深入理解 CAP 定理:分布式系统中的一致性、可用性与分区容错
文章目录
- [深入理解 CAP 定理:分布式系统中的一致性、可用性与分区容错](#深入理解 CAP 定理:分布式系统中的一致性、可用性与分区容错)
-
- [一、CAP 定理的起源](#一、CAP 定理的起源)
- [二、CAP 分别代表什么](#二、CAP 分别代表什么)
- 三、Consistency:一致性
- 四、Availability:可用性
- [五、Partition Tolerance:分区容错性](#五、Partition Tolerance:分区容错性)
- [六、CAP 的真正含义](#六、CAP 的真正含义)
- 七、为什么一致性与可用性会冲突
- [八、CP 系统:一致性优先](#八、CP 系统:一致性优先)
- [九、AP 系统:可用性优先](#九、AP 系统:可用性优先)
- [十、CA 系统是否存在](#十、CA 系统是否存在)
- [十一、CAP 与 ACID 的区别](#十一、CAP 与 ACID 的区别)
-
- [CAP 的一致性](#CAP 的一致性)
- [ACID 的一致性](#ACID 的一致性)
- [十二、CAP 与 BASE 理论](#十二、CAP 与 BASE 理论)
- [十三、现代系统如何平衡 CAP](#十三、现代系统如何平衡 CAP)
-
- [1. 可调一致性](#1. 可调一致性)
- [2. 多数派协议](#2. 多数派协议)
- [3. 分场景设计](#3. 分场景设计)
- 十四、常见误区
-
- [误区一:CAP 是三选二](#误区一:CAP 是三选二)
- [误区二:NoSQL 一定是 AP,SQL 一定是 CP](#误区二:NoSQL 一定是 AP,SQL 一定是 CP)
- [误区三:AP 一定比 CP 差](#误区三:AP 一定比 CP 差)
- 十五、架构实践建议
- 十六、总结
CAP 定理是分布式系统领域最经典、也最常被讨论的理论之一。几乎所有数据库、中间件、微服务架构、云原生系统,在设计高可用与数据一致性方案时,都会涉
及 CAP 的思想。
很多人知道 CAP 是"一致性、可用性、分区容错",但对它的真实含义、适用边界,以及工程实践中的落地方式理解并不深入。本文将从理论定义、证明背景、工程应用与常见误区几个层面,系统地介绍 CAP 定理。
一、CAP 定理的起源
CAP 理论最早由 Eric Brewer 在 2000 年提出,并在学术界引发广泛讨论。2002 年,Seth Gilbert 与 Nancy Lynch 对其进行了严格的数学证明,正式成为分布式系统中的基础理论。
CAP 讨论的核心问题是:
在一个可能发生网络分区的分布式系统中,系统是否能够同时保证强一致性与持续可用性?
结论是:不能。
二、CAP 分别代表什么
CAP 由三个概念组成:
- Consistency(一致性)
- Availability(可用性)
- Partition Tolerance(分区容错性)
但这三个词在分布式系统语境下有严格定义,不能按日常字面意思理解。
三、Consistency:一致性
CAP 中的一致性,并不是数据库事务 ACID 中的 Consistency,也不是"数据逻辑正确"。
它更准确地指的是:
所有客户端在任意时刻读取到的数据,必须是同一个最新版本。
系统对外表现得像只有一个副本,所有读写都发生在统一时间线上。
示例
假设系统有多个副本,初始值为:
x = 1
客户端 A 执行写操作:
x = 2
如果系统满足 CAP 中的一致性,那么任何后续读请求都必须返回:
x = 2
而不能返回旧值 1。
这类一致性通常对应分布式理论中的 线性一致性(Linearizability)。
四、Availability:可用性
可用性指的是:
每一个发送到正常节点的请求,都必须在有限时间内得到响应。
这里的重点是:
- 请求不能无限等待
- 服务不能因为内部协调而长期阻塞
- 即使返回的数据不是最新的,也必须给出结果
示例
某个数据库集群有 5 台机器,其中 2 台故障。只要还有节点正常运行,用户请求就应该得到响应。
五、Partition Tolerance:分区容错性
分区容错性指的是:
当节点之间网络通信异常时,系统仍然能够继续工作。
所谓网络分区,常见情况包括:
- 机房网络中断
- 节点之间丢包
- 延迟过高
- 路由故障
- 跨地域链路断开
在真实世界中,网络故障无法完全避免,因此分区容错并不是可选项,而是分布式系统的基本前提。
六、CAP 的真正含义
很多资料把 CAP 简化成"三选二",这并不准确。
更严谨的说法是:
当网络分区发生时,系统无法同时满足强一致性和高可用性。
也就是说:
- 如果没有分区,系统可以同时做到一致与可用
- 一旦发生分区,必须在 C 和 A 之间做权衡
因此在实际系统设计中,P 通常默认必须存在,真正的选择是:
- CP:一致性优先
- AP:可用性优先
七、为什么一致性与可用性会冲突
假设系统有两个节点:
- Node A
- Node B
初始余额:
balance = 100
此时 A 与 B 之间发生网络中断。
用户 1 向 A 发起扣款请求:
balance = 50
与此同时,用户 2 向 B 查询余额。
系统面临两种选择:
方案一:保证一致性(CP)
为了确保 B 不返回旧数据,B 必须拒绝请求或等待同步完成。
结果:
- 数据正确
- 用户可能超时
- 可用性下降
方案二:保证可用性(AP)
B 立即返回旧值 100。
结果:
- 用户请求成功
- 数据暂时不一致
这就是 CAP 的本质矛盾。
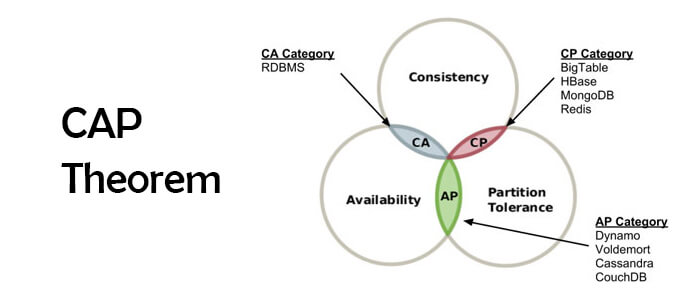
八、CP 系统:一致性优先
CP 系统在网络异常时宁可拒绝部分请求,也要保证数据正确。
常见策略:
- 多数派写入成功才提交
- Leader 不可用时暂停写操作
- 副本未同步前拒绝读取
典型场景
- 银行转账
- 库存扣减
- 订单支付
- 分布式锁
- 配置中心
常见系统
- ZooKeeper
- etcd
- HBase
- CockroachDB
- 使用多数写策略的 MongoDB
这些系统更适合对数据准确性要求极高的业务。
九、AP 系统:可用性优先
AP 系统在发生分区时,优先保证服务继续响应。
常见策略:
- 各节点独立提供服务
- 数据异步同步
- 冲突后续修复
典型场景
- 社交动态
- 点赞计数
- 推荐系统
- 日志收集
- 缓存系统
常见系统
- Cassandra
- Riak
- Dynamo 风格架构
- 某些 Redis 集群场景
这些系统适合海量访问、高并发、允许短暂不一致的业务。
十、CA 系统是否存在
理论上,单机数据库可以同时满足一致性与可用性,因为不存在网络分区问题。
但只要系统是分布式部署,网络故障就无法避免,因此严格意义上的 CA 分布式系统几乎不存在。
十一、CAP 与 ACID 的区别
很多初学者容易混淆两者。
CAP 的一致性
关注的是:
多个副本之间的数据是否一致
ACID 的一致性
关注的是:
事务执行前后是否满足业务约束
例如:
- 主键唯一
- 外键有效
- 余额不能为负数
两者解决的问题完全不同。
十二、CAP 与 BASE 理论
为了应对 AP 系统中的数据不一致问题,业界提出了 BASE 理论:
- Basically Available(基本可用)
- Soft State(软状态)
- Eventually Consistent(最终一致)
最终一致性的含义是:
系统允许短时间内数据不一致,但经过同步后最终会收敛一致。
常见例子:
- 缓存刷新
- 搜索索引更新
- DNS 传播
- 订单状态同步
十三、现代系统如何平衡 CAP
现实架构并不会简单地把系统归类为 CP 或 AP,而是按业务场景动态取舍。
1. 可调一致性
某些数据库允许开发者配置一致性级别,例如:
- ONE
- QUORUM
- ALL
这样可以在性能与一致性之间灵活选择。
2. 多数派协议
通过多数节点确认写入,既保证正确性,也提升容错能力。
典型算法包括:
- Paxos
- Raft
3. 分场景设计
同一系统不同功能采用不同策略:
- 下单接口:强一致
- 商品浏览:高可用
- 推荐服务:最终一致
十四、常见误区
误区一:CAP 是三选二
错误。
准确说法是:
网络分区发生时,在一致性与可用性之间二选一。
误区二:NoSQL 一定是 AP,SQL 一定是 CP
错误。
CAP 与数据库类型无直接关系,具体取决于系统实现方式。
误区三:AP 一定比 CP 差
错误。
很多互联网业务中,高可用远比强一致更重要。
十五、架构实践建议
设计系统时,不应简单问:
"这个系统是 CP 还是 AP?"
更应该问:
- 哪些数据必须强一致?
- 哪些功能允许延迟同步?
- 用户能接受多久的不一致?
- 故障发生时优先保数据还是保服务?
- 如何通过补偿机制修复异常状态?
这些问题比贴标签更重要。
十六、总结
CAP 定理并不是告诉我们如何设计系统,而是告诉我们系统设计的边界条件。
它提醒我们:
- 网络故障一定会发生
- 分布式系统不存在完美方案
- 一致性与可用性必须权衡
- 最优解永远取决于业务场景
真正优秀的架构设计,不是追求绝对 CP 或绝对 AP,而是在正确的地方做正确的取舍。