之前提到nccl有多种协议,并且主要以simple协议为例介绍nccl的流程,本节我们具体看下simple之外的LL和LL128协议,LL是low latency的缩写,表示低延迟。
协议在这里是指当前rank发送数据给peer的时候,peer如何知道数据已经可见,simple的做法是当前rank先发data,再执行fence_sys,最后发flag,peer轮询flag,当轮询到flag的时候就可以知道data已经可见,但是fence_sys是个耗时的操作,nccl通过拆分出单独的warp执行fence,这样数据量大的时候可以和data发送overlap起来,但是数据量小的时候还是无法隐藏fence_sys的延迟。
为了解决这个问题,nccl引入了LL和LL128,核心思想是将data和flag编码到一起,然后发送给peer,因为gpu可以保证8B写的原子性,因此LL的编码为4B data + 4B的flag,这样当peer轮询到flag的时候就知道data可见了,LL的带宽利用率为50%。LL128用于平衡带宽和延迟,保证在获得高带宽的时候同时延迟比simple低,编码格式为120B data + 8B flag,但是LL128使用条件会很严格,只有整条链路上都能做到128B的顺序一致性才可以使用。
单机LL
cpp
union ncclLLFifoLine {
struct {
uint32_t data1;
uint32_t flag1;
uint32_t data2;
uint32_t flag2;
};
uint64_t v[2];
int4 i4;
};
static constexpr int EltPerLine = sizeof(uint64_t)/sizeof(T);ncclLLFifoLine编码了data和flag,一个线程一次写一个Line,大小为16B,线程tid处理偏移为tid的line。EltPerLine表示一个line中可以容纳几个用户的elem,由于16B中只有8B是data,因此为sizeof(uint64_t)/sizeof(T)。
然后看下prims_ll.h,先看下构造函数,这个和之前simple的基本一致。
cpp
__device__ Primitives(...):
redOp(redOpArg),
tid(tid), nthreads(nthreads), wid(tid%WARP_SIZE), group(group),
stepLines(ncclShmem.comm.buffSizes[NCCL_PROTO_LL]/NCCL_STEPS/sizeof(ncclLLFifoLine)) {
auto *channel = &ncclShmem.channel;
int nrecv=0, nsend=0;
while (nrecv < Fan::MaxRecv && recvPeers[nrecv] >= 0) {
loadRecvConn(&channel->peers[recvPeers[nrecv]]->recv[connIndexRecv], nrecv);
nrecv++;
}
while (nsend < MaxSend && sendPeers[nsend] >= 0) {
loadSendConn(&channel->peers[sendPeers[nsend]]->send[connIndexSend], nsend);
nsend++;
}
loadRecvSync();
loadSendSync();
setDataPtrs(inputBuf, outputBuf);
}wid为lane_id,stepLines表示fifo中一个slot可以容纳多少个line,然后开始load send和recv conn,和simple一样的,第一个warp的tidi负责第i个send peer的同步,最后一个warp的tidi负责第i个recv peer的同步。setDataPtrs记录了用户的输入输出buffer到userBufs。
cpp
template <int RECV, int SEND, int SrcBuf, int DstBuf>
__device__ __forceinline__ void LLGenericOp(intptr_t srcIx, intptr_t dstIx, int nelem, bool postOp) {
constexpr int SRC = SrcBuf != -1 ? 1 : 0;
constexpr int DST = DstBuf != -1 ? 1 : 0;
T *srcElts = SrcBuf == -1 ? nullptr : userBufs[SrcBuf] + srcIx;
T *dstElts = DstBuf == -1 ? nullptr : userBufs[DstBuf] + dstIx;
nelem = nelem < 0 ? 0 : nelem;
if (SEND) waitSend(divUp(nelem, EltPerLine)*sizeof(ncclLLFifoLine));
nelem -= tid*EltPerLine;
srcElts += tid*EltPerLine;
dstElts += tid*EltPerLine;
int offset = tid;
int eltPerTrip = nthreads*EltPerLine;然后看下LLGenericOp,用户所有的操作都会使用LLGenericOp,一次 LLGenericOp对应一个step,即一个slot,RECV表示是否需要接收上一个rank发送过来的数据,同理SEND,SrcBuf表示输入的用户数据来自哪个buffer,-1表示不需要用户数据,Input表示输入来自用户的输入,Output表示输入来自用户的输出,同理DstBuf。srcIx表示在userBufsSrcBuf中的偏移量,同理dstIx。
通过waitSend等待peer有空闲slot,因为用户想要发送的数据量为nelem,因此总线实际产生nelem / EltPerLine个line,再乘以line的size得到总的发送数据量。
然后开始所有线程循环执行数据的发送过程,一次循环中,每个线程发送一个line,对应了EltPerLine个elem,所以tid在srcElts的偏移就是tid*EltPerLine,eltPerTrip就是所有线程一次循环可以发送多少个elem。
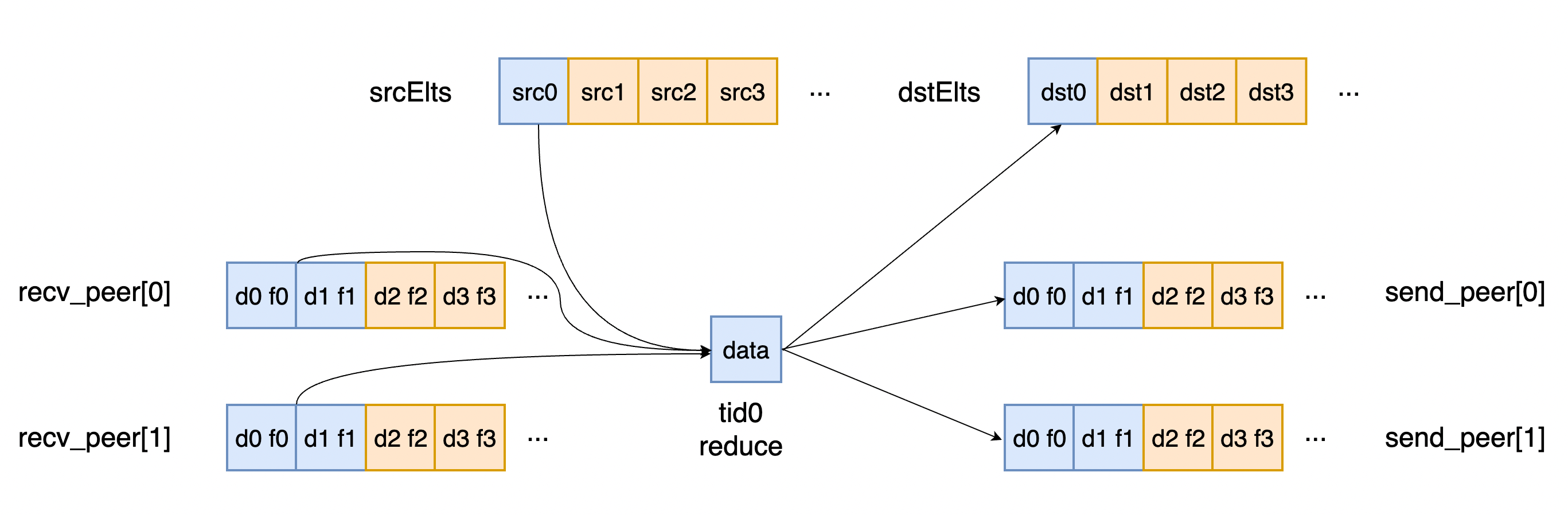
图 1
然后while循环执行数据的接收与发送,如图1所示,一个方块代表uint64大小,一共有nrecv个recv peer,一个线程在一次循环中会处理每个recv peer发送过来数据中的一个line,如recv_peer0中蓝色对应的就是一个line,tid0处理src和recv peer中所有蓝色数据,然后将这些line和用户输入的srcElts全部执行reduce,得到data,然后再发送给dstElts和所有的send peer。eltInLine表示当前线程本次实际需要处理多少个elem,data为从input中load到的数据。
为了性能考虑,nccl会尽量使用大的io指令来load数据,但是由PTX可知,访问的地址必须对齐访问的宽度,否则会产生未定义的行为。
The address must be naturally aligned to a multiple of the access size. If an address is not properly aligned, the resulting behavior is undefined. For example, among other things, the access may proceed by silently masking off low-order address bits to achieve proper rounding, or the instruction may fault.
LL尝试至少使用4字节访问指令,并通过引入DataLoader来处理srcElts对齐和非对齐两种场景。
cpp
struct DataLoader {
int misalign;
union {
uint32_t u4[sizeof(T) <= 2 ? 3 : 2];
uint64_t u8;
T elt[EltPerLine];
};
__device__ void loadBegin(T *src, int eltN) {
if (sizeof(T) <= 2) {
misalign = reinterpret_cast<uintptr_t>(src)%4;
uint32_t *p = reinterpret_cast<uint32_t*>(reinterpret_cast<uintptr_t>(src) & -uintptr_t(4));
u4[0] = load(p+0);
u4[1] = misalign + eltN*sizeof(T) > 4 ? load(p+1) : 0;
u4[sizeof(T) <= 2 ? 2 : 0] = misalign + eltN*sizeof(T) > 8 ? load(p+2) : 0;
}
else {
for(int i=0; i < EltPerLine; i++) {
if(i==0 || i < eltN)
elt[i] = load(src + i);
}
}
}
__device__ uint64_t loadFinish() {
if (sizeof(T) <= 2) {
u4[0] = __funnelshift_r(u4[0], u4[1], 8*misalign);
u4[1] = __funnelshift_r(u4[1], u4[sizeof(T) <= 2 ? 2 : 0], 8*misalign);
}
return u8;
}
};DataLoader一次会从srcElts中读取到一个line的elem,即uint64大小,union用于存储load的结果,如果非4字节对齐,那么需要从对齐的位置开始load,此时union需要3个uint32。
先看下loadBegin,如果T的类型小于等于2字节,那么需要考虑非4字节对齐的情况,misalign如果不为0,说明非对齐,需要将src下调到4字节对齐的位置p开始load。如果是对齐的,那么直接load即可。
cpp
template<typename U>
__device__ static U load(U *src) {
else if(sizeof(U) == 4)
asm volatile("ld.volatile.global.b32 %0,[%1];" : "=r"(u4) : "l"(src) : "memory");
else
asm volatile("st.volatile.global.b64 [%0],%1;" :: "l"(dst), "l"(u8) : "memory");
}然后看下loadFinish,如果为非对齐场景,那么通过__funnelshift_r(lo, hi, shift) 把 {hi, lo} 拼成 64 位然后右移 shift 位,取低 32 位。这样就把数据移到正确的位置,消除未对齐的部分。如果是对齐的,直接返回u8即可。
load拆分为为loadBegin和loadFinish,是为了隐藏load的延迟,通过在loadBegin和loadFinish之间插入readLL这一寄存器无关的指令,可以将load和readLL并行。
cpp
void LLGenericOp(...) {
while (nelem > 0) {
int eltInLine = EltPerLine < nelem ? EltPerLine : nelem;
DataLoader dl;
ncclLLFifoLine line[MaxRecv];
uint64_t data, peerData;
if (SRC) {
dl.loadBegin(srcElts, eltInLine);
srcElts += eltPerTrip;
}
if (RECV) {
readLLBeginAll<1>(offset, line);
peerData = readLL(offset, 0);
}
if (SRC) {
data = dl.loadFinish();
if (SrcBuf == Input) data = applyPreOp(redOp, data);
}
}
}回到LLGenericOp,因为一个线程处理一个line,线程tid处理偏移为tid的line,因此offset即tid。通过loadBegin发起对srcElts的load,然后开始执行readLLx系列指令来轮询recv peer的数据是否到达。
cpp
__device__ uint64_t readLL(int offset, int i) {
union ncclLLFifoLine* src = recvPtr(i) + offset;
uint32_t flag = recvFlag(i);
uint32_t data1, flag1, data2, flag2;
int spins = 0;
do {
asm volatile("ld.volatile.global.v4.u32 {%0,%1,%2,%3}, [%4];" : "=r"(data1), "=r"(flag1), "=r"(data2), "=r"(flag2) : "l"(&src->i4) : "memory");
if (checkAbort(abort, 1, spins)) break;
} while ((flag1 != flag) || (flag2 != flag));
uint64_t val64 = data1 + (((uint64_t)data2) << 32);
return val64;
}readLL就是获取recvPeeri发送过来的line,第i个recv peer的fifo为recvBuffi,对应的step为recvStepi,因此通过recvPtr(i)获取到了recv peeri的fifo中当前step的slot,然后加上offset得到这次处理line的位置。
cpp
inline __device__ int recvOffset(int i) { return (recvStep[i]%NCCL_STEPS)*stepLines; }
inline __device__ union ncclLLFifoLine* recvPtr(int i) { return recvBuff[i]+recvOffset(i); }然后通过ld.v4.u32 load这个line,轮询line中的flag,直到等于expect flag后返回line中的data,expect flag其实就是通过step得到的,只不过由于是4B,需要执行溢出的操作。readLLBeginAll和readLLFinish有点像拆分readLL,readLLBeginAll会从BeginIx开始的recv peer开始执行一次flag的load,readLLFinish是判断readLLBeginAll中flag是否为expect flag,如果不等于则while轮询,最后返回load到的data。这里拆分为两个步骤也是为了load延迟的隐藏。
cpp
void LLGenericOp(...) {
while (nelem > 0) {
...
if (RECV) {
data = !SRC ? peerData : applyReduce(redOp, peerData, data);
for (int i=1; i < MaxRecv && i < fan.nrecv(); i++) {
peerData = readLLFinish(offset, line, i);
data = applyReduce(redOp, peerData, data);
}
}
if (postOp) data = applyPostOp(redOp, data);
if (SEND) {
for (int i=1; i < MaxSend && i < fan.nsend(); i++)
storeLL(sendPtr(i)+offset, data, sendFlag(i));
storeLL(sendPtr(0)+offset, data, sendFlag(0));
}
if (DST) {
storeData(dstElts, data, eltInLine);
dstElts += eltPerTrip;
}
nelem -= eltPerTrip;
offset += nthreads;
}
if (RECV) {
for (int i=0; i < MaxRecv; i++) incRecv(i);
postRecv();
}
if (SEND) {
for (int i=1; i < MaxSend && i < fan.nsend(); i++)
incSend(i, offset);
incSend(0, offset);
}
}然后将所有收到的数据以及srcElts执行reduce,然后通过storeLL将data和flag编码到一起写入sendPtri以及dstElts。
cpp
__device__ void storeLL(union ncclLLFifoLine* dst, uint64_t val, uint32_t flag) {
asm volatile("st.volatile.global.v4.u32 [%0], {%1,%2,%3,%4};" :: "l"(&dst->i4), "r"((uint32_t)val), "r"(flag), "r"((uint32_t)(val >> 32)), "r"(flag) : "memory");
}在完成nlem的发送之后执行postRecv通知recv peer,当前rank已经完成了一个slot的处理,并通过incSend增加send step。
多机LL
现有LL的实现中,为了降低延迟,同样没有使用fence,而是和单机类似,通过使用host轮询flag的方式判断数据是否ready,因为发送端host轮询,因此选择将fifo放在host,对于recv端,fifo还是在gpu上。
cpp
static ncclResult_t sendProxyConnect() {
...
for (int p=0; p<NCCL_NUM_PROTOCOLS; p++) {
NCCL_NET_MAP_ADD_POINTER(map, 0, p!= NCCL_PROTO_LL && resources->useGdr ? 1 : 0, proxyState->buffSizes[p], buffs[p]);
resources->buffSizes[p] = proxyState->buffSizes[p];
}
...
}NCCL_NET_MAP_ADD_POINTER的第三个参数为是否为device,当协议为NCCL_PROTO_LL,会设置为放在host。但是recv端还是放在gpu。
cpp
static ncclResult_t sendProxyProgress() {
...
if (connFifo[buffSlot].size != -1 && (*recvTail > tail || p == NCCL_PROTO_LL)) {
int ready = 1;
else if (p == NCCL_PROTO_LL) {
uint32_t flag = NCCL_LL_FLAG(sub->base+sub->transmitted+1);
int nFifoLines = DIVUP(size, sizeof(union ncclLLFifoLine));
union ncclLLFifoLine* lines = (union ncclLLFifoLine*)buff;
for (int i=0; i<nFifoLines; i++) {
volatile uint32_t *f1 = &lines[i].flag1;
volatile uint32_t *f2 = &lines[i].flag2;
if (f1[0] != flag || f2[0] != flag) { ready = 0; break; }
}
}
}
}发送的时候对于LL协议,不再通过tail指针判断是否有新数据,而是每次轮询fifo中的slot,直到slot的所有slot的flag都为expect flag。
单机LL128
cpp
#define NCCL_LL128_LINESIZE 128
#define NCCL_LL128_LINEELEMS (NCCL_LL128_LINESIZE/sizeof(uint64_t))
#define NCCL_LL128_DATAELEMS (NCCL_LL128_LINEELEMS-1)LL128协议中是120B的data + 8B的flag,NCCL_LL128_LINESIZE表示一个line的大小,为128B。NCCL_LL128_LINEELEMS表示一个line中可以放多少个uint64。NCCL_LL128_DATAELEMS表示一个line中有多少个uint64可以用来存储data,因为有8B的flag,因此减掉1就好。
LL128使用了16B的读写,因此一个line对应了8个线程,一个warp中按照8线程分组,每个分组的最后一个线程为flag thread,用于处理line中的flag。
cpp
flagThread((tid%8)==7);
cpp
#define NCCL_LL128_SHMEM_ELEMS_PER_THREAD 8
static constexpr int WireWordPerSlice = WARP_SIZE*NCCL_LL128_SHMEM_ELEMS_PER_THREAD;
static constexpr int DataEltPerSlice = (WireWordPerSlice - WireWordPerSlice/NCCL_LL128_LINEELEMS)*(sizeof(uint64_t)/sizeof(T));LL128中按照warp粒度进行数据发送,一个warp一次发送称为一个slice,一个slice中一个thread一次负责8个uint64(包含flag),WireWordPerSlice表示一个slice中一共发送了多少个uint64,DataEltPerSlice表示一个slice中出去flag后有几个elem。WireWordPerSlice/NCCL_LL128_LINEELEMS表示一个slice中有几个line,一个line对应一个uint64的flag,所以需要减去。
cpp
template <int RECV, int SEND, int SrcBuf, int DstBuf>
__device__ __forceinline__ void GenericOp(intptr_t srcIx, intptr_t dstIx, int nelem, bool postOp) {
constexpr int SRC = SrcBuf != -1 ? 1 : 0;
constexpr int DST = DstBuf != -1 ? 1 : 0;
T const *srcPtr = SrcBuf == -1 ? nullptr : userBufs[SrcBuf] + srcIx;
T *dstPtr = DstBuf == -1 ? nullptr : userBufs[DstBuf] + dstIx;
int wireOffset = WireWordPerSlice*warp + 2*wid;
const int nwarps = nthreads/WARP_SIZE;
nelem = nelem < 0 ? 0 : nelem;
if (SEND) waitSend(divUp(nelem, DataEltPerSlice)*WireWordPerSlice*sizeof(uint64_t));
barrier();
nelem -= DataEltPerSlice*warp;
srcPtr += DataEltPerSlice*warp;
dstPtr += DataEltPerSlice*warp;
...
}然后看下GenericOp,warp表示当前线程所在warp的idx,wireOffset表示fifo的slot中,当前tid对应的偏移,单位为uint64,一个warp一次发送WireWordPerSlice个uint64,因此WireWordPerSlicewarp定位到warp的偏移,因为用了16B的读写,因此一个线程一次处理两个uint64,所以通过2wid定位到线程对应的偏移。然后通过waitSend等待send peer有空闲slot。
cpp
template <int RECV, int SEND, int SrcBuf, int DstBuf>
__device__ __forceinline__ void GenericOp(intptr_t srcIx, intptr_t dstIx, int nelem, bool postOp) {
...
while (nelem > 0) {
const int eltInSlice = min(nelem, DataEltPerSlice);
uint64_t regs[NCCL_LL128_SHMEM_ELEMS_PER_THREAD];
if (SRC) loadRegsBegin(regs, srcPtr, eltInSlice);
recvReduceSendCopy<NCCL_LL128_SHMEM_ELEMS_PER_THREAD, RECV, SEND, SrcBuf, DstBuf>(regs, wireOffset, postOp);
if (DST) storeRegs(dstPtr, regs, eltInSlice);
wireOffset += WireWordPerSlice*nwarps;
srcPtr += DataEltPerSlice*nwarps;
dstPtr += DataEltPerSlice*nwarps;
nelem -= DataEltPerSlice*nwarps;
}
barrier();
if (SEND) for (int i=0; i < MaxSend; i++) sendStep[i] += 1;
if (SEND) postSend();
if (RECV) for (int i=0; i < MaxRecv; i++) recvStep[i] += 1;
if (RECV) postRecv();
}首先看下如何从srcPtr中load数据。
cpp
template<int WordPerThread>
__device__ __forceinline__ void loadRegsBegin(uint64_t(®s)[WordPerThread], T const *src, int eltN) {
constexpr int EltPer16B = 16/sizeof(T);
if(reinterpret_cast<uintptr_t>(src)%16 == 0) {
for(int g=0; g < WordPerThread/2; g++) {
int ix = g*WARP_SIZE - 4*(g/2) + wid - (g%2)*(wid/8);
if(!flagThread || g%2==0) {
if(ix*EltPer16B < eltN)
load128((uint64_t*)(src + ix*EltPer16B), regs[2*g+0], regs[2*g+1]);
}
}
}WordPerThread就是NCCL_LL128_SHMEM_ELEMS_PER_THREAD,即为8。由于LL128使用了16B的读写,因此需要对16B对齐,我们先看16B对齐的场景,由于用户的输入为紧密输入的data,而loadRegsBegin的输出regs后续会转为line格式,即120B data + 8B flag,因此这里需要一个转换,如图2所示,只展示了warp中一个分组(8个线程)的三轮load行为,srcPtr为源数据,一个方块为一个uint64,srcPtr中的标号是每一轮内部的相对偏移,regs中t0r0表示线程0的第0号register。
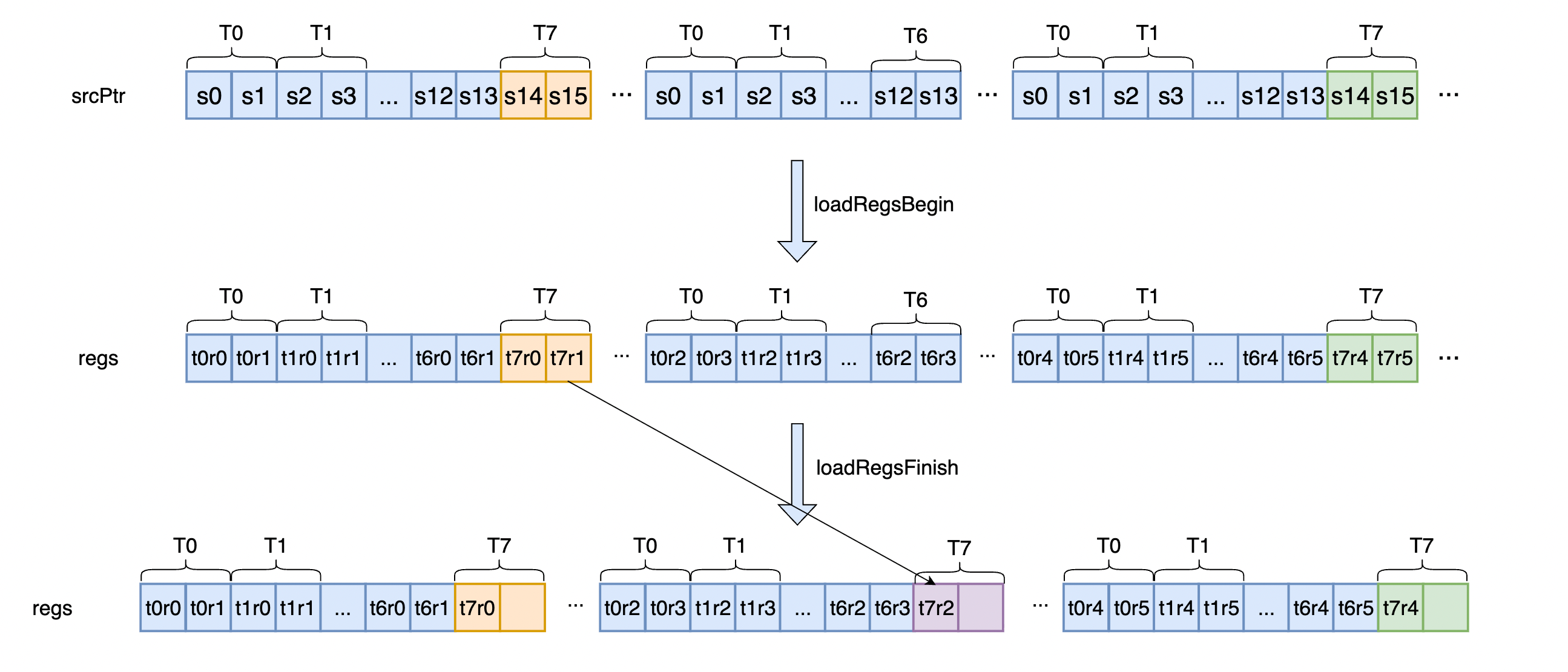
图 2
一个slice中一个thread一共需要load 8个uint64,一次load 2个uint64,因此一共需要4轮,即WordPerThread / 2,然后开始算每一轮的ix,即在src中的偏移,偏移的单位为16B,nccl现有的实现为偶数轮次,每个线程都load 16B,奇数轮次flag线程不执行load,其他线程仍然load 16B。一个warp一轮可以load 32个16B,因此g*WARP_SIZE就是当前轮次的起始位置,+ wid定位到当前tid对应的偏移。但是还要回退一些位置,回退来源有两个,一个是之前轮次中flag线程对应少load的空间,一个warp有4个flag线程,一个flag线程每两轮少load一个16B,因此需要- 4*(g/2),另一个来源是当前轮次内,当前tid之前的flag线程少load的空间,只有奇数轮次才会少load,一个flag线程在奇数轮次会少load一个16B,因此- (g%2)*(wid/8)。然后对于得到的ix,通过load128完成数据的load。最后通过loadRegsFinish将类似t7r1的位置赋值给t7r2,这样就得到了line的格式,t7的空闲slot会用来存flag。
cpp
template<int WordPerThread>
__device__ __forceinline__ void loadRegsBegin(uint64_t(®s)[WordPerThread], T const *src, int eltN) {
constexpr int EltPer16B = 16/sizeof(T);
...
else {
int misalignment = reinterpret_cast<uintptr_t>(src) % 16;
uint64_t *src8 = reinterpret_cast<uint64_t*>(reinterpret_cast<uintptr_t>(src) & -uintptr_t(16));
uint64_t *shm8 = shmemCvtPtr((uint64_t*)ncclScratchForWarp(warpInBlock));
for(int g=0; g < WordPerThread/2; g++)
if((g*WARP_SIZE + wid)*16 < misalignment + eltN*sizeof(T))
load128(src8 + 2*(g*WARP_SIZE + wid), regs[2*g+0], regs[2*g+1]);
for(int g=0; g < WordPerThread/2; g++)
storeShmem128(shm8 + 2*(g*WARP_SIZE + wid), regs[2*g+0], regs[2*g+1]);
__syncwarp();
T *shm = (T*)shm8 + misalignment/sizeof(T);
for(int g=0; g < WordPerThread/2; g++) {
int ix = g*WARP_SIZE - 4*(g/2) + wid - (g%2)*(wid/8);
if(!flagThread || g%2==0) {
if(ix*EltPer16B < eltN)
loadShmemMisaligned128(shm + ix*EltPer16B, regs[2*g+0], regs[2*g+1]);
}
}
}
}因为一个线程处理16B的数据,非对齐无法使用16B load指令,这样每个线程每次执行小于16B load的时候会产生无法coalesced的访问,因此nccl选择通过smem中转的方式,这样在gmem这层产生的还是coalesced的访存。
首先将src向下取整到16B对齐的位置,然后通过16B load到regs,再通过16B store到shm8。然后开始从shmem中load数据,ix的计算方式和上述一致,对于给定的ix,通过loadShmemMisaligned128来load。
cpp
template<typename T>
inline __device__ void loadShmemMisaligned128(T *ptr, uint64_t &v0, uint64_t &v1) {
union {
uint32_t tmp4[4];
uint64_t tmp8[2];
};
if(sizeof(T) < 4) {
uint32_t *ptr4 = reinterpret_cast<uint32_t*>(reinterpret_cast<uintptr_t>(ptr) & -uintptr_t(4));
#pragma unroll
for(int e=0; e < 4; e++) {
// Produce 4 bytes of sub-register type by reading 2 4-byte
// aligned values and shifting.
uint32_t lo, hi;
asm volatile("ld.shared.b32 %0,[%1];" : "=r"(lo) : "l"(ptr4+e+0) : "memory");
asm volatile("ld.shared.b32 %0,[%1];" : "=r"(hi) : "l"(ptr4+e+1) : "memory");
tmp4[e] = __funnelshift_r(lo, hi, 8*(int(reinterpret_cast<uintptr_t>(ptr))%4));
}
}
else if(sizeof(T) == 4) {
#pragma unroll
for(int e=0; e < 4; e++)
asm volatile("ld.shared.b32 %0,[%1];" : "=r"(tmp4[e]) : "l"(ptr+e) : "memory");
}
else /*sizeof(T)==8*/ {
#pragma unroll
for(int e=0; e < 2; e++)
asm volatile("ld.shared.b64 %0,[%1];" : "=l"(tmp8[e]) : "l"(ptr+e) : "memory");
}
v0 = tmp8[0];
v1 = tmp8[1];
}loadShmemMisaligned128对16B load的过程和LL的逻辑有些像,尽量使用大块的load,对于小于4字节的会通过4字节对齐的load+__funnelshift_r的方式进行load。
回到GenericOp中,继续看recvReduceSendCopy的过程。
cpp
__device__ __forceinline__ void recvReduceSendCopy(uint64_t(&v)[ELEMS_PER_THREAD], int ll128Offset, bool postOp) {
constexpr int SRC = SrcBuf != -1 ? 1 : 0;
uint64_t vr[ELEMS_PER_THREAD];
__syncwarp();
if (RECV) {
uint64_t* ptr = recvPtr(0)+ll128Offset;
uint64_t flag = recvFlag(0);
bool needReload;
int spins = 0;
do {
needReload = false;
for (int u=0; u<ELEMS_PER_THREAD; u+=2) {
load128(ptr+u*WARP_SIZE, vr[u], vr[u+1]);
needReload |= flagThread && (vr[u+1] != flag);
}
needReload &= (0 == checkAbort(abort, 1, spins));
} while (__any_sync(WARP_MASK, needReload));
for (int u=0; u<ELEMS_PER_THREAD; u+=2)
load128(ptr+u*WARP_SIZE, vr[u], vr[u+1]);
}
if (SRC) {
loadRegsFinish(v);
if (SrcBuf == Input) {
for (int u=0; u<ELEMS_PER_THREAD; u+=2) {
v[u] = applyPreOp(redOp, v[u]);
if (!flagThread)
v[u+1] = applyPreOp(redOp, v[u+1]);
}
}
}
...
}v\[\]就是loadRegsBegin得到的regs数组,然后开始wait recv_peer0的数据,while循环中每一个线程load 16B,然后flag线程检查自己load到的flag,如果等于expect flag,那么说明数据已经可见了,然后所有线程执行一遍load拿到数据,这里比较奇怪的是while循环check flag的时候为什么不只用flag线程去check,猜测有可能是一个8线程的组对应了128B,对应cacheline的大小,所以data线程执行或者不执行load对性能的影响不大。
cpp
void recvReduceSendCopy() {
if (SRC) {
loadRegsFinish(v);
if (SrcBuf == Input) {
for (int u=0; u<ELEMS_PER_THREAD; u+=2) {
v[u] = applyPreOp(redOp, v[u]);
if (!flagThread)
v[u+1] = applyPreOp(redOp, v[u+1]);
}
}
}
if (RECV) {
{
for (int u=0; u<ELEMS_PER_THREAD; u+=2) {
v[u] = SRC ? applyReduce(redOp, vr[u], v[u]) : vr[u];
v[u+1] = SRC ? applyReduce(redOp, vr[u+1], v[u+1]) : vr[u+1];
}
}
...
}如图2所示,通过loadRegsFinish将flag线程load的数据进行转换,接着将src中的数据v\[\]和recv_peer0的数据vr\[\]进行reduce,然后对其他所有recv_peer重复执行load和reduce的过程,这里不再赘述。
cpp
void recvReduceSendCopy() {
...
if (SEND) {
for (int i=1; i<MaxSend && i<fan.nsend(); i++) {
uint64_t flag = sendFlag(i);
uint64_t* ptr = sendPtr(i)+ll128Offset;
for (int u=0; u<ELEMS_PER_THREAD; u+=2) {
store128(ptr+u*WARP_SIZE, v[u], flagThread ? flag : v[u+1]);
}
}
uint64_t flag = sendFlag(0);
uint64_t* ptr = sendPtr(0)+ll128Offset;
for (int u=0; u<ELEMS_PER_THREAD; u+=2) {
store128(ptr+u*WARP_SIZE, v[u], flagThread ? flag : v[u+1]);
}
}
}然后将数据和flag一同写给send peer。
cpp
template<int WordPerThread>
__device__ __forceinline__ void storeRegs(T *dst, uint64_t(®s)[WordPerThread], int eltN) {
constexpr int EltPer16B = 16/sizeof(T);
for (int g=1; g < WordPerThread/2; g+=2) {
if (flagThread) regs[2*g-1] = regs[2*g];
}
int misalignment = reinterpret_cast<uintptr_t>(dst)%16;
uint64_t *shm8 = shmemCvtPtr((uint64_t*)ncclScratchForWarp(warpInBlock));
#pragma unroll
for(int g=0; g < WordPerThread/2; g++) {
int ix = g*WARP_SIZE - 4*(g/2) + wid - (g%2)*(wid/8);
if (!flagThread || g%2==0) {
if(misalignment == 0 && (ix+1)*EltPer16B <= eltN)
store128((uint64_t*)(dst + ix*EltPer16B), regs[2*g+0], regs[2*g+1]);
else
storeShmem128(shm8+2*ix, regs[2*g+0], regs[2*g+1]);
}
}
__syncwarp();
T *shm = (T*)ncclScratchForWarp(warpInBlock);
int skip = misalignment == 0 ? eltN & -EltPer16B : 0;
for(int i=skip+wid; i < eltN; i += WARP_SIZE)
dst[i] = shm[i];
}如果DST为1,那么通过storeRegs写入到dstPtr,由于在finish的过程中对flag线程对应的数据做了转换,这里需要转换回去。如果dstPtr为16B对齐的,直接写gmem,否则还是通过smem中转。
多机LL128
LL128在多机的send端将fifo放在gpu上,因此需要执行fence,sendConnTailPtr为多机场景用于和proxy交互的tail指针,hopper之后用了__threadfence_system,hopper之前用的是__threadfence。
cpp
inline __device__ void postSend() {
if (sendConnTailPtr) {
#if __CUDA_ARCH__ >= 900
__threadfence_system();
#else
__threadfence();
#endif
*sendConnTailPtr = sendConnTail += 1;
}
}其他流程和simple一样,不再赘述。
最后看下fence一个有趣的地方。
cpp
static ncclResult_t sendProxyProgress() {
if (p == NCCL_PROTO_LL128) {
ready = resources->useGdr;
if (!ready) {
// When data is in sysmem, we need to wait until all flags are correct since the GPU only
// called threadfence()
uint64_t flag = sub->base+sub->transmitted+1;
int nFifoLines = DIVUP(connFifo[buffSlot].size, sizeof(uint64_t)*NCCL_LL128_LINEELEMS);
volatile uint64_t* lines = (volatile uint64_t*)buff;
ready = 1;
for (int i=0; i<nFifoLines; i++) {
if (lines[i*NCCL_LL128_LINEELEMS+NCCL_LL128_DATAELEMS] != flag) { ready = 0; break; }
}
}
}
}网络发送逻辑的这个注释很奇怪,是说如果kernel在只执行threadfence的情况下,如果是gdr,即fifo位于gpu,那么threadfence就可以保证data和flag不乱序。但是如果非gdr,即fifo位于cpu,那么是乱序的。
从PTX规范角度来讲,生产者是gpu thread,消费者是cpu,无论fifo位于gpu还是cpu,他们都需要fence_sys才能保证不乱序。但是nccl对于hopper之前的架构的实现中,如果fifo位于gpu则只使用threadfence就可以保证可见性,这一点在看nvshmem代码的时候也有相同的逻辑,之前在这个issue中和deepseek的大佬有过咨询。
整理这些现象猜测可能是这样,当fifo在gpu的时候,执行threadfence后可以保证data落盘L2后才写flag,因此cpu看到flag并通知网卡的时候,data已经落盘到L2了,网卡也是从L2读data,所以此时可以保证顺序,但是如果fifo位于cpu,threadfence无法保证data和flag通过PCIe到cpu的相对顺序。因此这一实现并不符合PTX中的规范,但是是基于特定硬件场景上是正确的,还获得更好的性能。