数器就减1,什么时候计数器的值为0,也就到达了最外层
但是,"可重入锁"只能解锁死锁的这一种情况,也就是在同一个线程里嵌套多把同样的锁的情况,其他的情况是解决不了的
2,互相卡对方造成的死锁
例如两个线程两把锁,每个线程先获取一把锁,再尝试获取对方的锁
在《明朝那些事儿》有这样一个故事:明朝大将蓝玉北伐出征北元,后来北元丞相纳哈出归降,蓝玉晚上设宴款待他们;蓝玉看纳哈出的衣服比较破,就把自己的外衣脱了,给纳哈出披上,但是纳哈出却认为蓝玉是在羞辱他。纳哈出说你把酒喝了我再穿,蓝玉说你把衣服穿上我再喝酒,双方就争执起来,最后也差点打起来
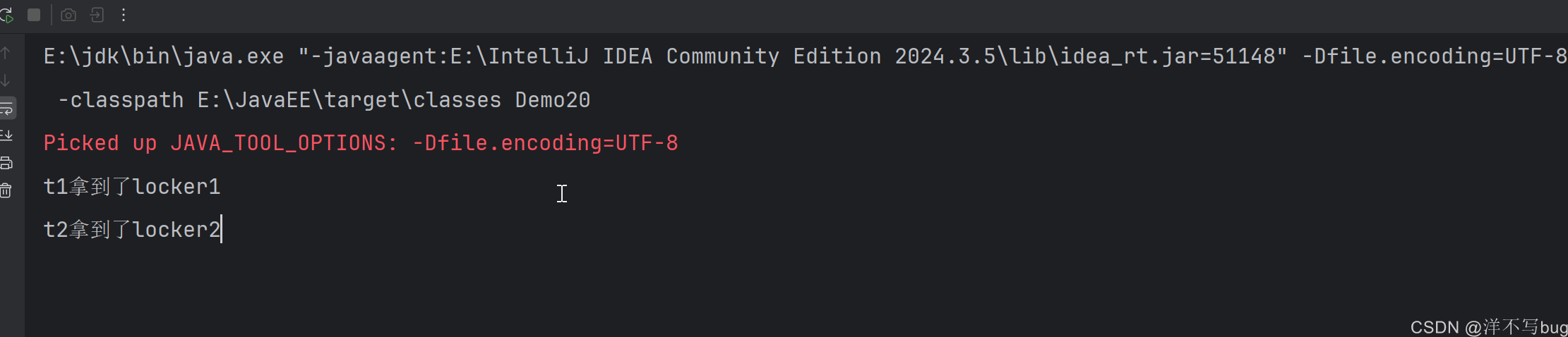
这个就类似于两个线程都先获取一把锁,再尝试获取对方的锁,进而会造成死锁的情况,这两个线程都在等对方解开锁,就会卡到这里,代码如下所示:
java
public class Demo20 {
public static void main(String[] args) throws InterruptedException {
Object locker1 = new Object();
Object locker2 = new Object();
Thread t1 = new Thread(() -> {
synchronized (locker1){
System.out.println("t1拿到了locker1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (locker2){
System.out.println("t1拿到了locker2");
}
}
});
Thread t2 = new Thread(() -> {
synchronized (locker2){
System.out.println("t2拿到了locker2");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (locker1){
System.out.println("t2拿到了locker1");
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
}
}
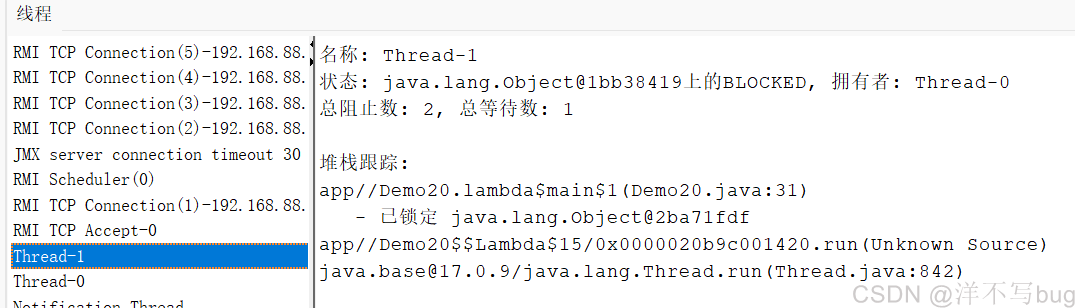
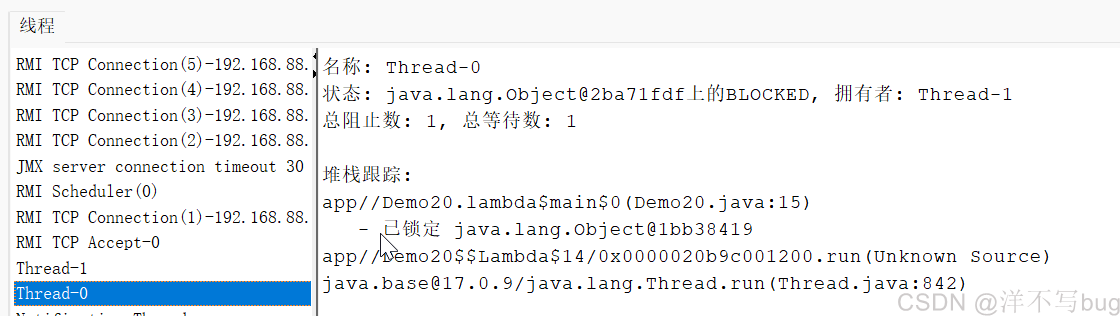
在检测平台上看下,这两个线程都是BLOCKED状态,如下图所示:
3,哲学家就餐问题
N个线程M把锁,也会出现死锁的情况,一个比较经典的例子就是"哲学家就餐问题",如下图:
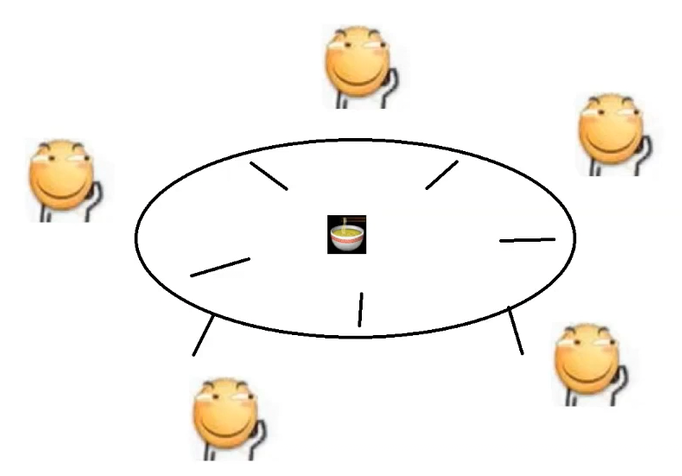
5个哲学家坐在一张桌子上,桌子中间放了一碗面,每两个哲学家之间都放了一根筷子,那如果一个哲学家想凑够一双筷子吃面,就需要拿起左手边和右手边的筷子
哲学家比较固执,如果只拿到了一根筷子,而另一只筷子在别人手里,那哲学家就会一直等,直到别人吃完面,把这根筷子放到桌子上去
这个模型,大部分情况下是不会产生死锁的,但是有这样一种情况:所有哲学家都同时拿起了左手边的筷子,再尝试去拿右手边的筷子,发现在别人手里,这时候所有哲学家都会左手拿着筷子不放手,一直等右边的筷子这就会构成一个死循环,所有哲学家都在等右边的人放下筷子,也就构成了死锁
这种死锁情况可能出现的概率比较小,但是一旦出现,逻辑就会卡死,也就是出现bug这种概率性的bug还是比较可怕的,可能程序员自己测试时没有触发这个bug,测试员进行测试的时候也没有触发,但是到用户手中某天就触发这个bug了,那就有点炸缸了
4,解决死锁
死锁产生需要四个必要条件:
- 锁是互斥的
像数据库中的读锁,就不是互斥的,就不会产生死锁,sychronized锁就是互斥的 - 锁不可被抢占
例如线程A发现一把锁在线程B那里,那线程A只能阻塞等待,不能把锁抢过来 - 请求和保持
一个线程拿到第一把锁的情况下,不去释放第一把锁,就去请求第二把锁,这个也就是前面所说的两个线程都在等对方先释放锁的死锁情况 - 循环等待
就类似前面说的那个哲学家就餐问题,大家互相等,构成了一个死循环
因为sychronized锁是互斥的,而且不可被抢占,所以第一点和第二点是没法改变的,就要从第三点和第四点上入手,来避免死锁
从第三点入手就是线程在没有释放第一把锁的时候,就不去请求第二把锁,代码如下所示:
java
Thread t1 = new Thread(() -> {
synchronized (locker1){
System.out.println("t1拿到了locker1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
synchronized (locker2){
System.out.println("t1拿到了locker2");
}
});那从第四点来入手,就是给锁编号,不要让等待关系构成循环
对于前面那个代码,可以让两个线程同时尝试请求locker1,这样就不会出现死锁的问题,代码如下所示:
java
public class Demo20 {
public static void main(String[] args) throws InterruptedException {
Object locker1 = new Object();
Object locker2 = new Object();
Thread t1 = new Thread(() -> {
synchronized (locker1){
System.out.println("t1拿到了locker1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (locker2){
System.out.println("t1拿到了locker2");
}
}
});
Thread t2 = new Thread(() -> {
synchronized (locker1){
System.out.println("t2拿到了locker2");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (locker2){
System.out.println("t2拿到了locker1");
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
}
}补充一点,Java 标准库中很多都是线程不安全的。这些类可能会涉及到多线程修改共享数据,又没有任何加锁措施.
- ArrayList
- LinkedList
- HashMap
- TreeMap
- HashSet
- TreeSet
- StringBuilder
-
只有少部分是线程安全的
- Vector (不推荐使用)
- HashTable (不推荐使用)
- ConcurrentHashMap
- StringBuffer
铁汁们会发现,大部分标准库中的类都没有加锁,这是因为给线程加锁是有代价的,会非常明显的影响效率,而且加锁还会触发锁竞争,产生阻塞,某个线程一旦加锁阻塞,什么时候能再次执行,就不好说了
Vector和HashTable 也是早期Java不成熟的时候引入的设定,它们就是无脑的全方法加锁,并发效率极低,现在已经被淘汰了
结语💕💕
加锁操作很简单,系统只认锁对象,当两个线程都针对同一个锁对象加锁时,其中个线程的指令在执行时,另一个线程就不能从中插队,进而保证线程安全
解决死锁就是从死锁的第三个和第四个特性来入手,也比较好解决🐵🐵🐵
以上就是今天的所有内容啦~完结撒花~🥳🎉🎉
