数据库事务
1、事务的特性是什么?如何实现的?
(事务的特性分别是ACID)也就是:
- 原子性:
一次事务的执行,要么全部成功,要么全部回滚。
主要由 undo log 来确保正常回滚。 - 一致性:
事务的执行前后,是从一个合理状态,转移到了另一个合理状态。且不会破坏规则。
这是事务追求最终目标,由(原子性/隔离性/持久性/数据库规范等)一起确保。 - 隔离性:
尽量确保事务之间并发执行时,而互不相互影响,
通常由MVCC与锁进行控制。 - 持久性:
一旦事务执行成功,数据就不会在丢失,哪怕系统宕机重启。
主要由 redo log 保证。
2、mysql可能出现什么和并发相关问题?
因为mysql 可以连接多个客户端,所以是肯定会遇到并发问题的。
而常见的并发问题有三种,分别是:脏读、不可重复读、幻读。
脏读 :在本事务中,读到了另一个事务还没有提交的数据。
不可重复读 :在同一个事务中,操作多次相同的sql读取操作,读到的数据不同。
幻读:在同一事务中,两次范围读取到的行数不同。
3、那些场景不适合脏读,举几个例子?
脏读,是在本次事务操作中,读到了另一个事务未提交的数据。如果另一个事务回滚了,就会导致数据不一致。
在银行、仓库管理这些高精度操作中,出现脏读会导致非常严肃的后果。
4、mysql是如何解决并发问题的?
常用的有三种手段:
1、锁 :mysql主要通过行锁与表锁来解决写写问题,临间锁/间隙锁来解决幻读问题。
2、设置隔离级别 :通过设计不同隔离级别(读未提交/读已提交/可重复读/串行化),来控制并发时不同事物之间的隔离程度。
3、MVCC多版本化控制:解决读写冲突问题,通过维护 undo log 版本链,结合不同时机生成Read View的,来解决不可重复读/脏读,并在临间锁的帮助下解决幻读。
5、事务的隔离级别有哪些?
- 读未提交(RU):本事务能读到,其他事务未提交的数据。
- 读已提交(RC):本事务结束之后,提交的数据才可以被其他事务读到。
- 可重复读(RR):同一事物内,所有操作共用一份ReadView,Innodb默认开启这个级别。
- 串行化(Serializable):通过读写锁,强制所有事物顺序执行。
6、mysql默认级别是什么?
可读性隔离级别。
7、可重复读隔离级别下,A事务提交的数据,在B事务能看见吗?
不可以,因为MVCC(多版本并发控制),在可重复读这一级别下,会在事务开始后的第一个查询语句进行。通过 undo log 生成一个版本快照,B之后所有的操作都是基于此快照进行的,所以读不到A后来提交的数据。
当然这个只是快照读,如果是加锁/修改/删除/...进行这些时,导致的回填,仍然会读到。
8、举个例子说可重复读下的幻读问题
当时事务A,第一次进行select操作时,会基于 undo log 生成快照,但如果此时事务B新增了id=5。这条数据。且此时事务A误进行了update id = 5 的操作,就会造成 trx_id ,变成A事务的。之后事务A的select就可以读到id=5,这条数据。
9、Mysql设置了可重复读隔离级别后,怎么保证不发生幻读?
当事务开启后,立马执行select ... for update这种操作,为其加上临间锁。避免其他事务在他查询的范围内插入新行,从而避免幻读。
10、串行化隔离级别是通过什么实现的?
通过更加严格的并发控制来实现的,通常表示为,对读写操作都加锁,使事务操作更容易阻塞,从而近似成顺序执行。
11、介绍MVCC的实现原理
MVCC就是多版本并发控制。他的核心思想是,让他读到他可见的版本,而不是最新的版本。
它主要有三部分实现:
1、innodb维护的隐藏字段
2、undo log
3、Read View
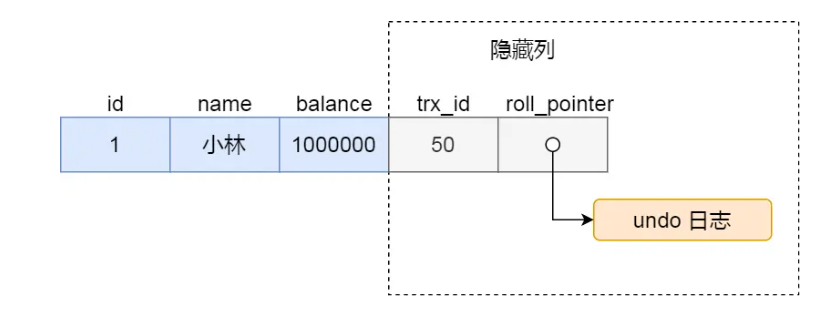
innodb对每行数据,维护了trx_id(最近一次事务对其进行了操作,并记录他的事务id),与roll_pointer(可以看到上一个版本)
版本链,其实就是由 undo log + roll_pointer 实现的。
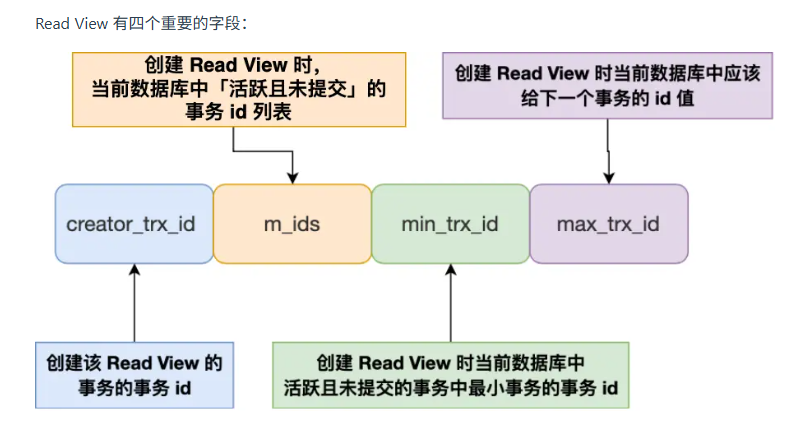
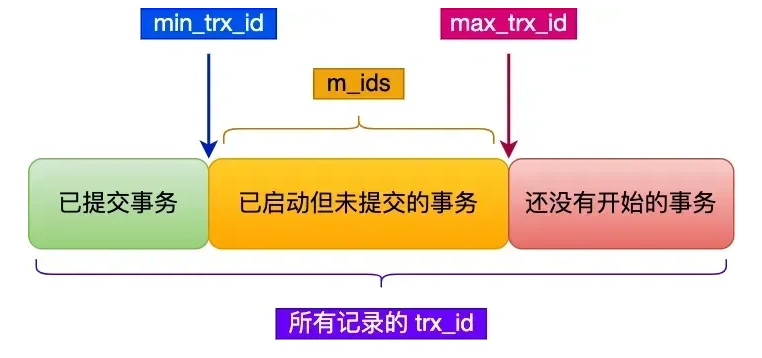
ReadView 是一个快照的核心,代表他当前可以读哪些数据。通过creator_trx_id、trx_ids、min_trx_id、max_trx_id这四个字段进行控制,读取的版本。
如果要读取目标的trx_id,小于min_trx_id,则可读。
如果读取目标的trx_id,大于min_trx_id,但小于max_trx_id。在判断是否在trx_ids中,不在的话,就可以读取。
其他的则统一读取不到。只能顺着undo log版本链,去获取它可以读到的版本。
12、一条update是不是原子性的?为什么?
单条语句本身都是原子操作,如果执行失败,则会通过undo log回滚。
13、滥用事务,或者一个事务里有特别多sql的弊端。
1、sql越多,执行时间就越长,若内部有锁得话,锁持有时间也会变成。锁竞争得风险更大,死锁的风险也会飙升。
2、由于undo log日志较多,不仅占用磁盘,并且失败回滚的话,耗时也更长。
3、主从复制的延迟也会更长。传输/重放成本,会更大。