引言
近两年记忆一词在 Agent 生态里被用得很泛------向量库 + top-K 叫记忆、RAG 叫记忆、滚动摘要也叫记忆------概念之间缺乏边界,技术选型时很难判断某个新出现的系统到底解决了什么问题。本文按"定义 / 形态 / 功能 / 动态 / 前沿"五块组织,每一节尝试回答三个问题:它解决了什么问题?难点在哪里?它在整张 Agent Memory 图谱中处于什么位置?
过去两年,LLM 生态的重心已经从"怎么把一次推理做好"迁移到"怎么让一个 Agent 在几十轮、跨任务、跨会话中持续工作"。真正把语言模型撑成智能体的,从来不是参数量,而是它能否记住发生过什么、能否把经验转化为能力、能否在下一次相似情境中主动调用过往。这正是 Agent Memory 这一话题越来越热的根本原因。
但也正因为它处在多个方向的交叉口------长上下文架构、RAG、Context Engineering、持续学习------术语迅速膨胀,很多所谓的"Memory 框架"其实只是换了个皮的向量检索。本文会按"Preliminaries / Form / Functions / Dynamics / Positions and Frontiers"五块,把这条脉络说清楚。
一、Preliminaries:先把"Agent 的记忆"定义清楚
1.1 Agent 与记忆系统的形式化
这一节解决的问题:在讨论任何具体技术之前,先给"Agent 的记忆系统"一个可讨论的统一抽象,避免后面的工作因为定义口径不一而无法互相比较。
难点:Agent 的动作空间本身就是异质的------有自然语言回复、有工具调用、有规划指令、有环境控制,不同任务对记忆的使用模式完全不同;同时"记忆"既要覆盖一次任务内的临时上下文,也要覆盖跨任务、跨会话的长期知识,很难用一个简单的模型框起来。
一个比较干净的形式化写法是¹:每个 Agent iii 在时刻 ttt 的动作可以写成
at=πi(oti, mti, Q),a_t = \pi_i(o_t^i,\ m_t^i,\ \mathcal{Q}),at=πi(oti, mti, Q),
其中各符号的含义是:
| 符号 | 含义 |
|---|---|
| πi\pi_iπi | 第 iii 个 Agent 的决策策略(policy),以当前观测、记忆信号、任务描述为输入,输出动作;在 LLM-based Agent 里通常就是"LLM + Prompt 模板 + 工具调用逻辑"整体,在 RL 场景下则是一个可训练的参数化策略 |
| ata_tat | 策略在时刻 ttt 输出的动作,可能是自然语言回复、工具调用、规划指令、环境控制等,是一个异质的动作空间 |
| otio_t^ioti | Agent iii 在时刻 ttt 从环境获取的观测 |
| mtim_t^imti | 从记忆系统取出并送给策略的记忆信号 (可能是若干文本片段、结构化摘要,或是一个特殊的"空值" ⊥\bot⊥ 表示这一步不检索) |
| Q\mathcal{Q}Q | 任务描述(用户指令、目标说明、外部约束),在一次任务内通常固定 |
| Mt∈M\mathcal{M}_t \in \mathbb{M}Mt∈M | 时刻 ttt 的记忆系统状态------所有"已被记住的内容"的集合;M\mathbb{M}M 表示所有可能记忆状态构成的空间 |
| ϕt\phi_tϕt | 时刻 ttt 产生的交互产物(本轮对话、工具调用结果、反思文本等可能进入记忆的素材) |
| ⊥\bot⊥ | 空值/空操作标记,用于表示"这一步不检索"或"这一步不写入" |
在此基础上,记忆系统本身是一个持续演化的状态 Mt\mathcal{M}_tMt,由三个算子驱动:
- Formation :Mt+1form=F(Mt, ϕt)\mathcal{M}_{t+1}^{\text{form}} = F(\mathcal{M}_t,\ \phi_t)Mt+1form=F(Mt, ϕt),把交互产物 ϕt\phi_tϕt 转成记忆候选;
- Evolution :Mt+1=E(Mt+1form)\mathcal{M}{t+1} = E(\mathcal{M}{t+1}^{\text{form}})Mt+1=E(Mt+1form),把新记忆整合进已有知识库;
- Retrieval :mti=R(Mt, oti, Q)m_t^i = R(\mathcal{M}_t,\ o_t^i,\ \mathcal{Q})mti=R(Mt, oti, Q),按需取出相关记忆送入推理。
"形成---演化---检索"这个三元闭环,是后面所有具体技术都会回到的母结构。一个实用的判据是:只要一个系统里这三个算子中有一个是缺席或静态的,那它大概率还不是 Agent Memory,而是在偏 RAG 或 Context Engineering 那一侧。
1.1.1 Temporal Roles:短期/长期其实是"调用频率"的副产物
这里有一个容易被忽略的事实:记忆是统一的 Mt\mathcal{M}_tMt,但三个算子 F,E,RF, E, RF,E,R 并不必须在每一步都被调用 ¹。不同系统的"记忆观感"差异,其实来自它们以不同频率和条件激活这三个算子。举两个极端:
有的系统只在任务初始化时做一次检索、之后全程不再查:
mti={R(M0, o0i, Q),t=0,⊥,t>0,m_t^i = \begin{cases} R(\mathcal{M}_0,\ o_0^i,\ \mathcal{Q}), & t = 0, \\ \bot, & t > 0, \end{cases}mti={R(M0, o0i, Q),⊥,t=0,t>0,
这里 ⊥\bot⊥ 表示"空检索"(null retrieval)。另一些系统则根据上下文触发器间断或持续地检索。Formation 也同样是一个谱系------最轻量的实现只是把观测直接堆进库里:
Mt+1form=Mt∪{oti},\mathcal{M}_{t+1}^{\text{form}} = \mathcal{M}_t \cup \{o_t^i\},Mt+1form=Mt∪{oti},
而更复杂的做法则会做抽取、抽象、模式提炼(可重复使用的 pattern)。
这就解释了一个看上去很困惑的事实:所谓"短期记忆"和"长期记忆"并不是两个架构模块,而是同一套 F/E/RF/E/RF/E/R 在不同时间粒度上被调用的结果 ¹。单任务内、以轻量 logging 形式不断积累的就是短期记忆;在任务边界 episodic 更新、或者持续在后台提炼的就是长期记忆。换句话说,短/长期是时间模式 ,不是结构划分。这也是为什么传统的 long/short-term 二分法不适合用来描述 Agent Memory------它太粗糙,容易把结构和调度混为一谈。
1.1.2 Memory--Agent Coupling:记忆信号在策略里是可有可无的输入
继续把 at=πi(oti,mti,Q)a_t = \pi_i(o_t^i, m_t^i, \mathcal{Q})at=πi(oti,mti,Q) 这个式子拎出来看,它还有一个容易被忽略的细节:当检索在当前步被关闭时,mtim_t^imti 可以被当成一个"显式的空输入"(distinguished null input) ¹。也就是说,"不查"本身也是策略的一种合法输出------这一点对后面讨论"检索时机与意图"至关重要:它意味着"要不要查"可以被完全内化为策略 πi\pi_iπi 的决策,而不是一个硬编码的外部触发器。
把这些组合起来,整个 Agent 的主循环其实可以写成这样的松耦合流水线:
observe→(optional) retrieve⏟R→act→receive feedback→(optional) update⏟F, E\text{observe} \to \underbrace{\text{(optional) retrieve}}{R} \to \text{act} \to \text{receive feedback} \to \underbrace{\text{(optional) update}}{F,\ E}observe→R (optional) retrieve→act→receive feedback→F, E (optional) update
不同系统的差别就在于:这五步里哪几步被实现,以什么频率、在哪些条件下被触发 。从这个视角看,从最 passive 的 buffer(只有 observe + act)到最 active 的 self-evolving knowledge base(五步全齐、且高频交替)之间是一条连续谱。Agent Memory 本质上是一个动态系统而非一个静态模块------你可以按这套公式给任意一个所谓的"Memory 框架"做还原分析,立刻看清它离真正的 Agent Memory 差在哪个算子上。
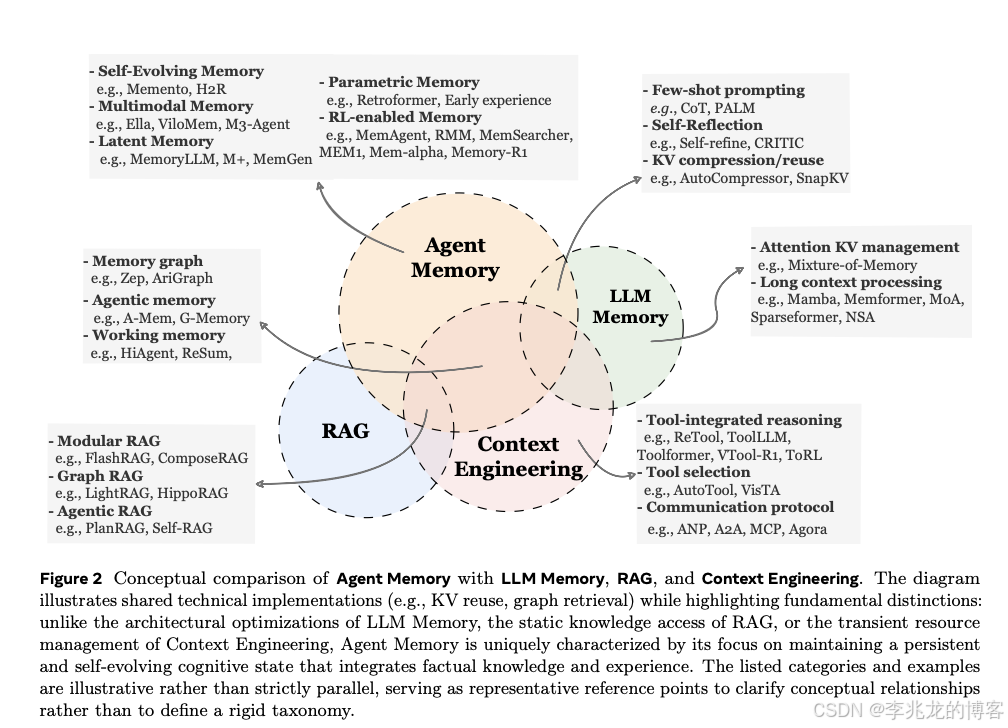
1.2 Agent Memory vs. LLM Memory / RAG / Context Engineering
这一节解决的问题:厘清 Agent Memory 与三个看起来很像、实际上关注层次不同的概念的边界。
难点:底层工程栈高度重叠------KV 压缩、向量索引、图结构这些东西在四个方向都会出现,所以没法从"用了什么技术"来划线,必须回到"它为谁服务"。常用的三条判据是¹:
- vs. LLM Memory :LLM Memory 关心的是模型自身的表示容量(Mamba 这类 SSM、滑动窗口注意力、KV Cache 压缩等²³),没有跨任务的持久化概念;Agent Memory 则是跨任务维护的认知状态,与底层模型架构解耦。两者有工程上的交叉(比如 KV 压缩既可以服务长上下文也可以做潜在记忆的存储介质),但目的不同。
- vs. RAG :判别标准只有一条------这个知识库会不会因为 Agent 自己的行动和反馈发生变化。如果答案是会,它就是 Agent Memory;如果只是访问一份固定文档库做单次增强,它就是 RAG。即使是 Agentic RAG(Self-RAG 这类⁴)引入了迭代检索和自主触发,只要它读的是一份外部静态资料,就仍然不构成真正的记忆。
- vs. Context Engineering :Context Engineering 是资源管理范式 ,目标是在有限的上下文窗口里最大化推理效率,关注的是"当前这一步怎么把 Prompt 拼好";Agent Memory 是认知建模范式,关注的是跨越任何单一上下文窗口的长期认知状态。前者是后者的一种实现手段,两者不是一个层次。
这一章是后面所有讨论的锚点。一旦记住"形成/演化/检索都要有、并且知识库随 Agent 自身行为改变"这两个标准,很多看似复杂的新工作立刻就能归位。
二、Form:记忆存放在哪里?
这一章解决的问题:选择一种物理介质和组织结构来承载记忆。它是后续所有 Formation / Retrieval / Evolution 操作可行性的前提。
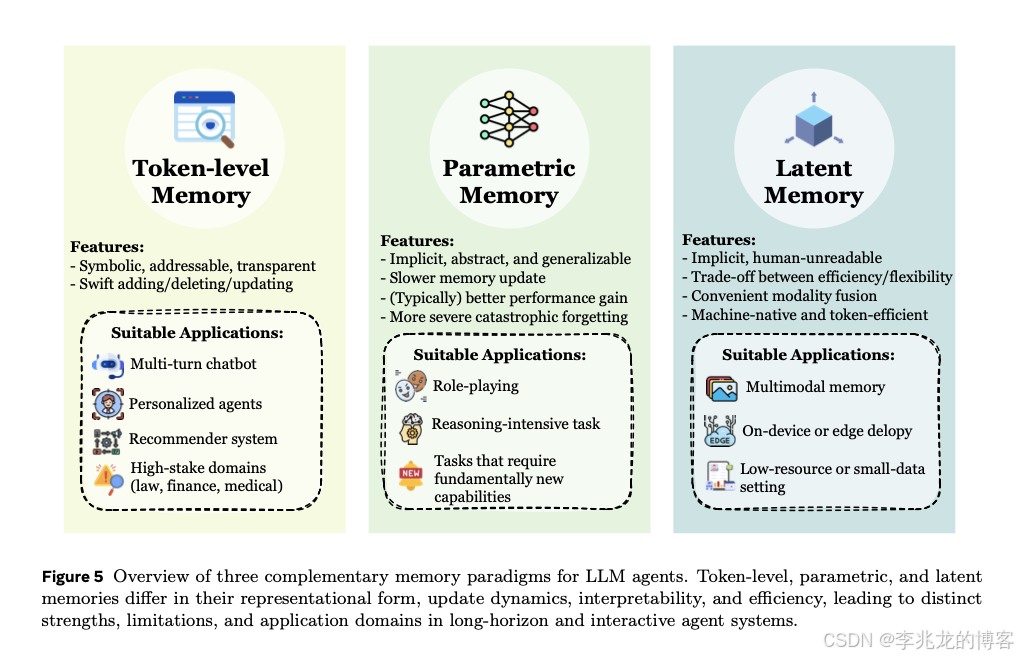
核心难点 :需要在可解释性 、检索效率 、存储成本 、更新成本 、多模态亲和性之间做综合权衡,而且没有任何一种形式在所有任务上普遍占优。现有实现基本上可以归纳为三大类------Token-level、Parametric、Latent¹,它们对应的是完全不同的取舍方式。
2.1 Token-level Memory:以离散文本为载体
Token 级记忆把信息存成可外部访问、可独立编辑的文本片段------原始对话、轨迹、chunk、工具日志都可以直接入库。它是目前研究最多、工程上最常见的形态,核心价值在于透明、可审计、可跨模型迁移(换个基座模型,记忆库不用重建)。
Token-level Memory 的真正差异不在"存什么",而在"记忆单元之间有没有拓扑、以及拓扑有几层" ¹。按这个视角,它可以被划成三个维度------Flat(1D)/ Planar(2D)/ Hierarchical(3D)。这里的 1D/2D/3D 不是空间维度,而是拓扑复杂度:从"无关系"到"同层有关系"再到"跨层有关系"的一条升级谱。
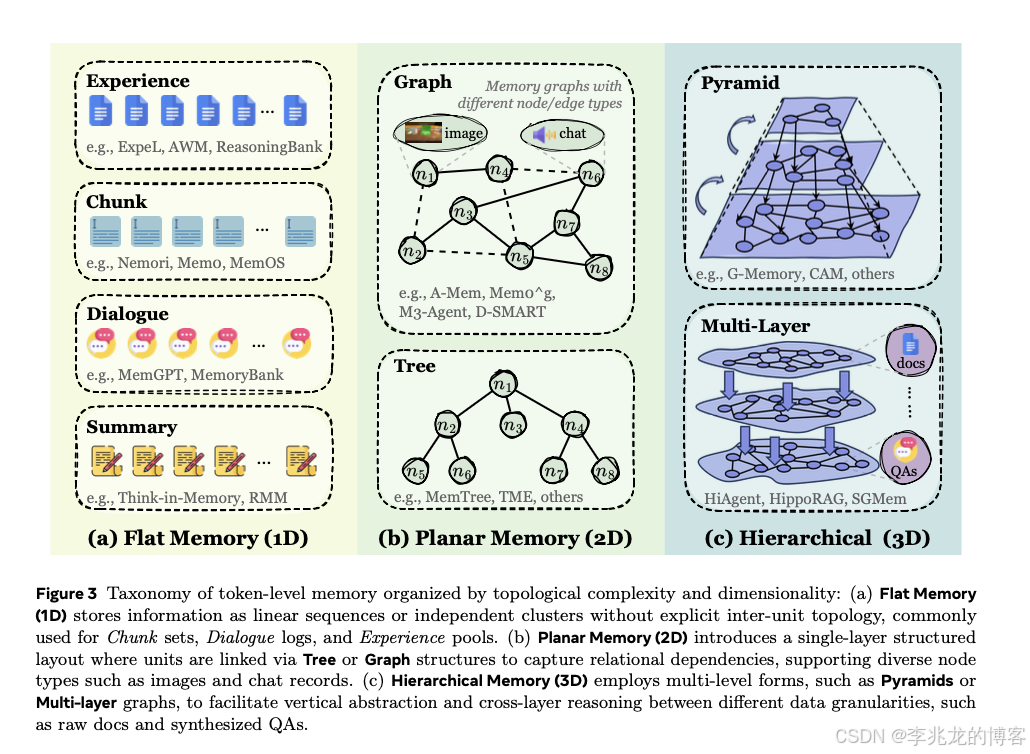
2.1.1 Flat Memory (1D):没有拓扑的堆积
定义 :把记忆作为离散单元的累积------文本片段、对话轮、用户画像、轨迹片段、向量等等,单元之间不显式建立任何语义或关系依赖¹。你可以把它想象成一个"带检索的 append-only 列表",单元之间唯一的隐式关联就是时间戳。
典型组织形式:
- Dialogue log(对话日志):按轮次追加完整对话,代表是 MemGPT⁶,用 OS 式的主存/磁盘抽象管理"活跃窗口 vs. 外部长期存储"之间的 page in/out;
- Experience pool(经验池):按任务追加反思/轨迹,代表是 Reflexion⁵,把自我反思的文本写入扁平池,后续任务取出作为 few-shot;
- Chunk set(分块池):把长文档切成 chunk 独立编码入库,这是绝大多数"向量库式"RAG 的默认形态。
它解决的问题:在最低的工程成本下快速支持"写-读-淘汰"三件事,支持高频追加------对话类、日志类、反思类场景几乎天然契合。
为什么会不够用 :单元之间没有任何显式关联,所有"关联推理"都被推给检索阶段靠相似度近似解决。这导致两个典型失效:(i) 多跳推理断链 ------两条本应被共同召回的记忆恰好语义相似度都不够高,就会被遗漏;(ii) 冗余累积------同一事实被反复追加多次,没有合并机制,越存越脏。所以 Flat Memory 通常必须配合 Formation 阶段的摘要/去重(见 4.1 节)才能长期工作。
定位:Token-level 的入门形态,适合对话、轻量经验积累、chunk-based RAG 等场景。
2.1.2 Planar Memory (2D):在"同一层"内显式连边
定义 :引入单层结构化拓扑 ------图、树、表、关系结构都算------在这一层内显式建模邻接、父子、语义聚类等关系,但不引入跨层抽象¹。从 Flat 到 Planar 的关键跨越可以用一句话来概括:从"存储(storage)"跃迁到"组织(organization)"¹。也就是说,Planar 开始主动告诉系统"哪些记忆彼此相关",而不是让检索时重新靠相似度去猜。
两种主流组织形式:
-
Tree(树结构):适合层级化的概念归类与由粗到细的检索。代表是 MemTree⁶⁵(从孤立的对话日志里动态推断层级 schema,把具体事件逐步归纳为高层概念,从而让 Agent 同时使用细粒度记忆和抽象知识)和 HAT⁶⁶(把长交互分段后逐层聚合,支持 coarse-to-fine 检索,在长上下文 QA 上优于纯向量索引)。注意:树本身只有一层"结构"(父子边),仍然是 Planar 而不是 Hierarchical------Hierarchical 的关键是跨层之间还要有跨层语义关系,不只是父子归属。
-
Graph(图结构):Planar 里最主流的形态,因为图天然能捕捉关联、因果和时间动态。代表是 HippoRAG⁷(类海马体的"知识图谱 + 段落存储",检索时以命中的种子实体在图上做个性化 PageRank 多跳扩散)和 A-MEM⁸(把记忆组织为互联卡片网络,语义相关的记忆聚入同一个 Box,新记忆写入时自动与相关 Box 建立边);更早的 Ret-LLM⁶⁷ 把外部存储抽象成可寻址的三元组表,本质上是"轻量知识图谱"。
它解决的问题 :把 Flat Memory 推给检索的"关联推理"前置到写入阶段------写入时就在单元间建立显式边,这样多跳查询变成图遍历而不是多次向量召回。对于需要实体-关系推理的任务(知识问答、代码库 Agent、科研助手),这是一个质变。
它的代价(与 3D 有本质区别) :Planar 的局限可以总结为一句话:没有层次机制,所有记忆必须被整合进一个单一的单体模块;随着任务场景变复杂,这种扁平化设计会越来越力不从心;更关键的是构建和搜索的高成本显著阻碍了实际部署¹。具体来看有三类:
- 结构性天花板:所有粒度被压进同一层 --- Planar 只有一个"层"的概念,主题、事件、细节全部挤在同一个图里。查"这篇论文讲了什么"和查"这个公式第 3 行怎么推的"走的是同一套检索,无法做"先看大图、再下钻"。这不是写入质量的问题,是结构本身的上限,规模上去之后无解。
- 构建与搜索成本单调增长 --- 图要维护实体、关系、时间戳,新数据进来要跑实体消解、去重、边合并;查询时稍微复杂一点就要做多跳遍历(HippoRAG 的 PageRank 扩散也不便宜)。这部分随库规模线性到超线性增长,是 Planar 难以长期扩展的核心工程原因。
- LLM 抽取引入的噪声被结构化地固化 --- 这是所有"让 LLM 抽三元组"的方案都会遇到的问题:错误的实体/关系一旦进图,就成了图的骨架,比错误文本更难纠正。
定位 :当任务本身自带实体-关系结构(知识问答、人物关系、代码调用图)且规模可控时,Planar 是 Token-level 里最有性价比的一档;但它有天花板------一旦任务场景多样化、粒度分化明显,Planar 就必然要么继续吃性能退化,要么升维到 3D。
2.1.3 Hierarchical Memory (3D):跨层连边的立体结构
定义 :在多个层级 上组织信息,并通过层间连接(inter-level connections)把这些层绑成一个"立体"的记忆空间¹。典型的层次结构可能是"原始观测 → 事件摘要 → 主题模式"这样的抽象阶梯,Agent 既能横向在同层内浏览,也能纵向在不同抽象层级之间跳转。
Hierarchical Memory 有一个关键门槛需要注意:它不等于"把记忆分成几档存" ¹。光是分档,还是多份 Planar 拼在一起;真正的 Hierarchical 的门槛是层间必须有语义连接,比如"第 5 条细节记忆 → 被总结到第 2 条事件摘要 → 被归入第 1 条主题模式"这样一条可追溯的上行链路,反过来也可以从主题一路下钻到原始观测。
两种典型形态:
-
Pyramid(金字塔型):从底层原始事实自下而上抽象。代表是 HiAgent¹⁰(以子目标为单位:当前活跃子目标保留细粒度轨迹,已完成子目标折叠为上层摘要,需要时可按层级反查原始轨迹);GraphRAG³⁹(通过社区检测在实体图上递归聚合子图,形成 entity → community → theme 的多层索引,支持从细粒度到高层主题的 coarse-to-fine 检索);Zep³⁸把记忆形式化为时态知识图谱后,同样做了社区划分得到层次结构。
-
Multi-layer Graph(多层图):层与层之间都是图,层间再有跨层边。代表是 G-Memory⁹,在多 Agent 场景下构建**交互图(原始对话)→ 查询图(任务摘要)→ 洞察图(跨任务原则)**三层,每层是图、层间有语义连接,Agent 可以 query-centric 地在三层之间纵向穿梭,例如从"跨任务洞察"下钻到具体触发它的那次交互。
它解决的问题:一次复杂任务里,不同阶段需要不同粒度的信息------规划阶段想要"主题级概括",执行阶段想要"具体事件",复盘阶段又想要"原始观测回放"。Flat 和 Planar 都把这三种粒度塞进同一层,只能靠检索时的 top-K 概率碰,而 Hierarchical 把它们分层显式化,在结构上就支持"先看高层,不够再下钻"。
它的代价(和 2D 不是同类问题) :3D 的核心挑战可以概括为:结构的复杂性与稠密的信息组织给检索效率和整体有效性都带来挑战;确保所有记忆仍然语义有意义、并设计最优的三维布局,是困难且关键的问题 ¹。3D 的痛点不是"长不大",而是"太复杂,出错会放大":
- 层间一致性:错误会沿层向上传播 --- 3D 最致命的地方是底层一条错误摘要会污染所有上层 :比如底层事件记忆把"用户讨厌辣"抽成"用户喜欢辣",这条错误会被总结进事件层、再归纳进主题层------等 Agent 下次规划时,错误的已经不是一条原始记忆,而是一整条抽象链路。相比之下,2D 的抽取噪声是"局部的"(错一条边影响有限),3D 的层间噪声是"系统性的"(错一条摘要污染整个金字塔分支)。这本质上类似数据库里"物化视图一致性"的问题,但在 LLM 里用自然语言表达,没有清晰的触发器机制。
- 三维布局设计本身就难 --- 分几层?每层用什么粒度?层间用什么连接规则?这些问题至今没有通用答案,通常要为每个任务类型单独设计¹。
- 构建和维护成本陡升 --- Formation 阶段要跑多轮抽象、社区检测或主题聚类;Evolution 阶段每次底层更新都要判断是否触发层间级联更新;遗忘底层条目时还要考虑上层摘要是否失去依据。检索效率同样要付代价------稠密的层间链接让查询有可能走进过多路径。
- 过度设计风险 --- 如果任务本身没有多粒度需求,三层结构只会带来复杂度而看不到收益。
2D 和 3D 的代价到底差在哪 ?一句话:2D 的问题是"单层结构撑不住复杂任务"------病在容量;3D 的问题是"层间错误会被结构放大、且布局难以设计"------病在噪声扩散与设计难度。不要以为 3D 只是 2D 的"升级版没坏处"------它用更强的表达力换来了更脆弱的错误边界。
定位:长程、多阶段、跨任务的 Agent 系统(长程规划、多 Agent 协作、终身学习型助手)里,Hierarchical 是目前的事实标准;但在单轮对话或短程任务里,它基本是 overkill。
2.1.4 一张速查表:三个维度到底差在哪
| 维度 | 单元间关系 | 层次 | 主要解决 | 主要代价 | 典型代表 |
|---|---|---|---|---|---|
| Flat (1D) | 无显式关系 | 单层 | 低成本追加、高频写入 | 多跳失联、冗余累积 | Reflexion⁵, MemGPT⁶ |
| Planar (2D) | 同层内显式拓扑(图/树/表) | 单层 | 实体-关系推理、多跳查询 | 单层容量上限、构建/搜索成本、抽取噪声局部固化 | HippoRAG⁷, A-MEM⁸ |
| Hierarchical (3D) | 同层有结构 + 跨层有语义连接 | 多层 | 多粒度导航、coarse-to-fine | 层间错误放大、三维布局难设计、级联维护成本 | G-Memory⁹, HiAgent¹⁰, GraphRAG³⁹ |
所以 1D/2D/3D 不是"哪个更先进"的简单递增关系 ------它是"愿意付多少组织成本来换多少推理能力"的三个锚点。工程上一个比较稳的渐进路径:先用 Flat 跑通业务闭环;发现多跳检索明显断链时升到 Planar;只有当任务开始出现"阶段切换需要不同粒度"且有能力处理层间一致性时,才有理由上 Hierarchical。
2.2 Parametric Memory:把知识写进权重
参数化记忆的思路完全不同------不再外挂,而是把知识直接编码进模型参数,推理时零检索延迟,和模型内在推理深度整合。按存储位置可以分为两支¹:
- Internal Parametric Memory(内部参数记忆):直接改原始权重。代表工作是 ROME¹¹(先用因果追踪定位存储某条事实的 MLP 层,再做 rank-1 权重更新)和 MEMIT¹²(把 ROME 扩展到批量编辑,通过 Multi-Layer Residual Distribution 同时改写多层,把可编辑知识规模从个位数推到数万条)。难点集中在"精确定位---定向编辑"这件事------在大模型的参数空间里精准找到某条知识对应的子集并且不扰动其它知识,目前仍然是脆弱的。
- External Parametric Memory(外部参数记忆):不动原始权重,而是通过 Adapter / LoRA 这类附加模块来承载记忆,代表有 WISE¹³(把预训练知识和编辑知识放在独立参数集里,用 Router 路由)和 ELDER¹⁴(维护多个 LoRA,学习一个自适应融合函数按输入语义混合)。相比改原权重更稳定,但记忆通过注意力间接起作用,注入效果受接口质量和路由质量牵制。
参数化记忆的通病是"灾难性遗忘"------新知识覆盖旧知识,更新完之后还可能被后续微调逐渐抹掉。这也是为什么它在绝大多数工程系统里还没成为主流:它更适合存稳定的、可被视为"能力"的先验(比如工具调用模式、角色设定),而不适合存高频变更的事实。
2.3 Latent Memory:以连续表示为载体
潜在记忆把历史编码成模型内部的连续表示(KV Cache、激活、嵌入向量),在隐空间里直接传递信息。它天然亲和多模态,推理效率也高,但可解释性差、难以调试。按操作方式可以细分为三种¹:
- Generate(生成型潜在记忆):通过辅助编码器把任意长度输入压缩为若干密集向量,例如 AutoCompressor¹⁵(训练模型把长文档压成 summary tokens 供后续作为 soft prompt)和 CoMEM¹⁶(用 Q-Former 把视觉语言输入压成定长连续记忆 token)。
- Reuse(复用型潜在记忆):直接把前向计算产生的 KV Cache 当作持久记忆跨轮复用,代表是 Memorizing Transformers¹⁷(维护外部 KV 库,通过 kNN 检索历史 KV 对注入当前层注意力)和 LONGMEM¹⁸(用轻量残差 SideNet 管理历史 KV 嵌入)。
- Transform(变换型潜在记忆):对已有 KV 做压缩、剪枝、重编码,例如 SnapKV¹⁹(按注意力头做多数投票保留关键 KV)和 PyramidKV²⁰(发现不同层对 KV 预算的需求不同,按层动态分配)。
潜在记忆更像是长上下文研究和 Agent Memory 的交汇地带。它的典型问题是语义漂移------在隐空间里做多轮复用和变换时,没有可解释的校验机制,误差会随迭代累积。
2.4 小结:什么任务选什么形态
记忆形式的选择不是单维优化,而是任务依赖的¹。几条实用的经验法则:
- 需要人工审计、频繁增删改的场景(多轮对话、金融/法律知识库):Token-level 为主;
- 稳定的角色先验、工具使用模式:Parametric 作为补充;
- 多模态、边缘部署、隐私敏感场景:Latent 更合适。
三、Functions:Agent 为什么需要记忆?
这一章解决的问题 :从 Form 转到认知功能------Agent 到底为什么事情去记?这里需要跳出长/短期这种时间维度的粗分类,改用三类功能来划分¹:Factual(事实记忆)/ Experiential(经验记忆)/ Working(工作记忆)。这三者的关系大致是"知道什么 / 如何做得更好 / 现在关注什么"。
共通难点:如何从大量噪声轨迹中识别出真正有长期价值的信息?如何让记忆在泛化性和情境特异性之间取得平衡?如何在有限的注意力预算下,让每一次推理都"看得见"真正相关的片段?
3.1 Factual Memory:保持一致性与连贯性
事实记忆存的是 Agent 关于用户和外部环境的声明性知识,它的作用是让 Agent 不要每次都"失忆"。可以进一步分为两支¹:
- User Factual Memory:用户相关的事实(身份、偏好、历史承诺)。代表工作是 MemGPT⁶(LLM 自主决定何时触发写入和压缩)和 RMM(Reflection-based Memory Management)²¹(把用户交互定期转化为话题级反思记录,新记忆先检索相似候选再由 LLM 判断是否合并)。真正的难点不是"存多少",而是"选择性地存哪些"------并非所有对话都值得持久化,过度筛选又会丢关键信息,用户偏好本身还会随时间演变。
- Environment Factual Memory :关于外部世界、代码库、工具和其他 Agent 的事实。代表有 HippoRAG⁷(用持久知识图谱承载长文档,支持多跳关系推理)和 MetaGPT²²(多 Agent 系统里的共享消息池作为协调基础)。难点在一致性维护:外部世界持续变化,记忆需要增量更新,多 Agent 场景还要解决写冲突。
3.2 Experiential Memory:把"发生了什么"转成"下次怎么做"
经验记忆是把原始交互轨迹沉淀为过程性知识,按抽象层级可以分四类¹:
- Case-based Memory(案例记忆):直接保留轨迹的最小化处理版本,代表是 ExpeL²³(对比成功与失败轨迹,保留成功轨迹作为 few-shot)和 Memento²⁴(用 Soft Q-Learning 动态调整轨迹采样概率,而不是简单的相似度)。好处是保真度高;代价是检索噪声大、案例质量参差不齐,低质案例会带来负迁移。
- Strategy-based Memory(策略记忆) :从轨迹里提炼可迁移的高层知识(规划模式、推理模板、工作流),代表是 AWM (Agent Workflow Memory)²⁵(从 Web 交互里自动归纳可复用工作流)和 Buffer of Thoughts²⁶(维护可迁移的元级思维模板库)。难点是抽象时的泛化/可操作性权衡,以及缺乏可靠的自动质量评估。
- Skill-based Memory(技能记忆) :把经验封装成可执行能力(代码、函数、API、MCP 工具)。代表是 Voyager²⁷(在 Minecraft 里持续积累 JavaScript 技能库,语义检索复用)和 ToolLLM / Gorilla²⁸²⁹(把大规模 API 文档训练进模型,并建立工具向量索引做语义级工具检索)。工具规模指数增长之后,工具的语义理解和检索本身就成了瓶颈。
- Hybrid Memory:单一形式都有短板,因此高层策略+底层案例/技能的组合正在成为主流,代表是 ExpeL 扩展版²³和 Agent KB³⁰(分层知识库:高层工作流引导方向,底层具体解决方案提供执行细节)。
经验记忆从 Case → Strategy → Skill 一路拉出来看,是抽象程度和可执行性之间的一条谱系:越具体,保真度越高、越难迁移;越抽象,越通用、但越依赖 LLM 自身的归纳能力。实际系统里几乎都是多种混用。
3.3 Working Memory:单任务内的推理工作区
工作记忆关心的不是跨任务长期状态,而是单次任务实例内的活跃上下文管理------把上下文窗口从被动只读的缓冲区变成可主动维护的推理工作区。按时间粒度分为两种¹:
- Single-turn Working Memory:单次前向计算里处理超长输入。代表是 LLMLingua³¹(按 token 困惑度估信息价值,做到 20× 压缩;LongLLMLingua 进一步引入 query-aware 动态压缩率)和 Synapse³²(在 Web 自动化里把 DOM 观测抽象为任务相关状态描述)。
- Multi-turn Working Memory:长程交互中维护"当前真正重要"的那一小块状态。代表是 MemAgent³³(固定预算的紧凑记忆,新观测进来先合并再压缩,用 RL 优化压缩策略)和 HiAgent¹⁰(以子目标为折叠单元,已完成子目标折叠为摘要,活跃窗口只保留当前子目标细节)。
工作记忆这条线和 Context Engineering 最容易混,区别在于它是"任务内的短期认知工作区",而 Context Engineering 是"每一步 Prompt 怎么拼"------两者是层次关系,不是对立关系。
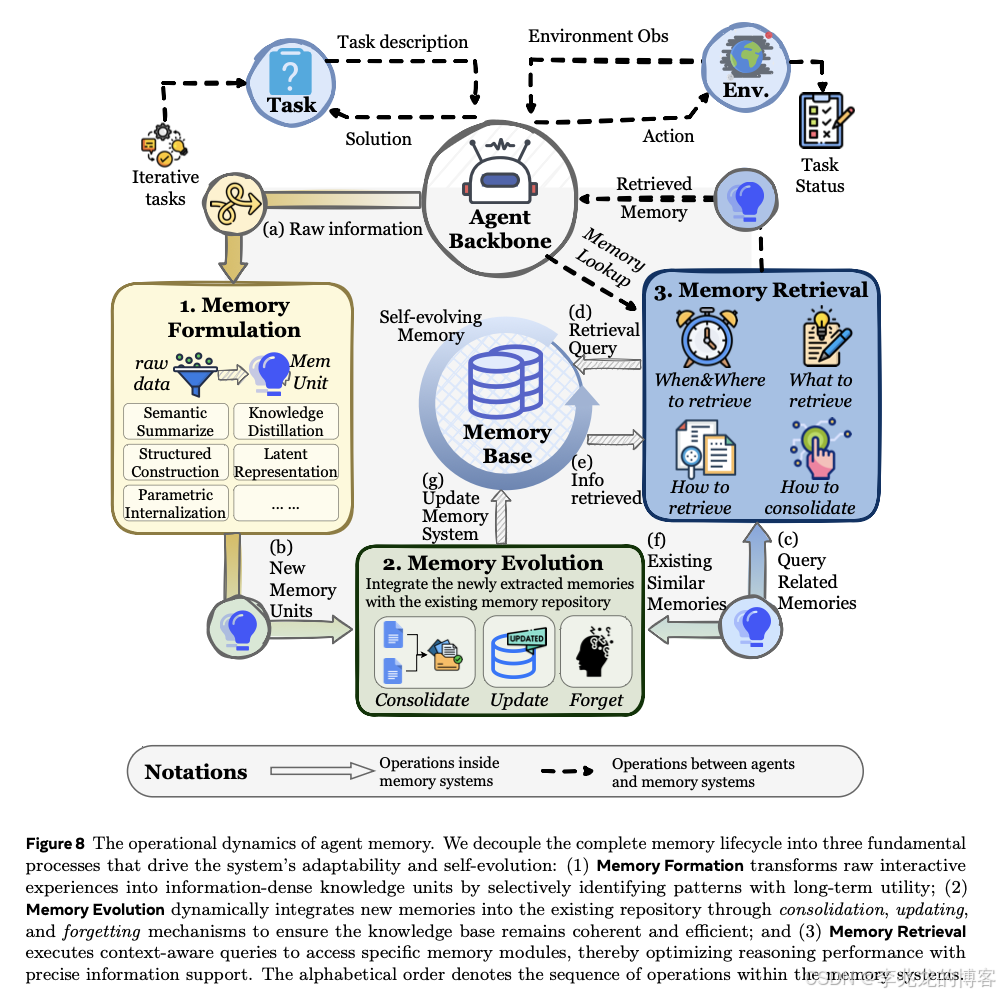
四、Dynamics:记忆如何运作与演化
这一章解决的问题:把记忆从"静态的库"变成"活的系统"。静态的向量库只是一个数据库;只有当 Formation / Evolution / Retrieval 三个过程都被显式建模时,它才算得上一个记忆系统¹。下面按三个阶段展开。
4.1 Memory Formation:原始交互如何变成记忆
解决的问题 :原始交互数据(对话、工具输出、环境反馈)体量大、噪声多、冗余高,直接存既占空间又降检索质量。Formation 要做的是有损压缩 + 结构化提炼。
主要有五条技术路线¹:
- Semantic Summarization(语义摘要) :把长对话压成紧凑语义摘要。代表是 ReadAgent³⁴(先做语义聚类再分区摘要,缓解跨段语义不连贯)和 Mem1³⁵(用 GRPO 训练模型学最优的增量摘要策略)。增量式 chunk-by-chunk 摘要的主要风险是累积误差导致全局语义漂移。
- Knowledge Distillation(知识蒸馏):在更细粒度上从轨迹里提出"具体可复用的知识"。代表是 R2D2³⁶(同时从正确和错误步骤里提炼反思洞察,形成双向修正)和 Mem-α³⁷(引入可训练的 LLMExtract 模块,端到端学习何时提、提什么、怎么留)。脱离固定 Prompt、走向可训练提炼模块,是这个方向比较明显的趋势。
- Structured Construction(结构化构建):把非结构化文本转成显式拓扑(知识图谱、层次树)。代表是 Zep³⁸(时态知识图谱,情节子图记事件时间戳,语义子图存实体关系,社区子图做高层聚类)和 GraphRAG³⁹(从文档里抽实体图,再用社区检测递归聚合子图为社区摘要,构建多层次索引)。关键困难是实体关系抽取的噪声和动态更新的成本。
- Latent Representation(潜在表示):直接把经历编码成连续向量或 KV 状态,跳过自然语言摘要。代表是 MemoryLLM⁴⁰(Transformer 每层嵌入可自更新的持久记忆向量,从参数化隐向量中召回记忆)和 ESR (Encode-Store-Retrieve)⁴¹(把第一人称视频帧编码成语言嵌入向量入库,用自然语言查询过去的视觉经历)。
- Parametric Internalization(参数内化):把外部记忆通过梯度写进权重,实现零延迟隐性访问。代表是 ROME¹¹(定向权重编辑)和 ToolFormer⁴²(把工具调用的决策逻辑 SFT 进模型权重)。它面对的是典型的稳定性-可塑性困境。
4.1.1 这五条路线怎么选?
这五类技术的划分依据可以归结为两个维度:压缩粒度 和编码逻辑¹。它们不是替代关系,而是沿这两个维度分布的不同锚点。把这两个维度展开,就能得到一张可操作的选择图:
维度一:压缩粒度(留多少原始信号 ↔ 留多少抽象信号)
信号保真度高 抽象程度高
├──────────────────────────────────────────────────────────┤
Latent Structured Semantic Knowledge Parametric
Representation Construction Summarization Distillation Internalization
(几乎不压缩) (保留实体关系) (留全局语义) (留可复用单元) (化为能力)维度二:编码形态(人类可读 ↔ 机器可读)
- 人类可读侧:Semantic Summarization、Knowledge Distillation、Structured Construction------存的是自然语言或显式结构,可以审计、编辑、跨模型迁移;
- 机器可读侧:Latent Representation、Parametric Internalization------存的是向量或权重,无法直接审阅,但零延迟、天然多模态。
基于这两个维度,可以用一套五问决策流程,在面对新场景时快速判断先上哪条路线:
-
记忆需要人工审计、编辑、或被监管吗?
- 是 → 只能在 Summarization / Distillation / Structured Construction 里选;
- 否 → 进入下一步。
-
这些信息后续需要做多跳推理、关系查询、或 coarse-to-fine 导航吗?
- 是 → Structured Construction(知识图谱、层次树),让关系在写入时就显式化;
- 否 → 进入下一步。
-
存的是"具体可复用的小单元"(事实、规则、偏好、API 用法),还是"全局宏观语义"(对话主题、文档脉络、任务流程)?
- 小单元 → Knowledge Distillation(从轨迹里细粒度提取);
- 宏观语义 → Semantic Summarization(压成高层蓝图)。
-
涉及多模态信号(视频、图像、音频)或推理延迟极敏感吗?
- 是,且可解释性不是硬需求 → Latent Representation(跳过自然语言摘要,直接编码为向量/KV);
- 否 → 留在前三类里。
-
这条知识是不是稳定、通用、高频访问、且可以作为"模型能力"而非"知识条目"的?(例如工具调用格式、角色设定、领域语法)
- 是 → Parametric Internalization(SFT / 权重编辑,一次写入、永久低延迟);
- 否 → 不要轻易动权重,灾难性遗忘的代价远大于增量存储。
一张速查表对照五种路线的典型取舍:
| 路线 | 压缩粒度 | 可解释性 | 推理延迟 | 更新成本 | 典型场景 |
|---|---|---|---|---|---|
| Semantic Summarization | 中(全局语义) | 高 | 低 | 低 | 长对话摘要、文档脉络、用户画像 |
| Knowledge Distillation | 细(可复用单元) | 高 | 低 | 中 | 经验沉淀、反思洞察、规则抽取 |
| Structured Construction | 细+带关系 | 高 | 中(图遍历) | 中偏高 | 知识问答、代码库、多跳推理 |
| Latent Representation | 极低(几乎不压缩) | 低 | 极低 | 中 | 多模态、长上下文、边缘部署 |
| Parametric Internalization | 极高(化为权重) | 极低 | 零(已内化) | 极高 | 稳定能力先验(工具调用、角色、领域语法) |
几个在工程里特别容易踩坑的判断误区:
- 不要把"什么都丢给 Structured Construction"当成默认方案。知识图谱看起来很美,但实体关系抽取的噪声会被结构化固化(见 2.1.2 节);如果任务没有明显的实体-关系结构,Summarization + Distillation 的组合往往更稳。
- Parametric Internalization 不是"升级版的外部记忆" 。它面对的是稳定性-可塑性困境,只适合存稳定且不常变的知识------把高频变更的事实(比如用户偏好)写进权重基本等于自找麻烦。
- Latent Representation 的一个常见陷阱是调试黑盒。多轮复用和变换会带来语义漂移,而潜在空间没有任何人类可读的校验机制。在生产系统里至少要搭配一条"可回读的人类可读镜像"(比如摘要)做旁路审计。
最后一个重要观点 :这五类不是互斥的 ------单个算法完全可以整合多种 formation 策略,在不同表示之间转换知识¹。真实系统里几乎一定是分层混用的:
一个比较稳的工程配方:热数据(当前任务轨迹)走 Semantic Summarization 快速压缩;中间层(跨会话经验)走 Knowledge Distillation 提炼成可复用单元;长尾冷数据走 Structured Construction 建图做归档;多模态部分用 Latent Representation 保底;最稳定的领域先验/角色行为最终通过 Parametric Internalization 固化进模型。
这五条路线本质上是在"压缩粒度、可解释性、延迟、更新成本"这四个轴上的不同取舍点------选路线的过程,本质是想清楚要为哪一项付出代价。
4.2 Memory Evolution:如何让记忆保持健康
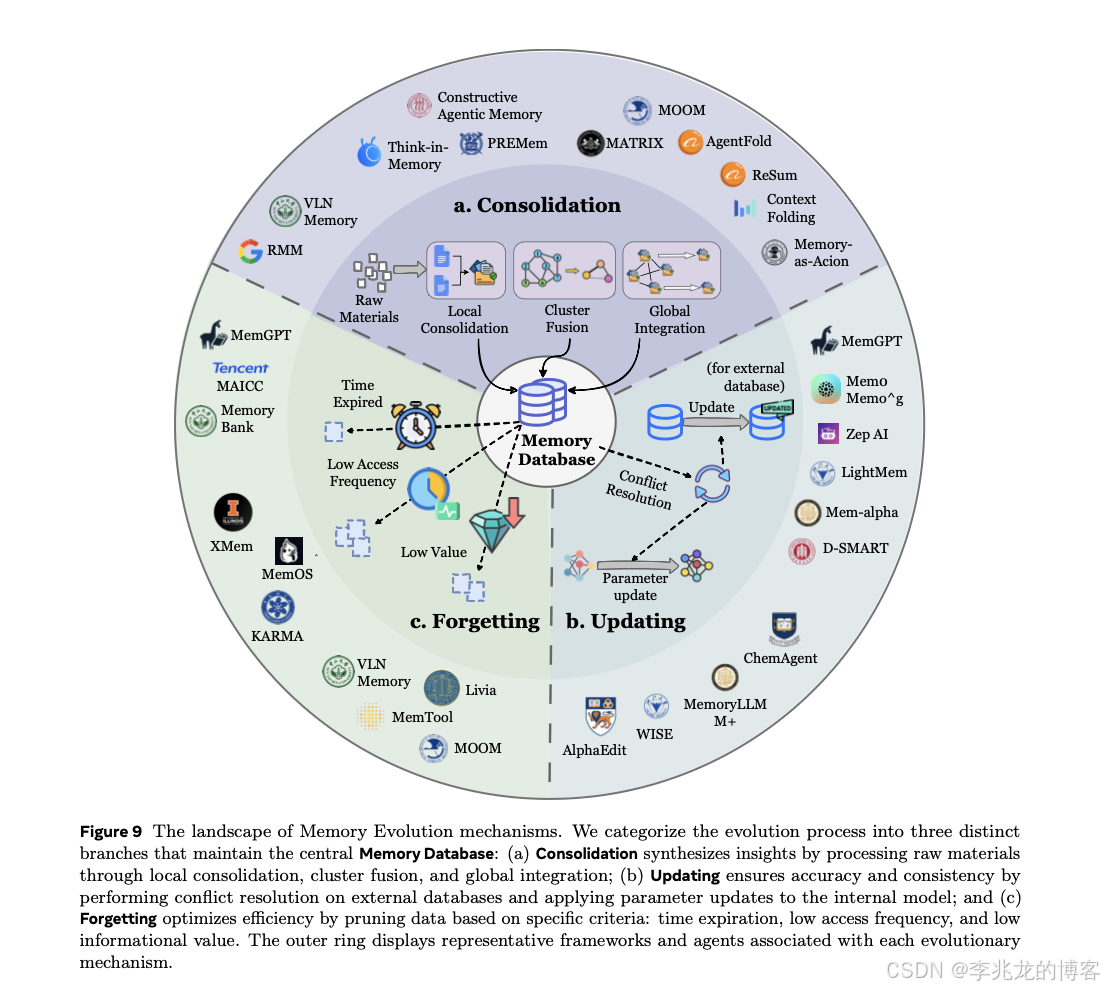
解决的问题 :如果只是不停追加新记忆,记忆库会迅速退化为"大而脏"的仓库------冗余、冲突、过时。Evolution 要做的是主动管理,让记忆库在泛化性、一致性和时效性上保持健康。主要有三类动作¹:
- Consolidation(整合):把分散的短期片段重组为结构化长期知识,识别并合并重复或相关条目。代表是 TiM (Think-in-Memory)⁴³(每轮触发 LLM 反思,比较新话题记忆和最相似历史条目,由 LLM 判断是否合并)和 Matrix⁴⁴(对执行轨迹迭代优化和全局整合,蒸馏跨任务通用原则)。难点在整合粒度------太激进会错误泛化,太保守就永远在冗余。
- Updating(更新):冲突或失效时精确修正条目。代表是 Zep³⁸(不做硬删,给旧事实加"已过时"时间戳,软更新保留时序完整性)和 Mem-α³⁷(把更新决策建模为 RL 策略学习,长期任务性能作为激励)。稳定性-新鲜度的权衡是主要挑战。
- Forgetting(遗忘):主动清除低价值条目。代表是 MAICC⁴⁵(软遗忘:重要性权重随时间指数衰减,不做硬删,避免关键稀有信息被误清)和 TiM + MemTool⁴³⁴⁶(用 LLM 作为记忆重要性评判器,从语义层面评估长期价值)。传统 LRU/LFU 的问题是会清掉"低频但关键"的长尾知识,这类语义感知遗忘是必要的升级。
Evolution 这一层是目前工程系统最容易偷懒的一层------很多所谓"上了记忆"的系统只有 Formation 和 Retrieval,没有 Evolution,本质上只是在往漏斗里灌水。真正的长期系统离不开它。
4.3 Memory Retrieval:从库到推理的接口
解决的问题:记忆检索是记忆系统和推理之间的接口层,它的质量直接决定推理质量。检索可以拆成四个依次衔接的步骤¹,这套拆解在工程上非常实用。
步骤一:Retrieval Timing and Intent(检索时机与意图)
- 解决的问题 :决定何时 触发检索,以及查哪个记忆模块(事实?经验?工作?)。无脑每次必检会引噪、增成本;遗漏又会诱发幻觉。
- 难点:Agent 需要实时评估自己的知识边界------"这个问题我是不是已经知道了?"这是个元认知问题,靠纯 Prompt 决策既脆弱又不稳定;多模块路由又会随系统规模指数变复杂。
- 技术方向 :
- 快慢思考触发:代表是 ComoRAG / PRIME⁴⁷⁴⁸,先生成初步回答,评估模块判断是否充分,不充分才触发深度检索,形成"先轻后重"的渐进式检索。
- 层次化意图路由:代表是 H-MEM⁴⁹,从领域层(Domain)逐步缩小到情节层(Episode),用多步过滤压缩候选空间;MemGPT / MemTool⁶⁴⁶则把检索当成函数暴露给 LLM 自主调用。
步骤二:Query Construction(查询构建)
- 解决的问题:用户原始输入("上次那个事情")和记忆库索引(结构化摘要、向量)之间存在语义鸿沟,直接拿原 Query 去检索在知识密集型和多跳场景下表现很差。
- 难点:复杂问题的分解逻辑本身依赖检索结果(我需要先知道"缺什么"才能构造子查询);查询改写对 LLM 理解能力要求高,改写也会引入新偏差。
- 技术方向 :
- 查询分解:代表是 MA-RAG⁵⁰,引入 Planner Agent 先制定检索计划,识别哪些知识片段是必要的,再生成针对性子查询。
- 查询改写:代表是 HyDE⁵¹,让 LLM 先生成"假设性文档",用其嵌入去做检索,相当于把 Query 从"问题侧"对齐到"答案侧"的语义分布。
步骤三:Retrieval Strategies(检索策略)
- 解决的问题:从大库里高效准确地找到最相关的知识,在精度/召回、以及不同存储结构(扁平文本、向量、图)之间做平衡。
- 难点:词法检索无法捕捉语义变体;语义检索的强制 top-K 会引入弱相关噪声;图检索在多跳扩散时路径爆炸;没有单一策略普遍占优。
- 技术方向 (四类主流方案):
- 词法检索(BM25):精确匹配术语和工具名,适合精度优先场景,但对语义变化敏感。
- 语义检索(Dense Retrieval):Sentence-BERT / CLIP⁵²⁵³类方案,共享嵌入空间里算余弦相似度,是当前主流默认方案。
- 图检索:HippoRAG⁷典型做法------检索出种子实体节点后在图上用 PageRank 扩散,多跳推理任务上显著好于纯向量。
- 混合检索:代表是 Agent KB³⁰,结合词法与语义,再叠加工具相关性、任务阶段优先级等多因子加权。
步骤四:Post-Retrieval Processing(检索后处理)
- 解决的问题:初步结果常带冗余、语义不一致、时间线矛盾的片段,直接塞进上下文会干扰推理甚至导向错误结论。
- 难点:重排评判标准难以统一(时间有效性、角色相关性、任务阶段),多来源聚合要解决语义冲突,机械合并会产生前后矛盾。
- 技术方向 :
- 学习式重排:代表是 learn-to-memorize⁵⁴,把多信号聚合(语义相似度、时间戳、重要性)建模为 RL 问题学习最优加权,避免手工调参。
- 聚合与压缩:代表是 MA-RAG 的 Extractor Agent⁵⁰,对每份检索结果做细粒度内容筛选,只留下和当前子查询强相关的精简片段,产出高密度局部上下文。
把这四步连起来看,有一个值得注意的趋势:Retrieval 正在被整体建模为一个 RL/Agent 问题,而不是"向量检索 + top-K"的传统流水线。Timing、Query、Ranking、Aggregation 这几个步骤里都已经出现了以学习代替启发式的代表作。
一个比较典型的例子是 MemSearcher ⁵⁹。它把整个检索流程抽象成一个 MDP------状态 是当前的任务上下文和紧凑的工作记忆,动作空间 同时包括"是否检索 / 生成怎样的子查询 / 从候选里保留哪些 / 丢弃哪些"这四类本来分散在不同步骤的决策,奖励直接来自下游任务的最终表现(比如问答是否正确)。训练完之后,这四步不再由人写死的启发式拼接------"什么时候查"不是 if-else 判断答案置信度,而是学出来的策略动作;"怎么改写查询"不是 HyDE 这类固定模板,而是策略学会了在哪类问题下应该怎么扩展;"保留哪些片段、丢弃哪些"也成了策略的一部分。这类 RL-assisted 系统正在变成长程/多轮任务里的主流做法¹。
和它互补的另一个典型是 Memory-R1 ⁵⁷,切入点略有不同------把"记忆管理"本身打包成工具(add / update / delete / 搜索)暴露给 Agent,然后用 RL 训练 Agent 主动决定什么时候调用哪个工具,同时还配了一个 LLM-based 的 Answer Agent 对检索结果做"可用不可用"的语义过滤。这等于把 Timing(调不调)、Intent(调哪个模块)、Post-Retrieval(用什么)三件事都变成可学习动作。
两者对比一下启发式方案就能看出差别:
| 步骤 | 传统启发式做法 | RL 驱动做法(以 MemSearcher / Memory-R1 为例) |
|---|---|---|
| Timing | 每次必检 / 置信度阈值 | 作为策略动作,任务奖励直接反向传播 |
| Query | 固定 HyDE 模板 / 关键词抽取 | 策略根据上下文生成子查询,训练目标对齐下游任务 |
| Ranking | 手工调整相似度+时间戳权重 | RL 学习最优聚合策略(learn-to-memorize⁵⁴) |
| Aggregation | 规则式丢弃 top-K 外的 / 固定模板融合 | LLM-based Answer Agent 学习保留哪些、舍弃哪些 |
但目前的 RL 驱动记忆系统都只覆盖了生命周期的一部分 ------MemSearcher 只管工作记忆,不管跨任务的长期整合与演化;Mem-α³⁷ 覆盖了记忆写入但还依赖人工设计的检索管线;Memory-R1 主要针对记忆操作而非整条流水线。真正完整的 Agent Memory 系统需要把 Formation、Evolution、Retrieval 三条生命周期全部端到端地纳入 RL 训练¹,这也是下一章 Frontiers 里 "RL Meets Agent Memory" 这条线的核心命题。
4.4 RL 驱动的记忆系统不是"不需要记忆系统了"
讨论到 MemSearcher、Memory-R1 这类 RL 工作时,很容易出现一个错觉------"既然 RL 把记忆管理学会了,那是不是就不需要专门的记忆系统了?" 这个判断恰好相反。RL 驱动的记忆系统不但没有削弱基础设施,反而对基础设施提出了更高的要求。
理解这件事的关键,是把记忆系统拆成两层来看:
| 层次 | 负责什么 | 实现方式 |
|---|---|---|
| Memory Substrate(记忆底座) | 真正把 Mt\mathcal{M}_tMt 这个状态存下来 、查出来 、改掉 | 向量库 / 图库 / KV 存储 / 倒排索引 / 时态结构 |
| Memory Policy(记忆策略) | 决定何时查 、用什么 Query 、保留哪些结果 、什么时候写回 、写成什么样 | Prompt / 规则 / RL 策略 |
RL 工作替代的是第二层------它不关心记忆到底怎么存,它关心的是记忆操作怎么被调度。而第一层(Substrate)在 RL 范式下反而必须变得更稳、更原子、更语义清晰。
从 RL 视角看,记忆扮演两个角色
回到 §1.1 里那个形式化:at=πi(oti, mti, Q)a_t = \pi_i(o_t^i,\ m_t^i,\ \mathcal{Q})at=πi(oti, mti, Q)。当我们把记忆管理纳入 RL 训练时,Mt\mathcal{M}_tMt 会同时出现在两个地方------
- 作为环境状态的一部分 :Mt\mathcal{M}_tMt 是 MDP 里 sts_tst 的组成部分,Agent 无法直接读取,只能通过 Retrieval 动作去观察它;
- 作为动作空间的扩展 :记忆操作本身变成可调用的工具,Agent 的动作空间 A\mathcal{A}A 里增加了一组原语 {retrieve, write, update, delete, consolidate, ...}\{\text{retrieve, write, update, delete, consolidate, ...}\}{retrieve, write, update, delete, consolidate, ...},这正是 Memory-R1⁵⁷ 的核心设计------把 add / update / delete / search 打包成工具给 Agent 调。
Substrate 是环境的一部分,Policy 是策略的一部分,这个分工一旦看清,RL 与 Agent Memory 的关系立刻清晰。
为什么 RL 反而对 Substrate 提出更高要求
这和数据库领域的一个经典观察是一致的:上层调度越智能、越动态,下层存储就越需要是原子的、可重放的、语义清晰的。具体有三条硬性要求:
- 动作语义必须稳定 :如果
retrieve(query)的语义每天都在变(今天 top-K=5,明天换成图扩散),策略就无法收敛。所以 Substrate 暴露的 API 必须是语义冻结 的------就像 SQL 之于数据库,上层应用怎么变,底层SELECT的语义不能变。这正好也解释了为什么博客 §4.3 要把 Retrieval 拆成 Timing / Query / Ranking / Aggregation 四步独立原语------这四步不只是一个理论切分,它同时是给 RL 策略定义动作粒度的 API 契约。 - 环境必须可重放 :RL 训练要求从同一个 sts_tst 出发多次采样得到的 st+1s_{t+1}st+1 分布一致。这要求 Substrate 支持版本化(每条记忆的写入/修改都有版本号)、幂等操作、时间戳完整性(能还原任意时间点的 Mt\mathcal{M}_tMt)。这也正是 Zep³⁸ 那种"时态标注软更新"真正的价值------它不只是为了人看起来清晰,而是为了让 Mt\mathcal{M}_tMt 成为一个可回溯的环境状态。
- 奖励必须能穿透回记忆操作 :一次
write的长期价值可能要等 20 轮之后才在任务成功率上显现,这要求 Substrate 保留足够的元数据做 credit assignment------这条记忆是谁写的、什么时候被读过、读出来之后用在哪次推理里、那次推理最终是否成功。Memory-R1 的记忆条目都带着"被访问次数 / 被采纳次数 / 被修改历史",没有这些元数据,RL 就没法把远期奖励反传到早期的记忆操作。
按 "Substrate × Policy" 给现有系统分层
如果用这个视角回看前面出现过的各种记忆系统,会发现它们其实是沿着一条清晰的智能度分层排开的:
| 层级 | Substrate | Policy | 代表 |
|---|---|---|---|
| L0:静态库 | 向量库 | 固定规则(top-K) | 朴素 RAG |
| L1:Prompt 驱动 | 向量库 / 图库 | LLM Prompt 决策(自由形式) | MemGPT⁶、Reflexion⁵ |
| L2:工具化 | 向量库 + 时态图 | Agent 调用 memory tools,但策略未经学习 | CAM⁵⁶、MemGPT 的 search_memory() |
| L3:RL 驱动策略 | 时态图 + 版本化存储 + 丰富元数据 | 记忆操作作为工具,策略通过 RL 学出来 | MemSearcher⁵⁹、Memory-R1⁵⁷ |
| L4(未来):端到端 | 同 L3,但 Substrate 的 schema 本身也可学 | Substrate + Policy 一起端到端优化 | 尚无系统全面实现¹ |
这张表里最关键的观察是:Substrate 的丰富度和 Policy 的智能度是正相关的,不是相互替代的。从 L0 到 L3,Substrate 在不断变复杂(从朴素向量库 → 时态图 → 版本化存储 → 元数据完备),这是为了承接越来越智能的 Policy。
这意味着什么:下一代记忆系统的工程形态
把这层分工推到产品形态上,会得到几个比较直接的推论:
- 记忆系统会像数据库一样分化为 Substrate 层和 Policy 层------前者标准化、通用化、可被任意 Agent 复用;后者业务相关、策略化、每个 Agent 自己训。
- Memory Substrate 的形态会越来越像"数据库 + MCP 工具"的融合:稳定的 CRUD 原语 + 语义级查询 + 版本时序能力 + 元数据追踪。
- 做 Memory 的团队和做 Agent 的团队会进一步分工:前者沉淀 Substrate(能力通用、不绑业务),后者训练 Policy(能力业务相关、绑定场景)。这一分工和数据库之于业务应用的历史分工完全一致。
- Substrate 必须先被打磨到 "RL-friendly" ------版本化、元数据完备、原子幂等------是训练记忆策略的前提,而不是事后补的东西。
回到那个起点:RL 驱动的记忆系统不是"不需要记忆系统",而是把记忆系统推向了一个更底层、更稳定、更像数据库的形态。这也是为什么把记忆当作 Agent 的一等公民、并为其单独设计基础设施,在未来几年会越来越重要。
五、Positions and Frontiers:哪里是前沿
5.1 从 Memory Retrieval 走向 Memory Generation
当前状态 :主流范式把记忆当静态库,检索目标是"找到最相关片段"。但越来越多的工作表明,真正有效的记忆利用往往是主动合成------用检索结果作为原料生成更适配当前任务的记忆表示(Retrieve-then-Generate,如 ComoRAG⁴⁷),甚至直接跳过检索,从当前推理状态合成任务定制的潜在记忆 token(Direct Generation,如 MemGen⁵⁵)。
未来挑战:生成式记忆要具备上下文自适应性(按任务阶段动态调整抽象粒度)、多信号融合能力,还需要用端到端优化信号(任务成功率)来学"什么时候生、怎么生"。
5.2 Automated Memory Management
当前状态 :绝大多数记忆系统还依赖人工规则驱动(固定阈值、静态 Prompt 模板)。近期的转变是把记忆操作(add / update / delete / retrieve)暴露为 Agent 可自主调用的工具,让 Agent 在决策循环里直接规划记忆操作,代表是 CAM⁵⁶、Memory-R1⁵⁷。
未来挑战 :走向真正自组织的记忆架构------能随经验动态调整链接结构、索引方式、抽象层次,最终记忆系统自身也具备自我进化能力。
5.3 Reinforcement Learning Meets Agent Memory
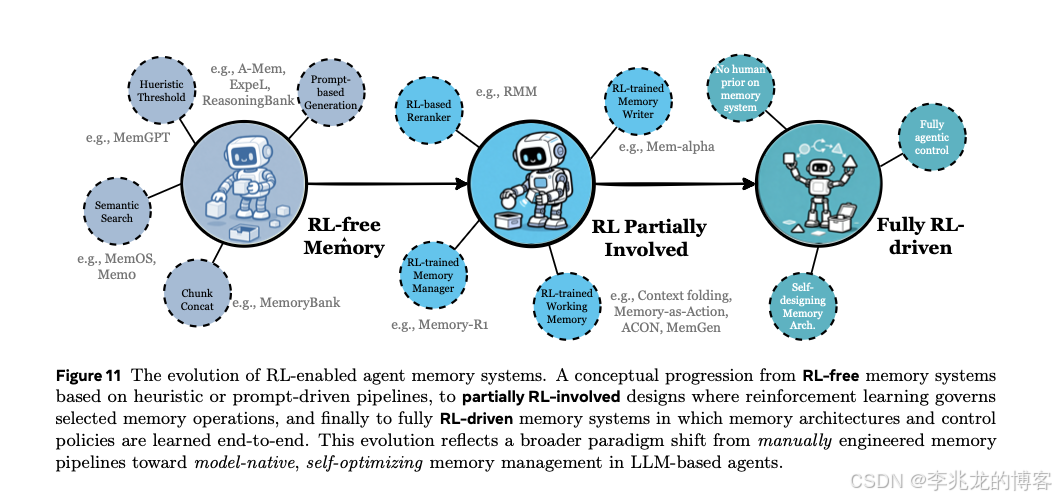
当前状态:记忆管理的核心决策(何时整合、何时遗忘、如何检索)大多来自人工启发式,缺乏对任务目标的直接优化。RL 已经从辅助局部操作(RMM²¹用策略梯度学检索排序)发展到驱动记忆管理的全局决策(Mem-α³⁷把更新建模为策略学习、Context-Folding/MemSearcher⁵⁸⁵⁹把工作记忆管理整体建模为 MDP)。
未来挑战 :在无人工先验的前提下端到端学习记忆格式、存储模式、演化规则,让记忆系统与推理能力协同进化。
5.4 Multimodal Memory
当前状态:现有系统以文本为主,视觉记忆研究正在增长,出现了 EgoLLaVA⁶⁰(处理第一人称视频)、MA-LMM⁶¹(双银行视觉记忆)、KARMA⁶²(多模态长短期混合记忆)这类专用系统;音频等模态仍在早期。
未来挑战 :跨模态语义对齐 (不同模态表示要能在统一语义空间互查)和多模态长程一致性(对象状态、空间布局在长视频里的持续追踪)是核心难点。目前还没有系统做到真正的全模态统一。
5.5 Shared Memory in Multi-Agent Systems
当前状态:从早期孤立本地记忆+消息传递,发展到集中式共享结构(MetaGPT 的共享消息池²²、G-Memory 的三层共享图⁹)。共享记忆已经是多 Agent 协作中减少冗余、防矛盾、实现集体智能的关键。
未来挑战 :角色感知的共享记忆------读写权限按角色、专业、信任级别动态约束;学习驱动的同步与冲突消解策略;开放多模态环境下的时序和语义完整性维护。
5.6 Memory for World Model
当前状态:世界模型需要对物理世界做高保真持续建模,记忆是其核心基础设施。当前沿三条路径演进:SSM 类(Mamba²)把历史压成固定大小递归状态;显式记忆银行(WorldMem⁶³)维护外部历史帧库支持精确回溯;稀疏记忆与检索(Ctrl-World⁶⁴)通过注入采样帧锚定生成连贯性。
未来挑战 :从数据缓存 (被动存历史帧)向状态模拟(主动维护可查询的世界状态)迁移,实现 System 1/System 2 双系统架构和主动记忆管理。
5.7 Trustworthy Memory
当前状态:Agent Memory 长期持久化用户的敏感数据,带来超出传统 RAG 安全边界的信任问题。近期工作揭示记忆模块可能通过间接 Prompt 注入泄露隐私,也需要支持显式访问控制、可验证遗忘、审计追踪。
三个核心维度:
- 隐私保护:差分隐私、联邦访问控制、用户主导的留存策略;
- 可解释性:可追溯的记忆访问路径、面向用户的诊断工具;
- 幻觉鲁棒性:不确定性感知检索、多 Agent 交叉验证、基于机制可解释性的幻觉溯源。
5.8 Human-Cognitive Connections
当前状态 :现有架构在结构上已经很接近人类认知模型------Atkinson-Shiffrin 的多存储模型对应 Working/Long-term 的分离;Tulving 的 Episodic/Semantic/Procedural 记忆对应事实/经验的划分。但有一个根本差距:人类记忆是建构性的,大脑回忆时会基于当前认知状态主动重构过去;现有 Agent 几乎都只做基于相似度的检索式访问。
未来方向 :引入离线整合机制 (类比睡眠中的记忆巩固:非交互阶段自主蒸馏通用模式、主动遗忘、重组结构);发展生成式记忆重构(按需合成潜在记忆 token),从根本上缩小 Agent 与人脑记忆动态之间的差距。
六、一个具体场景:AIOps Agent 的记忆系统怎么搭
把前面 Form / Functions / Dynamics 三条线落到一个具体场景里,可以更清楚地看出各个子方向是怎么组合起来的。以 AIOps 为例------Agent 需要在排查存储类故障时利用历史事件 、排查过程 、产品文档三类素材------一个合理的记忆系统大致可以这样设计:
Form(存在哪里)
- 原始工单、告警、复盘笔记:Flat (1D) Token-level,按时间追加,成本最低;
- 产品故障传播链、组件调用关系:Planar (2D) Graph,把"慢 IO → 网络拥塞 → 客户端超时"这种多跳依赖显式建边;
- 产品文档 / SOP / 指标词典:Hierarchical (3D),按"产品线 → 模块 → 指标/接口"分层,支持从主题下钻到细节。
Functions(记什么)
- Factual Memory:产品架构图、指标语义、配置项含义、集群拓扑(对应 Environment Factual Memory¹);
- Experiential Memory :
- Case-based --- 历史排查轨迹(每条告警 → 动作序列 → 根因);
- Strategy-based --- 从多条 Case 归纳出的排查模板("慢 IO 类工单的标准 7 步诊断");
- Skill-based --- 诊断脚本和健康检查函数,封装为可调用工具;
- Working Memory:单次排查会话内的已验证假设、已排除原因、当前怀疑链,任务结束后再决定是否写回长期记忆。
Dynamics(怎么运作)
- Formation:原始工单用 Semantic Summarization 做初步压缩,排查轨迹用 Knowledge Distillation 提炼根因与动作模式,架构/指标走 Structured Construction 建图;
- Evolution:相似 Case 触发 Consolidation;SOP 版本变动触发 Updating;低命中率或过时案例软遗忘(权重衰减而非硬删);
- Retrieval:四步走------Timing 由 Agent 显式通过 MCP 工具调用;Query 由 Planner 将"集群 X 慢查询"拆成"X 历史故障 / 慢查询通用根因 / X 近期变更"三条子查询;Strategy 采用"BM25 匹配错误码 + 向量召回相似故障 + 图上从告警节点做多跳扩散"的混合检索;Post-Retrieval 按"时间新鲜度 × 产品线匹配度 × 历史采纳率"重排并聚合。
未来可能的演进方向
- 经验进一步内化 :把高频、稳定的排查套路从 Strategy 升级到 Parametric Internalization,蒸馏进一个领域小模型,做到零检索延迟;
- 多模态扩展 :把火焰图、监控截图、调用链可视化以 Latent Representation 形式入库,解决纯文本无法表达的视觉特征;
- RL 驱动的记忆管理:参考 MemSearcher / Memory-R1⁵⁹⁵⁷ 的思路,用"MTTR 改善""根因定位成功率"等下游奖励信号,训练 Agent 学习何时检索 / 写入 / 整合 / 遗忘------把现在靠 Prompt 和规则驱动的部分逐步替换为可学习策略;
- 共享记忆:多 Agent SRE 协作时把 Experiential 做成跨 Agent 共享图(参考 G-Memory 思路⁹),把个体经验变成组织经验。
AIOps 是验证 Agent Memory 价值的比较理想的场景------三类功能都是刚需、数据自带结构、奖励信号明确(MTTR、根因准确率),适合作为把前面这套体系落到生产的第一块试验田。
结语
把整个五章串起来看,几个核心判断:
- 定义层面:Agent Memory 的核心区别标志是"形成-演化-检索"的闭环,以及"知识库随 Agent 自身行为改变"------这两条一旦抓住,大部分概念混淆都能迅速澄清;
- 实现层面:Form 决定能力上限(Token 透明但组合能力弱、Parametric 无检索延迟但难更新、Latent 高效但不可解释),Function 决定记忆的认知角色,Dynamics 决定系统长期是否能保持健康;
- 前沿层面:两个最有生命力的方向是"从检索到生成"和"用 RL 把记忆管理端到端自动化",它们把记忆系统从"工程件"推向"策略件",让记忆本身成为智能体策略空间的一部分。
回到一个更简单的问题:为什么要把"记忆"当作 Agent 的一等公民?因为在长程任务里,LLM 的瓶颈已经不再是一次推理的上限,而是跨时间的一致性与可积累性。一个不会记忆的智能体,本质上每次都是一个新的智能体;而真正值得称作 Agent 的系统,都应该能在和世界交互的过程中变得越来越像"它自己"。
参考文献
1 Yuyang Hu et al., Memory in the Age of AI Agents: A Survey --- Forms, Functions and Dynamics, arXiv:2512.13564v2, 2026. https://arxiv.org/abs/2512.13564
2 Albert Gu, Tri Dao, Mamba: Linear-Time Sequence Modeling with Selective State Spaces, arXiv:2312.00752, 2023.
3 Iz Beltagy et al., Longformer: The Long-Document Transformer, arXiv:2004.05150, 2020.
4 Akari Asai et al., Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection, ICLR 2024.
5 Noah Shinn et al., Reflexion: Language Agents with Verbal Reinforcement Learning, NeurIPS 2023.
6 Charles Packer et al., MemGPT: Towards LLMs as Operating Systems, arXiv:2310.08560, 2023.
7 Bernal Jiménez Gutiérrez et al., HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models, NeurIPS 2024.
8 Wujiang Xu et al., A-MEM: Agentic Memory for LLM Agents, arXiv:2502.12110, 2025.
9 G-Memory: Hierarchical Memory for Multi-Agent Systems, 2025 (见综述参考文献).
10 Mahdi Hu et al., HiAgent: Hierarchical Working Memory Management for Solving Long-Horizon Agent Tasks, 2024.
11 Kevin Meng et al., Locating and Editing Factual Associations in GPT (ROME), NeurIPS 2022.
12 Kevin Meng et al., Mass-Editing Memory in a Transformer (MEMIT), ICLR 2023.
13 WISE: Rethinking the Knowledge Memory for Lifelong Model Editing, NeurIPS 2024.
14 ELDER: Editing LLMs via Dynamic Experts Routing, 2024.
15 Alexis Chevalier et al., Adapting Language Models to Compress Contexts (AutoCompressor), EMNLP 2023.
16 CoMEM: Compressive Multimodal Memory for Long-Context Agents, 2025.
17 Yuhuai Wu et al., Memorizing Transformers, ICLR 2022.
18 Weizhi Wang et al., Augmenting Language Models with Long-Term Memory (LONGMEM), NeurIPS 2023.
19 Yuhong Li et al., SnapKV: LLM Knows What You are Looking for Before Generation, NeurIPS 2024.
20 Zefan Cai et al., PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling, 2024.
21 RMM: Reflection-based Memory Management for Long-Term Dialog Agents, 2024.
22 Sirui Hong et al., MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework, ICLR 2024.
23 Andrew Zhao et al., ExpeL: LLM Agents Are Experiential Learners, AAAI 2024.
24 Memento: Fine-tuning LLM Agents without Fine-tuning LLMs, 2024.
25 Zora Zhiruo Wang et al., Agent Workflow Memory, arXiv:2409.07429, 2024.
26 Ling Yang et al., Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models, NeurIPS 2024.
27 Guanzhi Wang et al., Voyager: An Open-Ended Embodied Agent with Large Language Models, TMLR 2024.
28 Yujia Qin et al., ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs, ICLR 2024.
29 Shishir G. Patil et al., Gorilla: Large Language Model Connected with Massive APIs, 2023.
30 Agent KB: Leveraging Cross-Domain Experience for Agentic Problem Solving, 2025.
31 Huiqiang Jiang et al., LLMLingua / LongLLMLingua: Compressing Prompts for Accelerated Inference of LLMs, EMNLP 2023 / ACL 2024.
32 Longtao Zheng et al., Synapse: Trajectory-as-Exemplar Prompting with Memory for Computer Control, ICLR 2024.
33 Hongli Yu et al., MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent, 2025.
34 Kuang-Huei Lee et al., A Human-Inspired Reading Agent with Gist Memory of Very Long Contexts (ReadAgent), 2024.
35 Mem1: Learning Memory Management with GRPO, 2025.
36 R2D2: Reflective Reasoning with Dual Direction Distillation, 2025.
37 Mem-α: Learning Memory Update via Reinforcement Learning, 2025.
38 Preston Rasmussen et al., Zep: A Temporal Knowledge Graph Architecture for Agent Memory, 2025.
39 Darren Edge et al., From Local to Global: A GraphRAG Approach to Query-Focused Summarization, 2024.
40 Yu Wang et al., MemoryLLM: Towards Self-Updatable Large Language Models, ICML 2024.
41 Encode-Store-Retrieve (ESR): Language-Guided Episodic Memory for Egocentric Video, 2024.
42 Timo Schick et al., Toolformer: Language Models Can Teach Themselves to Use Tools, NeurIPS 2023.
43 Lei Liu et al., Think-in-Memory (TiM): Recalling and Post-thinking Enable LLMs with Long-Term Memory, 2023.
44 Matrix: Iterative Trajectory Refinement and Global Memory Consolidation, 2025.
45 MAICC: Memory-Aware Intelligent Context Curation, 2025.
46 Elias Lumer et al., MemTool: Memory-Aware Tool Retrieval for LLM Agents, 2025.
47 ComoRAG: Cognitive-Mode Retrieval-Augmented Generation, 2025.
48 PRIME: Progressive Retrieval with Intrinsic Memory Evaluation, 2025.
49 H-MEM: Hierarchical Memory Routing from Domain to Episode, 2025.
50 MA-RAG: Multi-Agent Retrieval-Augmented Generation with Planner and Extractor Agents, 2025.
51 Luyu Gao et al., Precise Zero-Shot Dense Retrieval without Relevance Labels (HyDE), ACL 2023.
52 Nils Reimers, Iryna Gurevych, Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, EMNLP 2019.
53 Alec Radford et al., Learning Transferable Visual Models From Natural Language Supervision (CLIP), ICML 2021.
54 Learn-to-Memorize: RL-based Memory Retrieval Reranking, 2025.
55 MemGen: Direct Generation of Latent Memory Tokens from Reasoning State, 2025.
56 CAM: Agent-Callable Memory Operations, 2025.
57 Memory-R1: Reinforcement Learning for Agent Memory Operations, 2025.
58 Context-Folding: MDP-based Working Memory Management, 2025.
59 MemSearcher: MDP-based Memory Retrieval Agent, 2025.
60 EgoLLaVA: Egocentric Video Understanding with LLaVA, 2024.
61 Bo He et al., MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding, CVPR 2024.
62 KARMA: Hybrid Long/Short-Term Multimodal Memory for Embodied Agents, 2024.
63 WorldMem: Explicit Frame Memory Bank for World Models, 2025.
64 Ctrl-World: Sparse Memory Anchoring for Controllable World Models, 2025.
65 Alireza Rezazadeh et al., MemTree: A Dynamic, Schema-Inferring Memory Structure for Dialogue Agents, 2025.
66 HAT: Hierarchical Aggregate Tree for Long-Context QA, 2024.
67 Ali Modarressi et al., Ret-LLM: Towards a General Read-Write Memory for Large Language Models, arXiv:2305.14322, 2023.