1 LangChain简介
开发者使用 LangChain提供的"核心组件"(零件),按照一个良好的 "分层架构"(内部设计) 所创造的环境,像拼积木一样,轻松地组合出各种AI应用
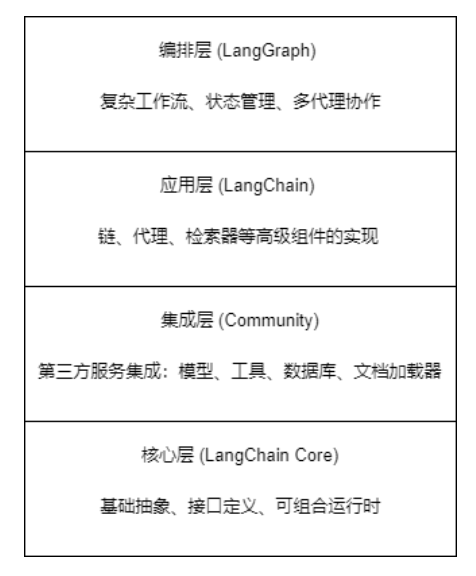
1.1 分层架构
LangChain主要分为四个层次:
核心层LangChain Core、集成层Community、应用层LangChain、编排层LangGraph
1.1.1 核心层LangChain Core
LangChain 规定,不管什么LLM模型或工具,都必须提供一个标准插头,即实现统一的调用方法。而LangChain框架的核心层就是一个只认标准的抽象接口的插座,如果有新的模型,LangChain就会让你为它配一个包装类,将模型原本不规则的接口转化为标准的接口,也就是说,
LangChain是通过让大家遵守同一套调用规则(通过抽象基类定义的标准接口),并要求所有组件都通过一个适配器(包装类)来遵守这套规则,实现了不同组件之间的即插即用
LangChain的核心层制定了一套"插头标准"。所有AI模型和工具,通过对应的"适配器"(你import的类)把自己变成标准插头。这样你就能像拼乐高一样,把它们任意组合起来,并且随时替换其中的零件,而整个作品不会散架
当你写代码时,你用的是 from langchain_openai import ChatOpenAI,或者 from langchain_community.tools import DuckDuckGoSearchRun,这些都是已经写好的适配器。你直接拿来用,它们自然就符合标准
python
# 用户/框架 → .invoke() 或 .call() # 你主要用的
# ↓
# 基类实现 → 一些通用逻辑
# ↓
# 具体实现 → ._run() 或 ._generate() # 适配器开发人员实现的
class 适配器(基类):
def _run(self, input):
# 1. 转换输入格式(标准 → 原生)
原生输入 = self._转换输入(input)
# 2. 调用原生API
原生响应 = 调用原始API(原生输入)
# 3. 转换输出格式(原生 → 标准)
标准输出 = self._转换输出(原生响应)
return 标准输出1.1.2 集成层 (Community Integrations)
集成层是LangChain生态最丰富的部分,包含了
与各种外部服务和工具的连接器
主要集成类别:🌱 模型提供商 :OpenAI、Anthropic、Google、Meta、智谱AI、通义千问等(调用方式一模一样,无需额外学习)
🌱 向量数据库 :Chroma、Pinecone、Weaviate、Milvus、Qdrant等(
使用"文档嵌入模型",将一个文本块转换为一个摘要向量,通过对比 问题查询vector 与 文本块vector 之间的相似度来查询对应的文本块)🌱 文档加载器 :PDF、Word、Excel、网页、数据库、API等(读取文档)
🌱 工具集成:计算器、搜索引擎、API调用、代码执行等(让AI能使用各种外部工具)
python
向量数据库存储格式
vector_database_entry = {
"embedding": [0.1, 0.2, -0.3, ...], # 768维向量(压缩的语义)
"document": "完整的500字文本内容", # 原始文本
"metadata": {"source": "doc.pdf", "page": 5} # 元数据
}
搜索时:
1. 用向量快速找到相关条目(高效)
2. 返回时提供完整的原始文本(完整)
Document Embedding(提取文本块摘要)
(1)得到每个token的embedding:[1, 50, 768] - 50个token,每个768维
(2)使用池化(Pooling)合并成一个向量
(a) 平均池化(Mean Pooling)
document_vector = torch.mean(token_embeddings, dim=1) # [1, 768] - 50个token向量的平均值
(b) CLS token池化(BERT方式)
document_vector = token_embeddings[:, 0, :] # 取第一个[CLS]token [1, 768]
(c) 最大池化(Max Pooling)
document_vector = torch.max(token_embeddings, dim=1)[0] # [1, 768] - 取每个维度的最大值
return document_vector # 单个向量代表整个文档1.1.3 应用层(LangChain)
应用层基于核心层抽象和集成层能力,提供了开箱即用的高级功能,这是大多数开发者直接接触的部分
核心组件:🌱 链 :预定义的工作流程,把多个步骤连接起来完成复杂任务,如RetrievalQA、ConversationalRetrievalChain(简单问答、多步骤但固定,
固定的工作流程)🌱 代理 :具备推理和工具使用能力的
智能体自己决定做什么、用什么工具(动态决策、使用外部工具、步骤不确定)🌱 检索器 :文档检索和相似度搜索的高级封装,简化向量数据库的使用
🌱 记忆:对话历史管理和上下文维护
python
检索器(RAG必不可少的组件):
检索器不是存储,是搜索接口,必须与向量数据库配合使用
配置决定效果:k值、搜索类型、过滤条件
可以组合使用:多个检索器集成提高效果
用户问题
↓
检索器.invoke(问题) ← 核心调用
↓
[内部:向量化 → 搜索 → 排序 → 过滤]
↓
返回相关文档列表
↓
交给LLM生成答案检索器类型:
🌱 向量检索器 :语义检索,
将文本块转换成向量,计算向量之间的相似度🌱 关键词检索器 :文字匹配,
匹配关键字,不懂语义(类似于传统Ctrl+F搜索,搜索"苹果"只能找到包含"苹果"这两个字的文档,找不到"Apple"或"水果之王"的相关内容)🌱 混合检索器 :
结合向量检索器、关键字检索器,兼顾语义理解和文字精确匹配,同时使用向量和关键词检索,然后合并结果🌱 压缩检索器 :先检索,再压缩/提炼检索结果,去除冗余信息,只保留最相关部分
🌱 集成检索器:组合多个检索器,加权投票,适用于对准确性要求高的场景
Agent 本质就是一个图工作流,LangGraph 就是构造 Agent 的底层框架调用
create_agent方法 = 用别人写好的 ReAct 工作流,将控制权给 Agent自己写 StateGraph = 开发人员手动设计流程,控制权完全在你
1.1.4 编排层(LangGraph)
编排层是LangChain体系中最先进的部分,
专门处理需要状态维护(应用层的链简单记忆,记忆有限,编排层可以维护完整状态)、循环、分支等复杂逻辑的应用场景
- LangChain:处理简单任务
- LangGraph:多轮对话、分支判断、跟踪复杂状态、并行处理
编排层是LangChain的"操作系统",它管理复杂的工作流,让多个AI协同工作,处理需要状态、循环、分支的复杂任务
核心概念:🌱 状态图(状态、边、事件、条件) :基于状态机的工作流定义
🌱 持久化状态 :支持长时间运行的复杂任务
🌱 多代理协作 :多个AI代理协同工作的框架(单个AI能力有限,需要多个协作)
🌱 循环和条件:支持if-else、for、while等控制流
2 LangChain核心模块
- 📦 模型 I/O(Model I/O) - 与AI模型交互的基础
- 🔗 检索(Retrieval) - 获取外部知识
- 🧠 记忆(Memory) - 记住对话历史
- ⛓️ 链(Chains) - 组合多个步骤
- 🕵️ 代理(Agents) - 动态使用工具
- 🎛️ 回调(Callbacks) - 监控和日志
2.1 模型输入输出
核心功能 :与各种AI模型(LLM、ChatModel、Embedding)交互的标准化接口(
可以对输入格式化、对不同的模型调用统一的接口、将输出转换为指定的结构化数据)类比就像电源插座,不管什么电器(模型),插上就能用
包含三个子组件:
提示模版(Prompts) :动态提示词管理和格式化
语言模型(Language Models) :统一的模型调用接口(invoke)
输出解析器(Output Parsers):把模型的输出解析成结构化数据(比如在Prompt中添加"请输出JSON格式",但模型返回的字符串形式,需要转换成JOSN对象)
2.2 检索(Retrieval)
核心功能:从外部数据源获取相关信息
四个步骤:🌱 (1) 文档加载器 :从各种来源加载文档,支持:PDF、Word、网页、数据库、API等
🌱 (2) 文本分割器 :把长文档切成文本块(模型有长度限制,需要分块处理)
🌱 (3) 向量存储 :将文本块存储向量,方便快速检索,工具:Chroma、Pinecone、FAISS、Weaviate
🌱 (4) 检索器 :搜索相关文档的接口,类型包括:向量检索、关键词检索、混合检索等
🌱 使用:retriever.invoke("问题") → 返回相关文档
2.3 记忆(Memory)
核心功能:保存和回忆对话历史
主要类型:🌱 (1) 对话缓冲记忆 :记住所有对话
🌱 (2) 对话缓冲窗口记忆 :记住最近N轮对话
🌱 (3) 对话摘要记忆 :对长对话生成摘要,记住摘要(节省token,保留关键信息)
🌱 (4) 实体记忆:记住特定实体信息(个人信息、偏好信息、上下文信息、关系信息等)
2.4 链(Chains)
核心功能:把多个组件连接成工作流
类比:就像工厂流水线,原料经过多道工序变成产品
主要类型:🌱 简单链 (LLMChain)
🌱 顺序链 (SequentialChain):多个链按顺序执行(处理多步骤任务)
🌱 转换链 (TransformChain):自定义数据处理步骤(不需要LLM,常用于:数据清洗、格式转换、文本预处理、数据提取)
🌱 检索问答链(TransformChain):检索 + 问答一体化(用户问题 → 检索相关文档 → 组合文档和问题 → LLM生成答案) 基于事实,减少幻觉,可以访问最新信息,答案有据可循
2.5 代理(Agents)
核心功能:让AI自主决定使用什么工具
类比:就像有多个工具的智能助手,自己选择工具解决问题
核心概念:
工具 :代理可以使用的功能
代理执行器 :代理执行器(工具选择决策、执行流程管理、错误处理和恢复)
代理类型区分 = 提示模板 + 代理类 + 输出解析器
代理类型(通过传入的 prompt 提示模板来决定代理的行为):
- Zero-shot:每次重新思考,无记忆
- ReAct:思考→行动→观察循环,思考过程透明,可解释性强
- Conversational:带对话记忆
- Self-ask:自我提问寻找答案
python
# 不同代理使用不同的提示模板
# Prompt 模板仓库(Hub)
from langchain import hub
# 零样本代理
zero_shot_prompt = hub.pull("hwchase17/zero-shot-react")
# ReAct代理(思考-行动循环)
react_prompt = hub.pull("hwchase17/react")
# 对话代理(带历史)
conversational_prompt = hub.pull("hwchase17/conversational-react")
# 自我提问代理
self_ask_prompt = hub.pull("hwchase17/self-ask-with-search")
# 不同的提示模板定义了不同的思考方式
prompt_templates = {
"react": "思考:...\n行动:...\n观察:...",
"conversational": "历史:{chat_history}\n思考:...",
"self_ask": "问题:...\n子问题:...\n答案:...",
"zero_shot": "直接回答,不需要思考步骤"
}2.6 回调(Callbacks)
核心功能:监控和记录AI应用运行情况
类比:就像飞机的黑匣子,记录所有操作
主要用途:
日志记录 、监控指标 、流式输出 (实时显示生成过程,用户可以看到AI一个字一个字生成,而不是等待全部完成)、自定义处理(特定事件触发特定操作,例如当检索到文档时:记录到数据库;当生成完成时:发送通知;当发生错误时:报警)
3 LangGraph入门
3.1 状态图
🌱 状态图是LangChain中构建复杂AI工作流的「可视化流程图」,让开发者能清晰地设计和控制AI的思考过程(一步一步按照流程来执行)
🌱 什么时候需要用状态图?有严格顺序的业务流程、需要复杂决策逻辑、多轮对话需要记忆上下文、需要可靠性和可预测性、需要可视化调试
状态图核心概念:
状态(让AI记住对话历史,保持上下文连贯)节点(当前节点AI只做当前节点的事)边(告诉AI"接下来该去哪",控制流程顺序、处理分支逻辑等)图(把零散的功能组织成完整系统)
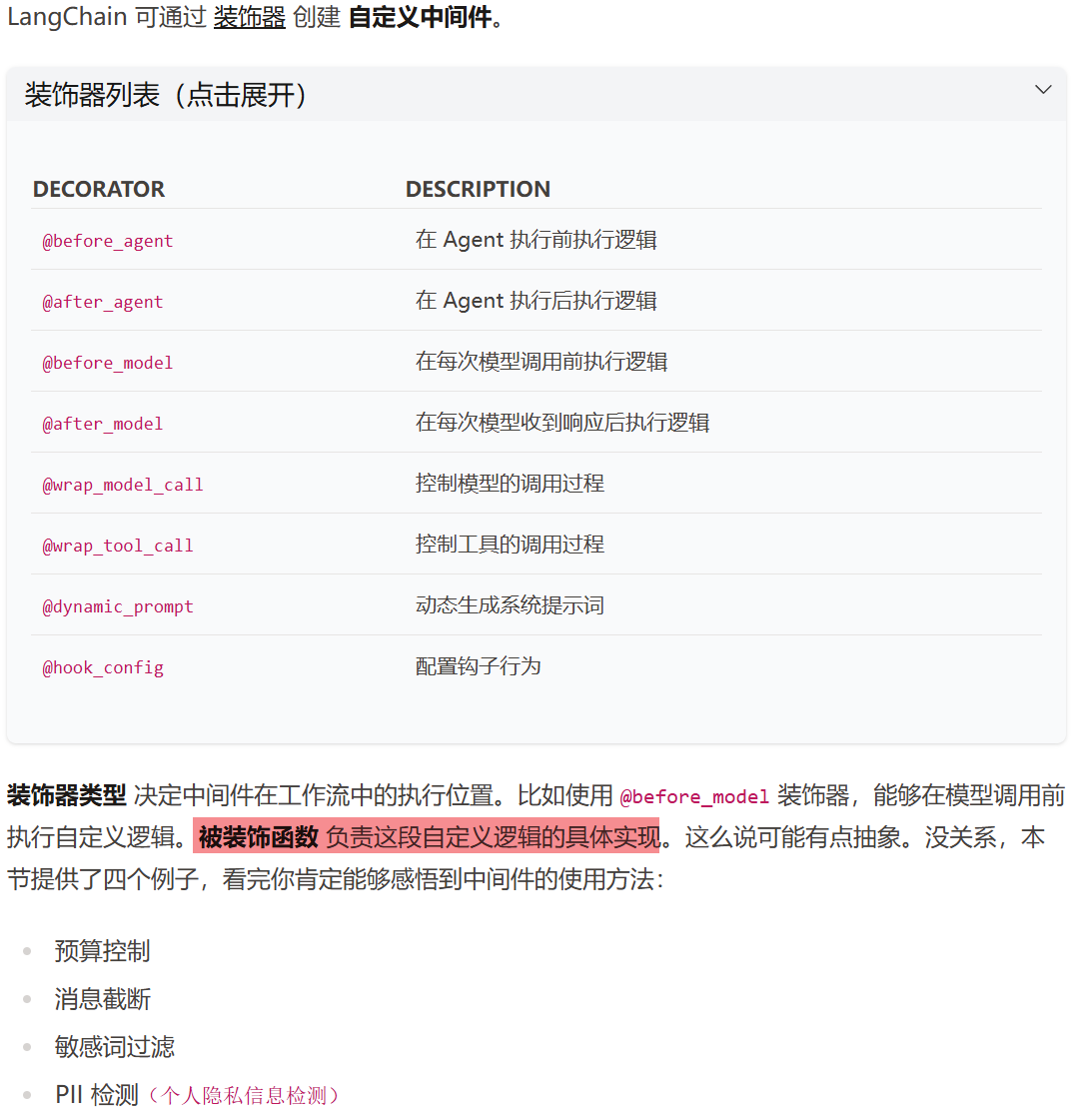
3.2 中间件
中间件就是在「正常流程」中插入的「额外处理步骤」,不改变原来的代码,额外添加日志、缓存、安全检查等逻辑,诸多新功能均藉由中间件实现,比如人机交互、动态系统提示词、动态注入上下文等等
特点:
- 钩子函数:在特定时机执行的代码
- 可插拔:随时添加或移除,不影响核心功能
- 职责单一:每个中间件只做一件事
预算控制
随着对话轮次增加,每次请求携带的对话记录也会越来越长,从而导致请求费用上升。为了控制预算,可以设定在对话轮次超过某个阈值后,切换到低费率模型。这个功能可以通过自定义中间件实现
@wrap_model_call,控制模型的调用过程
消息截断智能体的上下文存在长度限制。一旦超过限制,就需要对上下文进行压缩。在众多方法中,截断是最简单粗暴、易于实现的方法。消息截断功能可以通
@before_model,在每次模型调用前执行逻辑装饰器实现
敏感词过滤
护栏 是智能体提供的一类内容安全能力的统称。大模型本身具备一定的内容风控能力,但很容易被突破。智能体可以在模型之外,提供额外的安全保护。这是通过工程上的强制检查实现的。在 LangGraph 中,护栏可以通过中间件轻松实现,若用户的最新消息中包含某些敏感词,智能体将拒绝回答
PII检测PII(Personally Identifiable Information)检测可以发现用户输入中的邮箱、IP、地址、银行卡等隐私信息,并做出处置
3.3 人机交互
人机交互(Human-in-the-loop, HITL)指智能体为了向人类索要执行权限或额外信息而主动中断,并在获得人类反馈后继续执行的过程
LangGraph 内置人机交互中间件 HumanInTheLoopMiddleware。触发人机交互时,HITL 会将当前状态保存到 checkpointer 短期记忆中,并等待人类回复。待获得回复后,再将状态从检查点中恢复出来,继续执行任务
- 在演示环境/测试环境等,可以将数据存储到
InMemorySaver,内存存储:程序重启后数据丢失- 在生产环境中,需要将数据存储到数据库/磁盘,持久化存储,持久化存储优势:程序崩溃、服务器维护、版本升级等都不会导致数据丢失,持久化存储检查点例如:
SqliteSaver(不需要安装服务器、不需要配置、生成本地文件)、PostgresSaver、MongoDBSaver、RedisSaver
3.4 记忆
记忆(Memory)是一个可选模块。如非必要,你无需向智能体添加 Memory 模块。因为 StateGraph 本身就含有历史消息列表 messages,足以满足最基础的"记忆"需求
需要添加 Memory 模块的情况包括:
历史消息太多,需要用外部工具存储记忆
触发人工干预时,临时保存 Agent 的状态(人机交互)
跨对话提取用户偏好 等
LangGraph 将记忆分为:短期记忆:
原始对话,不处理,不总结,直接存储;可以存储在InMemorySaver内存、数据库等长期记忆:
提炼的关键信息,会遗忘/更新,不重要的信息会被覆盖,数据库存储此外,还有一个 LangMem (专门的记忆管理系统)也提供记忆存取功能
如何选择使用什么记忆?
- 简单应用时使用:StateGraph.messages
- 需要暂停/恢复/人机交互:短期记忆Checkpoint
- 需要个性化:数据库/向量数据库进行长期记忆存储
- 当开发复杂系统时:组合使用
3.5 上下文工程
上下文工程(Context Engineering)对于 Agent 得出正确的结果至关重要。模型回答不好,很多时候不是因为能力不足,而是因为没有获得足以推断出正确结果的上下文信息。通过上下文工程,增强 Agent 获取和管理上下文的能力,是很有必要的
LangGraph 将上下文分为三种类型(定义不同中间件-不同装饰器):
- 模型上下文:模型生成时使用的上下文,对话历史、提示词
- 工具上下文:工具函数执行时需要的运行时信息,用户ID、权限、会话
- 生命周期上下文:管理AI系统整个生命周期的状态,参与度、错误计数、状态
上下文的具体实现依赖中间件,而上下文的存储则依赖记忆系统
模型上下文和工具上下文:瞬态更新,生命周期上下文会持续更新:持续将旧消息替换为摘要。
获取上下文:
- 运行时(Runtime)- 所有节点共享一个 Runtime。同一时刻,所有节点取到的 Runtime 的值是相同的。一般用于存储时效性要求较高的信息,
Runtime Context 需要配置,执行环境信息- 短期记忆(State)- 在节点之间按顺序传递,每个节点接收上一个节点处理后的 State。主要用于存储 Prompt 和 AI Message,
直接访问,存储对话本身的状态信息,框架自动维护(聊天记录)- 长期记忆(Store)- 负责持久化存储,可以跨 Workflow / Agent 保存信息。可以用来存用户偏好、以前算过的统计值等,例如
InMemorySaver
python
# State 就是 LangGraph 里用来存放对话历史、中间结果等所有运行时数据的记忆容器,Agent 和中间件都是靠它来感知上下文的
# 中间件里 → request.state
# 节点函数里 → state
# 运行结束后 → agent.invoke() 的返回值
@dataclass
class Context:
user_role: str
deployment_env: str
result = agent.invoke(
{"messages": [{"role": "user", "content": "广州今天的天气怎么样?"}]},
context=Context(user_role="viewer", deployment_env="production"),
config=config,
)3.6 并行
介绍两种实现并行的方法:
- 节点并行(节点并行很容易实现,使用 StateGraph 创建带并行节点的工作流就可以)
- Map-reduce
Map-Reduce 原本是什么意思?
Map(映射):把一个大任务拆成很多独立的小任务,并行处理(同时做)
Reduce(归约):把所有小任务的结果收集起来,合并成最终结果
例子:统计一本书里每个单词出现的次数Map:把书分成 10 章,10 个人同时数自己那章的单词
Reduce:把 10 个人的统计结果合并,得到全书的结果
在 AI Agent 中怎么用?比如问:"苹果公司有哪些优缺点?"
先发散 :让多个 AI Agent(或一个 Agent 多次调用)同时处理不同的问题或角度:让 3 个 Agent 分别从 财务、产品、企业文化 角度分析
后收敛:把多个 Agent 的答案汇总、去重、整理成一个最终答案
LangGraph 也可以实现 Map-Reduce具体实现:
- 写一个 for 循环,调用多次 AI API(Map),再把所有回复拼在一起(Reduce)
这样的好处:
- 标准化:LangGraph 提供了现成的工具来定义"先发散后收敛"的流程,不用自己从头写
- 可读性强:LangGraph 画的流程图一目了然,容易理解和维护
- 功能更全:除了 Map-Reduce,还能轻松实现更复杂的 Agent 协作流程(比如循环、条件判断)