NTIRE 2026 Challenge on Nighttime Image Dehazing------冠军方案解读
论文:HistoFusionNet: Histogram-Guided Fusion and Frequency-Adaptive Refinement for Nighttime Image Dehazing
一. 简介
NTIRE 的全称为New Trends in Image Restoration and Enhancement Challenges,即"图像复原和复原挑战中的新趋势",是CVPR(IEEE Conference on Computer Vision and Pattern Recognition)举办的极具影响力的计算机视觉底层任务比赛,主要涉及的研究方向有:图像超分辨率、图像去噪、去模糊、去摩尔纹、重建和去雾等。

其中在2026年,CVPR开展的NTIRE相关挑战有:
- 夜间图像去雾(NightTime Image Dehazing);
- 图像阴影去除(Image Shadow Removal);
- 3D内容超分辨率重建(3D Content Super-Resolution);
- 光场图像超分(Light Field Image Super-Resolution);
- 低光图像增强(Low Light Image Enhancement);
- 图像去噪(Image Denoising);
- 4倍图像超分辨率重建(Image Super-Resolution (x4));
- 遥感红外图像超分辨率重建(Remote Sensing Infrared Image Super-Resolution);
- 高效超分辨率重建(Efficient Super-Resolution);
- 3D内容复原和重建(3D Restoration and Reconstruction);
- 高效真实世界去模糊(Efficient Real-World Deblurring )。
同时,以上的这些挑战也蕴含着当前的一些研究难点及挑战,需要研究学者们集思广益,提出针对提升任务性能的想法,为共同解决近年来的难题贡献出一份力量。
本篇文章着重于NTIRE 2026 夜间图像去雾(Nighttime Image Dehazing) 挑战赛冠军队伍McMaster University的HistoFusionNet方案的解读,总结报告中能够提升任务的tricks,以期给相关的科研任务一些启发。
二、夜间图像去雾比赛情况
共有 218 名参与者注册参加比赛,22 个团队成绩有效。排名前五的团队如下:

综合各个指标(PSNR/SSIM/LPIPS等)的判定标准下,几个有特色的队伍成绩如下:
| 排名 | 队伍 | 综合得分依据 | 特点 |
|---|---|---|---|
| 1 | HistoDehaze | PSNR 第 1 + SSIM 第 2 + LPIPS 第 1 | 综合冠军,PSNR遥遥领先 |
| 2 | XJRes | PSNR 第 2 + SSIM 第 1 + LPIPS 第 4 | 综合第二 |
| 3 | KETI | PSNR 第 3 + SSIM 第 3 + LPIPS 第 3 | 综合第三 |
亮点:HistoDehaze的PSNR为27.88 ,XJRes的PSNR为27.44 ,KETI的PSNR为27.30 。笔者从HistoDehaze提出的HistoFusionNet网络结构可以看出,HistoFusionNet网络是由NTIRE 2024 Challenge on Dense and Non-Homogeneous Dehazing赛道的亚军方案 ------DehazeDCT改进而来,其中DehazeDCT在本次赛道的PSNR达到27.47 ,这也就意味着HistoDehaze队伍采用的baseline已经能够超过XJRes队伍(PSNR为27.44),直接在PSNR指标上排第一名。这说明选择一个合适的baseline模型非常重要(划重点!),甚至起跑线就是其他队伍的终点线。
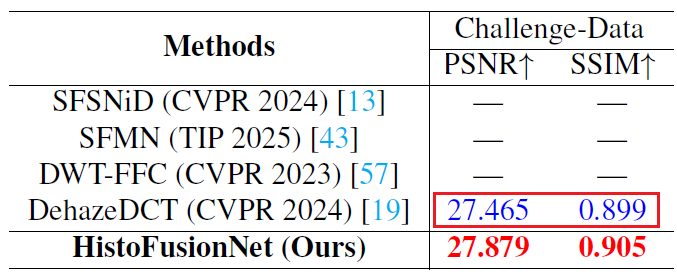
笔者进一步浏览了NTIRE 2024 Challenge on Dense and Non-Homogeneous Dehazing的比赛报告,发现了非常巧合的地方,原来HistoDehaze队伍就是NTIRE 2024的亚军队伍(Dehazing R),这就难怪了,自家人不说两家话哈哈,有往年积累沉淀的比赛方案,直接拿来用就是。不断改进DehazeDCT模型,最终演化为HistoFusionNet模型,最终碾压其他队伍,salute!
三、夜间图像去雾的挑战性
夜间图像去雾(Nighttime Image Dehazing)一直是图像复原领域中非常有挑战性的一类任务。相比白天场景,夜间图像往往不仅存在"雾",还会同时伴随:
- 雾霾散射(haze scattering)
- 雾会导致图像发灰、低对比度、远处区域模糊,这是去雾任务最基础的退化来源。
- 强光源带来的辉光(glow)
- 路灯、车灯、霓虹灯、广告牌等强光源在雾天条件下会形成明显的辉光扩散(glow),造成局部发亮、溢出,甚至淹没图像的结构信息。
- 非均匀亮度(non-uniform illumination)
- 夜间场景亮度差异巨大,有些区域非常亮,有些区域极暗,这使得网络很难学习统一的恢复映射。
- 颜色偏移(color distortion)
- 人工光源往往带有明显色调,例如偏黄、偏蓝或偏红,导致图像局部颜色失真更严重。
- 传感器噪声(sensor noise)
- 夜间成像通常伴随较高 ISO 和较低信噪比,因此噪声会更加明显,且容易在增强过程中被放大。
这些退化通常相互耦合,导致图像出现可见度下降、局部过曝、暗部细节丢失、色彩失真等一系列问题。可以认为,夜间去雾实际上更像是一个雾 + 光照 + 色偏 + 噪声的联合复原问题,而不是简单的移除雾气。因此,很多在白天去雾任务中表现不错的方法,放到夜间场景后往往效果有限。
三、冠军方案整体思路
针对上述难题,我们来解读一篇来自 NTIRE 2026 Nighttime Image Dehazing Challenge 的冠军方案------HistoFusionNet 。这篇论文提出了一个将 直方图引导特征融合 与 频率自适应细化 结合起来的夜间去雾框架,并最终在 22 支参赛队伍中获得第 1 名。HistoFusionNet的网络结构如下:
- 基于DCNv4的主分支:作为主干去雾网络,负责进行多尺度特征提取和恢复;
- 基于频域感知的辅助分支:作为辅助去雾网络,负责利用频域信息进行特征提取和恢复;
- Histogram Transformer Block:在 U-Net 的 bottleneck 位置引入直方图注意力模块,负责建模"动态范围相似区域"之间的长距离依赖;
- 频域自适应细化模块:在主干去雾和辅助去雾分支的基础上做进一步细化,增强颜色、边缘和局部细节。
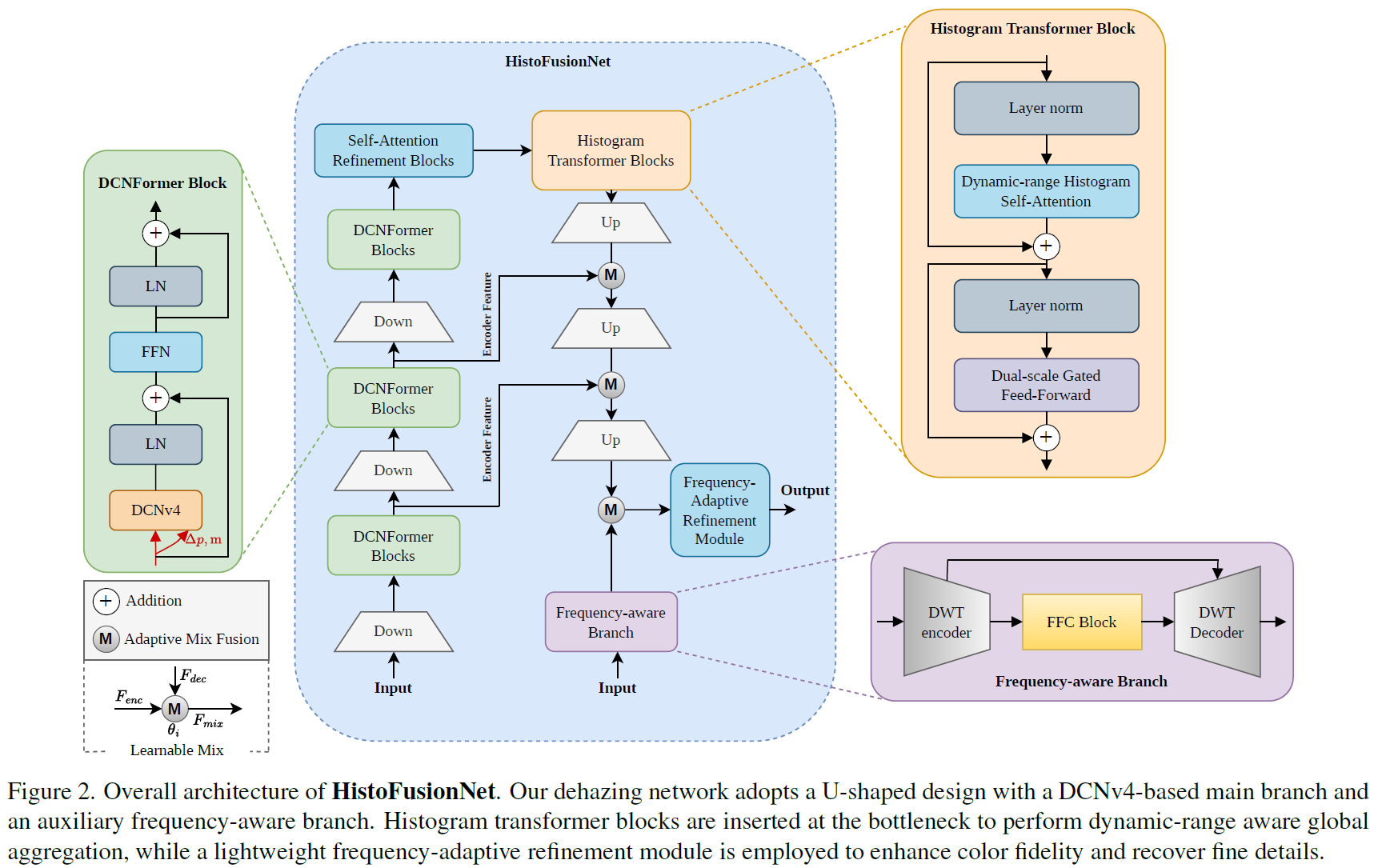
1. 基于DCNv4的主分支
夜间图像中的退化具有很强的空间不均匀性,例如:
- 路灯附近 glow 很强
- 阴影区域雾更浓且噪声更多
- 远处区域对比度更低
- 强光处结构容易被淹没
普通卷积使用固定采样位置,难以灵活适应这类复杂场景。相比之下,可变形卷积(Deformable Convolution) 可以根据输入内容动态调整采样位置,更适合这类非均匀退化问题。
论文中采用的是 DCNv4,相比 DCNv3 具有以下优点:
- 去掉了 modulation softmax 归一化
- 提高了内存访问效率
- 收敛更快
- 动态建模能力更强
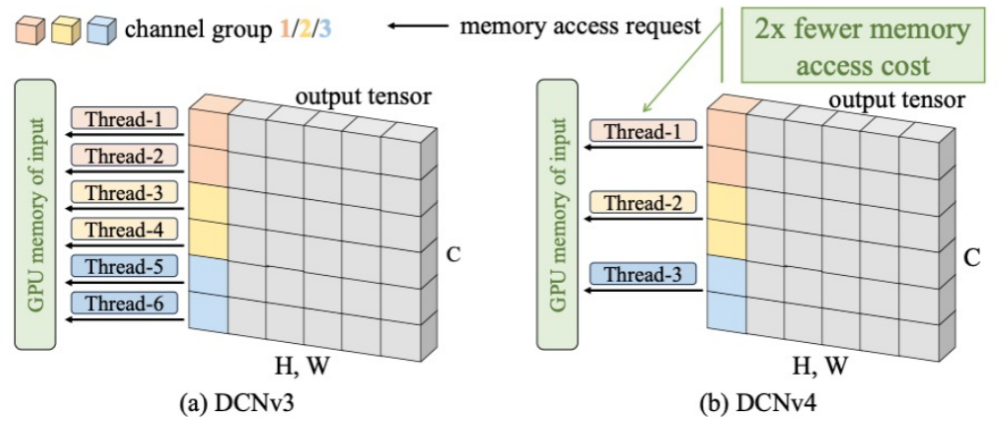
因此DCNv4非常适合做夜间图像去雾的主干网络,DCNv4 的核心操作deformable aggregation的表达式如下:
y ( p 0 ) = ∑ g = 1 G ∑ k = 1 K w g m g k x g ( p 0 + p k + Δ p g k ) y(p_0)=\sum_{g=1}^{G}\sum_{k=1}^{K} w_g m_{gk} x_g(p_0+p_k+\Delta p_{gk}) y(p0)=g=1∑Gk=1∑Kwgmgkxg(p0+pk+Δpgk)
其中:
- p 0 p_0 p0:当前参考位置;
- G G G:分组数;
- K K K:采样点数;
- w g w_g wg:第 g g g 组的投影权重;
- m g k m_{gk} mgk:调制系数;
- p k p_k pk:预定义偏移;
- Δ p g k \Delta p_{gk} Δpgk:学习到的偏移量。
相对于普通卷积,可变形卷积的优点如下:
- 网络不会只在固定卷积核位置采样;
- 而是根据图像内容,自适应地调整采样位置;
- 从而更灵活地建模局部复杂退化。
2. Histogram Transformer Blocks
Histogram Transformer Blocks是方案特色的设计之一,标准 self-attention 往往要么对所有 token 进行全局建模,要么在固定局部窗口内进行建模。但夜间图像中,相似退化区域往往并不相邻,也就是说:真正应该重点交互的信息,不一定来自空间邻居,而可能来自**"亮度/动态范围相似"**的远距离区域。
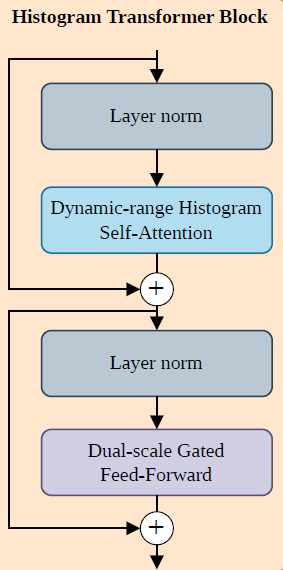
假设 bottleneck 输入的特征为:
F ∈ R h × w × c F \in \mathbb{R}^{h \times w \times c} F∈Rh×w×c
首先为每空间位置计算一个强度描述子:
s ( p ) = 1 c ∑ j = 1 c F p , j s(p)=\frac{1}{c}\sum_{j=1}^{c} F_{p,j} s(p)=c1j=1∑cFp,j
其中:
- p p p 表示空间位置
- j j j 表示通道维度
也就是说,作者用通道均值作为该位置的"强度/动态范围"表示。
随后按照 s ( p ) s(p) s(p) 的大小进行:
- 排序
- 分桶
- 在每个桶内部做 self-attention
- 再恢复原来的空间顺序
排序与分桶过程可写为:
{ F ( 1 ) , F ( 2 ) , ... , F ( B ) } = P ( F ) \{F^{(1)},F^{(2)},\dots,F^{(B)}\}=P(F) {F(1),F(2),...,F(B)}=P(F)
其中:
- P ( ⋅ ) P(\cdot) P(⋅) 表示排序和分桶操作
- B B B 表示 histogram bins 的数量
对于第 b b b 个 bin,self-attention 写成:
A t t n ( Q ( b ) , K ( b ) , V ( b ) ) = S o f t m a x ( Q ( b ) ( K ( b ) ) ⊤ d ) V ( b ) Attn(Q^{(b)},K^{(b)},V^{(b)})= Softmax (\frac{Q^{(b)}(K^{(b)})^\top}{\sqrt d})V^{(b)} Attn(Q(b),K(b),V(b))=Softmax(d Q(b)(K(b))⊤)V(b)
最后,通过逆置换恢复原空间顺序:
F ^ = P − 1 ( C o n c a t ( F ^ ( 1 ) , F ^ ( B ) ) ) \hat F = P^{-1}\left(Concat(\hat F^{(1)},\,\hat F^{(B)})\right) F^=P−1(Concat(F^(1),F^(B)))
为什么这种设计适合夜间去雾?这种设计的优势在于:
(1)按"退化属性"而不是"空间邻接"组织信息。让具有相似动态范围退化的区域优先交互,更符合夜间图像的真实退化规律。
(2)更适合处理非均匀亮度。夜间图像亮度分布极不均匀,空间上相邻未必退化相似,而按强度分桶则更有针对性。
(3)放在 bottleneck 上处理更高效。在最低分辨率层进行排序和注意力计算,开销更低,同时该层拥有较丰富的多尺度语义信息,适合做长程依赖建模。
3. 频域自适应细化模块
在主去雾网络输出之后,论文进一步加入了一个轻量级细化模块,用于提升复原图像的颜色一致性、局部结构、纹理细节、视觉自然度。虽然主去雾网络已经可以去掉大部分 haze 和 glow,但输出结果中仍然可能存在:
- 局部颜色偏差
- 纹理恢复不完整
- 边缘不够锐利
- 某些区域增强不一致
因此,作者增加一个轻量模块,专门用于"残差细化"。令第 i i i 个尺度上的编码器特征为 F e n c i F_{enc}^i Fenci,和当前解码器特征为 F d e c i F_{dec}^i Fdeci,通过一个可学习门控进行融合:
F m i x i = α i F e n c i + ( 1 − α i ) F d e c i F_{mix}^i=\alpha_i F_{enc}^i+(1-\alpha_i)F_{dec}^i Fmixi=αiFenci+(1−αi)Fdeci
其中:
α i = σ ( θ i ) \alpha_i=\sigma(\theta_i) αi=σ(θi)
其中 θ i \theta_i θi 是可学习标量, σ ( ⋅ ) \sigma(\cdot) σ(⋅) 是 sigmoid 函数。
这种设计的所表达的含义如下:
- 编码器特征偏向结构与底层信息;
- 解码器特征偏向恢复后的高级表示;
- 两者的融合比例由网络自动学习。
进一步地,在傅里叶域中,将特征分解为低频和高频两部分:
F l o w = F − 1 ( M ⊙ F ( F d ) ) F_{low}=\mathcal{F}^{-1}(M \odot \mathcal{F}(F_d)) Flow=F−1(M⊙F(Fd))
F h i g h = F − 1 ( ( 1 − M ) ⊙ F ( F d ) ) F_{high}=\mathcal{F}^{-1}((1-M)\odot \mathcal{F}(F_d)) Fhigh=F−1((1−M)⊙F(Fd))
其中:
- F \mathcal{F} F:傅里叶变换
- F − 1 \mathcal{F}^{-1} F−1:逆傅里叶变换
- M M M:自适应频率掩码
- ⊙ \odot ⊙:逐元素乘法
- F d F_d Fd:主去雾网络输出特征
然后,将这些频率信息与混合特征进一步融合:
F ^ = G ( F m i x , F l o w , F h i g h ) \hat F = G(F_{mix},F_{low},F_{high}) F^=G(Fmix,Flow,Fhigh)
最终输出图像可写为:
I o u t = ϕ ( θ ( I h a z y ) ) I_{out}=\phi(\theta(I_{hazy})) Iout=ϕ(θ(Ihazy))
其中, θ ( ⋅ ) \theta(\cdot) θ(⋅)为去雾网络, ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)为频率自适应细化模块。
在频域中,低频部分主要对应全局亮度、光照趋势和颜色分布;高频部分主要对应边缘、纹理和局部结构 。夜间图像中,雾和辉光往往更影响低频,而细节模糊、锐度不足则体现在高频。将两者分开处理,再自适应融合,有助于更自然地恢复颜色、更清晰地恢复结构、减少锐化带来的噪声和伪影。
4. 训练策略
作者采用了两阶段训练,分为Stage 1和Stage 2,而不是一次性联合训练:
Stage 1:训练去雾主网络
首先训练主干去雾网络,包括:
- DCNv4 U-Net;
- Histogram Transformer;
- frequency-aware branch;
- 使用 PyTorch 实现,在NVIDIA H100 80GB上训练,随机裁剪为 384 × 384的图块,使用90° / 180° / 270°随机旋转增强;
- 训练5000个epoch,初始学习率为 1 × 10 − 4 1\times10^{-4} 1×10−4,在第 2000, 3000 , 4000 个epochs时学习率衰减为原来的 0.5 倍。
Stage 2:训练 refinement 模块
在主网络已经学会基本去雾后,再加入 refinement 模块做残差细化。这种两阶段训练的好处是:主干先学习稳定的粗恢复能力;refinement 专注于最后的细节和颜色修补;整体训练更稳定。
-
随机裁剪为 384 × 384的图块,使用90° / 180° / 270°随机旋转增强;
-
学习率固定为 1 × 10 − 5 1\times10^{-5} 1×10−5。
损失函数
Stage 1和Stage 2的训练阶段,采用了四个损失函数的组合形式进行训练:
L d e h a z e = L 1 + α L S S I M + β L P e r c e p + γ L a d v L_{dehaze}=L_1+\alpha L_{SSIM}+\beta L_{Percep}+\gamma L_{adv} Ldehaze=L1+αLSSIM+βLPercep+γLadv
其中 L 1 L_1 L1为像素级重建损失, L S S I M L_{SSIM} LSSIM为结构相似性损失, L P e r c e p L_{Percep} LPercep为感知损失, L a d v L_{adv} Ladv为对抗损失。损失权重系数: α = 0.2 \alpha = 0.2 α=0.2, β = 0.01 \beta = 0.01 β=0.01, γ = 0.0005 \gamma = 0.0005 γ=0.0005。
四、去雾效果
在夜间强光、雾气和暗部共存的复杂场景中,HistoFusionNet在颜色、结构和自然度上表现不错。

五、总结
HistoFusionNet 是一篇非常值得学习的夜间图像去雾工作,它的核心贡献在于:
- 从问题本质出发,抓住了夜间退化与动态范围、频率分布的关系;
- 利用 Histogram Transformer 建模动态范围相似区域之间的长程依赖;
- 利用 Frequency-Adaptive Refinement 对颜色和细节进行进一步修复;
- 结合 DCNv4 backbone,形成了一个兼顾空间、全局与频率的统一框架;
最终,这个方法不仅在多个真实雾图数据集上取得了优异结果,也在 NTIRE 2026 Nighttime Image Dehazing Challenge 中获得了冠军。
最后感谢小伙伴们的学习噢~