半夜三点,Grafana 大盘上 GPU 利用率持续在 15% 上下浮动。
你盯着屏幕:算力没问题,显存没爆,loss 曲线也正常------训练就是慢得离谱。
这时候你基本可以断定:卡的不是 GPU,是 GPU 之间那根线。
大模型训练时代,"通信瓶颈"这四个字几乎是每个 Infra 工程师的口头禅。但真正能把这件事讲透、定位准、调得动的人,其实没那么多。很多人遇到训练慢,第一反应是去调 batch size、去换 optimizer、甚至去怀疑显卡------折腾三天,最后发现是交换机某个端口的 PFC 没配对。
这篇文章我想和同行聊聊自己在一线排查通信瓶颈时常用的一套 SOP。它不是理论,是血淋淋踩过坑之后沉淀下来的工作流。如果你正在做大规模分布式训练、正在为集群 MFU 上不去发愁,这篇值得你花十分钟看完。
一、先立规矩:排查通信瓶颈不能靠猜
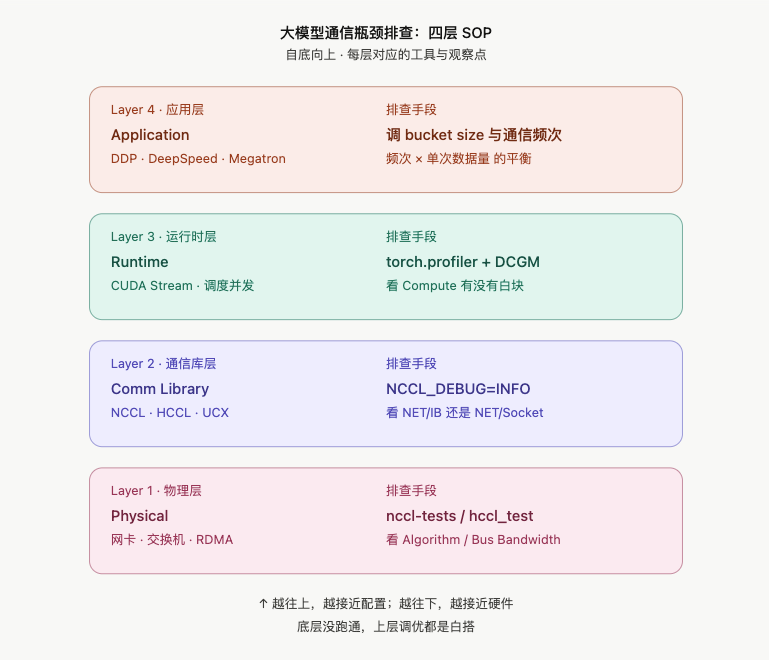
分布式训练里的通信栈,从下到上大概可以分成四层:
- 物理层:网卡(RDMA / RoCE / IB)、交换机、光模块
- 通信库层:NCCL(或华为昇腾的 HCCL)、UCX、Gloo
- 运行时层:CUDA 调度、Stream 并发、Profiler 埋点
- 应用层:PyTorch DDP / DeepSpeed / Megatron 的通信策略
每一层都可能成为瓶颈,而且症状往往长得很像------都是"GPU 利用率低"。但治疗方案天差地别:物理层问题得找运维改交换机,通信库问题得改环境变量,应用层问题得改配置。
所以排查顺序必须是自底向上,先确认底层没病,再往上查。下面这套 SOP 就是按这个顺序展开的。
你的 GPU 为什么只能跑 20%?大模型训练通信瓶颈的四层
二、第一层:nccl-tests ------ 摸清物理网络的真实底牌
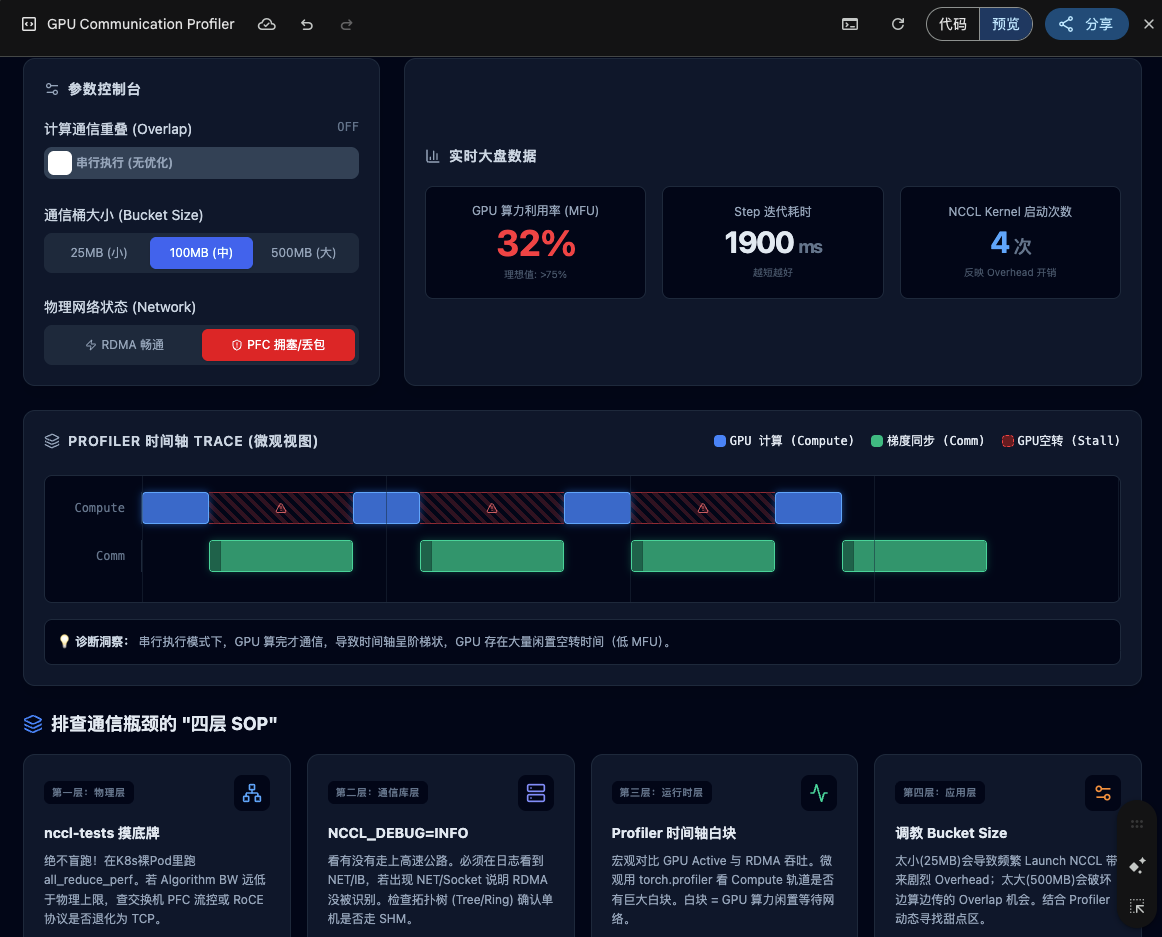
在真正跑大模型之前,绝对不能盲跑,必须先摸底物理网络的真实带宽。
用的工具是英伟达官方的 nccl-tests,重点跑两个:all_reduce_perf 和 all_gather_perf。直接在 K8s 裸 Pod 里拉起,跨多台宿主机测。
看两个关键指标:**Algorithm Bandwidth(算法带宽)**和 Bus Bandwidth(总线带宽)。
举个例子:你机器上插的是 400G RDMA/RoCE 网卡,理论物理上限大概是 50 GB/s。如果 nccl-tests 跑出来只有几 GB/s,基本可以锁定两个典型问题:
- 交换机的 PFC 流控没配好,触发了大规模重传
- RoCE 协议没通,协议栈退化成了普通 TCP,彻底失去 RDMA 的意义
这两个问题你在训练日志里完全看不出来,但它们会让你 100 万一张的卡跑成 1 万块钱的卡。所以这一步是所有排查的起点------物理底牌不清,后面一切都是沙上建塔。
顺便说一句:如果你在昇腾集群上排查,对应的工具是华为的
hccl_test,思路完全一致。
三、第二层:NCCL_DEBUG=INFO ------ 看 NCCL 有没有走上高速公路
有时候物理层明明没问题(nccl-tests 跑得漂亮),但训练速度就是慢------十有八九是 NCCL 没走最优路径。
这时候开一个开关就行:
export NCCL_DEBUG=INFO
export NCCL_DEBUG_SUBSYS=INIT,ENV在 K8s 的 Pod yaml 或者 Ray 任务的 env 里注入,然后去扒 Worker 节点的 stdout 日志。你要像鹰眼一样盯这几个关键词:
第一,看 NET/IB 还是 NET/Socket。 这是最关键的一条。如果日志里显示 NET/Socket,说明你的 RDMA 网卡根本没被识别,NCCL 正在用极慢的传统 TCP 通信------所有网卡投资瞬间打水漂。必须看到 NET/IB,才说明走上了 RDMA 高速公路。
第二,看 SHM(Shared Memory)。 这是判断单机内部多卡有没有走共享内存通信。如果同机多卡居然走网络,单机效率也崩了。
第三,看拓扑树(Tree/Ring)。 NCCL 启动时会自动构建通信环,拓扑会打印在日志里。如果你看到拓扑奇怪------比如同一台机器的卡先跑到别的机器绕一圈再回来------就该上手调 NCCL_TOPO_FILE 了。
NCCL 的日志是你跟它沟通的唯一方式。 不看日志就盲调环境变量,和不看仪表盘开车没什么区别。
四、第三层:宏观大盘 + 微观 Profiler ------ 定位瓶颈在哪一行代码
前两层确认底层 OK 之后,训练还是慢,就要进入运行时诊断。这一步分宏观和微观两层看。
宏观:大盘看"有没有"通信瓶颈
不用重新发明轮子:Prometheus + Grafana + NVIDIA DCGM Exporter 就够用。关注两个指标的对比:
- GPU 算力利用率(SM Active)
- 网卡吞吐量(RDMA / NVLink / PCIe 的 Tx/Rx)
经典的通信瓶颈画像是这样的:GPU 算力利用率经常掉到 20% 以下,而网卡吞吐长期顶在红线上。这两条曲线一组合,基本就是 Communication Bound 实锤。
微观:Profiler 看"卡在哪一行代码"
大盘能告诉你"有问题",但具体卡在哪一行,需要 torch.profiler(或 DeepSpeed 自带的 Flops Profiler)。在训练代码里埋点,把 trace 导出成 JSON,拖到 Chrome 的 chrome://tracing 或 Perfetto 网站里看。
你会看到时间轴上有两种色块:
- Compute Stream(计算流) :
gemm、matmul、relu等 GPU 算子 - Communication Stream(通信流) :
ncclAllReduce、ncclAllGather等
重点看三件事:nccl:all_reduce / nccl:all_gather 的色块有多长?这些色块执行期间 Compute Stream 是不是空白?通信时间占整个 step 的百分比是多少?
如果你发现 AllGather 占了前向传播的大半时间、Compute 轨道全是白块------实锤通信瓶颈。对开了 ZeRO-3 的训练这个问题尤其典型,因为它每次前向都要 AllGather 拉取参数,网络一跟不上,整个集群就在那等。
这时候你有两条出路:要么开 CPU Offload 减小通信量,要么优化计算通信重叠(Overlap)。
GPU 计算与通信重叠模拟器
五、第四层:Bucket Size ------ 最容易被忽略的一颗旋钮
很多人排查到 Profiler 那一步就收工了。但我想讲一个特别容易被忽略的优化点:Bucket Size。
概念不复杂。为了防止网络被海量小通信请求冲垮,PyTorch 会把梯度塞进"桶(Bucket)"里,桶满了再统一发一次 AllReduce。
在哪调:
- 原生 DDP :初始化时的
bucket_cap_mb参数(默认 25 MB) - DeepSpeed :
ds_config.json里的reduce_bucket_size和allgather_bucket_size(通常默认 500M 起步)
为什么这件事重要?举一个真实场景:
你有一个 Billion 参数级别的模型,用默认 25MB 的 bucket size。一轮反向传播会触发成百上千次 小 AllReduce。每次 NCCL Kernel 启动都有几十微秒的固定开销。加起来------Kernel Launch Overhead 就能吃掉几百毫秒的迭代时间。
调大到 50--100 MB,通信频次降下来、单次传输数据量变大,才能真正吃满网卡带宽。
但也不是越大越好。无限调大会带来两个副作用:一是内存飙升,二是破坏"边算边传"的 Overlap 机会------一个大 bucket 要等所有梯度都算完才能发,前面先算完的梯度就只能干等。
所以 bucket size 没有放之四海皆准的值,它是个需要边看 Profiler 边调的参数。这也是为什么很多厂商的"推荐配置"到你集群上就不好用------因为别人家的瓶颈和你的不在同一个地方。
六、延伸:怎么在 Profiler 里判断"重叠"做得好不好
前面好几次提到 Compute 和 Communication 的重叠。这是整个通信优化的核心目标,单独拿出来讲讲判断方法。
在 Profiler 的时间轴上,横轴是时间,纵轴是不同的 Stream 轨道。重叠做得好不好,在这张图上一眼可见。
极差的重叠(串行执行) :Compute 轨道的色块结束了,Communication 轨道才开始;通信结束了,下一段 Compute 才开始。Compute 轨道上充满巨大的白块------GPU 在干等。
极好的重叠 :Compute 轨道密密麻麻塞满算子(GPU 几乎 100% 满载),正下方的 Communication 轨道也在同时跑 ncclAllReduce。通信时间被完美地藏进了计算时间里,用户感知不到它的存在。
这就是为什么"开 ZeRO 优化"、"调合理 bucket size"、"开通信 overlap"听起来像玄学------实际上它们都在干同一件事:消除 Compute 轨道上的白块。
我有个简单的方法判断一个 Infra 工程师的调优水平:把他调优前后的 Profiler 截图并排放。白块变少了多少,水平就有多少。
七、写在最后
做大规模分布式训练这几年,我越来越觉得:通信瓶颈的排查,本质上是一个"自底向上"的显微镜工作。
- 物理层没跑通,上层再优化都是白搭
- 通信库没走对,Profiler 再漂亮也藏着惊雷
- 运行时不看 Trace,就是盲人摸象
- 应用层参数不调,再好的底层也发挥不出来
这四层逐级排查下来,你会慢慢形成一种**"哪里痛就扎哪里"的直觉**------看一眼 Grafana 就知道是网卡问题还是算力问题,扫一眼 NCCL 日志就知道要不要调拓扑,瞄一眼 Profiler 就知道是 bucket 问题还是 overlap 问题。
这不是玄学,是大量盲区被逐一照亮之后的自然结果。
这篇文章里的每一个命令、每一条日志、每一个参数,都来自我(和同行们)在集群上踩过的真实坑。大模型这几年硬件堆得越来越猛,但系统侧的收益远远没有被榨出来------很多集群的 MFU 之所以只有 15%,不是因为硬件不行,是因为没人把通信栈真正调一遍。
如果你也有排查通信瓶颈的神奇故事,欢迎在评论区分享。集群这东西,坑多得够聊一整年。
如果觉得有帮助,点个赞/收藏/转发。后续我会继续分享 AI Infra、集群运维、大模型训练优化的实战经验。