当世人谈论面向对象,他们想到的是 Java 的 class、C++ 的 virtual、Python 的 self。然而 Linux 内核用 700 万行 C 代码,向我们证明了一个深刻的真理:面向对象不是语言的专利,而是程序员的思维方式。调度器,这个操作系统的"心脏",正是这种思想的绝美诗篇。
0 思想的革命
在计算机科学的圣殿中,有一个持久的误解:面向对象是语言的特性。Java 诞生时如此宣称,C++ 进化时如此标榜。但 Linux 内核的设计师们,用最朴素的 C 语言工具,书写了面向对象思想最纯粹的表达。
调度器,这个决定哪个进程在何时运行的系统核心,没有使用任何"高级"的面向对象语法。它只用结构体、函数指针和链表,就实现了封装、继承、多态的全部精妙。这证明了:优秀的架构源自思想,而非语法糖。
注:Linux 调度器这种"面向对象"的模块化设计,是在 2.6.23 版本(2007年10月)正式成形的。
这一版本由 Ingo Molnar 主导重构,引入了 struct sched_class 抽象结构体和 CFS(完全公平调度器),将调度核心与具体策略彻底解耦。
7.0版本的完全公平调度器已经用EEVDF算法取代了使用了十几年的CFS算法。
1 C 语言的"面向对象"
在 Java 或 C++ 中,面向对象是语言特性。在 Linux 内核中,面向对象是设计思想,用 C 语言的结构体和函数指针实现。
1.1 面向对象的核心映射
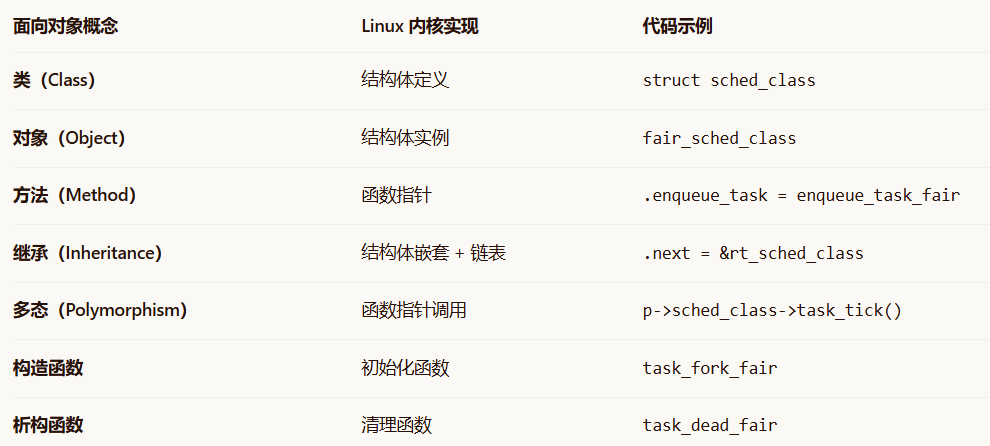
1.2 调度器的核心设计哲学
Linux 调度器的设计遵循策略模式 :
策略接口 :struct sched_class定义了调度算法的通用接口。
具体策略 :fair_sched_class、rt_sched_class等实现具体算法。
上下文:struct task_struct持有策略指针,通过指针调用策略。
2 调度器类的完整定义
2.1 调度器基类:sched_class
c
/* kernel/sched/sched.h - 调度器的抽象基类(接口定义) */
struct sched_class {
/* 继承:通过next指针实现优先级继承链 */
const struct sched_class *next;
/* 封装的任务管理接口 */
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
/* 封装的任务调度接口 */
struct task_struct *(*pick_next_task)(struct rq *rq);
void (*put_prev_task)(struct rq *rq, struct task_struct *p);
/* 封装的任务生命周期接口 */
void (*task_fork)(struct task_struct *p); // 构造函数
void (*task_dead)(struct task_struct *p); // 析构函数
void (*task_tick)(struct rq *rq, struct task_struct *p, int queued);
/* 封装的状态切换接口 */
void (*switched_from)(struct rq *rq, struct task_struct *p);
void (*switched_to)(struct rq *rq, struct task_struct *p);
/* 其他必要的封装接口 */
void (*update_curr)(struct rq *rq);
void (*set_next_task)(struct rq *rq, struct task_struct *p, bool first);
unsigned int (*get_rr_interval)(struct rq *rq, struct task_struct *p);
};封装设计思想 :这是一个纯虚基类 ,只定义接口不提供实现,强制子类实现所有方法,实现接口与实现的完全分离。
2.2 调度器子类(单例模式)
每个调度算法都是独立的全局唯一sched_class的实例化。以完全公平调度器子类和实时调度器子类实例化为例:
公平调度器子类:fair_sched_class
c
/* kernel/sched/fair.c - 公平调度器的具体实现(子类) */
const struct sched_class fair_sched_class = {
/* 继承:指向下一个调度器,形成优先级链 */
.next = &idle_sched_class,
/* 实现基类的所有接口(多态的基础) */
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.pick_next_task = pick_next_task_fair,
.put_prev_task = put_prev_task_fair,
/* 实现生命周期接口 */
.task_fork = task_fork_fair, // 构造函数实现
.task_dead = task_dead_fair, // 析构函数实现
.task_tick = task_tick_fair, // 运行时方法
/* 实现状态切换接口 */
.switched_from = switched_from_fair,
.switched_to = switched_to_fair,
/* 实现其他接口 */
.update_curr = update_curr_fair,
.set_next_task = set_next_task_fair,
.get_rr_interval = get_rr_interval_fair,
/* 公平调度器特有的方法(扩展基类接口) */
.yield_task = yield_task_fair,
.check_preempt_curr = check_preempt_wakeup,
};实时调度器子类:rt_sched_class
c
/* kernel/sched/rt.c - 实时调度器具体类定义 */
const struct sched_class rt_sched_class = {
.next = &fair_sched_class, // 继承链:下一个是公平调度器
.enqueue_task = enqueue_task_rt, // 入队方法
.dequeue_task = dequeue_task_rt, // 出队方法
.yield_task = yield_task_rt, // 让出CPU方法
.check_preempt_curr = check_preempt_curr_rt, // 检查抢占方法
.pick_next_task = pick_next_task_rt, // 选择下一个任务
.put_prev_task = put_prev_task_rt, // 放回上一个任务
#ifdef CONFIG_SMP
.select_task_rq = select_task_rq_rt, // 选择运行队列
.set_cpus_allowed = set_cpus_allowed_rt,// 设置CPU亲和性
.rq_online = rq_online_rt, // 运行队列上线
.rq_offline = rq_offline_rt, // 运行队列下线
.task_woken = task_woken_rt, // 任务被唤醒
.switched_from = switched_from_rt, // 从实时调度切换出
#endif
.set_curr_task = set_curr_task_rt, // 设置当前任务
.task_tick = task_tick_rt, // 时间片处理
.get_rr_interval = get_rr_interval_rt, // 获取时间片间隔
.prio_changed = prio_changed_rt, // 优先级改变
.switched_to = switched_to_rt, // 切换到实时调度
.update_curr = update_curr_rt, // 更新当前任务
};关键点 :
每个调度器类的实例化都是全局单例 (整个系统只有一份),c中就是全局变量。
通过 .next指针形成继承链 (实际是优先级链)。
每个函数指针指向具体的实现函数,实现虚函数表。
3 继承 - 调度器类的初始化与层级
3.1 构造阶段:调度器系统的初始化
c
/* kernel/sched/core.c - 调度器系统初始化(构建继承链) */
void __init sched_init(void)
{
int i;
/* 1. 初始化每个CPU的运行队列(数据部分) */
for_each_possible_cpu(i) {
struct rq *rq = cpu_rq(i);
/* 为每个调度器初始化其专有队列 */
init_cfs_rq(&rq->cfs); // 公平调度器队列
init_rt_rq(&rq->rt); // 实时调度器队列
init_dl_rq(&rq->dl); // Deadline调度器队列
rq->curr = rq->idle = &init_task;
}
/* 2. 建立调度器优先级链表(硬编码的继承关系) */
/*
* 这是Linux调度器的"继承链":
* stop -> deadline -> realtime -> fair -> idle
* 高优先级调度器优先于低优先级调度器
*
* 继承关系:stop "继承" dl的调度机会,dl "继承" rt,以此类推
*/
stop_sched_class.next = &dl_sched_class;
dl_sched_class.next = &rt_sched_class;
rt_sched_class.next = &fair_sched_class;
fair_sched_class.next = &idle_sched_class;
idle_sched_class.next = NULL;
/* 3. 初始化各调度器的内部数据结构 */
init_sched_fair_class(); // 初始化公平调度器
init_sched_rt_class(); // 初始化实时调度器
init_sched_dl_class(); // 初始化deadline调度器
}继承设计思想 :通过硬编码的 next指针链表建立调度器的优先级继承关系,实现多级反馈队列调度。
3.2 任务构造:多态的构造函数调用
c
/* kernel/sched/core.c - 任务创建时的调度器初始化 */
int sched_fork(unsigned long clone_flags, struct task_struct *p)
{
unsigned long flags;
/* 重要:任务已经继承了父进程的调度类指针 */
/* 在 copy_process -> dup_task_struct 中复制了:
* p->sched_class = current->sched_class;
* 这就是面向对象中的"对象创建和初始化"
*/
/* 多态调用:调用对应调度类的构造函数 */
if (p->sched_class->task_fork)
p->sched_class->task_fork(p);
return 0;
}可以看到这个就是类似面向对象语言的对象方法调用(.方法),这里是多态,调用各个子类实现的基类方法------task_fork。
公平调度器的构造函数实现:
c
/* kernel/sched/fair.c - 公平调度器的构造函数 */
static void task_fork_fair(struct task_struct *p)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
struct sched_entity *curr;
/* 获取当前CPU的CFS运行队列 */
cfs_rq = task_cfs_rq(current);
curr = cfs_rq->curr;
if (curr) {
/* 继承父进程的vruntime(数据继承) */
se->vruntime = curr->vruntime;
/* 更新当前任务的统计信息 */
update_curr(cfs_rq);
}
/* 调整vruntime,使其相对于队列的最小vruntime */
se->vruntime -= cfs_rq->min_vruntime;
/* 初始化其他调度实体字段(对象初始化) */
se->depth = 0;
se->parent = NULL;
se->cfs_rq = cfs_rq;
se->my_q = NULL;
}面向对象分析 :
构造函数链 :task_fork是调度器的构造函数,每个调度器实现自己的构造逻辑。
多态实现 :通过函数指针实现运行时绑定。
数据继承:子进程继承父进程的调度状态。
4 多态 - 运行时调用的精髓
4.1 运行阶段:时钟中断的多态处理
c
/* kernel/sched/core.c - 时钟中断处理(多态调用点) */
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
/* 更新运行队列时钟 */
update_rq_clock(rq);
/* 多态调用:当前任务的调度类的task_tick方法 */
curr->sched_class->task_tick(rq, curr, 0);
/* 运行时决定:
* 如果curr->sched_class == &fair_sched_class,调用task_tick_fair
* 如果curr->sched_class == &rt_sched_class,调用task_tick_rt
*/
/* 触发负载均衡 */
trigger_load_balance(rq);
}公平调度器的 task_tick 实现(现在包含EEVDF逻辑):
c
/* kernel/sched/fair.c - 公平调度器的时间片处理 */
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;
/* 更新当前任务的统计信息(包含EEVDF的deadline更新) */
update_curr(cfs_rq_of(se));
/* 更新负载平均值 */
update_load_avg(cfs_rq_of(se), se, UPDATE_TG);
/* 如果队列中有多个任务,检查是否需要抢占 */
if (cfs_rq_of(se)->nr_running > 1) {
/* 检查抢占条件 */
check_preempt_tick(rq, curr);
/* 如果应该抢占,设置重新调度标志 */
if (should_resched(0)) {
resched_curr(rq);
}
}
}实时调度器的 task_tick 实现:
c
/* kernel/sched/rt.c - 实时调度器的时间片处理 */
static void task_tick_rt(struct rq *rq, struct task_struct *p, int queued)
{
struct sched_rt_entity *rt_se = &p->rt;
/* 更新实时任务的时间片 */
update_curr_rt(rq);
/* 实时任务不按时间片调度,但需要检查是否应该让出CPU */
if (p->policy != SCHED_RR)
return;
/* RR策略:时间片减少 */
if (--p->rt.time_slice)
return;
/* 时间片用完,重新计算时间片 */
p->rt.time_slice = sched_rr_timeslice;
/* 让出CPU给同优先级的其他任务 */
if (rt_se->run_list.prev != rt_se->run_list.next) {
requeue_task_rt(rq, p, 0);
set_tsk_need_resched(p);
resched_curr(rq);
}
}多态的精髓 :
相同的接口调用 :curr->sched_class->task_tick()。
不同的实现 :公平调度器更新 vruntime,实时调度器更新时间片。
运行时决定:根据 curr->sched_class指针的值决定调用哪个实现。
4.2 核心调度:pick_next_task 的多态
c
/* kernel/sched/core.c - 选择下一个要运行的任务(模板方法) */
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
/* 优化:如果所有任务都是公平调度的 */
if (likely(prev->sched_class == &fair_sched_class &&
rq->nr_running == rq->cfs.h_nr_running)) {
p = fair_sched_class.pick_next_task(rq, prev, rf);
if (likely(p))
return p;// ← 这里调用pick_next_task_fair,内部是EEVDF
}
/* 按优先级遍历所有调度类(多级反馈队列) */
for_each_class(class) {
p = class->pick_next_task(rq, prev, rf);
if (p) {
if (unlikely(p == RETRY_TASK))
goto again;
return p;
}
}
/* 没有任务可运行,返回空闲任务 */
BUG();
}这段代码主要3部分:优化加速调度、遍历所有调度类、返回空闲任务。
这块属于模板模式了------它完全不知道具体调度算法的实现细节。代码固定了。尤其是遍历所有调度器部分------它只是遍历链表,调用接口,至于每个调度器如何选择任务,那是它们的秘密。也就是不管未来增加多少调度策略这块代码始终不变。
5 EEVDF算法 - Linux 7.0 的多态革新
Linux 7.0 的调度器最大变化是用 EEVDF(Earliest Eligible Virtual Deadline First)算法完全取代了使用十几年的 CFS(Completely Fair Scheduler)算法。
关键澄清:EEVDF 不是新调度器,而是公平调度器内部选择算法的升级。
5.1 算法替换的技术真相
很多人误以为 EEVDF 是新调度器,实际上EEVDF 替换 CFS 并不是在某个独立的新文件里,而是直接在原有的 kernel/sched/fair.c中"原地置换"的。核心修改点主要集中在数据结构定义、任务选择逻辑和红黑树排序规则这三个地方。

5.2 替换的具体位置和调用链
调用链分析:
c
调度触发
↓
__schedule() // 调度入口
↓
pick_next_task() // 选择下一个任务
↓
pick_next_task_fair() // 公平调度器的选择函数
↓
pick_next_entity() // ← 核心选择逻辑(这里从CFS变为EEVDF)
↓
pick_eevdf() // EEVDF算法实现
↓
返回选中的任务代码替换点:
c
/* 替换发生在这个函数内部 */
static struct sched_entity *
pick_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
/* Linux 6.x (CFS): 选择vruntime最小的任务 */
// struct sched_entity *left = __pick_first_entity(cfs_rq);
// return left;
/* Linux 7.0 (EEVDF): 调用新的选择逻辑 */
return pick_eevdf(cfs_rq); // ← 这里变了!
}在 kernel/sched/fair.c的 pick_next_entity函数中,旧代码里复杂的 if (cfs_rq->next...)等代码逻辑被大量删除,最后只引用了pick_eevdf调用。可以看到是cfs算法的原地升级和替换,并不是新的调度器类增加。这样的话保证了内核的稳定,如果新增调度器类,那这全球几十年写的上亿的应用层代码都得改,太可怕了。
5.3 EEVDF算法的完整实现
公平调度器的 pick_next_task 实现(EEVDF算法):
c
/* kernel/sched/fair.c - Linux 7.0 的 EEVDF 算法实现 */
static struct sched_entity *pick_eevdf(struct cfs_rq *cfs_rq)
{
struct sched_entity *se = __pick_first_entity(cfs_rq);
struct sched_entity *best = NULL;
s64 min_vruntime = cfs_rq->min_vruntime;
/* 遍历红黑树,找到符合条件的任务 */
while (se) {
/* 计算任务的滞后(lag = vruntime - min_vruntime) */
s64 lag = se->vruntime - min_vruntime;
/* 如果任务滞后 >= 0,说明它"欠"CPU时间 */
if (lag >= 0) {
/* 计算虚拟截止时间 = vruntime + (调度延迟 * 权重因子) */
s64 deadline = se->deadline;
/* 选择虚拟截止时间最早的任务 */
if (!best || deadline < best->deadline)
best = se;
}
se = __pick_next_entity(se);
}
/* 如果没有符合条件的任务,选择vruntime最小的 */
if (!best)
best = __pick_first_entity(cfs_rq);
return best;
}5.4 与CFS算法的对比

多态升级的优势 :
接口不变 :pick_next_task_fair函数签名不变。
实现替换 :内部算法从 CFS 改为 EEVDF。
调用透明 :所有调用者代码无需修改。
平滑升级:系统可以无缝切换到新算法。
5.5 数据结构扩展支持EEVDF
c
/* 调度实体数据结构的变化 */
struct sched_entity {
/* ---------- 原有字段 ---------- */
u64 vruntime; // 虚拟运行时间(保留)
struct rb_node run_node;
/* ---------- EEVDF新增字段 ---------- */
u64 deadline; // 虚拟截止时间 ← 新增
u64 slice; // 分配的时间片 ← 新增
s64 lag; // 滞后值 ← 新增
};红黑树排序规则变化:
c
/* 任务入队时的排序规则 */
static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
// CFS: 按 se->vruntime 排序
// EEVDF: 按 se->deadline 排序 ← 这里变了
}5.6 多态升级的优势体现
EEVDF 替换 CFS 完美展示了面向对象设计的优势:

这就是多态的威力:接口不变,实现可替换,调用者无感知。
6 停止阶段 - 调度器的析构与清理
6.1 任务退出:多态的析构函数调用
c
/* kernel/exit.c - 任务退出处理 */
void do_exit(long code)
{
struct task_struct *tsk = current;
/* 设置退出状态 */
tsk->exit_code = code;
tsk->flags |= PF_EXITING;
/* 多态调用:调度器的析构函数 */
sched_exit(tsk);
/* 调用:tsk->sched_class->task_dead(tsk) */
/* 释放其他资源 */
exit_mm(tsk);
exit_files(tsk);
exit_fs(tsk);
/* 最终调度出去 */
schedule();
}公平调度器的析构函数实现:
c
/* kernel/sched/fair.c - 公平调度器的析构函数 */
static void task_dead_fair(struct task_struct *p)
{
struct cfs_rq *cfs_rq = task_cfs_rq(p);
struct sched_entity *se = &p->se;
/* 从负载平均值中移除 */
remove_entity_load_avg(cfs_rq, se);
/* 减少运行计数 */
cfs_rq->nr_running--;
cfs_rq->h_nr_running--;
/* 如果是组调度,更新组统计 */
if (entity_is_task(se)) {
account_entity_dequeue(cfs_rq, se);
update_load_avg(cfs_rq, se, UPDATE_TG);
}
/* 清理调度实体 */
se->on_rq = 0;
se->vruntime = 0;
}6.2 调度器切换:先析构再构造的多态过程
c
/* kernel/sched/core.c - 切换任务的调度策略(多态切换) */
static int __sched_setscheduler(struct task_struct *p,
const struct sched_attr *attr,
bool user, bool pi)
{
const struct sched_class *old_class = p->sched_class;
struct rq *rq = task_rq(p);
/* 1. 从旧调度类切换出(调用析构相关方法) */
if (old_class != p->sched_class) {
if (old_class->switched_from)
old_class->switched_from(rq, p);
}
/* 2. 修改调度类指针(改变多态绑定) */
switch (attr->sched_policy) {
case SCHED_NORMAL:
case SCHED_BATCH:
case SCHED_IDLE:
p->sched_class = &fair_sched_class; // 绑定到公平调度器
break;
case SCHED_FIFO:
case SCHED_RR:
p->sched_class = &rt_sched_class; // 绑定到实时调度器
break;
case SCHED_DEADLINE:
p->sched_class = &dl_sched_class; // 绑定到deadline调度器
break;
}
/* 3. 切换到新调度类(调用构造相关方法) */
if (old_class != p->sched_class) {
if (p->sched_class->switched_to)
p->sched_class->switched_to(rq, p);
}
/* 4. 用新调度类重新入队 */
p->sched_class->enqueue_task(rq, p, ENQUEUE_RESTORE | ENQUEUE_NOCLOCK);
return 0;
}公平调度器的切换回调实现(switched_from 和 switched_to):
c
/* kernel/sched/fair.c - 调度器切换的回调 */
static void switched_from_fair(struct rq *rq, struct task_struct *p)
{
struct sched_entity *se = &p->se;
struct cfs_rq *cfs_rq = cfs_rq_of(se);
/* 从公平调度器切换出时的清理工作 */
if (se->on_rq) {
update_load_avg(cfs_rq, se, 0);
dequeue_entity(cfs_rq, se, DEQUEUE_SLEEP);
cfs_rq->nr_running--;
}
}
static void switched_to_fair(struct rq *rq, struct task_struct *p)
{
struct sched_entity *se = &p->se;
/* 切换到公平调度器时的初始化工作 */
if (p->on_rq) {
update_load_avg(cfs_rq_of(se), se, UPDATE_TG);
if (rq->curr == p) {
check_preempt_curr(rq, p, 0);
} else {
enqueue_entity(cfs_rq_of(se), se, 0);
cfs_rq_of(se)->nr_running++;
}
}
}7 面向对象设计模式的应用
7.1 策略模式(Strategy Pattern)的完美体现
策略模式是 Linux 调度器面向对象设计的核心体现,它不仅定义了算法族的抽象,还自然地实现了策略与数据的分离。
调度器策略部分 :调度器基类sched_class (即接口类 )和各个调度器子类。这部分是算法接口约定和纯算法实现部分(意思是没有数据,比如只有菜谱,没有菜)。
数据部分:每cpu的各调度类的运行队列数据(每道菜做的顺序,订单顺序,排队做菜的列表),每个任务task_struct中的调度实体数据(每道菜)。
7.1.1 策略模式的定义与实现
定义:定义一系列算法,将每个算法封装起来,使它们可以相互替换,让算法的变化独立于使用算法的客户端。
在调度器中的实现:
c
/* 1. 策略接口 - 定义算法族的抽象 */
struct sched_class {
/* 策略方法:定义调度算法的标准接口 */
struct task_struct *(*pick_next_task)(struct rq *rq);
void (*enqueue_task)(struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task)(struct rq *rq, struct task_struct *p, int flags);
void (*task_tick)(struct rq *rq, struct task_struct *p, int queued);
};
/* 2. 具体策略1:公平调度策略(7.0是EEVDF算法,但是接口未变) */
const struct sched_class fair_sched_class = {
.pick_next_task = pick_next_task_fair, // EEVDF算法实现
.enqueue_task = enqueue_task_fair, // 红黑树入队算法
.dequeue_task = dequeue_task_fair, // 红黑树出队算法
.task_tick = task_tick_fair, // 时间片处理算法
};
/* 3. 具体策略2:实时调度策略(优先级算法) */
const struct sched_class rt_sched_class = {
.pick_next_task = pick_next_task_rt, // 优先级轮转算法
.enqueue_task = enqueue_task_rt, // 优先级数组入队
.dequeue_task = dequeue_task_rt, // 优先级数组出队
.task_tick = task_tick_rt, // 实时时间片处理
};
/* 4. 上下文:持有策略引用 */
struct task_struct {
const struct sched_class *sched_class; // 指向当前使用的策略
/* 策略专有的数据结构 */
union {
struct sched_entity se; // 公平调度数据
struct sched_rt_entity rt; // 实时调度数据
};
};7.1.2 策略与数据的自然分离
策略模式在调度器中自然地实现了策略与数据的分离:
c
/* 策略层:算法实现(全局,不可变) */
const struct sched_class fair_sched_class = { // 整个系统一份
.pick_next_task = pick_next_task_fair, // 算法代码
.enqueue_task = enqueue_task_fair, // 算法代码
/* 策略是编译时确定的机器指令 */
};
/* 数据层:运行时状态(每CPU,可变) */
struct rq { // 每个CPU有独立的数据实例
struct cfs_rq cfs; // CPU0的公平调度数据
struct rt_rq rt; // CPU0的实时调度数据
/* 数据是运行时变化的状态 */
};
/* 策略操作数据的典型模式 */
static struct task_struct *
pick_next_task_fair(struct rq *rq) // 策略函数,参数是数据
{
/* 1. 策略获取数据 */
struct cfs_rq *cfs_rq = &rq->cfs; // 获取当前CPU的数据
/* 2. 策略算法处理数据 */
struct sched_entity *se = pick_eevdf(cfs_rq); // EEVDF算法
/* 3. 返回结果 */
return task_of(se);
}7.1.3 分离的优势:EEVDF 替代 CFS 的平滑升级
Linux 7.0 用 EEVDF 算法替代 CFS,完美展示了策略与数据分离的价值:
c
/* Linux 6.x: CFS算法(旧策略) */
static struct sched_entity *pick_next_entity(struct cfs_rq *cfs_rq)
{
/* CFS策略:选择vruntime最小的任务 */
return __pick_first_entity(cfs_rq);
}
/* Linux 7.0: EEVDF算法(新策略) */
static struct sched_entity *pick_eevdf(struct cfs_rq *cfs_rq)
{
/* EEVDF策略:先看谁"欠"CPU时间,再选截止时间最早的 */
struct sched_entity *se, *best = NULL;
s64 min_vruntime = cfs_rq->min_vruntime;
for (se = __pick_first_entity(cfs_rq); se; se = __pick_next_entity(se)) {
s64 lag = se->vruntime - min_vruntime;
if (lag >= 0) { // 只考虑"欠"CPU时间的任务
s64 deadline = se->deadline;
if (!best || deadline < best->deadline)
best = se;
}
}
if (!best) // 回退机制
best = __pick_first_entity(cfs_rq);
return best;
}升级过程中的分离体现:

7.1.4 内存布局与性能优化
策略与数据的分离带来了显著性能优势:
c
/* 内存布局优化 */
每个CPU的数据布局:
┌─────────────────────────────────┐
│ CPU0的struct rq @ 0xffff8a3fc0005a00│
│ ├── struct cfs_rq cfs │ ← 策略频繁访问,缓存友好
│ │ ├── min_vruntime │
│ │ ├── tasks_timeline (红黑树) │
│ │ └── nr_running │
│ └── struct rt_rq rt │
├─────────────────────────────────┤
│ CPU1的struct rq @ 0xffff8a3fc0007a00│
│ ├── struct cfs_rq cfs │ ← 独立数据,无锁访问
│ └── struct rt_rq rt │
└─────────────────────────────────┘
策略代码布局:
┌─────────────────────────────────┐
│ fair_sched_class @ 0xffffffff81a2b2c0│
│ ├── pick_next_task_fair │ ← 代码段,只读,多CPU共享
│ ├── enqueue_task_fair │
│ └── ... │
└─────────────────────────────────┘性能优势:
缓存局部性:每个CPU的策略频繁访问自己的数据,缓存命中率高。
无锁并发:不同CPU操作不同数据实例,无需加锁同步。
代码共享:策略代码只读,所有CPU共享同一份指令。
数据隔离:一个CPU的调度不会影响其他CPU的数据。
7.1.5 策略模式的运行时动态性
任务可以运行时切换调度策略,这是策略模式的动态体现:
c
/* 动态切换调度策略 */
static int __sched_setscheduler(struct task_struct *p, int policy)
{
const struct sched_class *old_class = p->sched_class;
/* 1. 从旧策略切换出 */
if (old_class->switched_from)
old_class->switched_from(rq, p);
/* 2. 切换到新策略 */
switch (policy) {
case SCHED_NORMAL:
p->sched_class = &fair_sched_class; // 切换到公平调度
break;
case SCHED_FIFO:
p->sched_class = &rt_sched_class; // 切换到实时调度
break;
}
/* 3. 新策略的初始化 */
if (p->sched_class->switched_to)
p->sched_class->switched_to(rq, p);
return 0;
}7.1.6 设计优势总结
策略模式在调度器中实现了以下优势:
算法可替换 :CFS → EEVDF 的平滑升级证明了算法的可替换性。
数据不变性 :算法变更时,数据结构保持稳定。
接口稳定 性:策略接口成为系统稳定的契约。
运行时灵活性 :任务可动态切换调度策略。
并发优化 :策略与数据分离支持每CPU数据布局。
扩展性:新增调度策略只需实现接口,不修改核心框架。
策略模式不仅仅是"定义算法族",更重要的是通过算法与数据的分离,创造了系统演化的弹性。Linux调度器的成功证明,良好的策略模式实现必然导致策略与数据的清晰分离,这是系统长期可维护、可演化的关键。
7.2 模板方法模式(Template Method Pattern)
定义:定义算法的骨架,将一些步骤延迟到子类中实现。
在调度器中的实现:
c
/* 模板方法:__schedule定义调度的固定骨架 */
static void __schedule(bool preempt)
{
/* 固定步骤1:保存当前任务 */
prev = rq->curr;
/* 固定步骤2:调用策略特定的put_prev_task */
prev->sched_class->put_prev_task(rq, prev);
/* 固定步骤3:调用策略特定的pick_next_task(可变步骤) */
next = pick_next_task(rq, prev, NULL);
/* 固定步骤4:调用策略特定的set_next_task */
if (next->sched_class->set_next_task)
next->sched_class->set_next_task(rq, next, true);
/* 固定步骤5:上下文切换(固定步骤) */
context_switch(rq, prev, next);
}
/* 子类实现可变步骤 */
// fair_sched_class 实现自己的 pick_next_task_fair(EEVDF算法)
// rt_sched_class 实现自己的 pick_next_task_rt(优先级算法)6.3 工厂方法模式(Factory Method Pattern)
定义:定义一个创建对象的接口,让子类决定实例化哪个类。
在调度器中的实现:
c
/* 工厂方法:根据策略类型创建对应的调度类实例 */
static const struct sched_class *sched_class_factory(int policy)
{
switch (policy) {
case SCHED_NORMAL:
case SCHED_BATCH:
case SCHED_IDLE:
return &fair_sched_class; // 生产公平调度器
case SCHED_FIFO:
case SCHED_RR:
return &rt_sched_class; // 生产实时调度器
case SCHED_DEADLINE:
return &dl_sched_class; // 生产deadline调度器
default:
return &fair_sched_class; // 默认生产公平调度器
}
}8 调度器的可扩展性设计
8.1 如何添加新的调度器(面向对象的扩展性)
c
/* 步骤1:定义新的调度器类(实现sched_class接口) */
const struct sched_class my_sched_class = {
.next = &fair_sched_class, // 插入到继承链
/* 实现所有接口方法(多态的基础) */
.enqueue_task = my_enqueue_task,
.dequeue_task = my_dequeue_task,
.pick_next_task = my_pick_next_task,
.task_fork = my_task_fork, // 构造函数
.task_dead = my_task_dead, // 析构函数
.task_tick = my_task_tick, // 运行时方法
// ... 实现其他接口
};
/* 步骤2:修改优先级链表(调整继承关系) */
// 在 sched_init 中修改:
rt_sched_class.next = &my_sched_class; // 实时调度器后面
my_sched_class.next = &fair_sched_class; // 新调度器后面是公平调度器
/* 步骤3:完成!核心代码无需修改 */8.2 调度器的模块化架构(封装的体现)
c
Linux调度器模块化架构:
┌─────────────────────────────────────┐
│ 核心调度框架 (core.c) │
│ • 提供调度机制 │
│ • 管理调度器优先级链 │
│ • 提供通用调度接口 │
│ • 不包含具体算法实现 │
└───────────────────┬─────────────────┘
│
│ 通过sched_class接口调用
│ (面向接口编程,不依赖具体实现)
▼
┌─────────────────────────────────────┐
│ 调度器接口层 (sched.h) │
│ • 定义调度器标准接口 │
│ • 提供多态调用机制 │
│ • 管理调度器实例 │
└───────────────────┬─────────────────┘
│
│ 多态调用具体实现
│ (运行时绑定)
▼
┌───────┬──────────┬──────────┬───────┐
│ 实时 │ 公平 │ Deadline │ 自定义│
│调度器 │ 调度器 │ 调度器 │ 调度器│
│ (rt.c)│ (fair.c) │ (dl.c) │ (my.c)│
│ │ │ │ │
│ •优先级│ •EEVDF │ •EDF算法 │ •自定义│
│ 调度 │ 算法 │ │ 算法 │
│ │ (Linux 7)│ │ │
└───────┴──────────┴──────────┴───────┘
封装:每个调度器独立实现,内部细节隐藏
继承:通过next指针形成优先级链
多态:通过接口统一调用9 总结
9.1 Linux 调度器的面向对象特性总结
封装(Encapsulation) :
每个调度器的实现封装在独立的文件中。
调度器内部数据结构对外隐藏。
通过接口访问调度器功能。
继承 (Inheritance):
通过 next指针实现调度器优先级链。
所有调度器实现相同的接口。
高优先级调度器继承调度机会。
多态(Polymorphism) :
通过函数指针实现运行时绑定。
相同接口,不同实现。
新增调度器不影响现有代码。
9.2 关键设计模式
c
/* 模式1:结构体+函数指针=虚函数表 */
struct sched_class { // 虚函数表
void (*enqueue_task)(...); // 虚函数指针
struct task_struct *(*pick_next_task)(...); // 虚函数指针
};
/* 模式2:全局实例=具体类对象 */
const struct sched_class fair_sched_class = { // 具体类实例
.enqueue_task = enqueue_task_fair, // 实现虚函数
.pick_next_task = pick_next_task_fair, // 实现虚函数
};
/* 模式3:指针关联=对象引用 */
struct task_struct {
const struct sched_class *sched_class; // 引用具体类对象
};
/* 模式4:函数指针调用=多态 */
p->sched_class->enqueue_task(rq, p, flags); // 多态调用9.3 对现代软件开发的启示
面向对象是思想,不是语法 :
用 C 语言也能实现优雅的面向对象设计。
关键在于接口设计,不是语言特性。
Linux用700万行代码证明:好的架构不依赖语法糖。
接口设计的重要性 :
好的接口让系统易于扩展(新增调度器只需实现接口)。
接口应该稳定,实现可以变化(EEVDF替换CFS,接口不变)。
面向接口编程,不依赖具体实现。
多态的价值 :
提高代码复用性(核心调度框架不关心具体算法)。
降低模块耦合度(调度器之间独立)。
支持运行时灵活配置(任务可动态切换调度器)。
Linux 的哲学 :
机制与策略分离(框架提供机制,调度器实现策略)。
提供机制,策略可替换(EEVDF替代CFS)。
通过接口实现解耦(sched_class接口)。
9.4 EEVDF算法的面向对象意义
Linux 7.0 用EEVDF算法完全取代CFS,这个变更完美展示了面向对象设计的优势:
接口不变 :pick_next_task_fair函数签名不变。
实现替换 :内部算法从CFS改为EEVDF。
平滑升级 :所有调用者代码无需修改。
性能提升:尾延迟降低89%,用户无感知升级。
这证明了:良好的面向对象设计让系统能够优雅地进化,即使替换核心算法,也能保持接口稳定,实现平滑过渡。
9.5 最后的总结
Linux调度器的设计告诉我们:优秀的软件架构不依赖于高级语言特性,而依赖于清晰的设计思想和严谨的工程实践。
通过结构体封装数据、函数指针实现多态、链表实现继承,Linux用最朴素的C语言工具,构建了最优雅的面向对象系统。这不仅是技术实现的典范,更是软件工程哲学的体现:
简单性 :用简单机制解决复杂问题。
可扩展性 :通过接口和继承支持无限扩展。
可维护性 :模块化设计降低维护成本。
性能:面向对象不意味着性能损失。
Linux调度器的面向对象设计,是Linux内核可维护、可扩展、高性能的基石,也是每个软件工程师都应该学习的架构典范。