摘要 :面向施工现场与制造业安全监管中"人工巡检成本高、漏检与时效性不足"的痛点,老思在本文系统性梳理并实践了 YOLOv5--YOLOv12 的迭代升级路线,构建了一套面向 个人防具(PPE)检测 的端到端应用系统,并给出可复现的完整工程。系统以 YOLO 系列多版本模型 为核心,针对安全帽、反光背心/工装、口罩/护目镜、手套等典型防护目标实现精确检测与类别统计,推理输出包含目标框、类别与置信度,并支持阈值(Conf/IoU)调节与结果可视化。工程侧采用 Python 3.12 + PySide6(Qt 信号槽) 实现友好的桌面端界面,覆盖图片/视频/摄像头多源输入、实时播放控制、检测结果保存与导出等流程;同时引入 SQLite 完成用户注册登录、独立配置与历史记录持久化,形成"检测---记录---回溯"的闭环。算法层面在统一数据与评估协议下对 YOLOv5 至 YOLOv12 的精度与速度进行对比分析,并结合任务特性给出训练配置与部署建议。文末附 完整代码、界面工程与数据集构建/标注/划分说明,便于读者复现实验并开展二次开发。
功能效果展示视频 YOLOv5至YOLOv12升级:个人防具检测系统的设计与实现(完整代码+界面+数据集项目)
文章目录
- [1. 前言综述](#1. 前言综述)
- [2. 数据集介绍](#2. 数据集介绍)
- [3. 模型设计与实现](#3. 模型设计与实现)
- [4. 训练策略与模型优化](#4. 训练策略与模型优化)
- [5. 实验与结果分析](#5. 实验与结果分析)
-
- [5.1 实验设置与对比基线](#5.1 实验设置与对比基线)
- [5.2 量化对比结果(n-type 与 s-type)](#5.2 量化对比结果(n-type 与 s-type))
- [5.3 曲线结果与现象解释(收敛性、PR 与阈值选择)](#5.3 曲线结果与现象解释(收敛性、PR 与阈值选择))
- [6. 系统设计与实现](#6. 系统设计与实现)
-
- [6.1 系统设计思路](#6.1 系统设计思路)
- [6.2 登录与账户管理](#6.2 登录与账户管理)
- [7. 下载链接](#7. 下载链接)
- [8. 参考文献(GB/T 7714)](#8. 参考文献(GB/T 7714))
1. 前言综述
施工与工业现场的安全合规具有强约束属性,但传统依赖巡检员目测与事后抽查的流程往往难以覆盖"多工点、强动态、遮挡频繁"的真实作业节奏,因而把个人防具(PPE)使用状态转化为可度量、可追溯、可实时响应的视觉信号,成为智能安全管理的重要切入点。1 (World Health Organization) 现有流行病学与职业卫生统计也提示,职业暴露带来的死亡负担与长期健康损害依旧显著,且相当比例来自可通过工程控制、制度执行与PPE合规共同降低的风险场景。2 (World Health Organization) 因此,在安全帽、反光背心/工装、护目镜/口罩、手套等典型防护要素上实现可部署的自动检测与统计,不仅对应监管"可见、可查、可追责"的合规需求,也为班组级即时纠偏、企业级风险画像与培训评估提供数据基础。
从研究脉络看,早期安全视觉监测多依赖人工设计特征与规则推断,面对尺度变化、背景杂乱、光照剧烈变化时,模型鲁棒性与跨场景泛化很难保障;深度学习把"特征学习"内化到网络端到端优化,使施工安全视觉逐步从"可用原型"走向"工程化系统"。围绕施工安全的计算机视觉综述研究指出,现场视频数据的获取条件复杂、标签成本高、业务闭环牵涉管理流程,导致安全视觉系统在可靠性、可解释性与落地协同方面仍存在明显瓶颈。3 (ScienceDirect) 进一步的安全科学视角强调,视觉算法不只是识别工具,还应与安全管理传统(行为安全、系统安全、文化与制度)建立可操作的映射关系,否则难以把"检测结果"转化为"管理动作"。4 (ScienceDirect) 与此同时,建设领域更广义的计算机视觉研究综述也表明,安全管理、进度监控、质量巡检等任务的共同难点在于场景高度非结构化与目标类别长尾分布,工程部署需要兼顾实时性、鲁棒性与可维护性。5 (Springer)
在PPE检测方向,国外较早的代表性工作已将单阶段检测网络用于安全帽与反光背心等要素的实时合规判定,并在工程场景中讨论了摄像机视角、遮挡与实时性之间的权衡。6 (ScienceDirect) 随着"仅检测PPE"向"判定穿戴状态"演进,研究开始引入实例分割与跨帧跟踪,将PPE与人员建立关联关系,从而更接近现场安全员的判读逻辑。7 (OUP Academic) 系统性综述进一步总结了PPE合规自动化的热点:多类别小目标、遮挡与姿态变化、跨场景域偏移,以及合规判定规则与模型输出之间的结构化融合问题。8 (Springer) 面向工业级复杂环境的最新研究也开始把目标检测与人体姿态估计联合起来,通过关键点约束与去重分配机制增强遮挡条件下"PPE---人员"的正确匹配,从而在召回与F1等指标上获得更稳定的收益。9 (ScienceDirect)
国内研究在安全帽等强监管目标上推进较快,围绕小目标、密集与遮挡的工程痛点,常采用轻量化主干、多尺度融合、注意力与更稳健的回归损失进行改造,并结合跟踪策略降低视频流漏检。比如有工作在YOLOv5框架中引入简化Transformer增强全局信息建模,结合改进的Deep SORT提升遮挡与多目标视频场景的容错能力,并通过BiFPN式的融合改善尺度变化适应性。10 (Journal of Engineering Science) 也有研究从工程部署出发,采用Ghost卷积降低计算量,引入坐标注意力抑制复杂背景干扰,并以改进的IoU类损失提升预测框回归质量,从而在兼顾精度的同时提升帧率表现。11 (Journal of Engineering Science) 进一步地,基于更轻量检测骨架(如YOLOv7-tiny)的改进工作通过增强ELAN式特征提取、叠加轻量注意力与小目标检测层,并配合WIoU类损失强化对密集小目标与遮挡目标的刻画,强调在算力受限条件下获得速度---精度平衡。12 (Microelectronics and Computers)
| 代表性工作 | 任务与算法侧重点 | 数据与场景 | 优点概述 | 主要局限 |
|---|---|---|---|---|
| 6 | 单阶段检测做PPE合规识别 | 施工现场图像/视频 | 实时性强,工程流程清晰 | 遮挡与人员关联判定不足 |
| 7 | 实例分割+跟踪,输出穿戴状态 | 自建视频流与标注帧 | 更贴近"人---PPE"关系建模 | 标注成本高,跨场景仍需适配 |
| 9 | 检测+姿态估计联合,遮挡下分配去重 | 多工业场景数据 | 遮挡条件下关联更稳 | 系统复杂度与算力需求上升 |
| 10 | YOLOv5改造:Transformer/跟踪/BiFPN | 公开+跟踪数据集 | 强化全局与尺度适应,漏检降低 | 工程实现链条更长 |
| 11 | YOLOv5轻量化+注意力+改进回归损失 | 多场景自采集 | 速度与精度兼顾,利于部署 | 类别扩展与域偏移仍敏感 |
| 12 | YOLOv7-tiny改造:轻量注意力+小目标层 | 复杂工地密集场景 | 算力受限下保持可用性能 | 复杂PPE组合场景需更强建模 |
从技术难点上看,PPE检测属于典型的"多尺度小目标+强遮挡+强背景干扰"任务:安全帽、手套等目标在远景监控里经常只有几十像素量级,且与人体目标存在强依附关系,单纯的框检测容易在姿态变化或遮挡时产生错配;多尺度特征表达与融合因而成为检测器稳定性的基础能力之一。13 (CVF Open Access) 此外,现场数据还存在长尾类别、穿戴不规范(半戴、反戴、遮挡佩戴)、夜间与逆光、雨雾粉尘等退化因素,导致训练集与部署域之间的分布差异显著,评价指标也需要同时关注精度、召回与实时延迟对业务闭环的影响。
在检测器演进方面,YOLOv5的工程化实现推动了单阶段检测在工业与安防中的普及,使"可训练、可部署、可复现"的训练---推理范式更加成熟。14 (Zenodo) 近期工作则进一步把注意力机制更系统地引入实时检测网络设计,强调在保持高吞吐的前提下提升特征交互与长程依赖建模能力,为复杂场景下的小目标与遮挡鲁棒性提供新的结构手段。15 (arXiv) 老思在本文(博客)中将上述研究与工程需求对齐:围绕PPE合规检测这一明确任务,在统一数据与评估口径下系统对比YOLOv5至YOLOv12的性能与部署代价,并给出可直接运行的桌面端系统实现(PySide6界面、多源输入、阈值可调、结果可视化与导出、SQLite账号与历史持久化);同时配套整理数据集与训练脚本,尽量降低复现与二次开发门槛。
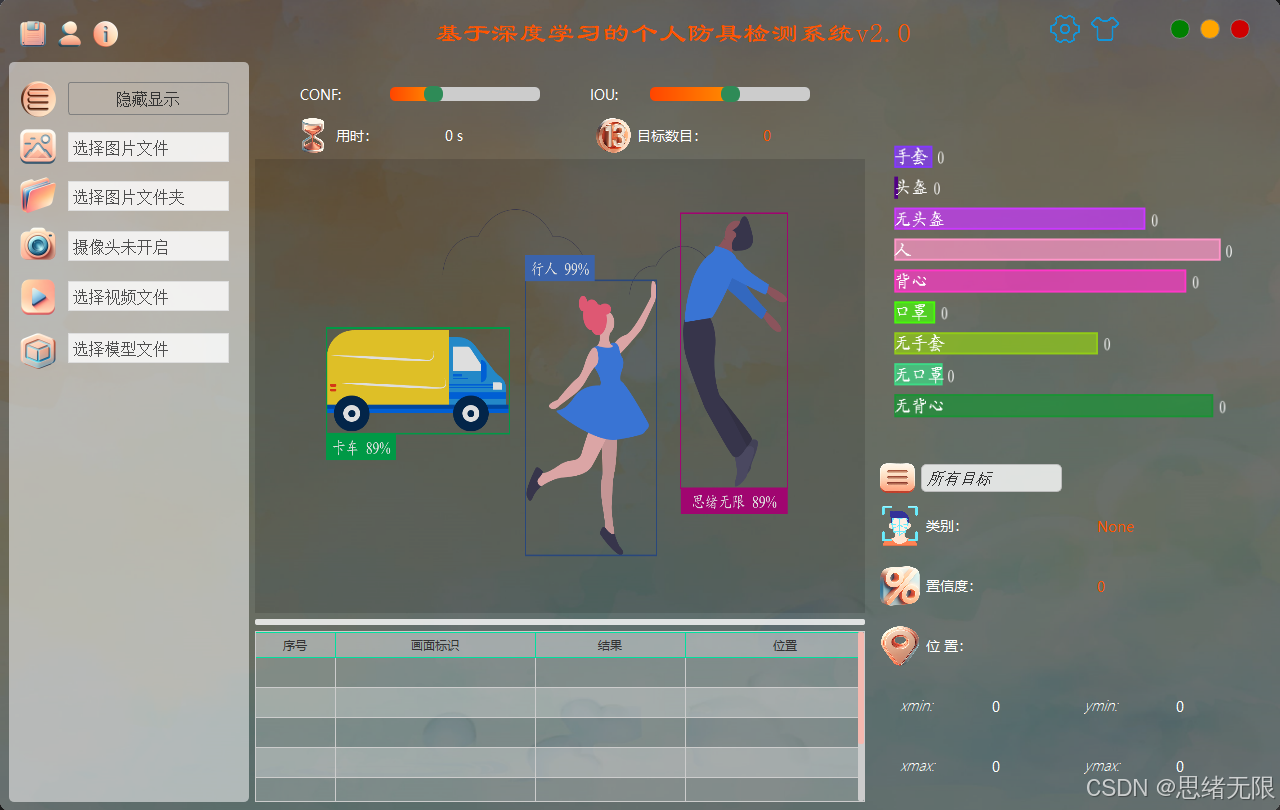
主要功能演示:
(1)启动与登录:启动进入登录页,支持注册/登录;校验通过后加载用户配置与历史记录,进入主界面。
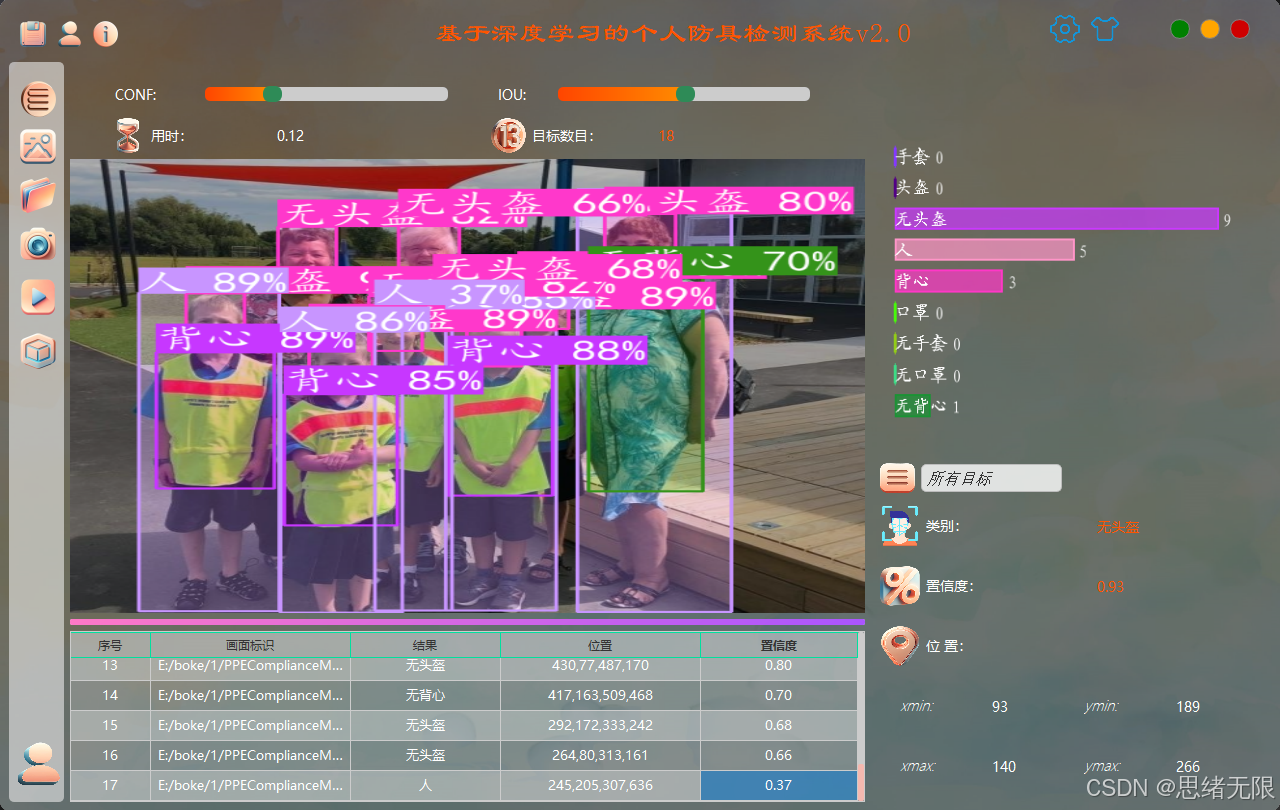
(2)多源输入与实时检测:支持摄像头/视频/图片/文件夹四种输入;实时或批量推理,输出检测框、类别、置信度与类别统计;Conf/IoU可随时调节并即时生效。
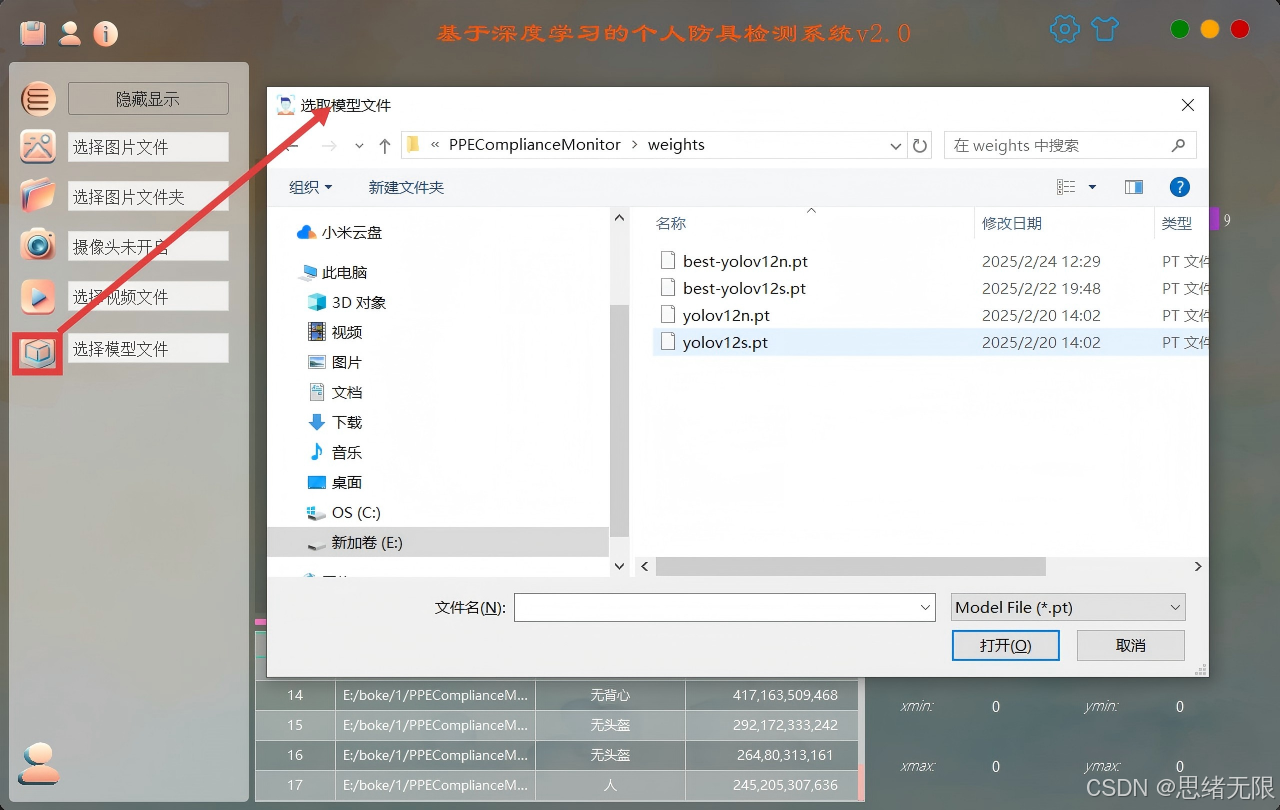
(3)模型选择与对比演示:内置YOLOv5--YOLOv12并支持导入自训练权重;同一输入源下快速切换模型,对比检出效果与推理速度,并展示FPS/耗时与统计差异。
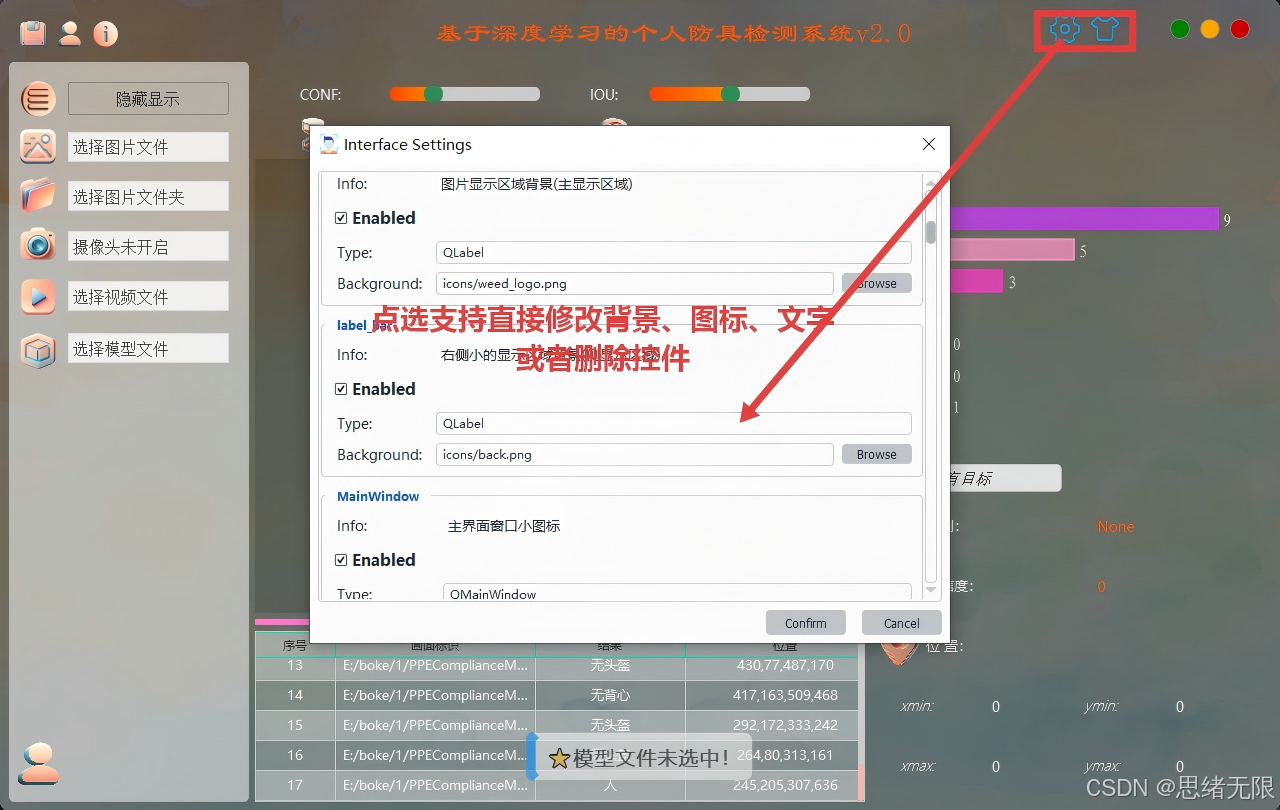
(4)主题修改功能:一键切换浅色/深色与主色调,支持背景与图标样式调整;主题按用户保存到SQLite,切换后无需重启即可生效。
2. 数据集介绍
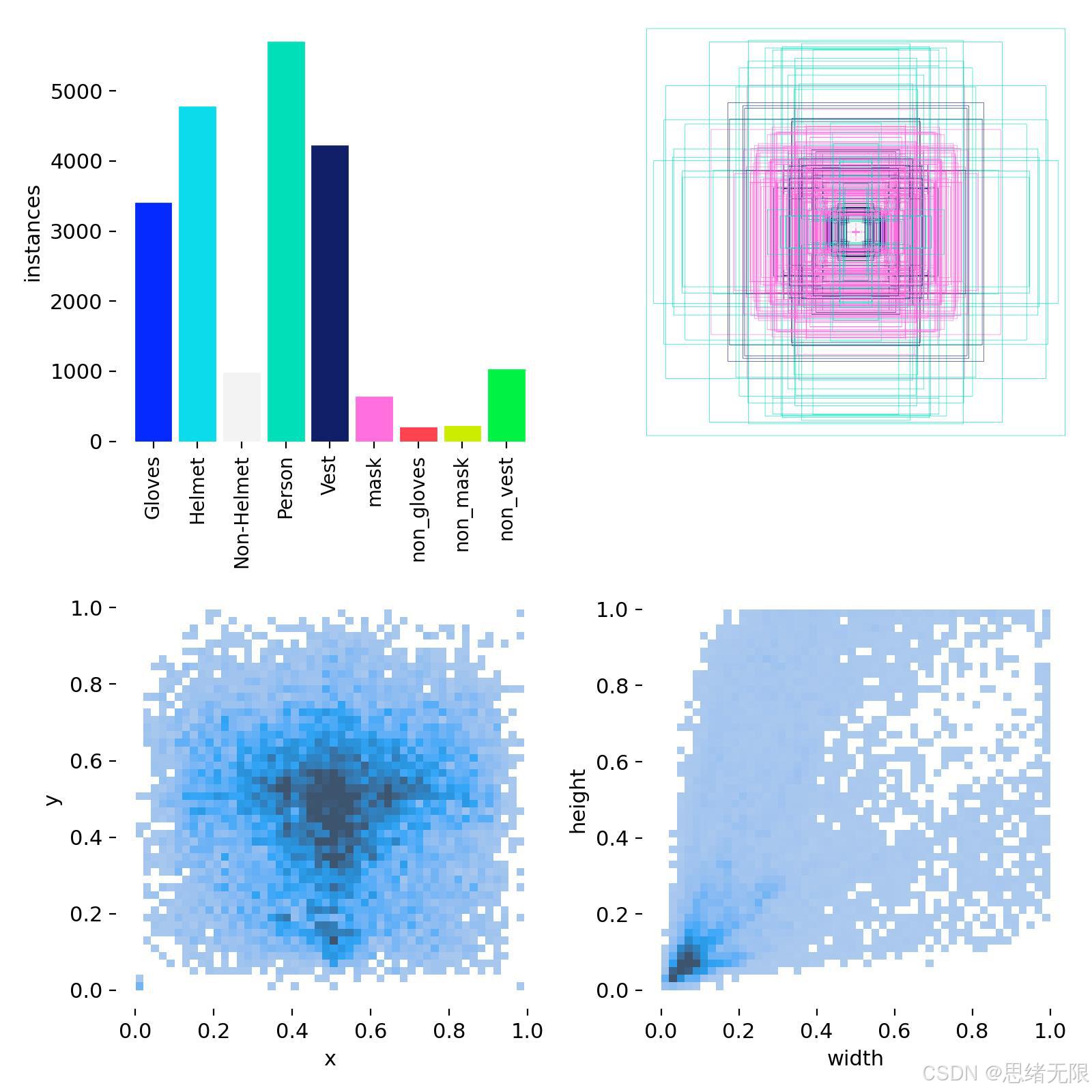
本项目围绕施工与工业场景的PPE合规检测构建专用数据集,样本覆盖"人员主体---防具佩戴---防具缺失"三类语义关系,便于在同一检测框架中同时输出"是否佩戴"与"缺失告警"两类信息。数据集共包含 4,713 幅图像,其中训练集 4,287 幅、验证集 385 幅、测试集 41 幅,整体划分更偏向训练侧(约 90.96% / 8.17% / 0.87%),符合工程实践中"以提升模型泛化为主"的构建取向,但也意味着测试集较小,最终指标可能受样本波动影响更明显。类别体系共 9 类,分别为 Gloves(手套)、Helmet(头盔)、Non-Helmet(无头盔)、Person(人)、Vest(背心)、mask(口罩)、non_gloves(无手套)、non_mask(无口罩)、non_vest(无背心),其中缺失类用于表达关键PPE未佩戴的监督信号,便于系统在推理端直接输出更贴近业务的告警对象。
python
Chinese_name = { "Gloves": "手套", "Helmet": "头盔", "Non-Helmet": "无头盔","Person": "人", "Vest": "背心", "mask": "口罩","non_gloves": "无手套","non_mask": "无口罩", "non_vest": "无背心"}
从标注统计图与分布热图可以看出,Person、Helmet、Vest、Gloves 为高频类别,mask 与各类缺失标签样本相对更少,呈现典型长尾分布;同时,目标中心点 ( x , y ) (x,y) (x,y) 的密度主要集中在图像中部附近,这与监控视角下"人员通常位于画面中心区域"的采集习惯一致。框尺度分布方面,宽高 ( w , h ) (w,h) (w,h) 在小尺寸区域密度更高,并向大尺寸形成长尾,说明数据同时包含远景小目标(如口罩、手套)与近景大目标(如人员、背心)并存的情况;这类分布往往对检测器的多尺度表达与小目标召回更敏感。为对齐YOLO训练接口,标注采用 YOLO TXT 归一化格式(以图像宽高为基准归一化 x , y , w , h x,y,w,h x,y,w,h),图像在训练/推理阶段通常统一缩放到 640 × 640 640\times 640 640×640(可按实验配置调整),并配合常见的数据增强(如随机翻转、颜色扰动、Mosaic 等)提升对遮挡与光照变化的鲁棒性;其中提供的训练拼图示例也直观反映了Mosaic增强在样本组织上的表现。
3. 模型设计与实现
面向施工与工业现场的PPE合规检测,模型侧的首要约束不是"离线指标做得多高",而是在遮挡、远景小目标、强光与逆光、多人密集与频繁运动模糊等条件下,持续给出稳定的检测框、类别与置信度,并把推理延迟控制在可用于实时告警的范围内。基于这一现实约束,博主将检测器选型收敛到单阶段实时检测范式:一方面,两阶段框架在小目标定位上具有优势,但在持续视频流与多路监控输入的吞吐要求下,整体时延与部署复杂度往往更难控制;另一方面,YOLO家族具备成熟的训练、推理与导出工具链,便于在同一工程框架内完成从YOLOv5到YOLOv12的横向对比与快速替换。本文默认以 YOLOv12n 作为主模型,但同时保留 YOLOv5--YOLOv12 的权重加载入口,用于在"更稳健的训练行为"与"更强的表征能力"之间按场景取舍;需要强调的是,Ultralytics 文档明确指出 YOLOv12 属于社区模型,可能出现训练不稳定、显存占用偏高以及CPU推理吞吐下降等问题,因此在强调可部署稳定性时可回退到更成熟的版本。 (Ultralytics Docs)
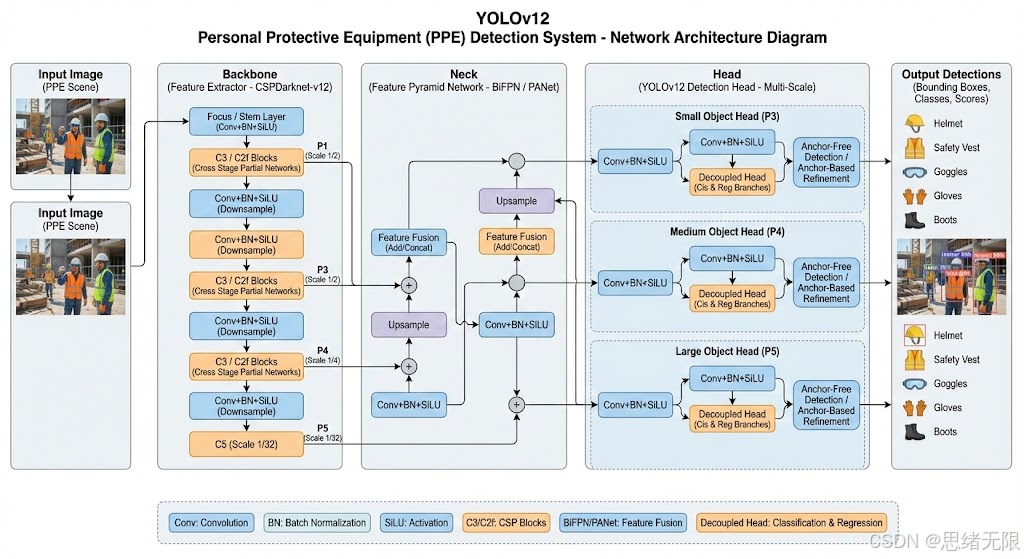
从"骨干网络选择"的角度看,检测器的特征提取部分本质上是一个可替换的视觉编码器:以 ResNet 为代表的残差网络更强调深层可优化性与语义表达,适合算力相对充足的服务器侧;以 MobileNet 为代表的深度可分离卷积更强调端侧效率,适合边缘设备实时推理;以 EfficientNet 为代表的复合缩放策略在参数量与精度之间通常具有更平滑的折中,适合对"同等算力下更高精度"敏感的场景。在本文工程中,模型主干并不直接采用上述分类网络作为Backbone,而是使用YOLO系列既有的高效骨干与特征聚合模块,但保留这种"编码器可替换"的认识有助于解释后续的工程决策:当目标转向更轻量部署时,优先选择YOLO的n/tiny尺度与更保守的结构,而非盲目追求复杂注意力堆叠。
在网络结构层面,YOLOv5的标准结构可以概括为"Backbone---Neck---Head"三段式:Backbone采用 CSPDarknet53 风格提取分层特征;Neck侧组合 SPPF 与 PANet 进行多尺度特征融合;Head输出多尺度检测结果,完成分类与框回归。 (Ultralytics Docs) 对于PPE任务,这种多尺度输出尤为关键:Person通常是大目标,而mask、Gloves在监控远景里常呈现为小目标,二者需要在不同stride的特征图上被同时稳定建模。YOLOv12在总体仍保持实时检测框架的前提下,把结构重心转向"注意力导向"的特征交互:其核心是 Area Attention ,将特征图划分为若干等分区域(文档给出的默认示例为4个区域),在区域级别计算自注意力以降低标准自注意力的计算与访存开销;同时引入 R-ELAN 改善特征聚合与优化路径,并结合 FlashAttention 降低显存访问成本,移除显式位置编码,并使用 7 × 7 7\times 7 7×7 可分离卷积作为"位置感知器"来隐式注入位置信息。 (Ultralytics Docs) 这种设计对于PPE场景的意义在于:当口罩、手套等目标被遮挡或仅局部可见时,区域级特征交互更可能稳定保留可辨识的局部证据;当背景纹理复杂时,更大的有效感受野有助于利用人体上下文抑制"把背景当防具"的误检。
任务建模方面,本文数据集包含9类目标:既包括"佩戴类"(Helmet、Vest、Gloves、mask)与主体类(Person),也包括"缺失类"(Non-Helmet、non_vest、non_gloves、non_mask)。这类"缺失类"在视觉学习上并非天然可学习语义,必须对应到可标注的可视区域(例如头部区域对应无头盔、上身区域对应无背心、手部区域对应无手套、口鼻区域对应无口罩),才能在检测框监督下形成稳定梯度信号;工程上其优势在于推理端可以直接输出"缺失告警框",减少额外规则推断的复杂度。模型输出形式可统一写为候选集合 ( b ^ i , o ^ i , p ^ i ) ∗ i = 1 N {(\hat b_i,\hat o_i,\hat p_i)}*{i=1}^{N} (b^i,o^i,p^i)∗i=1N,其中 b ^ i = ( x ^ i , y ^ i , w ^ i , h ^ i ) \hat b_i=(\hat x_i,\hat y_i,\hat w_i,\hat h_i) b^i=(x^i,y^i,w^i,h^i) 为归一化框参数, o ^ i \hat o_i o^i 为目标置信度(objectness), p ^ i \hat p_i p^i 为类别分布;推理阶段以置信度阈值 τ c \tau_c τc 与NMS的IoU阈值 τ ∗ i o u \tau*{iou} τ∗iou(在系统界面中对应Conf/IoU滑条)完成候选筛选与重叠抑制,最终输出检测框、类别与置信度,并同步更新类别计数用于合规统计。
损失函数层面,为兼容不同YOLO版本的实现差异,本文采用统一描述:总损失通常由分类项与框回归项构成,并在部分实现中加入更细粒度的分布回归约束,可写为
L = λ box L box + λ cls L cls + λ obj L obj + λ dfl L dfl . L=\lambda_{\text{box}}L_{\text{box}}+\lambda_{\text{cls}}L_{\text{cls}}+\lambda_{\text{obj}}L_{\text{obj}}+\lambda_{\text{dfl}}L_{\text{dfl}}. L=λboxLbox+λclsLcls+λobjLobj+λdflLdfl.
其中 L cls L_{\text{cls}} Lcls 多使用二元交叉熵(BCE)或其变体以适应多类别密集预测; L obj L_{\text{obj}} Lobj 用于约束前景与背景的置信度分离; L box L_{\text{box}} Lbox 常使用基于IoU的回归损失来提升定位质量。以CIoU为例,其形式可写为
CIoU = IoU − ρ 2 ( c , c ^ ) d 2 − α v , L box = 1 − CIoU , \text{CIoU}=\text{IoU}-\frac{\rho^2(\mathbf{c},\mathbf{\hat c})}{d^2}-\alpha v,\qquad L_{\text{box}}=1-\text{CIoU}, CIoU=IoU−d2ρ2(c,c^)−αv,Lbox=1−CIoU,
其中 ρ ( ⋅ ) \rho(\cdot) ρ(⋅) 表示预测框与真值框中心点距离, d d d 为两框外接矩形对角线长度, v v v 与 α \alpha α 用于约束长宽比一致性。对PPE这种小目标与细长目标并存的任务,IoU类损失的价值不仅在于提升定位精度,还在于稳定正负样本分配,减少"轻微偏移导致正样本丢失"的训练震荡。
工程实现上,老思将模型能力封装为 Detector 处理层:负责权重加载、输入预处理(letterbox缩放到 640 × 640 640\times 640 640×640 并保持宽高比)、推理与后处理(阈值筛选与NMS),并将输出映射为系统需要的数据结构(框坐标、英文类名与中文显示名、置信度、实例计数)。由于系统需要支持YOLOv5--YOLOv12一键切换,推理接口保持一致:仅替换权重与少量推理参数即可在同一输入源下复现对比;同时把Conf/IoU作为运行时可调参数,保证现场能够根据光照与遮挡快速调整"误检---漏检"折中。下面给出一段与工程一致的最小化伪代码,用于说明推理链路(并非完整项目代码):
python
# 伪代码:Detector 推理主流程(与UI解耦)
model = YOLO(weight_path) # 支持切换 yolov5~yolov12 权重
results = model.predict(
source=img,
imgsz=640,
conf=conf_thres,
iou=iou_thres,
verbose=False
)
for box in results[0].boxes:
cls_id = int(box.cls)
score = float(box.conf)
x1,y1,x2,y2 = map(int, box.xyxy[0])
en_name = names[cls_id]
zh_name = Chinese_name[en_name] # 例如 Helmet->头盔
# 输出:绘制框、更新统计、写入数据库/导出文件文中涉及的结构示意与可视化参考图,建议在博客中以"网络整体架构如下图所示""注意力热力图对比如下图所示"进行引用;对应的可直接下载链接如下(放在代码块中便于复制):
text
# YOLOv5 backbone-neck-head 结构示意(Ultralytics Docs 图)
https://cdn.jsdelivr.net/gh/ultralytics/assets@main/docs/yolov5-model-structure.avif
# YOLOv10/YOLOv11/YOLOv12 热力图对比(Ultralytics Docs 图)
https://cdn.jsdelivr.net/gh/ultralytics/assets@main/docs/yolo12-comparison-visualization.avif上述模型设计使系统在"统一的数据接口、统一的推理入口、统一的可视化与统计输出"下完成多版本YOLO的可复现对比,同时为后续训练策略与工程部署(ONNX/TensorRT导出、多源输入并行、数据库持久化)留出了清晰的结构边界。
4. 训练策略与模型优化
在PPE合规检测这一类"多人密集、遮挡频繁、小目标占比高"的任务中,训练策略的核心不是盲目拉高模型容量,而是让网络在真实监控域下形成稳定的判别边界,并把误检与漏检控制在可接受范围。老思在实现上采用"预训练权重初始化 + 统一分辨率输入 + 逐步减弱强增强"的训练主线:以COCO等通用数据预训练权重作为初始化,先快速对齐基础边缘与纹理特征,再在本数据集上完成域内适配;输入尺寸默认固定为 640 × 640 640\times 640 640×640,并使用 letterbox 保持宽高比,减少几何畸变带来的标签噪声。由于你的数据集中 Person/Helmet/Vest/Gloves 等高频类与 non_、mask 等相对低频类呈现长尾分布,训练中需要更关注低频类召回的稳定性,实践上可通过类别损失加权、启用 Focal 风格的难例调制(若框架支持)、以及在数据层面提高含缺失类样本的抽样概率来缓解"主类学得很快、尾类收敛很慢"的现象;同时在验证阶段重点观察 non_ 类的误检来源,通常与局部遮挡、人体姿态极端或标注边界不一致相关,需要通过更一致的标注规范与更稳健的增强策略共同消解。
训练流程上,推荐采用"强增强预热---稳定收敛---后期精修"的节奏控制。前期使用 Mosaic 等增强扩大组合空间,提高模型对背景与遮挡变化的鲁棒性;中后期逐步关闭强增强(例如在最后若干个 epoch 关闭 Mosaic),避免网络长期依赖非自然拼接分布而影响真实场景精度。学习率采用带 warmup 的余弦退火较为稳健,其典型形式可写为
η ( t ) = η min + 1 2 ( η 0 − η min ) ( 1 + cos π t T ) , \eta(t)=\eta_{\min}+\frac{1}{2}\left(\eta_{0}-\eta_{\min}\right)\left(1+\cos\frac{\pi t}{T}\right), η(t)=ηmin+21(η0−ηmin)(1+cosTπt),
其中 η 0 \eta_{0} η0 为初始学习率, T T T 为总训练步数或总epoch对应的步数;warmup阶段以线性或指数方式从较小学习率提升到 η 0 \eta_{0} η0,可显著降低初期梯度震荡与早期过拟合。为了在有限显存下提高吞吐,训练默认开启混合精度(FP16/AMP),并配合 EMA(指数滑动平均)稳定权重,其更新形式为
θ ema ← β , θ ema + ( 1 − β ) , θ , \theta_{\text{ema}} \leftarrow \beta,\theta_{\text{ema}}+(1-\beta),\theta, θema←β,θema+(1−β),θ,
其中 β \beta β 通常取接近 1 的值以获得更平滑的权重轨迹。你的数据集测试集仅 41 张,统计波动较大,因此更合理的做法是以验证集作为早停与调参依据,最终仅在确定训练策略后对测试集进行一次性汇报,保证对比结论更可信、可复现。
为了便于复现实验,本文给出一套在 RTX 4090 上常用且足够稳健的默认配置(具体数值可按显存与速度目标微调)。需要注意的是,这些参数的价值在于"可作为统一基线",后续做 YOLOv5--YOLOv12 横向对比时,应尽量保持数据、分辨率、增强与训练轮数一致,从而将差异尽可能归因于模型结构本身。
| 名称 | 作用(简述) | 数值 |
|---|---|---|
| epochs | 最大训练轮数 | 120 |
| patience | 早停耐心(验证无提升则停止) | 50 |
| batch | 批大小 | 16 |
| imgsz | 输入分辨率 | 640 |
| pretrained | 加载预训练权重 | true |
| optimizer | 优化器选择 | auto |
| lr0 | 初始学习率 | 0.01 |
| lrf | 最终学习率占比 | 0.01 |
| momentum | 动量系数 | 0.937 |
| weight_decay | 权重衰减 | 0.0005 |
| warmup_epochs | 预热轮数 | 3.0 |
| mosaic | Mosaic增强强度/概率 | 1.0 |
| close_mosaic | 训练后期关闭Mosaic轮数 | 10 |
| device | GPU | RTX 4090 |
模型优化在本文中分为"训练侧优化"与"部署侧优化"两条线并行推进。训练侧重点在于稳定收敛与泛化:对长尾类别优先保证召回,必要时在不改变主干结构的前提下调整分类项权重或难例调制,并通过更严格的标注一致性来降低标签噪声;对小目标则优先保证输入分辨率与多尺度特征的有效性,避免过早降低 imgsz 或过强裁剪导致目标信息丢失。部署侧则以减少推理时延与提升吞吐为目标,常见做法是将最优权重导出为 ONNX 并进一步转换为 TensorRT 引擎,启用 FP16 推理;若场景对延迟极敏感且硬件支持,也可考虑 INT8 量化(需要校准集并关注低频类的精度跌落)。在系统实现层,博主将这些优化封装为可切换的推理后端,使得同一套 PySide6 界面能够在"PyTorch 原生推理---ONNXRuntime---TensorRT"之间平滑切换,从而把训练得到的精度优势,尽可能以可控时延的形式兑现到实时告警链路中。
5. 实验与结果分析
5.1 实验设置与对比基线
本节在同一数据划分(Train 4287 / Val 385 / Test 41)与统一输入分辨率 640 × 640 640\times 640 640×640 的前提下,对 YOLOv5--YOLOv12 的多种尺度进行横向对比,重点关注两类工程属性:其一是检测质量(对合规告警而言更敏感的是召回与误检的平衡),其二是端侧实时性(包含预处理、推理与后处理在内的总时延)。你提供的测速记录表明,本次端侧耗时统计基于 NVIDIA GeForce RTX 3070 Laptop GPU(8GB) 的单次推理测量结果(表中分别给出了 Pre/Inf/Post 的分项耗时)。
评价指标采用 Precision、Recall、F1 与 COCO 风格 mAP。其基本定义为
P = T P T P + F P , R = T P T P + F N , F 1 = 2 P R P + R , P=\frac{TP}{TP+FP},\qquad R=\frac{TP}{TP+FN},\qquad F1=\frac{2PR}{P+R}, P=TP+FPTP,R=TP+FNTP,F1=P+R2PR,
其中 T P , F P , F N TP,FP,FN TP,FP,FN 分别为真阳性、假阳性与假阴性。mAP 侧重点在于综合不同召回水平下的精度表现:mAP50 表示 IoU=0.5 下的平均精度,mAP50-95 则在 0.50 , 0.55 , ... , 0.95 {0.50,0.55,\ldots,0.95} 0.50,0.55,...,0.95 上取均值,更严格地反映定位质量与框回归的稳定性。
5.2 量化对比结果(n-type 与 s-type)
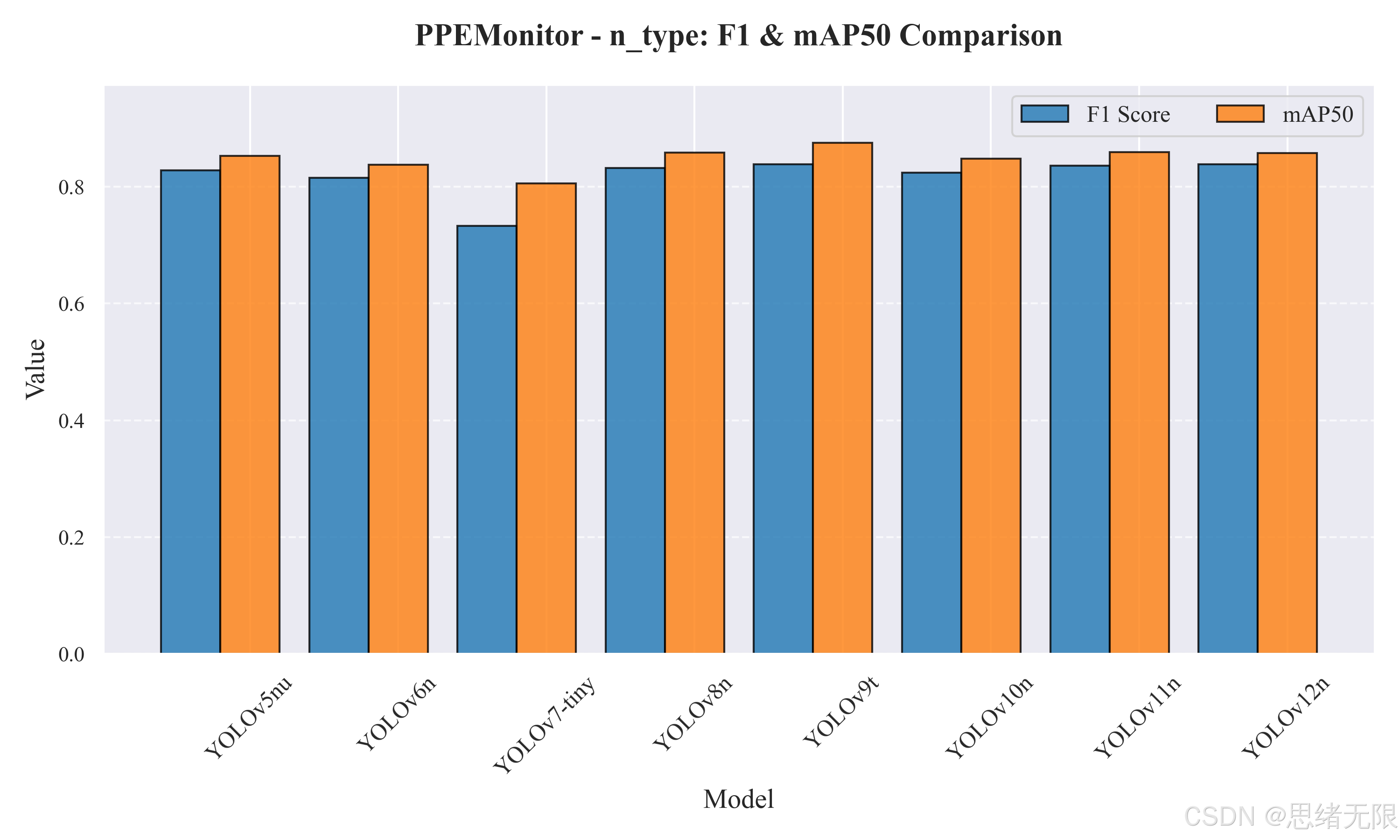
首先给出轻量级 n-type 的量化结果。如下表所示,YOLOv9t 在 mAP50(0.875)与 mAP50-95(0.585)上取得最高值,说明其整体检出能力与定位质量最强;而 F1 的最高值由 YOLOv12n 给出(0.839),其优势更多来自更高的 Precision(0.887),即在保持召回的同时进一步压低误检。速度方面,YOLOv8n 的总耗时最低(10.17 ms,约 98 FPS),YOLOv6n 也具有接近的实时性(10.34 ms,约 97 FPS),体现出在"稳定实时帧率优先"的部署场景下,v8n/v6n 仍是非常稳健的基线选择。与 YOLOv5nu 相比,YOLOv9t 的 mAP50 绝对提升约 0.022,而 YOLOv12n 的 F1 绝对提升约 0.011,但二者推理耗时相对更高(分别约 51 FPS 与 63 FPS),其收益更适合"单路或少路视频、精度优先"的场景。
| Model | Params(M) | FLOPs(G) | F1 Score | mAP50 | mAP50-95 | TotalTime(ms) | FPS |
|---|---|---|---|---|---|---|---|
| YOLOv5nu | 2.6 | 7.7 | 0.828 | 0.853 | 0.560 | 10.940 | 91.408 |
| YOLOv6n | 4.3 | 11.1 | 0.815 | 0.838 | 0.543 | 10.340 | 96.712 |
| YOLOv7-tiny | 6.2 | 13.8 | 0.733 | 0.805 | 0.476 | 21.080 | 47.438 |
| YOLOv8n | 3.2 | 8.7 | 0.832 | 0.859 | 0.568 | 10.170 | 98.328 |
| YOLOv9t | 2.0 | 7.7 | 0.838 | 0.875 | 0.585 | 19.670 | 50.839 |
| YOLOv10n | 2.3 | 6.7 | 0.824 | 0.848 | 0.568 | 13.950 | 71.685 |
| YOLOv11n | 2.6 | 6.5 | 0.836 | 0.859 | 0.570 | 12.970 | 77.101 |
| YOLOv12n | 2.6 | 6.5 | 0.839 | 0.858 | 0.578 | 15.750 | 63.492 |
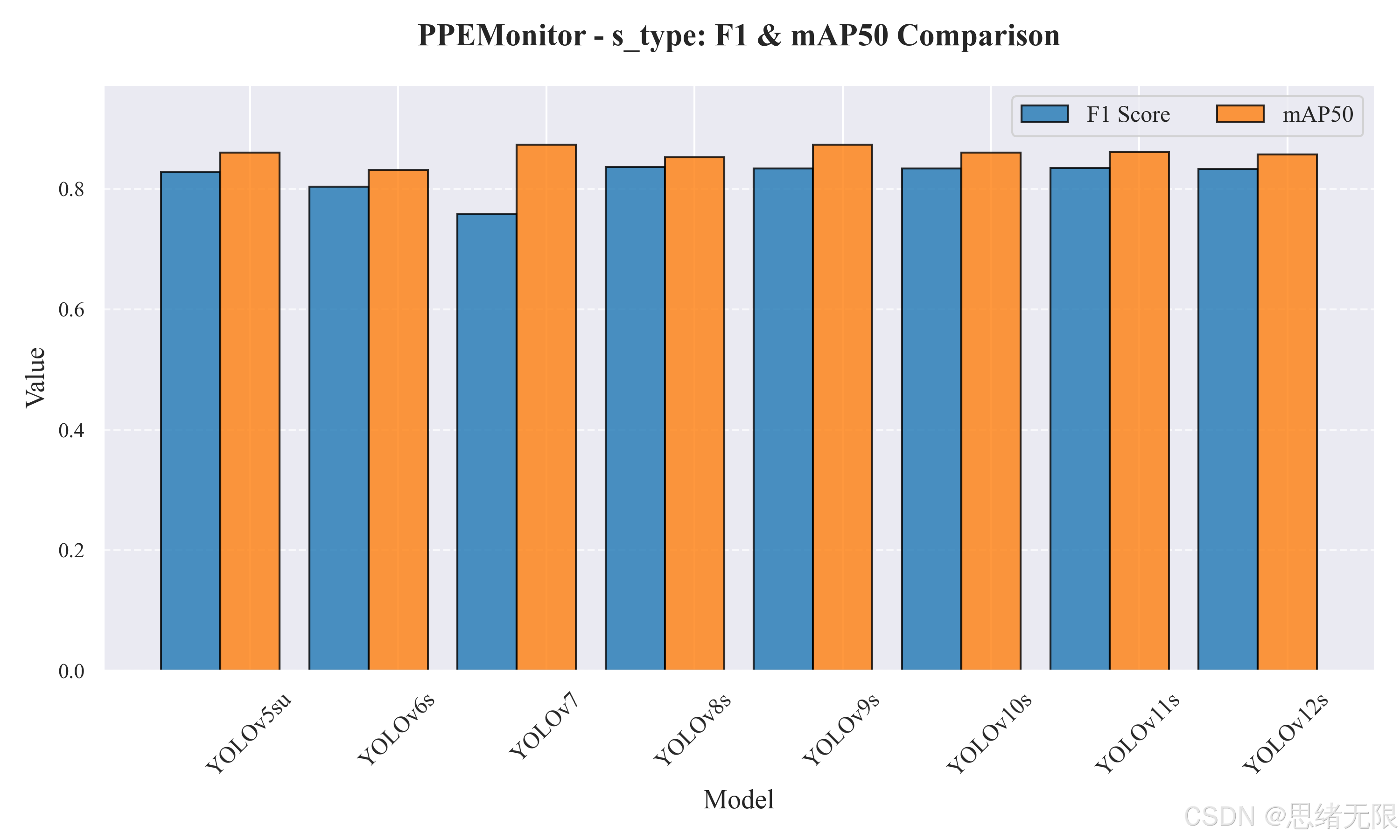
在 s-type 对比中,整体呈现"精度更高但速度代价更明显"的趋势。表中 YOLOv8s 给出了最高 F1(0.836),并且保持了最快的总耗时(11.39 ms,约 88 FPS),因此从"工程均衡"角度更接近可直接落地的主模型;YOLOv9s 在 mAP50-95 上达到最高(0.590),说明其框回归更稳健、定位更精细,但推理时延明显增加(约 45 FPS),更适合对定位质量更敏感且路数较少的部署。需要特别注意的是,YOLOv7 的 mAP50 最高(0.873),但 Precision 显著偏低(0.668),导致 F1 仅为 0.758,这类表现通常意味着模型倾向"多报不漏",在合规告警场景会带来更多误报,需要配合更严格的置信度阈值或更强的后处理约束才能用于上线。
| Model | Params(M) | FLOPs(G) | F1 Score | mAP50 | mAP50-95 | TotalTime(ms) | FPS |
|---|---|---|---|---|---|---|---|
| YOLOv5su | 9.1 | 24.0 | 0.828 | 0.860 | 0.562 | 12.240 | 81.699 |
| YOLOv6s | 17.2 | 44.2 | 0.804 | 0.831 | 0.549 | 12.260 | 81.566 |
| YOLOv7 | 36.9 | 104.7 | 0.758 | 0.873 | 0.573 | 29.520 | 33.875 |
| YOLOv8s | 11.2 | 28.6 | 0.836 | 0.853 | 0.567 | 11.390 | 87.796 |
| YOLOv9s | 7.2 | 26.7 | 0.833 | 0.873 | 0.590 | 22.170 | 45.106 |
| YOLOv10s | 7.2 | 21.6 | 0.834 | 0.860 | 0.586 | 14.190 | 70.472 |
| YOLOv11s | 9.4 | 21.5 | 0.835 | 0.861 | 0.584 | 13.470 | 74.239 |
| YOLOv12s | 9.3 | 21.4 | 0.833 | 0.857 | 0.575 | 16.740 | 59.737 |
与上述表格对应的 F1 与 mAP50 柱状对比图如图所示:n-type 中 YOLOv9t 的 mAP50 优势最明显,而 YOLOv12n 的 F1 略占优;s-type 中各模型 mAP50 更接近,但 F1 的差异能更直接反映"误报控制能力"。
n-type 对比图 :
s-type 对比图 :
5.3 曲线结果与现象解释(收敛性、PR 与阈值选择)
从收敛过程看,mAP50 随 epoch 的变化曲线(如下图所示)表明各模型在前 10--20 个 epoch 内快速建立可用检测能力,并在约 40--60 epoch 后逐步进入平台期;其中个别模型(例如 v10n)在早期爬升更慢,但后期能追平到与其他模型相近的稳定区间,这更像是优化路径与正负样本分配策略差异带来的"学习节奏"变化,而非最终上限差异。
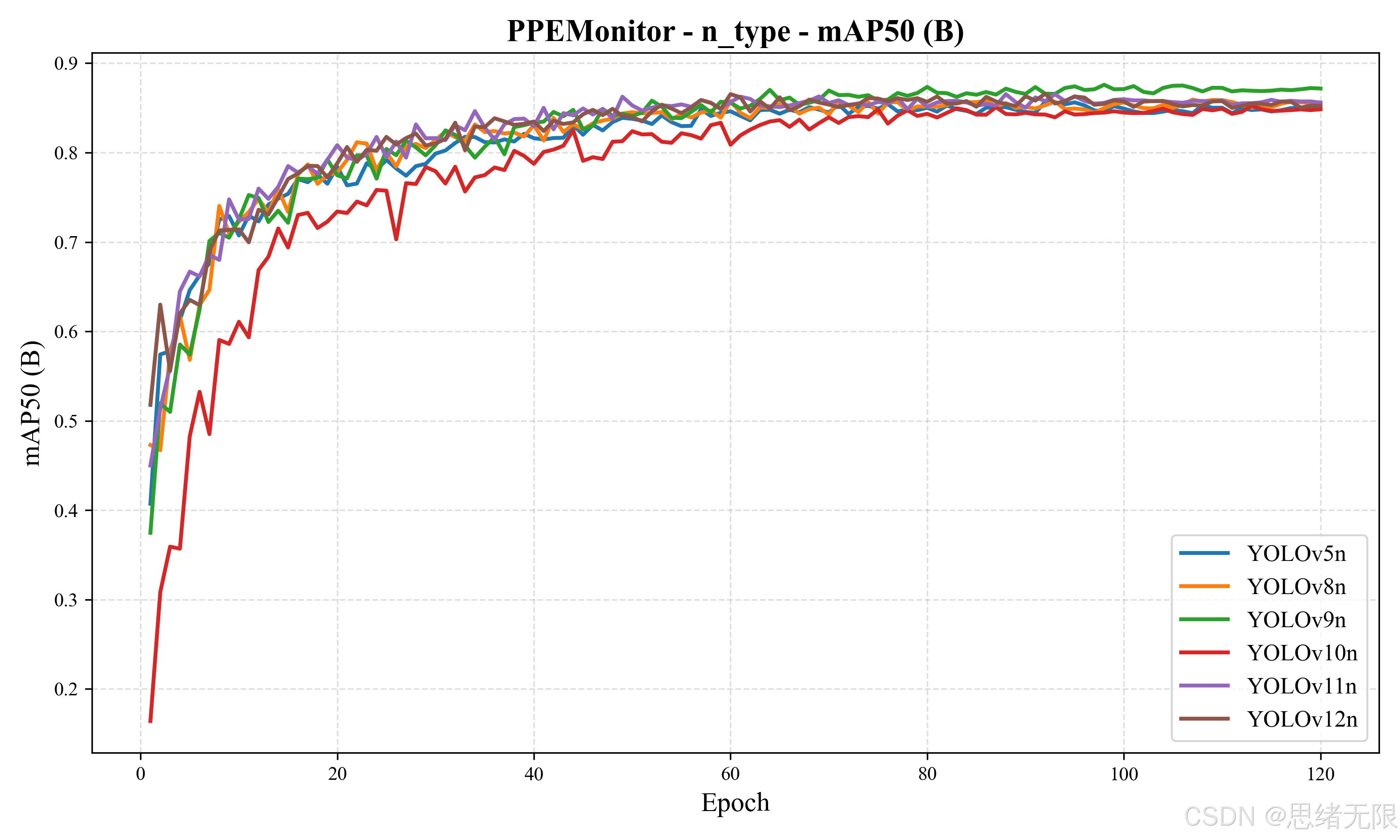
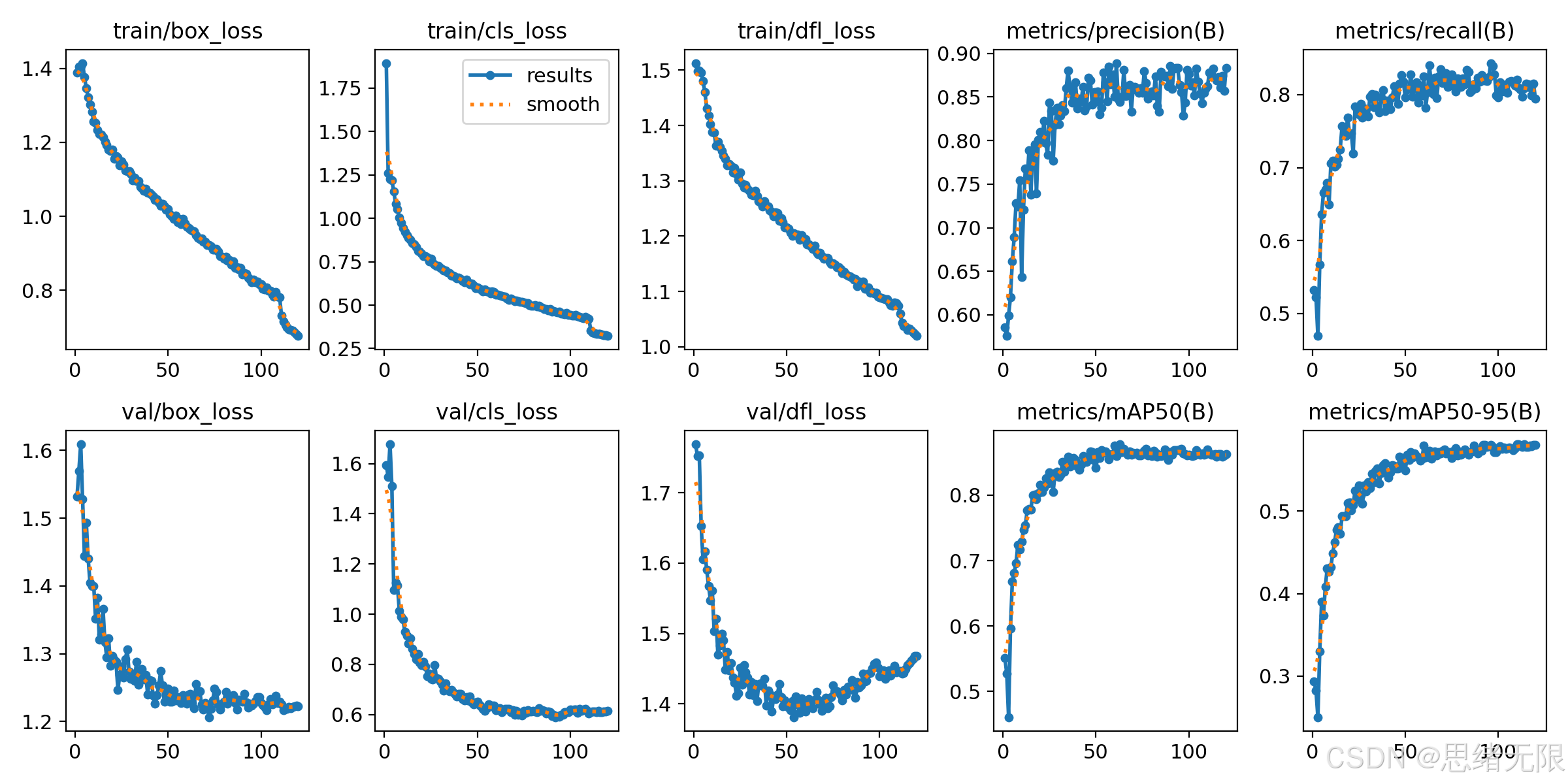
更细粒度的训练/验证损失与 Precision、Recall、mAP 曲线如图所示,整体呈现训练损失单调下降、验证指标稳定上升并在后期趋于饱和的形态,说明训练过程总体稳定;同时 val/dfl_loss 在后段略有抬升,提示后期继续训练的收益有限,更适合在平台期附近启用早停或降低学习率做短程精修。
训练曲线图:
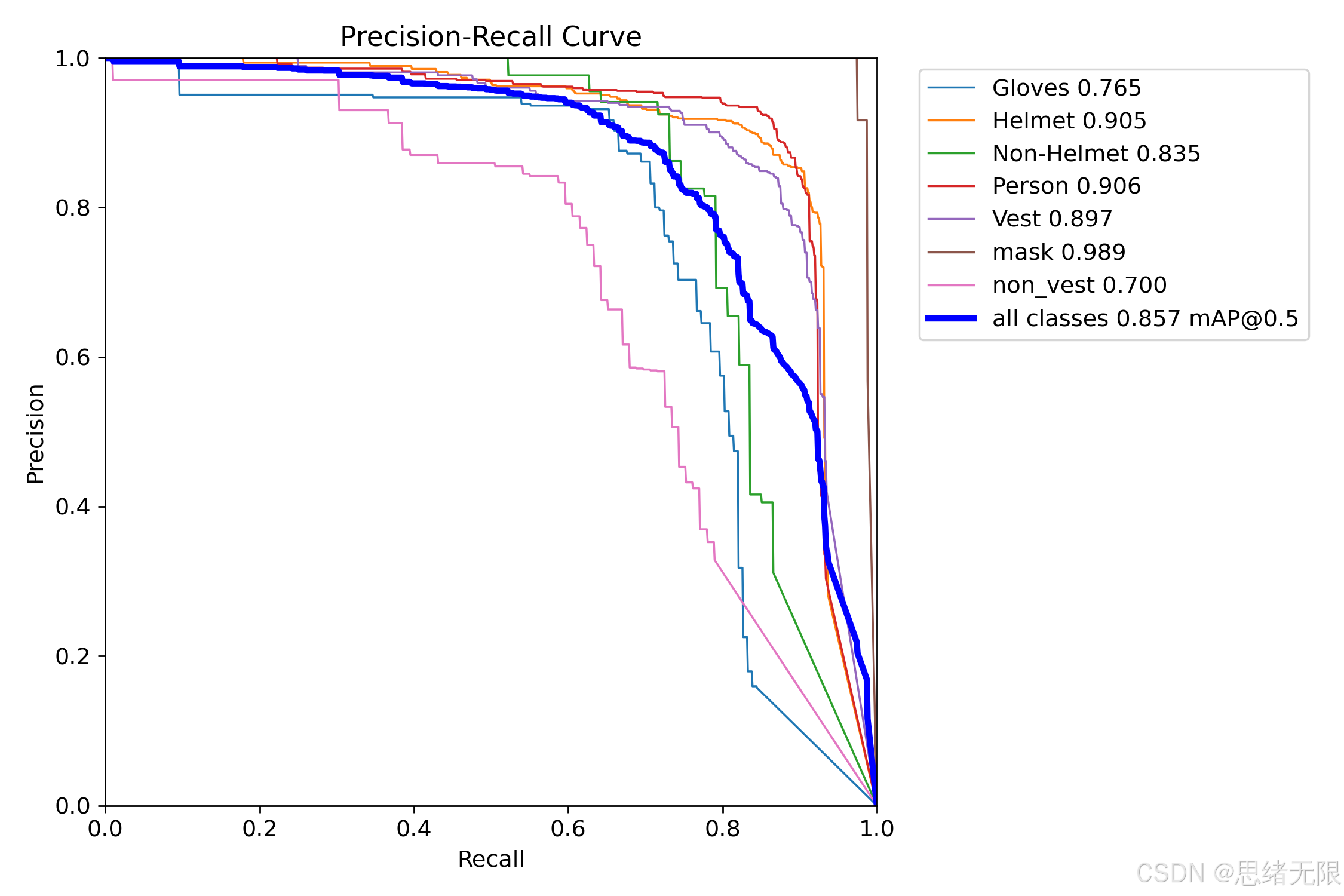
PR 曲线能更直观反映"召回提升时精度下降的速度"。平均 PR 曲线对比(如下图所示)显示,n-type 中 YOLOv9t 的曲线整体更靠近右上角,因此其 mAP50 最优;而 YOLOv6n、YOLOv7-tiny 曲线下降更快,对应更明显的精度损失。在单模型的类别级 PR 图中(如下图所示),mask、Helmet、Person、Vest 的 AP 明显高于 Gloves 与 non_vest,其中 non_vest(0.700)与 Gloves(0.765) 属于主要短板类别,这与其更易被遮挡、尺度更小、以及"缺失类标注边界更易产生歧义"等因素一致;因此若系统业务更关注"缺失告警"(如无背心),应在后续优化中优先补充该类样本、强化该类的难例增强,并在推理端结合 Person 框做空间约束以降低误检扩散。
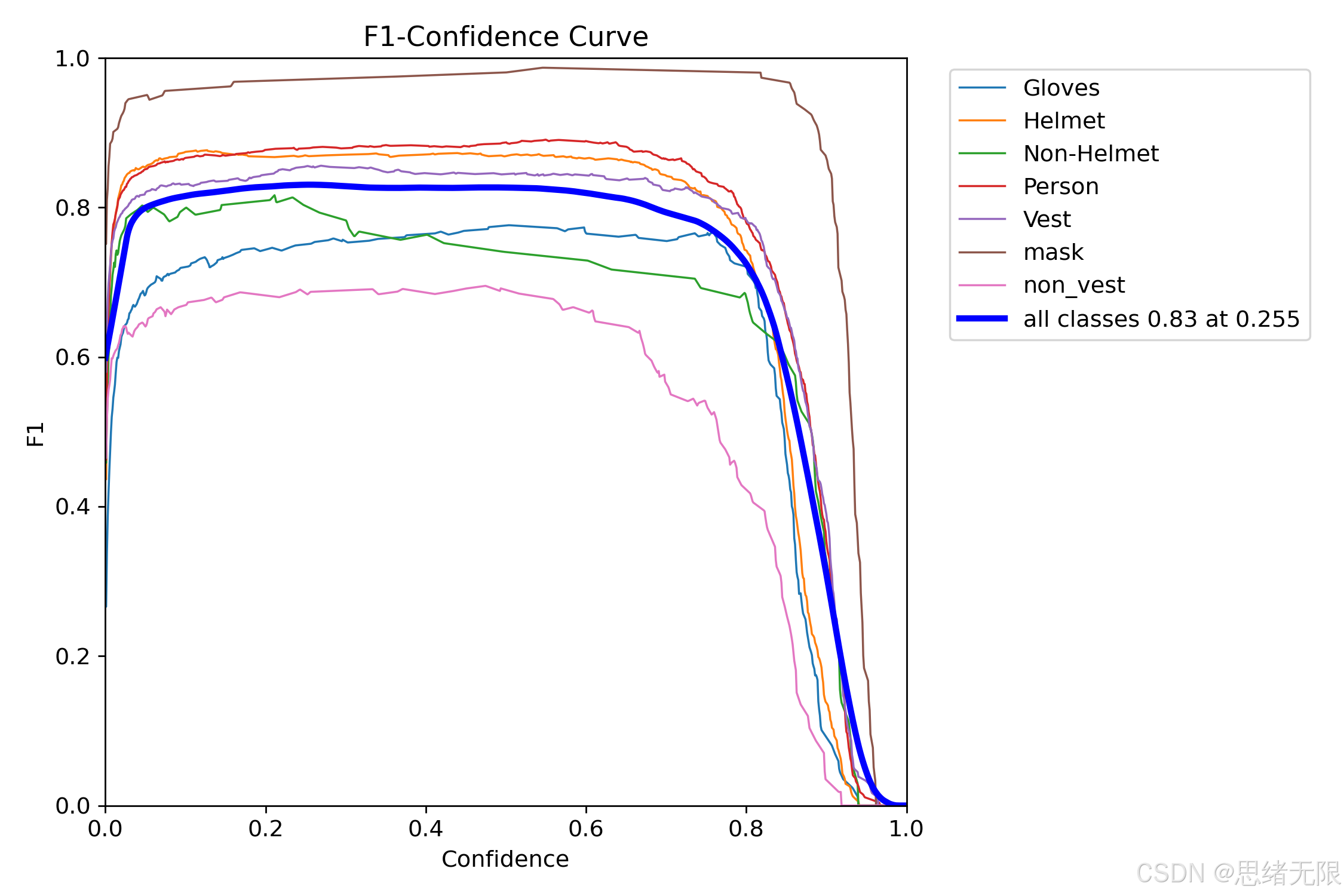
最后,阈值选择直接决定上线体验。F1-Confidence 曲线(如下图所示)给出了全类最优点 F1=0.83,Confidence≈0.255 ,这意味着在本数据集与当前后处理下,将默认置信度阈值设在约 0.25 能获得更均衡的误检与漏检表现;若现场更强调"宁可少报也不误报",可将阈值向 0.35--0.50 上调以换取更高 Precision,但代价是 non_* 类与小目标的漏检会更明显。
6. 系统设计与实现
6.1 系统设计思路
系统以桌面端实时检测为目标,整体采用"界面层---控制层---处理层"的分层组织方式,以降低推理逻辑与UI渲染的耦合度。界面层由 Ui_MainWindow 承载按钮、画布、表格、日志栏等交互控件;控制层由 MainWindow 负责状态机管理、槽函数调度与资源生命周期控制(输入源切换、播放控制、阈值更新、模型切换、主题切换等);处理层由 Detector 封装权重加载、预处理、YOLO推理、NMS与结果结构化输出,并向控制层回传检测框、类别、置信度与统计信息。为避免推理阻塞主线程,推理过程建议运行在 QThread 或 QRunnable 中,通过 Qt 信号槽把结果异步送回UI线程完成绘制与表格刷新,从而保证视频/摄像头场景下界面持续响应。
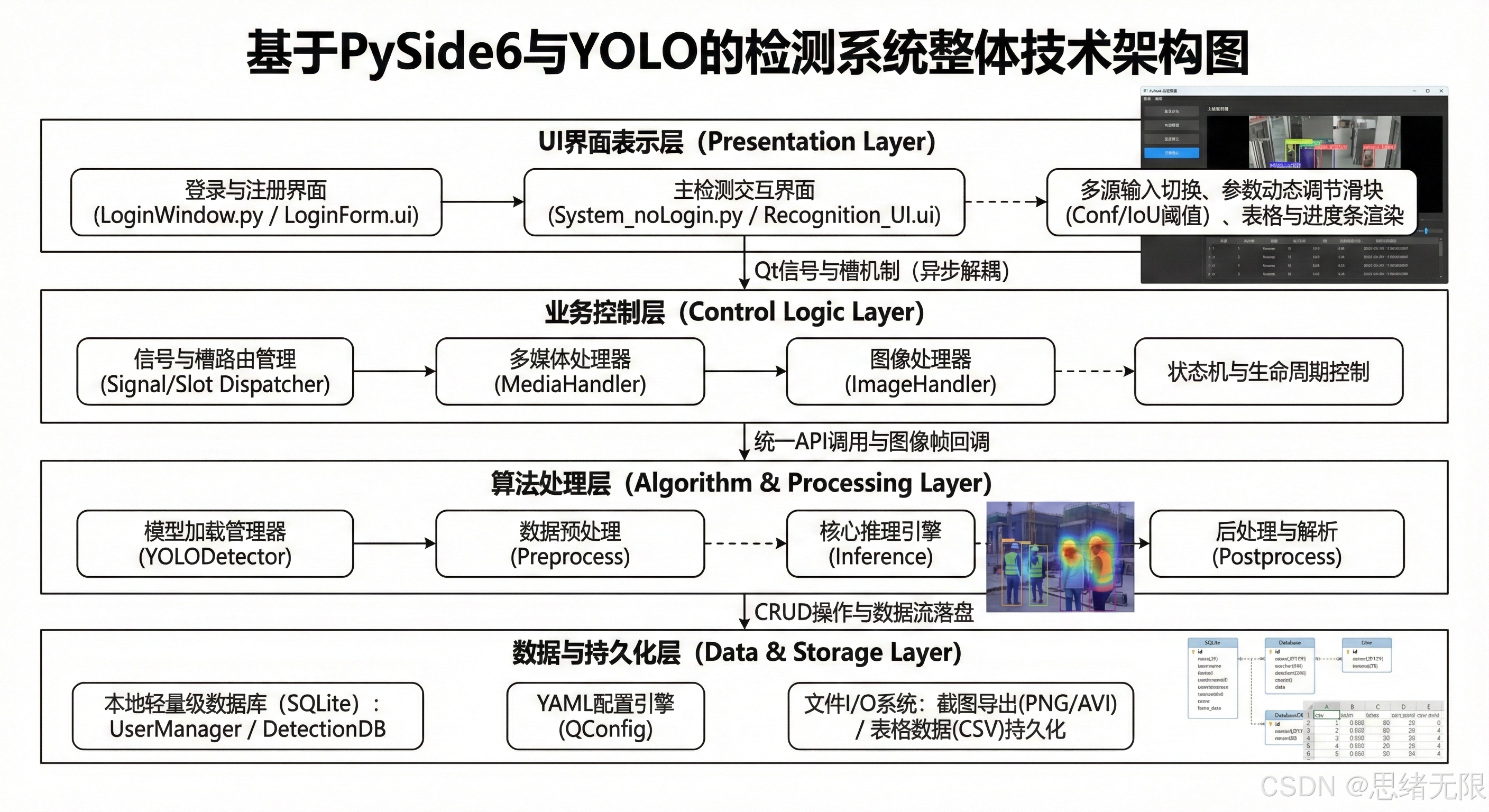
在输入组织上,系统将摄像头、视频、单图与文件夹统一抽象为"帧源(Frame Source)",对外提供一致的 next() 迭代接口,使后续的预处理与推理链路保持单一实现。预处理采用 letterbox 将输入缩放到 640 × 640 640\times 640 640×640 并保持宽高比,推理输出经阈值筛选与NMS得到最终检测框集合;随后在后处理阶段完成类别映射(英文ID到中文显示名)、目标数量统计以及"缺失类"告警提示的结构化封装。界面侧提供 Conf/IoU 的实时调节,其本质是运行时改变筛选阈值 τ c \tau_c τc 与NMS阈值 τ i o u \tau_{iou} τiou,以在不同工况下快速平衡误报与漏报,并把变化即时反馈到检测画面与统计面板,便于现场校准。
数据持久化与导出采用 SQLite 作为轻量级本地数据库:用户表用于登录注册与权限隔离,配置表用于保存每个用户的阈值、最近模型、主题等偏好,结果表用于保存检测记录(时间戳、输入源、类别计数、可选的截图路径/导出路径)。在工程实现上,检测结果的"保存到文件"与"写入数据库"被设计为可选分支,既支持仅做实时展示,也支持留存审计与离线复盘;并通过用户ID实现"用户独立配置与独立结果空间",使系统在多人共用同一设备时仍保持数据边界清晰。
图 系统流程图
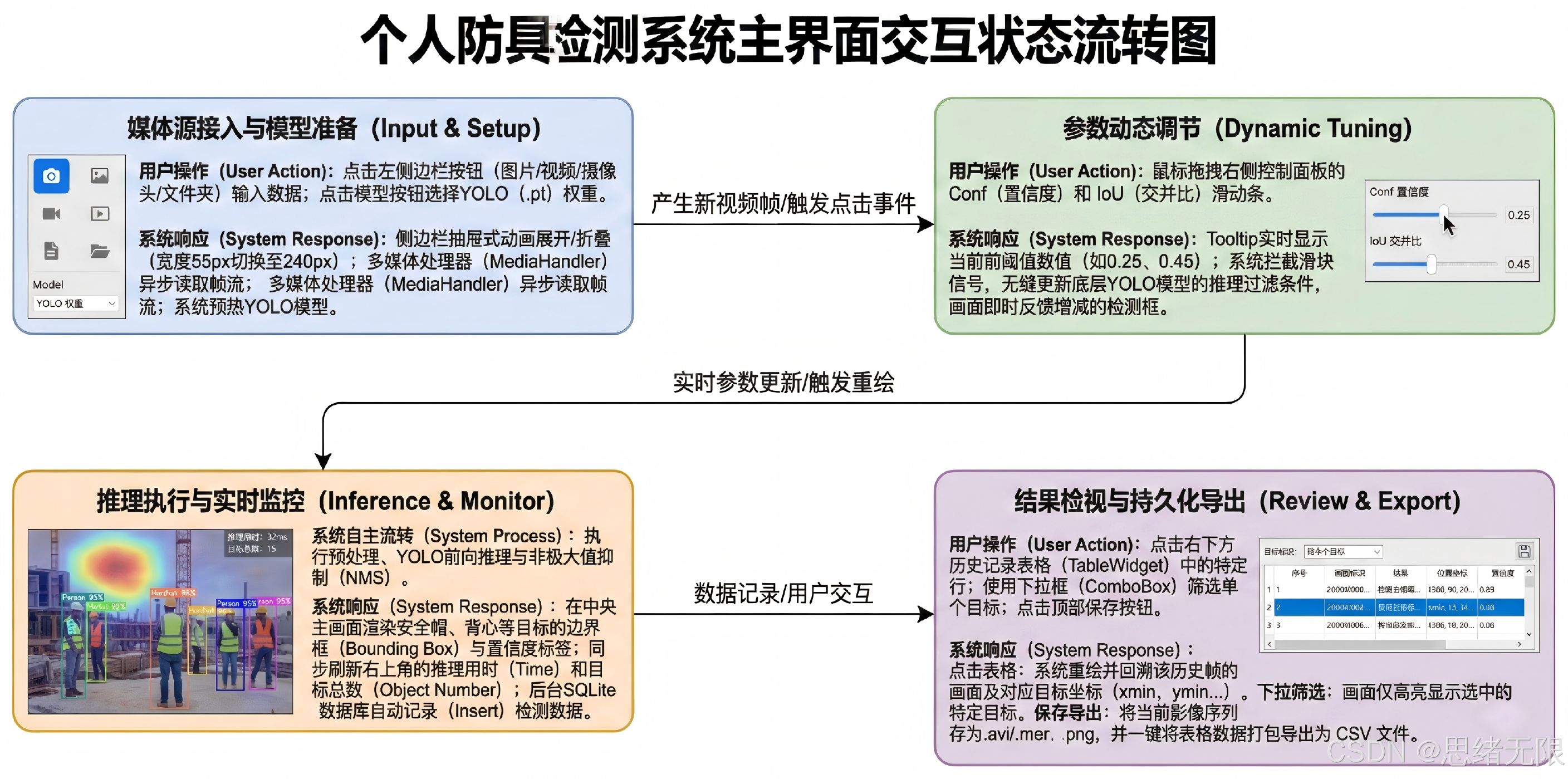
图注:系统从初始化到多源输入,完成预处理、推理与界面联动,并通过交互形成闭环。
6.2 登录与账户管理
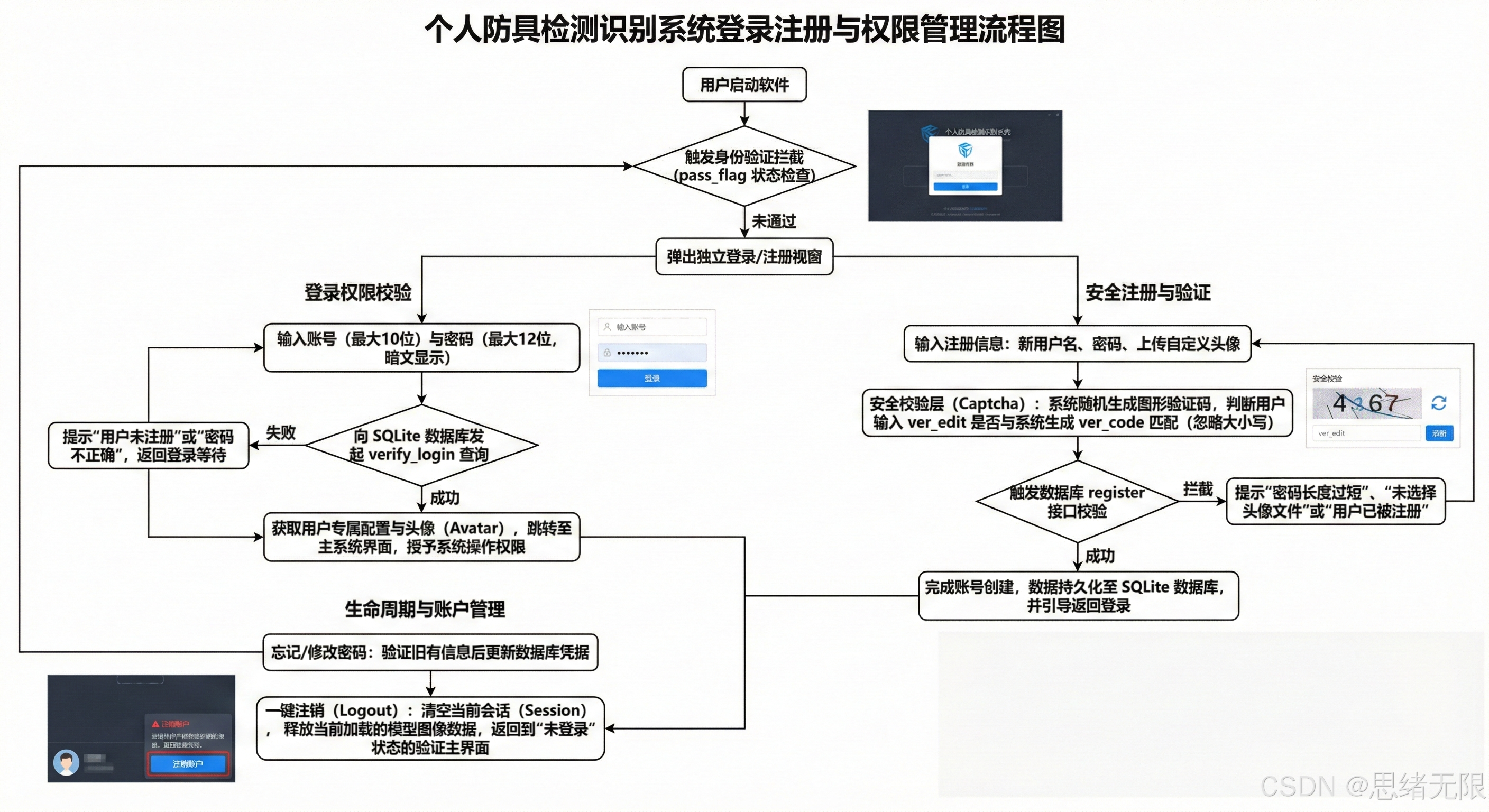
系统的账户体系以"登录态驱动业务态"为设计原则:启动后先完成注册/登录校验,获得 user_id 后再加载该用户的阈值、主题、最近模型与历史检测记录,使主界面一进入即处于可用配置;资料修改(头像、密码)被视为对用户元数据的在线更新,写回 SQLite 后立即在界面侧同步显示,从而保证"配置---展示---持久化"一致;注销或切换账号时,系统清理会话并回收与用户强相关的运行状态(当前输入源、结果缓存、导出路径等),再返回登录页重新建立隔离环境,这样既能满足多人共用设备的合规需求,也能与主检测流程自然衔接,实现个性化空间与结果留存的工程闭环。
7. 下载链接
若您想获得博文中涉及的实现完整全部资源文件 (包括测试图片、视频,py, UI文件,训练数据集、训练代码、界面代码等),这里见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:
完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见视频,项目完整文件请见项目介绍及功能演示视频处给出:➷➷➷
项目介绍地址: https://my.feishu.cn/wiki/ZBMswJLVpi9Emvk8ppjcGyeGnXf
功能效果展示视频 YOLOv5至YOLOv12升级:个人防具检测系统的设计与实现(完整代码+界面+数据集项目)
环境配置博客教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境配置教程;
或者环境配置视频教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境依赖配置教程
数据集标注教程(如需自行标注数据):数据标注合集
8. 参考文献(GB/T 7714)
1 World Health Organization, International Labour Organization. WHO/ILO joint estimates of the work-related burden of disease and injury, 2000--2016: global monitoring report R. Geneva: World Health Organization, 2021. (World Health Organization)
2 World Health Organization. WHO/ILO joint estimates: occupational health---Q&A EB/OL. World Health Organization, 2021. (World Health Organization)
3 Fang W, Ding L, Love P E D, et al. Computer vision applications in construction safety assuranceJ. Automation in Construction , 2020, 110: 103013. DOI:10.1016/j.autcon.2019.103013. (ScienceDirect)
4 Guo B H W, Zou Y, Fang Y, et al. Computer vision technologies for safety science and management in construction: A critical review and future research directionsJ. Safety Science , 2021, 135: 105130. DOI:10.1016/j.ssci.2020.105130. (ScienceDirect)
5 Xu S, Wang J, Shou W, et al. Computer Vision Techniques in Construction: A Critical ReviewJ. Archives of Computational Methods in Engineering , 2021, 28: 3383--3397. DOI:10.1007/s11831-020-09504-3. (Springer)
6 Nath N D, Behzadan A H, Paal S G. Deep learning for site safety: Real-time detection of personal protective equipmentJ. Automation in Construction , 2020, 112: 103085. DOI:10.1016/j.autcon.2020.103085. (ScienceDirect)
7 Lee Y-R, Jung S-H, Kang K-S, et al. Deep learning-based framework for monitoring wearing personal protective equipment on construction sitesJ. Journal of Computational Design and Engineering , 2023, 10(2): 905--917. DOI:10.1093/jcde/qwad019. (OUP Academic)
8 Vukicevic M, Petrovic P, Milosevic A, et al. A systematic review of computer vision-based personal protective equipment complianceJ. Artificial Intelligence Review , 2024. DOI:10.1007/s10462-024-10978-x. (Springer)
9 López L, Suárez-Ramírez J, Alemán-Flores M, et al. Automated PPE compliance monitoring in industrial environments using deep learning-based detection and pose estimationJ. Automation in Construction , 2025, 176: 106231. DOI:10.1016/j.autcon.2025.106231. (ScienceDirect)
10 白培瑞, 王瑞, 刘庆一, 等. DS-YOLOv5:一种实时的安全帽佩戴检测与识别模型J. 工程科学学报 , 2022. DOI:10.13374/j.issn2095-9389.2022.11.11.006. (Journal of Engineering Science)
11 侯公羽, 陈钦煌, 杨振华, 等. 基于改进YOLOv5的安全帽检测算法J. 工程科学学报 , 2022. DOI:10.13374/j.issn2095-9389.2022.12.07.002. (Journal of Engineering Science)
12 Zhao Y, Wu X, Feng Y, et al. Safety helmet wearing detection algorithm for complex construction sitesJ. Microelectronics & Computer , 2025. DOI:10.19304/J.ISSN1000-7180.2024.0545. (Microelectronics and Computers)
13 Lin T-Y, Dollár P, Girshick R, et al. Feature Pyramid Networks for Object DetectionC//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . 2017: 2117--2125. (CVF Open Access)
14 Jocher G, et al. ultralytics/yolov5 (software)EB/OL. Zenodo, 2020. DOI:10.5281/zenodo.3908559. (Zenodo)
15 Tian Y, Ye Q, Doermann D. YOLOv12: Attention-Centric Real-Time Object DetectorsEB/OL. arXiv:2502.12524, 2025. (arXiv)