It's not hard. It's just new.
刚过去的这个周末,我跟久未谋面的朋友小A相聚了一番。小A当前在一家公司担任HR,最近在进行大量的招聘工作,需要处理各个渠道过来的简历。
背景:使用 Excel 维护候选人简历信息
由于公司规模小,没有成熟的简历管理系统,再加上出于简便的考虑,小A之前一直是用Excel进行候选人维护,例如下表,每次有新的候选人简历,就在表格里增加一行。在查找时,直接用 Ctrl+F 进行全表检索。
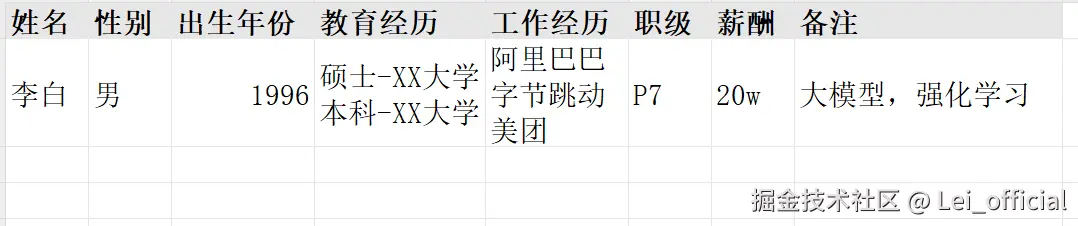
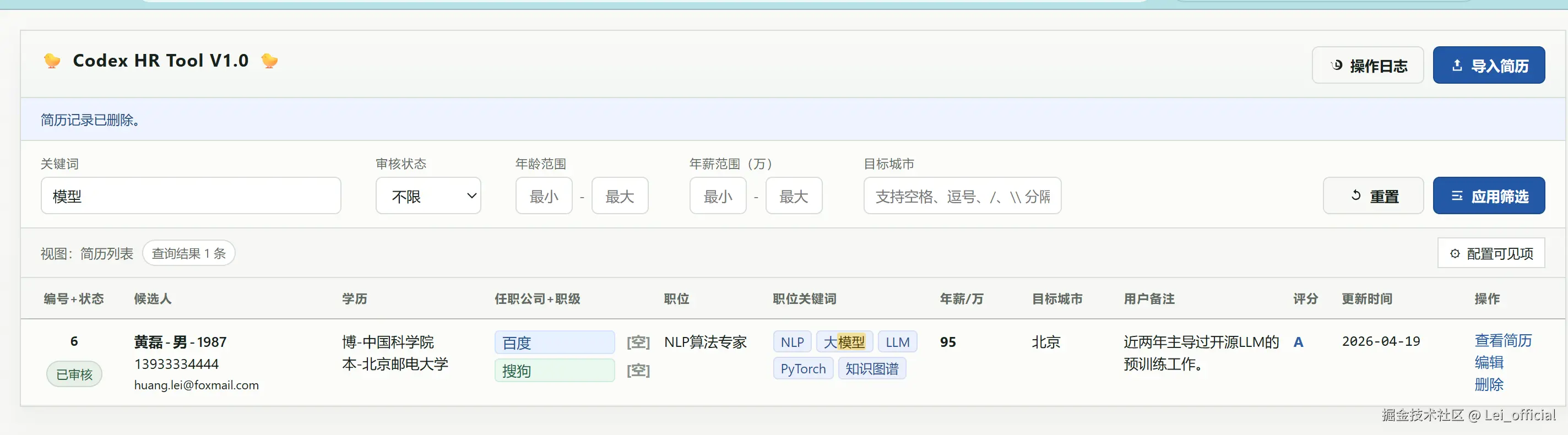
不得不说,这是一种最朴实、最简单的管理方案。插入数据的成本低,随之而来的,是巨大的使用和维护开销。同时,对于在线的简历维护系统(Boss、猎聘等),需要充值后才能解锁完整功能。
综上,在聊天中,小A希望能够有一套搭建在本地的简历维护系统,支持基本的插入、编辑、搜索,如果能够做到自动化则最好。我认为这是一个很好的扩展能力边界的机会,在之前的实践中,我一直在自己熟悉的技术栈里应用AI,也切实感受到了AI带来效能的提升。而在后端、前端(H5)则几乎没有尝试过。
因此,在聊天的过程中,小A细化了他工作的痛点,并将其整理成一份略具雏形的PRD。以此为起点,我构建出了一套运行在本地环境、支持AI提取关键信息、自动化归档简历的系统。
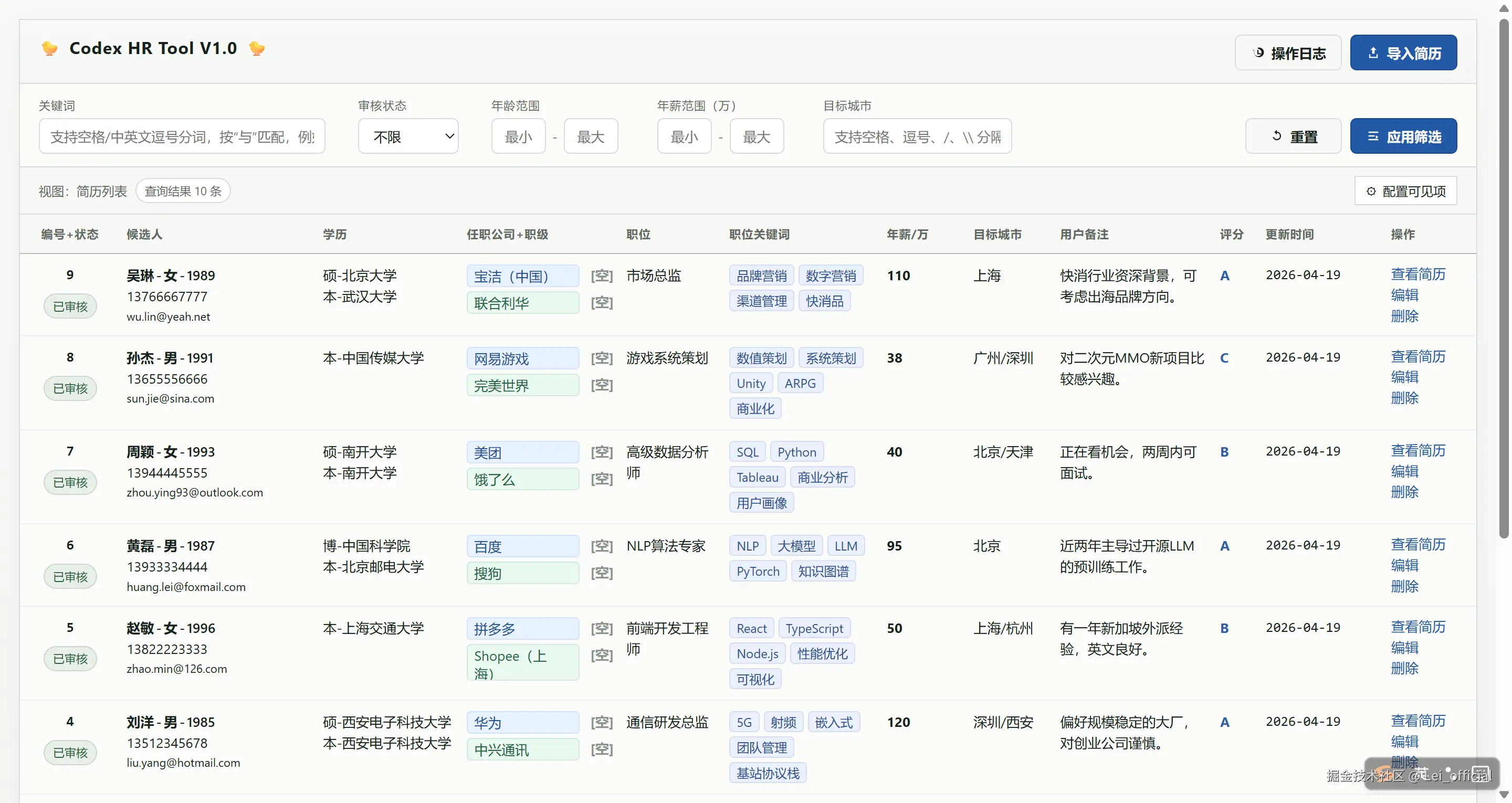
阶段性V1.0版本如下图所示,其中填充mock数据。
前期工作:痛点梳理与需求澄清
在这个场景下,我作为功能开发人员,而小A则是我的客户,是需求的提出方。小A之前没有担任过产品经理,但他非常有积极性地做这件事,为此还专门学习了PRD的写法,并且按照他的理解,写出了第一版PRD。这一点上,我还是很佩服他的。
挖掘用户最本质的需求
用户最本质的需求是想要一个 轻量、可控、符合自身工作习惯 的单机管理简历的工具。市面上的类似系统要么太重、要么不适合个人单机场景,于是我想到利用 AI Agent 自己制作一个。
该简历维护平台典型的工作流如下:
导入简历 -> 结构化抽取 -> 筛选检索 -> 行内审核编辑 -> 预览原始 PDF
头脑风暴:痛点与解决方案
小A的痛点其实很简单:
- 简历文件分散在不同目录,检索和对比成本很高。
- 关键字段(教育、工作经历、目标城市、关键词)长期靠人工整理,重复劳动很重。
- 需要个性化搜索,例如按照年龄、薪资、意向城市等进行匹配。
做个人项目最忌讳的是功能发散,很多人不是不会写代码、用AI,而是尝试一次就做到功能完美的公司级平台系统,这会导致项目边界不断膨胀。因此,我把这次的目标限定为------做一个 每天真的会打开用的小工具 ,而不是做一个 完美的简历维护系统。
将问题收敛到周末可完成
我主要做了三件事:
- 砍需求,只保留主链路。
- 明确边界:单机单用户、先支持
PDF/DOCX。 - 每一步都要可验收,不做"写完再看"。
实践阶段
设计技术方案
在AI的建议下,为了保证开发速度和可维护性,我采用的是朴素而且高效的一套方案:
- 后端:FastAPI
- 存储:文件 + SQLite
- 前端:React + Vite
- 抽取层 :
Extractor抽象(支持 Codex CLI 与 Rule Extractor)
核心数据流
- 上传/导入简历
- 归档原件并提取文本
- 结构化字段写入数据库
- 前端高密度表格筛选与高亮
- 行内编辑、审核通过、删除、查看原文
在Ai的辅助下,即使我的python仅具备初级水平,仍然完成了这样一套MVP版本的简历管理工具。
周末两天我具体做了什么
Day 1 上午:需求澄清与工程雏形建立
- 人vs人 多轮沟通需求,明确页面形式、字段、搜索匹配条件
- 人vsAI 创建工程雏形,能运行并在浏览器中查看效果
目标只有一个:能跑、能存、能查。
Day 1 下午:导入主链路
- 批量上传
- 提交历史页面
- 原始文件归档
- PDF/DOCX 文本提取与失败状态记录
做到这里,基本固定了系统的主要数据和控制链路。
Day 2 上午:数据抽取与审核闭环
- 接入抽取器抽象层(支持 在线codex cli接口 和 离线语义分析 切换)
- 支持手工修正与重抽取
- 完善编辑、删除、审核功能
由于语义提取的功能对于大模型来说并不是很复杂,考虑到 codex cli 接口用量限制与稳定性波动,这里还计划接入国内的大模型。
Day 2 下午:UI优化,验收和微调
- 反复调整顶部筛选区、数据分列的格式
- 关键词命中高亮
- 原始 PDF 弹窗预览
UI可视化效果是AI的弱项,我在这一方面花费了较多时间,才将前端页面调整到信息密度适中,文字展示效果较好的程度。这一块如果要做的更加美观,可能需要专业的美工参与。也许有专攻前端UI效果的AI Skill,只是我目前尚未了解到。
我是如何和 AI 协作的
这次最有价值的不是代码和工程本身,而是协作方式。AI完成的质量,取决于使用者提问的质量 。我建议用 小步快跑 的方式:
- 每次只交付一个闭环步骤(实现 + 验证 + 文档更新)。
- 若失败,必须给出"原因 + 修复 + 验证命令"。
- 需求变更必须回写任务文档,避免上下文漂移。
我把常用的 Prompt 分成3类,它们的结构大概是这样:
1.需求开发类 Prompt
text
目标:
实现 XXX 功能,范围仅限 A/B/C 文件。
验收标准:
1) ...
2) ...
约束:
1) 不改动无关模块
2) 变更后执行测试并反馈结果2.问题修复类 Promt
text
问题:
出现 XXX 异常,给我:
1) 根因
2) 最小修复方案
3) 验证步骤3.UI 调整类 Prompt
text
UI 调整:
- 按"高密度、报表导向、筛选优先"改版,不要大圆角卡片风。
- 将"备注"列的宽度减少2个汉字,将其加到"任职公司"列。过程中最关键的 4 个坑
| 坑 | 现象 | 处理 | 结论 |
|---|---|---|---|
| 抽取质量不稳定 | 学历/任职公司会空,或者格式不统一 | 规则归一化 + 提示词约束 + 人工编辑兜底 | 自动抽取必须和人工修正并存 |
| UI "能看"不等于"能用" | 早期 UI 看起来还行,但筛选效率低 | 从卡片改成表格工作台,列宽、换行、操作密度逐项打磨 | 工具型产品的 UI 指标是"信息吞吐量" |
| 导入与处理链路卡顿 | 导入后等待感明显 | 增加任务状态、进度反馈、日志定位;抽取流程与导入流程解耦 | 可观测性几乎和功能同等重要 |
| 历史字段债务 | 早期字段定义和当前 UI 不一致,造成噪音 | 清理旧字段,仅保留当前必需字段集合 | 越早清债,后续迭代越稳 |
阶段总结与思考
当下,这个项目算是告一段落了,尽管还有很多可以打磨的地方,但我已经决定撤出其中,将精力分配到更加重要的事项上
当前量化结果
目前这个项目已经进入"个人可持续使用"状态,核心指标如下:
- 代码规模约
9,744行 - 后端模块
10个,前端核心模块3个,脚本模块3个 - API 路由约
24个 - 回归测试
12项通过
功能上已覆盖:
- 批量导入、去重、归档
- 自动抽取(可切换本地/在线策略)
- 高密度筛选工作台
- 行内审核与编辑
- 操作日志与 PDF 预览
这个项目给我带来真正的价值
- 验证了 人+AI 可以产生的生产力突破性提升,将原本两周都未必能完成的任务,压缩成两天的工作量。
- 让我 亲身实践并独立完成 了一整套前后端闭环的系统,并且使用的还不是我最熟悉的开发语言。
- 让我更确认,个人工具最该追求的是 闭环和迭代速度,而不是第一天就追求大而全。
- 让我认识到,在能力范围内要使用最强的大模型,因为大模型能够带来效率的提升是 乘法 ,而不是 加法。举例来说,在回答一个问题时,模型A的准确率是90%,模型B的准确率是80%。当问题不断迭代,到5个问题时,模型A积累的准确率尚有60%,而模型B已经降到了32%。尽管我们为更强模型支付了更高的订阅费用,但同时也避免了较弱模型带来时间和金钱的浪费。
- 我还学会了让两个模型之间交叉验证,即模型A完成某个步骤后,交由模型B检查它的工作成果。如果没有多个模型,也可以让同一模型的不同 Subagent 来完成这种校验。
尚存不足之处
目前仍有三类改进空间:
- 在线模型的稳定性问题。当前使用的是codex,一方面需要科学上网才能访问,另一方面额度有限。未来考虑替换为国内大模型。
- 备份/恢复、诊断脚本等工程能力还可继续补齐。
- 列表查询与分页性能还能再优化。
但对小A的个人使用场景来说,它基本进入进入"可用生产工具"阶段。
附:主要功能界面
截图:批量导入
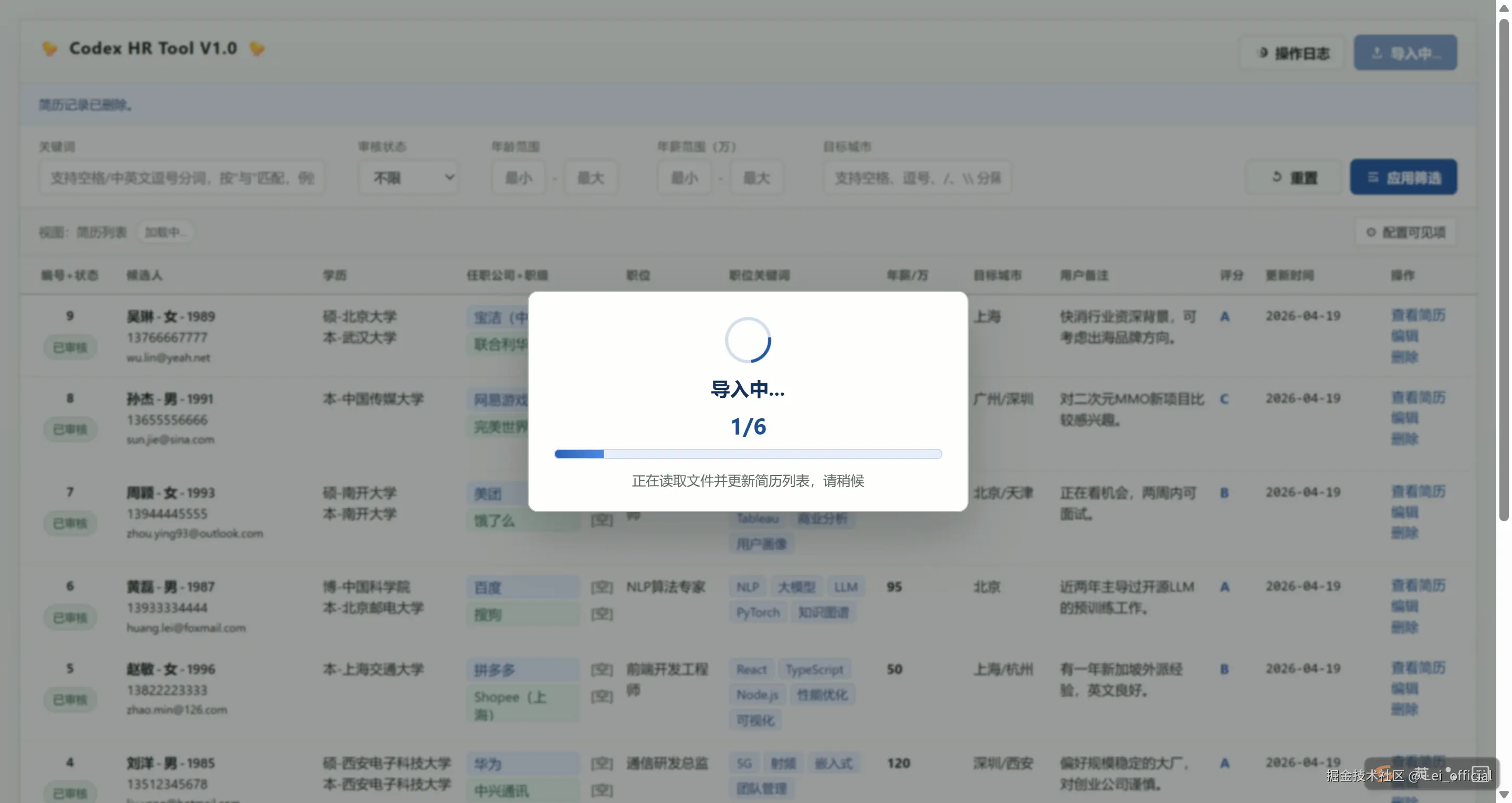
截图:行内编辑
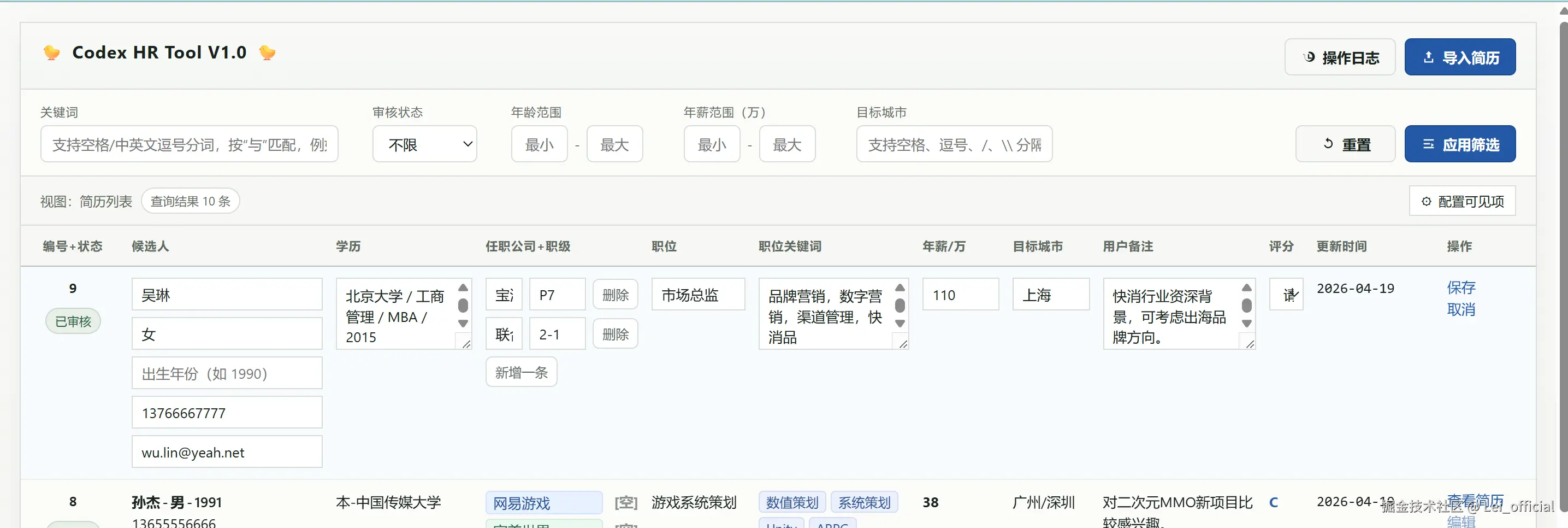
截图:关键词高亮筛选