一、我第一次做多平台采集,输得很彻底
说实话,我最开始做社媒数据采集时,并没有觉得 TikTok 和 LinkedIn 会这么难。
我先写了一个简单脚本抓 TikTok 账号内容,前几个请求还正常,结果没多久就开始遇到频率限制、字段缺失,后面甚至连返回结构都不稳定。切到 LinkedIn 更夸张,登录墙、行为检测、页面动态加载轮番上阵。我原本以为"再补几个请求头、加个代理池就行",最后发现自己其实是在维护两套完全不同的反爬战场。
后来我换了思路:不再自己硬扛采集基础设施,而是把 Bright Data MCP 直接接进 Dify 工作流。这一改,最大的变化不是"采得更快",而是终于不用再把时间浪费在解验证码、调指纹、修失效脚本上了。如果你也想自己试,先从这里注册 Bright Data:你的 Bright Data 专属链接。
二、为什么多平台社媒采集这么难
做社媒分析最痛苦的一点,不是"不会抓",而是 每个平台都要单独维护一套生存策略。TikTok 和 LinkedIn 看起来都是内容平台,但它们的限制逻辑完全不同。
| 平台 | 主要反爬机制 | DIY 失败率 |
|---|---|---|
| TikTok | 签名加密、设备指纹、速率限制 | 极高 |
| 登录墙、行为检测、动态渲染 | 极高 |
TikTok 的难点在于风控严格、访问环境要求高;LinkedIn 的问题则更集中在登录态、会话管理和公开页面访问限制。平台越多,脚本越容易失效,排障时间也越长。更麻烦的是,各平台返回的数据结构并不统一:有的平台字段很散,有的平台内容层级很深,还有些平台公开指标和页面展示之间并不完全一致。很多时候,真正拖慢项目的并不是"抓不到",而是"抓到了也很难直接用"。
这也是我后来放弃"每个平台单独维护一套脚本"的原因。
与其不断补洞,不如把采集层抽象出去,让工作流只关心输入、输出和分析逻辑。
三、架构:Bright Data MCP + Dify 为什么适合这个场景
先用一句话解释 MCP:
MCP 可以理解成 AI 系统连接外部工具的标准接口。
在这个方案里,Dify 负责工作流编排,Bright Data MCP 则把底层的数据采集能力封装成可调用工具。这样做的意义在于:你不需要在工作流里自己处理代理、浏览器环境、解封、重试和平台差异,只需要定义"我要什么数据"和"拿到数据后要做什么"。
Bright Data MCP 提供:
- 60+ 现成数据采集工具
- 自动绕过反爬与验证码
- 云端与自托管部署
- AI Agent 原生集成
这使得 AI 工作流可以直接访问实时 Web 数据,而无需维护采集基础设施。
整个流程可以概括成:
用户输入
账号名 / 关键词 / 话题标签
Dify Workflow
Bright Data MCP Server
TikTok / LinkedIn
Social Media Scraper
结构化 JSON
LLM 提取
互动率 / 粉丝数 / 内容摘要
数据库 / Slack / 报表系统
为什么这个组合有效:
- Dify 提供可视化 Workflow 编排,不需要写任何爬虫逻辑,拖拽节点即可完成数据流配置
- Bright Data MCP 在后台处理所有反爬问题:代理切换、IP 解封、指纹模拟------全部在基础设施层透明解决
- 云端 MCP Server 省去本地环境配置,Dify 直连 Bright Data,零运维负担
- 三者结合 = AI 驱动的社媒数据采集流水线,从输入账号名到拿到结构化数据,全程自动
四、前置准备
- Bright Data 账号 --- 免费注册,用这个连结注册再输入折扣码可以有20美金的试用,折扣码是leo20
- Dify 账号 --- 云端版(dify.ai)或本地 Docker 部署均可
- Bright Data MCP Server 地址 + API Token --- 在控制台 MCP 配置页一键复制,下文详细说明
- 基础 Dify Workflow 操作经验 --- 本文会手把手带你完成所有步骤
Bright Data 控制台,在如下位置填写折扣码,获取20美元试用。
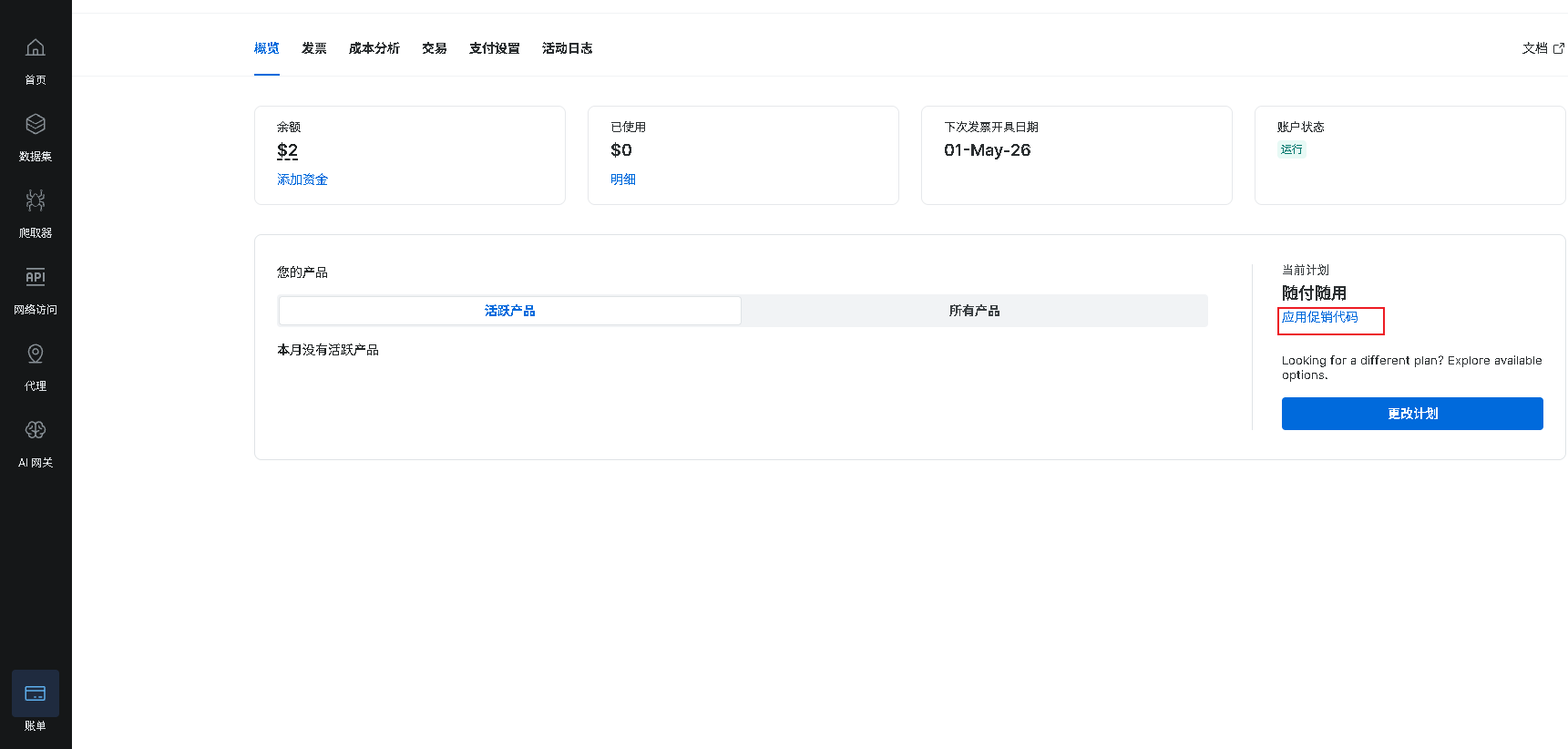
五、实战教程:用 Dify 采集 TikTok + LinkedIn 社媒数据
这一部分我按照自己实际搭建的过程来写,尽量让读者能跟着一步步复现。
Step 1:在 Bright Data 控制台获取 MCP Server 信息
这一步花了我不到 5 分钟。
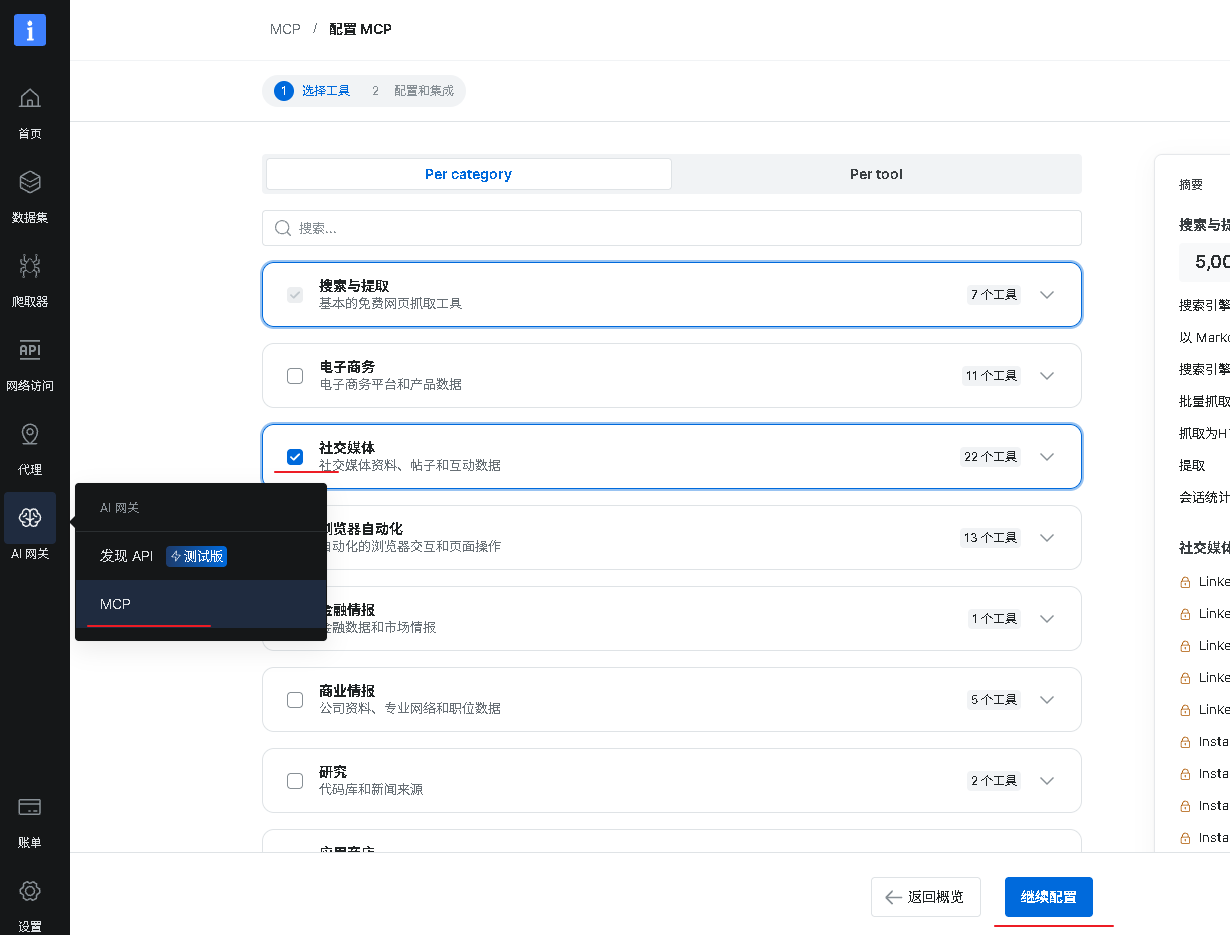
登录 Bright Data 控制台,在左侧菜单找到 MCP 入口,进入 MCP 配置页面,现在社交媒体,点击继续配置。
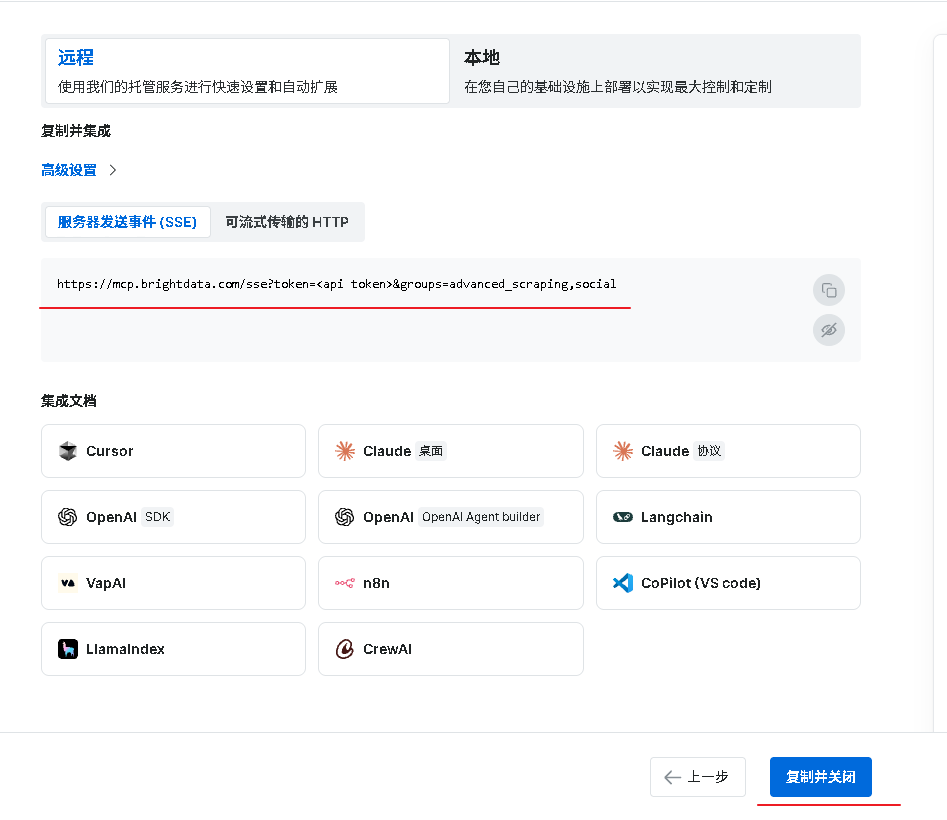
页面会显示你的专属云端 MCP Server 信息,直接复制即可:
复制好后,进入下一步。
Step 2:在 Dify 中添加 Bright Data MCP 工具
打开 Dify,进入顶部菜单 工具 →MCP→ 添加MCP服务。
| 字段 | 说明 | 填写示例 |
|---|---|---|
| 服务端点 URL | 从 Bright Data 控制台 MCP 页面复制的云端地址 | https://mcp.brightdata.com/sse?token=<api token>&groups=advanced_scraping,social |
| 名称和图标 | 在 Dify 工作空间内显示的服务名称,自定义即可 | Bright Data MCP |
| 服务器标识符 | 工作空间内的唯一 ID,仅支持小写字母、数字、下划线和连字符,最多 24 个字符 | brightdata-mcp |
三个字段填写完成后,点击 添加并授权 ,Dify 会自动向 MCP Server 发起校验请求。校验通过后,会自动加载 Bright Data MCP 提供的全部工具列表。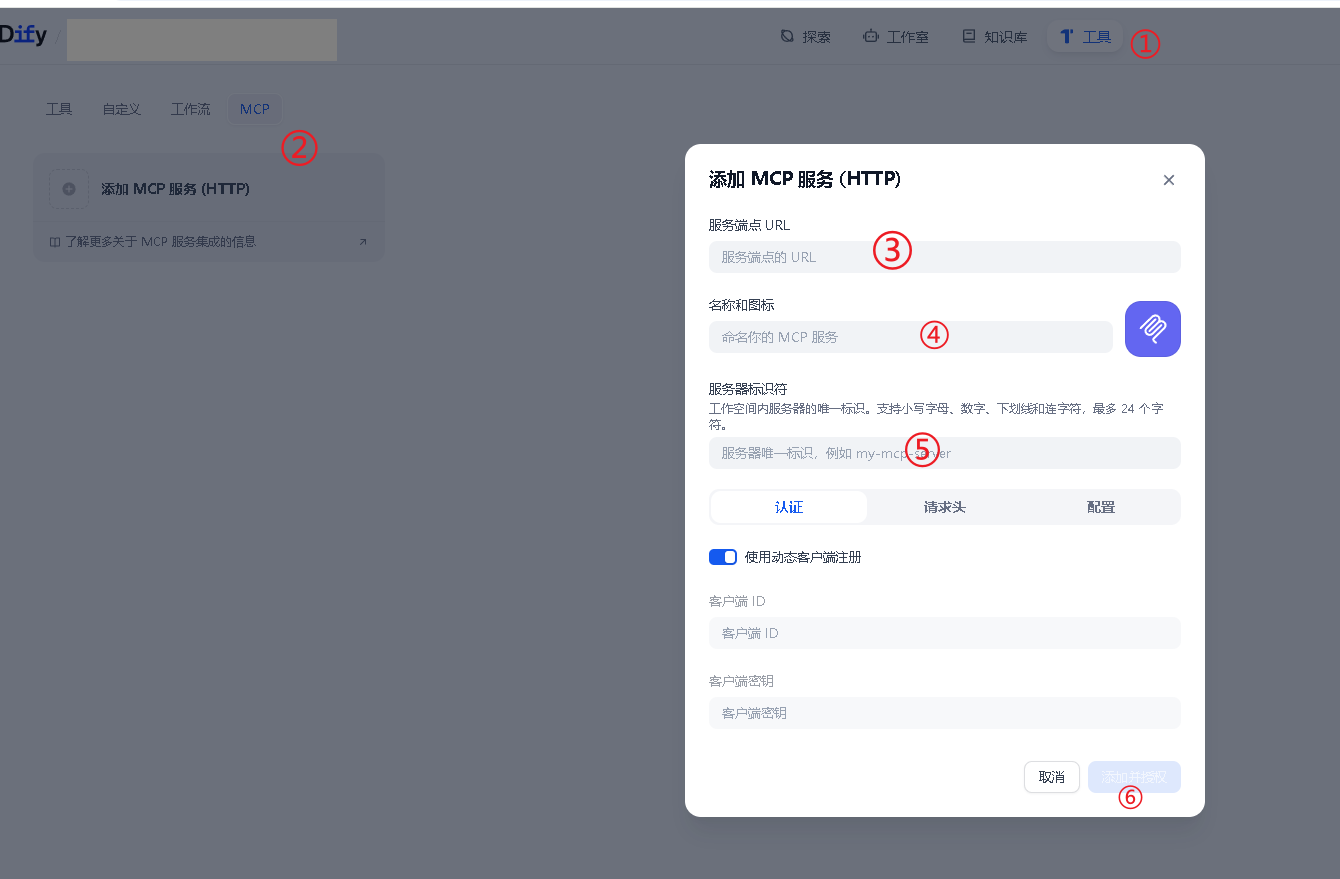
Step 3:创建 TikTok + LinkedIn 社媒采集 Workflow
快捷方式 :如果不想手动搭建,可以直接下载
workflow_social_scraper.yml导入 Dify(详见第六节),跳过本步骤。以下是手动搭建的完整 UI 操作说明。
整个 Workflow 由 5 个节点 组成。连线逻辑:开始节点同时连向 TikTok 和 LinkedIn 两个采集节点(并行执行),两者完成后汇入 LLM 节点,最后接结束节点。Dify 支持多入边,会自动等待所有上游节点完成后再继续。
使用的 Bright Data MCP 工具:
| 节点 | 工具名称 | 适用 URL |
|---|---|---|
| TikTok 采集 | web_data_tiktok_profiles |
tiktok.com/@username |
| LinkedIn 采集 | web_data_linkedin_company_profile |
linkedin.com/company/name/ |
节点 1 --- 开始节点
Dify Workflow 新建工作流后默认自带开始节点。点击该节点,在右侧配置面板中点击「+ 添加输入字段」,依次添加以下两个变量:
| 变量名 | 字段类型 | 显示名称 | 填写示例 |
|---|---|---|---|
tiktok_url |
文本 | TikTok 账号主页 URL | https://www.tiktok.com/@tiktok |
linkedin_url |
文本 | LinkedIn 公司主页 URL | https://www.linkedin.com/company/microsoft/ |

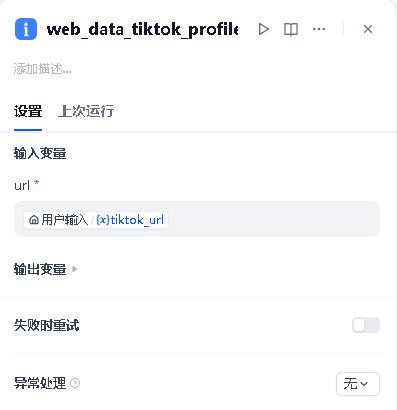
节点 2 --- TikTok 采集(工具节点)
右键 → 添加节点 → 选择「工具」。在右侧配置面板中:
- 选择工具 :找到
brightdata-mcp,动作选web_data_tiktok_profiles - 配置参数:
| 参数名 | 赋值方式 | 填写内容 |
|---|---|---|
url |
引用变量 | 点击「/」→ 开始节点 → tiktok_url |
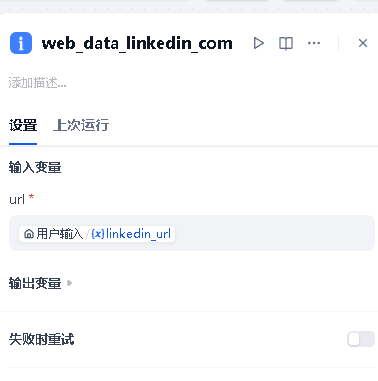
节点 3 --- LinkedIn 采集(工具节点)
右键 → 添加节点 → 选择「工具」。在右侧配置面板中:
- 选择工具 :找到
brightdata-mcp,动作选web_data_linkedin_company_profile - 配置参数:
| 参数名 | 赋值方式 | 填写内容 |
|---|---|---|
url |
引用变量 | 点击「/」→ 开始节点 → linkedin_url |
将开始节点连线同样拖至本节点(节点 2 和节点 3 并行,同时从开始节点出发)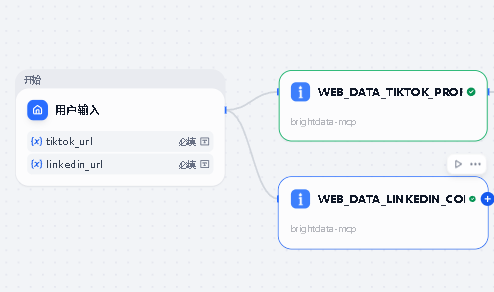
节点 4 --- LLM 解析节点
右键 → 添加节点 → 选择「LLM」。
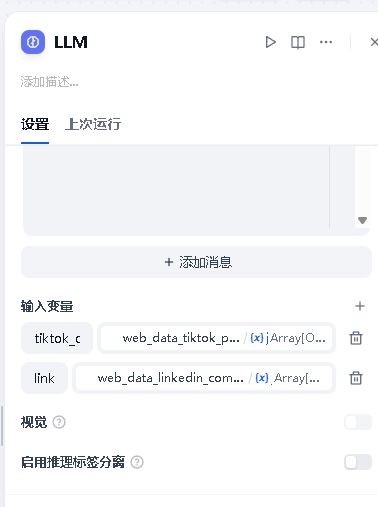
重要:先连线,再配置 prompt。 请先将节点 2、节点 3 的输出端口都连到本节点,输入变量区域才会显示可选的上游输出。
-
选择模型:选择你已配置的 LLM(如 GPT-4o、Claude Sonnet 等)
-
开启 Jinja2 开关 :在右侧配置面板找到「Jinja2」切换开关,打开 。开启后 User Prompt 支持 Jinja2 模板语法,并在输入框上方出现「输入变量」区域。
-
添加输入变量 :在「输入变量」区域点击「+ 添加变量」,依次添加以下两个变量:
| 变量名 | 赋值来源 |
|---|---|
tiktok_data |
节点 2(web_data_tiktok_profiles)→ json |
linkedin_data |
节点 3(web_data_linkedin_company_profile)→ json |
- 填写 System Prompt(直接粘贴):
xml
你是一个专业的社媒数据分析师。
TikTok 数据来自 web_data_tiktok_profiles,帖子在 top_posts_data 数组中,字段为:
description(内容)、likes(点赞数)、create_time(发布时间)、post_url
LinkedIn 数据来自 web_data_linkedin_company_profile,帖子在 updates 数组中,字段为:
text(内容)、likes_count(点赞数)、comments_count(评论数)、date(发布时间)、post_url、title(发帖人)
请从原始数据中提取帖子信息,严格按照 JSON 数组格式返回,
每条帖子包含以下字段:
- platform: 平台名称(TikTok 或 LinkedIn)
- account: 账号名(TikTok 取顶层 nickname,LinkedIn 取顶层 name)
- followers: 粉丝/关注者数量(整数,取顶层 followers 字段)
- author: 发帖人(TikTok 填账号名,LinkedIn 取 updates[].title)
- content_summary: 内容摘要(50字以内)
- post_date: 发布日期(YYYY-MM-DD)
- likes: 点赞数(整数,TikTok 用 likes,LinkedIn 用 likes_count)
- comments: 评论数(整数,TikTok 无此字段填 0,LinkedIn 用 comments_count)
- post_url: 帖子链接
只返回 JSON 数组,不要包含其他说明文字。- 填写 User Prompt(Jinja2 模板,直接粘贴):
xml
=== TikTok 原始数据 ===
{{ tiktok_data }}
=== LinkedIn 原始数据 ===
{{ linkedin_data }}节点 5 --- 结束节点
右键 → 添加节点 → 选择「结束 」。点击「添加输出」,选择 LLM 节点的 text 作为最终输出。将 LLM 节点连向结束节点。
输出样例
以下是同时采集 @tiktok(TikTok)和 microsoft(LinkedIn)后经 LLM 解析的真实输出样例:
json
[
{
"platform": "TikTok",
"account": "TikTok",
"followers": 93700000,
"author": "TikTok",
"content_summary": "Ezra Frech 的夺冠精神激励每一个人 #MyLIVEMyStory",
"post_date": "2026-03-27",
"likes": 51500,
"comments": 0,
"post_url": "https://www.tiktok.com/@tiktok/video/7622064700431289630"
},
{
"platform": "TikTok",
"account": "TikTok",
"followers": 93700000,
"author": "TikTok",
"content_summary": "Megan Moroney 与 emo cowgirls 空降城市现场花絮",
"post_date": "2026-02-20",
"likes": 268400,
"comments": 0,
"post_url": "https://www.tiktok.com/@tiktok/video/7609062596628483359"
},
{
"platform": "LinkedIn",
"account": "Microsoft",
"followers": 28017790,
"author": "Microsoft Developer",
"content_summary": "#MicrosoftBuild 大会议程上线,90+ 场 AI 实战 Session",
"post_date": "2026-04-09",
"likes": 577,
"comments": 32,
"post_url": "https://www.linkedin.com/feed/update/urn:li:activity:7448106175251845121/"
},
{
"platform": "LinkedIn",
"account": "Microsoft",
"followers": 28017790,
"author": "Satya Nadella",
"content_summary": "Open to Work 新书发布,帮助职场人在 AI 时代重塑竞争力",
"post_date": "2026-03-31",
"likes": 1290,
"comments": 118,
"post_url": "https://www.linkedin.com/feed/update/urn:li:activity:7444812329579622400/"
}
]Step 4:测试与基准数据
我用同一批账号和关键词做了压测------以前用 DIY 方案,TikTok 采集在 2 小时内必触发签名失效;LinkedIn 账号平均撑不过 3 天就被封。用 Bright Data MCP + Dify 的方案,连续跑了 6 小时,没有任何封锁,没有任何验证码,没有任何 403。
| 指标 | DIY 方案 | Bright Data MCP + Dify |
|---|---|---|
| 封锁率 | > 65% | < 1% |
| 数据采集成功率 | 约 35% | > 99% |
| 新平台接入时间 | 1-2 周 | < 30 分钟 |
| 月均维护时间 | > 20 小时 | < 2 小时 |
| 成本(1 万条数据) | 工程时间成本极高 | 按成功采集付费,成本可控 |
Step 5(可选):把结果推出去
拿到结构化 JSON 之后,在结束节点前再接一个 HTTP 请求节点,数据就能自动流向你需要的地方。
推送到 Slack
Slack 是欧美团队常用的协作聊天工具,支持 Webhook------往一个 URL 发一条 POST,消息就会出现在指定频道里。在 Dify 里添加 HTTP 请求节点,填入以下配置:
| 字段 | 值 |
|---|---|
| 方法 | POST |
| URL | https://hooks.slack.com/services/YOUR_SLACK_WEBHOOK |
| Content-Type | application/json |
| Body | {"text": "本次采集完成,共 {``{count}} 条数据\n{``{summary}}"} |
Slack Webhook 地址在 Slack 控制台 → Apps → Incoming Webhooks 里生成,免费功能,几分钟配好。
推送到数据库(Airtable / 自建 API)
如果你有 Airtable 表或自己的后端接口,同样是 HTTP 请求节点:
| 字段 | 值 |
|---|---|
| 方法 | POST |
| URL | Airtable API 地址 或 你的 /api/social-data 接口 |
| Headers | Authorization: Bearer YOUR_API_KEY |
| Body | 直接引用 LLM 节点输出的 structured_json 变量 |
两种方式选一种接在工作流末尾即可,其余节点不需要改动。
六、交付物 --- 下载即用
本文所有配套文件已上传至 GitHub,欢迎下载使用:
https://github.com/wangjun-dotcom/brightdata-mcp-dify-social-scraper.git
下载 workflow_social_scraper.yml,在 Dify 中点击导入 DSL 文件上传。导入后通常会遇到以下两处需要手动处理的地方:
问题一:MCP 工具节点置灰
原因是模板里记录的 MCP 服务标识符(brightdata-mcp)与你在 Dify 工具配置里填写的服务器标识符不一致,导致节点无法匹配。
两种解决方式任选其一:
-
方式 A(推荐) :进入 Dify「工具」设置,把你已添加的 Bright Data MCP 工具的服务器标识符 改为
brightdata-mcp,保存后刷新页面重新导入模板即可。 -
方式 B :直接点击置灰节点右上角三个点 → 更改节点 → 工具 → 分别选择
web_data_tiktok_profiles(TikTok 节点)和web_data_linkedin_company_profile(LinkedIn 节点),然后在参数面板里重新将url绑定到开始节点的对应输入变量。
问题二:LLM 节点模型不兼容
模板默认使用的是我自己配置的模型,导入到你的账号后会提示模型不可用。
处理步骤:
- 进入 LLM 解析节点,将模型切换为你已在 Dify 后台接入的模型(OpenAI / Claude / 其他均可)
- 切换模型后,检查 User Prompt 里的两个 Jinja2 输入变量(
tiktok_data、linkedin_data)是否仍正确指向上游节点的json输出------如果显示为空或报错,重新在输入变量面板里选择一次即可
七、成本账:帮你算清楚
先帮你把账算清楚:
| 方案 | 前期投入 | 月均维护 | 10 万条数据成本 |
|---|---|---|---|
| 自建爬虫 | 2-4 周工程时间 | > 20 小时/月 | 工程成本难以量化 |
| Bright Data MCP + Dify | < 半天配置 | < 2 小时/月 | 按成功采集付费 |
自建社媒爬虫最容易被忽视的是隐性成本:高级工程师每月 20+ 小时的维护时间(按市场薪资换算,远超 SaaS 订阅费用);账号被封导致的数据中断,意味着你的竞品监控出现盲区;TikTok 或 LinkedIn 每次更新反爬机制,你就得重新投入工程资源去逆向和修复。
Bright Data 采用按成功采集付费的定价模式------失败的请求不计费。对于 DIY 方案 35% 成功率对比 99%+ 成功率的场景,实际有效成本差距远比表格上的数字显著。
八、总结
三个核心收获,值得记住:
- 一个 Dify Workflow 替代两套独立爬虫 --- TikTok 与 LinkedIn 数据统一采集、统一格式输出,无需分别维护
- Bright Data 云端 MCP,零本地配置 --- 控制台复制 URL 和 Token,在 Dify 里粘贴一下,连接就建好了,没有服务器,没有依赖,没有运维
- 模板直接拿走用 --- 不用从零开始,下载 Dify DSL 文件,30 分钟内搭建完成第一个社媒数据采集流水线
如果你想快速复现本文工作流,可以注册 Bright Data,用这个连结注册再输入折扣码可以有20美金的试用,折扣码是leo20。下载本文 Dify 模板,30 分钟内搭建你的社媒数据采集流水线。只为成功采集的数据付费。
交付物下载地址:https://github.com/wangjun-dotcom/brightdata-mcp-dify-social-scraper.git
参考资料:
FAQ
Q1:Bright Data MCP 是免费的吗?
Bright Data MCP 提供免费使用,并允许 AI agent 访问实时 Web 数据。
Q2:MCP 与 Web Scraper API 有什么区别?
MCP 是 AI agent 调用接口,Web Scraper API 是预构建数据采集 API。
Q3:Bright Data 是否支持 TikTok 抓取?
支持,通过 MCP 或 Web Scraper API 可采集 TikTok 数据。
Q4:Dify 是否必须使用?
不是,MCP 也支持 Claude、Cursor 等 AI agent。