一、引言
这两天系统学习了一遍 RAG,原本以为它就是文档切片 + 向量检索 + 大模型回答这么一条标准流程,但真正从头到尾梳理下来之后,我发现事情没那么简单。
RAG 最有意思的地方,不是它用了什么新概念,而是它重新回答了一个很关键的问题:
当大模型面对企业知识、私有文档和最新资料时,怎么才能不靠猜,而是基于真实内容回答问题?
很多人第一次接触 RAG,都会先记住几个关键词:Embedding、向量数据库、检索、Rerank、Chunk
但如果这些概念没有被串成一条完整链路,就很容易变成每个词都认识,但整体还是有点模糊。
所以这篇文章,我想不只是罗列概念,而是尝试把 RAG 从头到尾重新讲清楚:
文档是怎么进入系统的?为什么一定要切片?检索为什么不只是向量搜索?为什么召回之后还要重排?RAG 真正难的地方到底在哪?
如果你也在学 Agent,希望这篇梳理能帮你把 RAG 真正串起来。
二、为什么大模型需要RAG?
先看一个最根本的问题:大模型已经这么强了,为什么还需要 RAG?
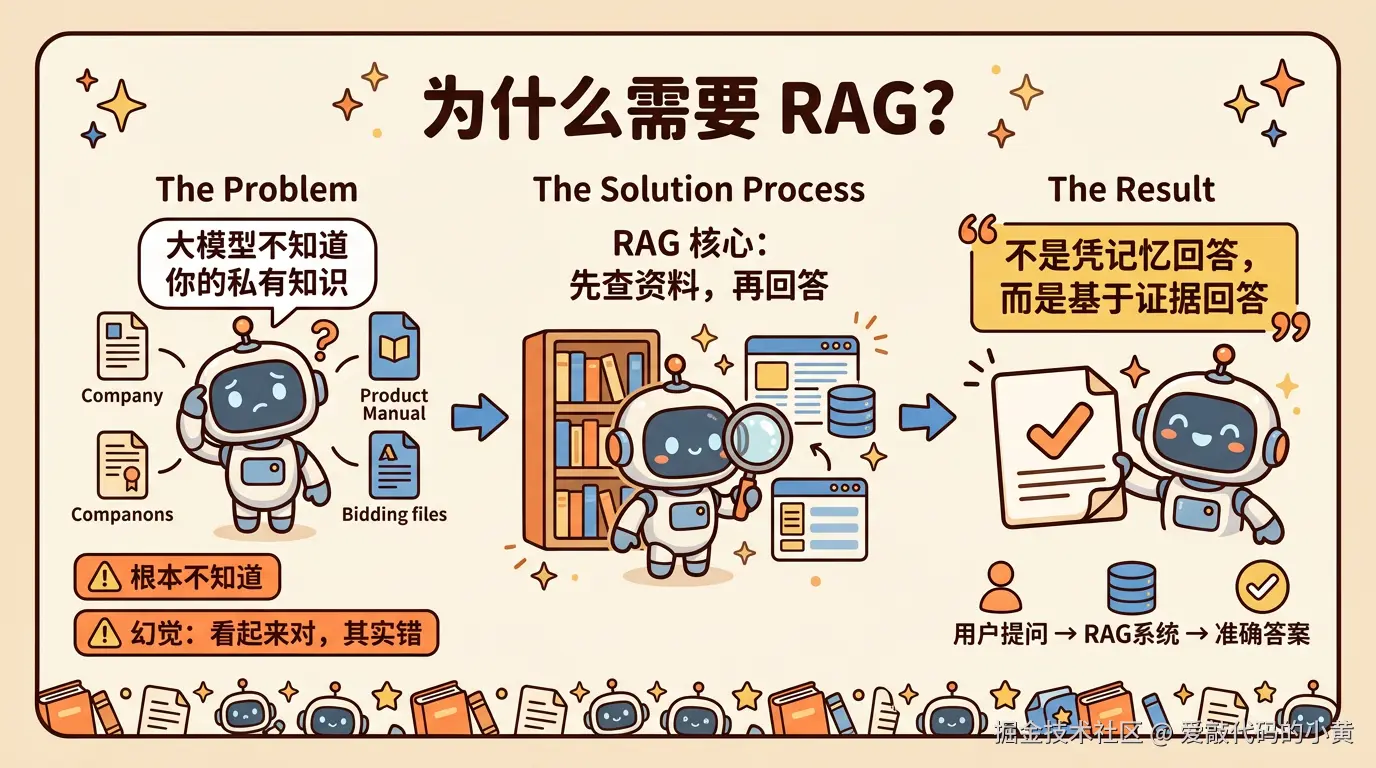
因为大模型再强,也不天然知道你的私有知识。
比如:
- 企业内部制度
- 产品说明书
- 招投标材料 这些内容,大模型本身并不会自动掌握。即使好像知道一些,也很难保证准确,更难保证是最新的。
于是问题就出现了:
- 它可能根本不知道
- 它也可能不知道,但仍然生成一个看起来很对的答案 后者,就是我们熟悉的幻觉。
而 RAG 的核心思路,就是让模型在回答之前,先去外部知识库里查资料,再基于资料作答。
所以,RAG 的本质可以概括成一句话:不是让模型凭记忆回答,而是让模型基于证据回答。
这也是为什么 RAG 特别适合企业知识库场景。企业真正需要的,往往不是一个会聊天的模型,而是一个能基于内部资料准确回答问题的系统。
三、RAG 到底是怎么跑起来的?
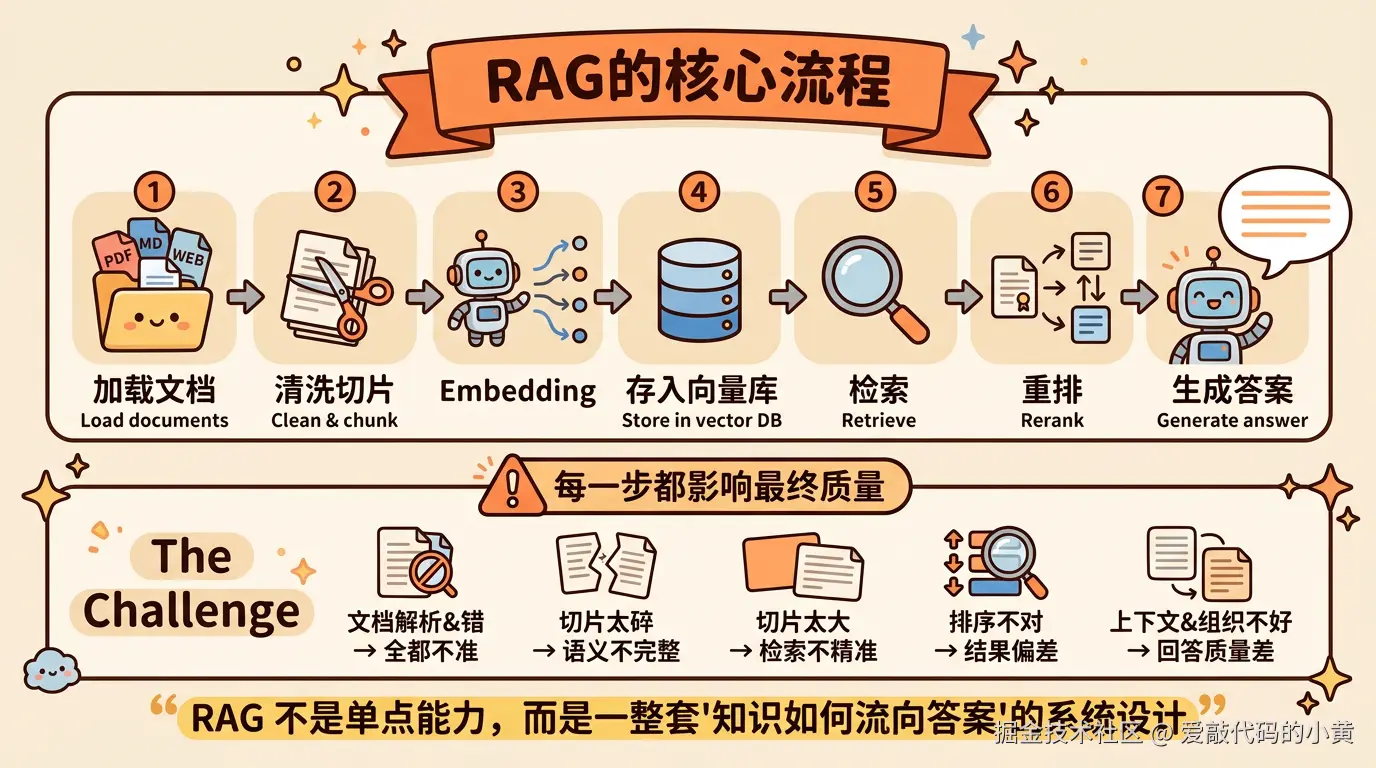
从整体流程看,一个完整的 RAG,大致是这样一条链路:
- 加载文档
- 对文档做清洗和切片
- 把文本块做 Embedding
- 存入向量数据库
- 用户提问时先做检索
- 对检索结果做重排
- 把最相关的上下文交给大模型生成答案
看起来不复杂,但真正难的是:这条链路里,每一步都会影响最终回答质量。
比如:
- 文档解析错了,后面全都不准
- 切片太碎,语义不完整
- 切片太大,检索不精准
- 召回到了,但排序不对
- 检索结果不错,但上下文组织得不好
所以,RAG 不是单点能力,而是一整套知识如何流向答案的系统设计。
四、第一步:先让知识进入系统
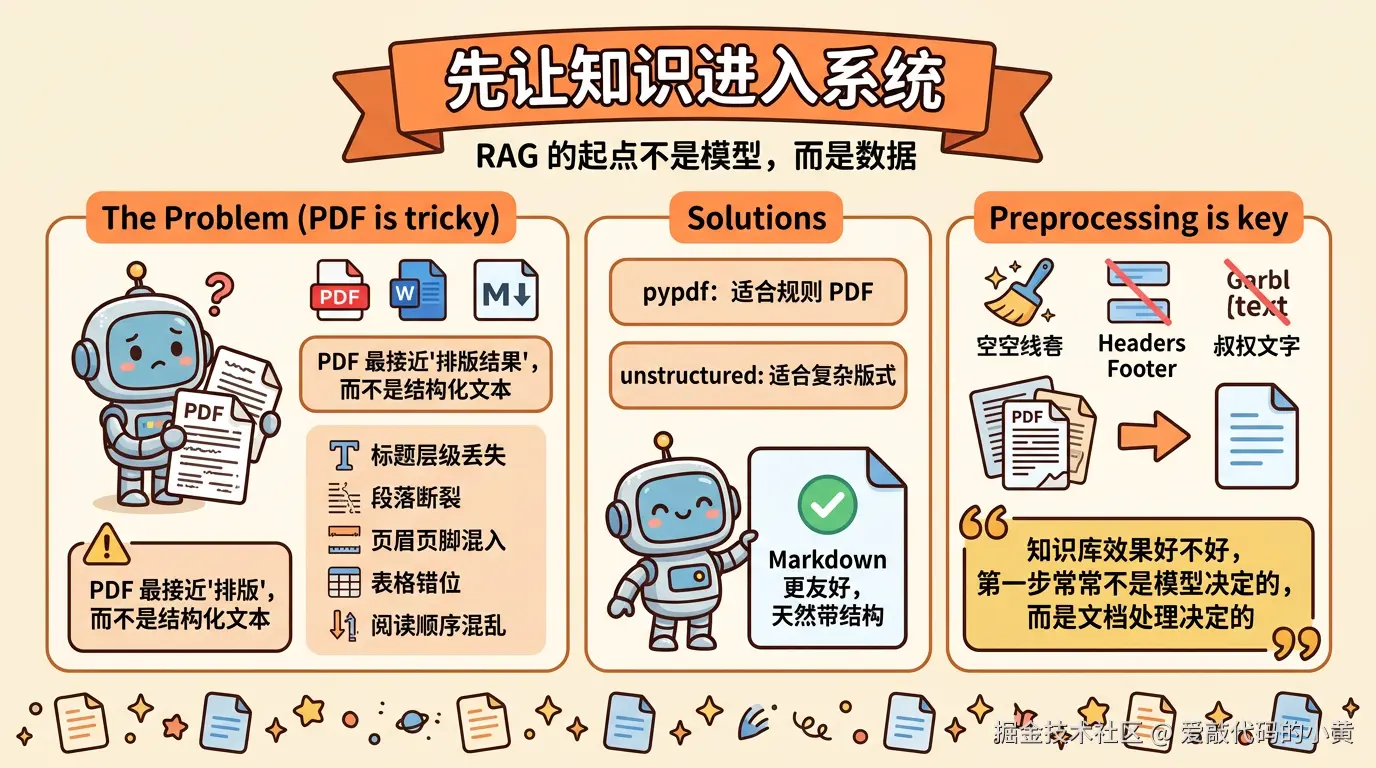
RAG 的起点不是模型,而是数据。
因为模型最终能回答什么,很大程度上取决于你给了它什么知识。现实里的知识源往往非常杂,常见的包括:PDF、Markdown、Word、网页等
其中最常见、也最麻烦的,通常是 PDF。
1. PDF 为什么麻烦?
因为 PDF 更接近排版结果,而不是天然结构化文本。
它抽取出来之后,经常会出现:标题层级丢失、段落断裂、页眉页脚混入正文等
所以,RAG 里的文档加载,绝不是把字读出来这么简单。更重要的是尽量保留结构。
常见做法比如:
- 用 pypdf 抽文本,适合相对规则的 PDF
- 用 unstructured 做更复杂的结构解析,适合版式复杂的文档 如果是 Markdown,会相对友好很多。因为它天然带有标题、段落、列表等结构信息,更适合进入后续流程。
2. 为什么预处理很关键?
因为原始文档通常不能直接进入知识库。
在正式切片前,往往还要做一层清洗,比如:去掉无效空行、去掉重复页眉页脚、清理乱码和特殊符号等
这些步骤看起来像基础工作,但其实非常重要。
后面做过滤检索、结果溯源、答案引用时,很多能力都依赖这些结构和元数据。
一句话来说就是:知识库效果好不好,第一步常常不是模型决定的,而是文档处理决定的。
五、为什么切片是 RAG 里最容易被低估的一步?
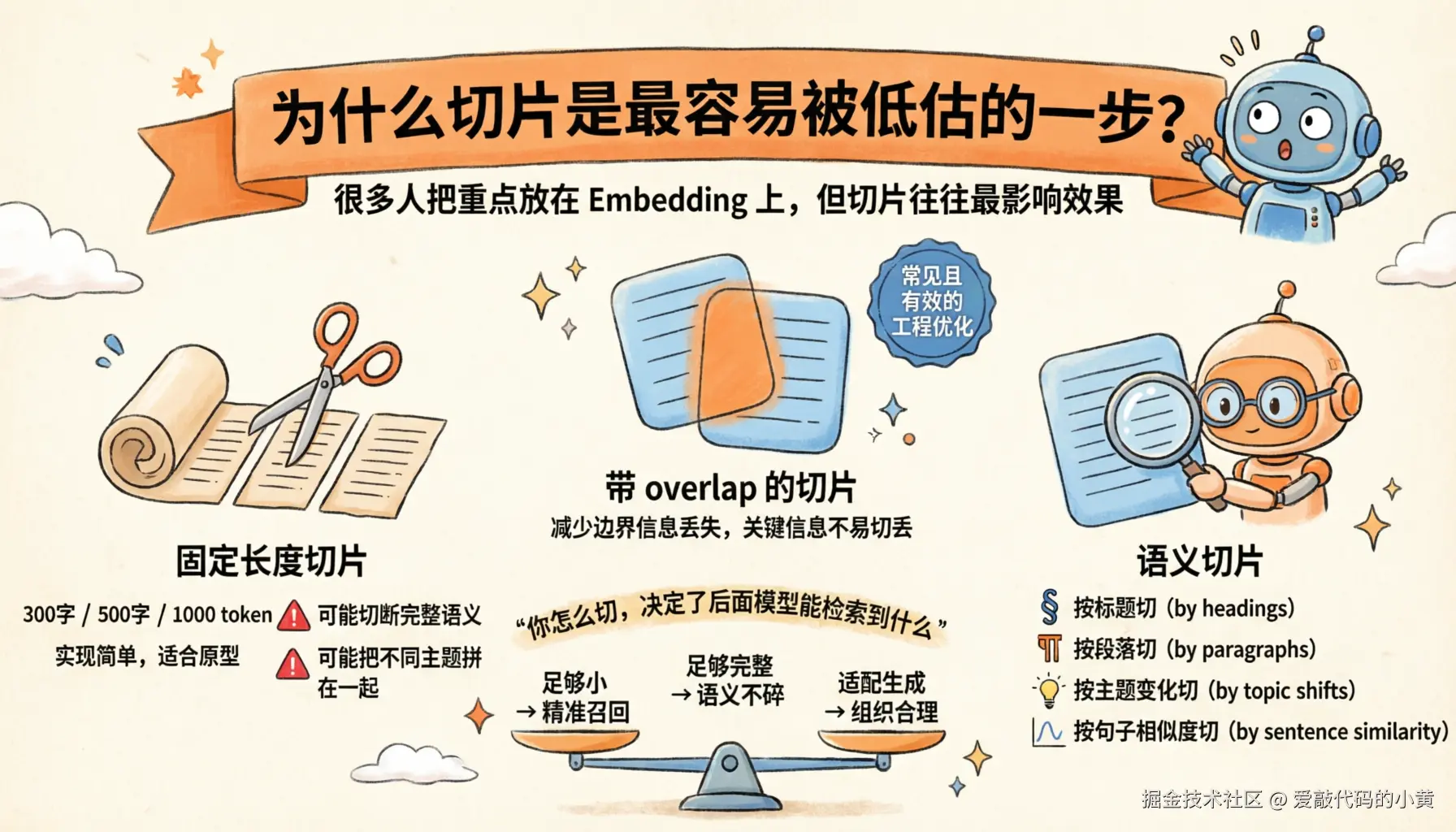
很多人学 RAG,第一反应会把重点放在 Embedding 或向量数据库上。
但真正做下来会发现,切片往往才是最影响效果的环节之一。
原因很简单:文档太长,不能整篇直接拿去检索,也不可能完整塞进模型上下文。
所以必须把它拆成一个个 chunk。
1. 固定长度切片
最基础的方式,就是按固定长度切。
比如每 300 字、500 字,或者每 1000 token 切一块。
这种方法实现简单,适合快速搭原型。但问题也明显:
- 可能把一个完整语义硬切断
- 也可能把两个不同主题拼到一起
2. 带 overlap 的切片
为了减少边界信息丢失,通常会在相邻 chunk 之间加入 overlap,也就是重叠区域。
这样做的好处是:即使关键信息刚好落在边界上,也不容易被切丢。
这是很常见、也很有效的一种工程优化。
3. 语义切片
更进一步的方式,是按语义边界切片,比如:
- 按标题切
- 按段落切
- 按主题变化切
- 按句子相似度切
所以切片本质上是在平衡三件事:
- chunk 要足够小,便于精准召回
- chunk 又要足够完整,不能把语义切碎
- chunk 的组织方式要适配后面的生成
说得更直接一点:你怎么切,决定了后面模型能检索到什么。
3.1 句子相似度
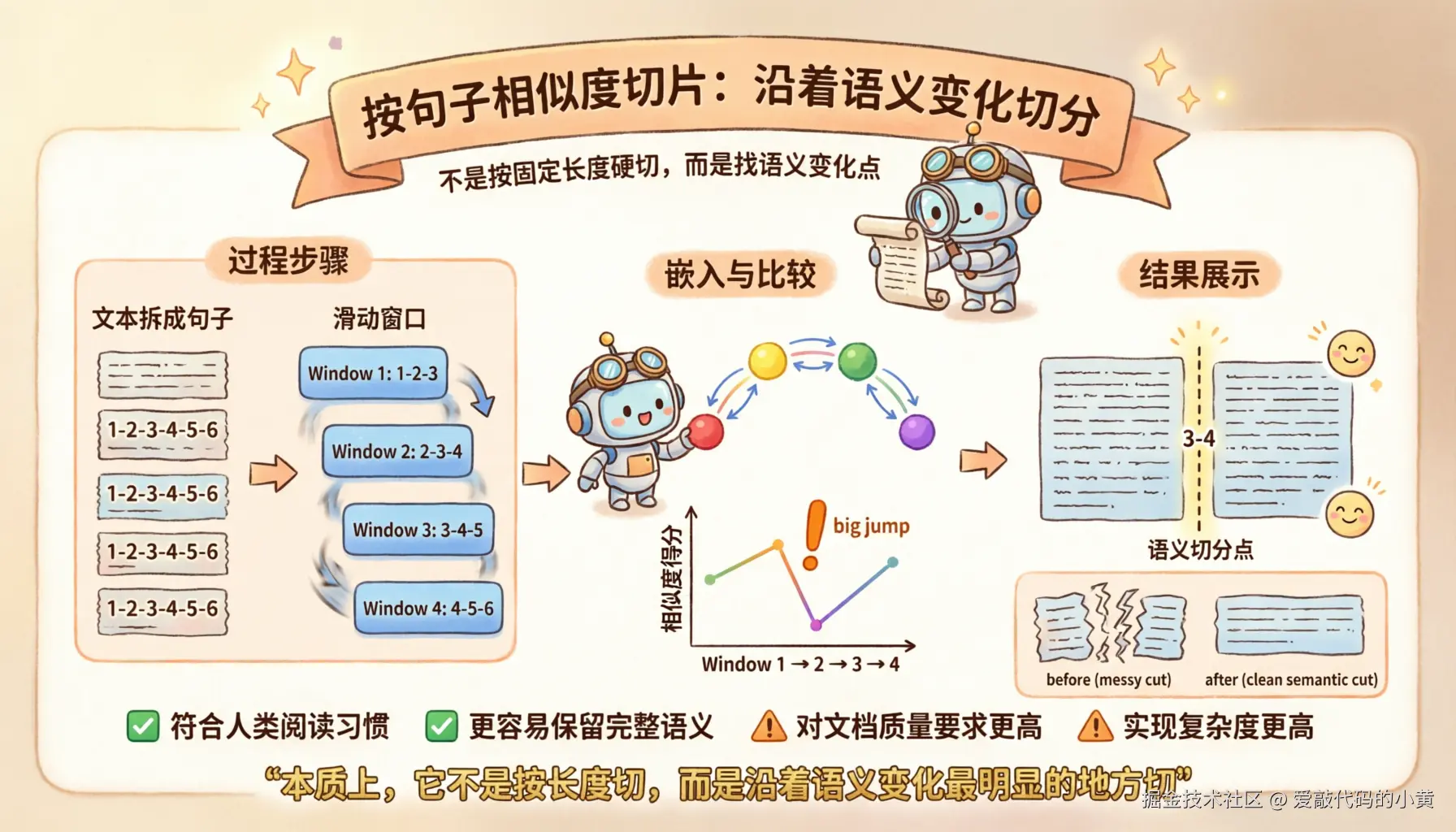
其中,按句子相似度切可以单独展开一下。
它的思路不是按固定长度硬切,而是先判断一段文本内部,语义究竟是在哪里发生变化的。
如果某个位置前后已经不像在讲同一件事了,那么这个位置就很适合作为切分点。
比如一段文本被拆成 1、2、3、4、5、6 六个句子。
如果窗口大小设为 3,就可以得到 1-2-3、2-3-4、3-4-5、4-5-6 这些滑动窗口。
接着,把每个窗口送进 embedding 模型,得到对应的语义向量,再比较相邻窗口之间的差异。
如果某个位置前后的差异突然变大,就说明主题可能在这里发生了变化,这个变化最大的点就可以作为候选切分点。
本质上,它不是按长度切,而是沿着语义变化最明显的地方切。
这种方式更符合人类阅读习惯,也更容易保留完整语义。但它对文档质量要求更高,实现复杂度也更高。
六、Embedding 和向量数据库,到底在做什么?
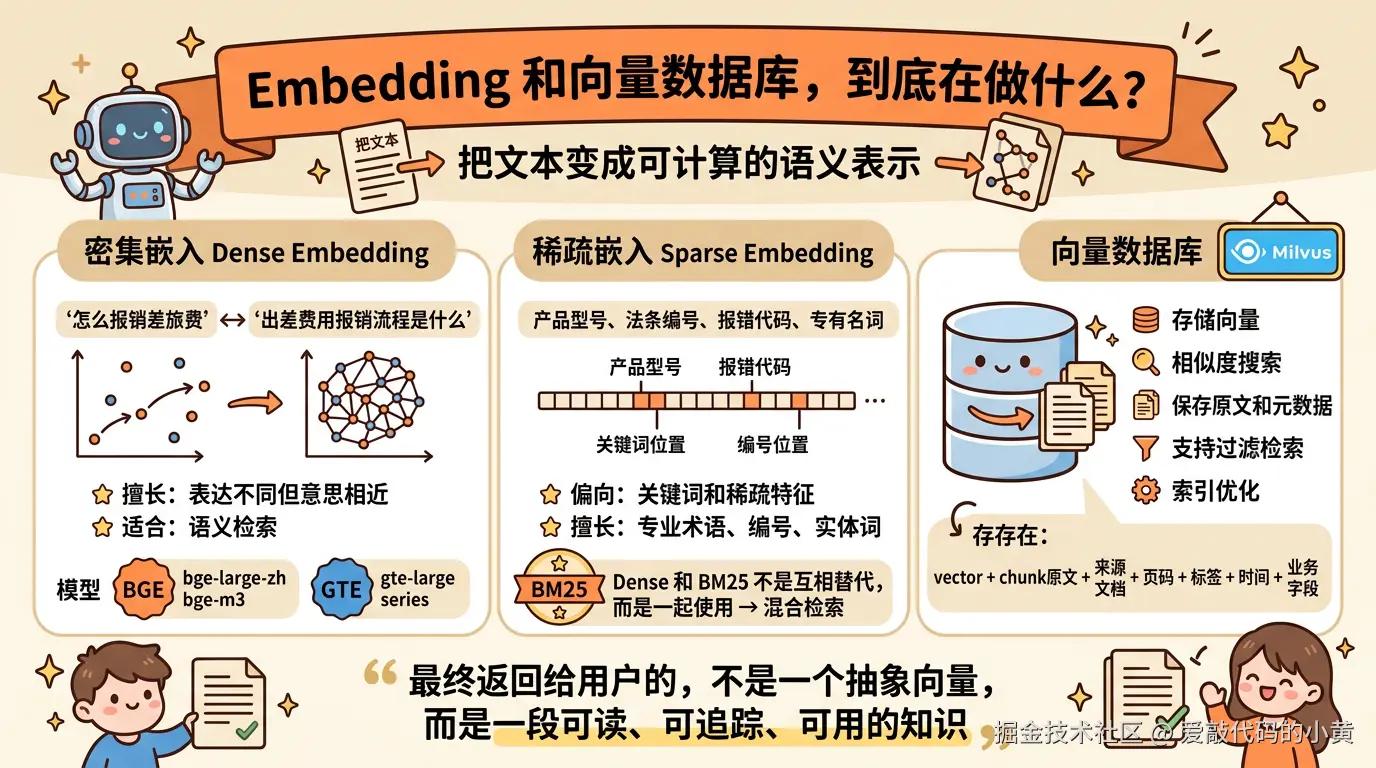
切完片之后,下一步就是把文本变成可计算的语义表示,这就是 Embedding。
你可以把它理解成:把一句话映射成一个语义坐标。
这样,用户提问时,系统就可以根据语义距离,去找最接近的文本块。
1. 密集嵌入(Dense Embedding)
最常见的一类是密集嵌入,也就是 Dense Embedding。
它会把文本表示成一个稠密向量,比较擅长处理表达不同,但意思相近的情况。
比如怎么报销差旅费和出差费用报销流程是什么,虽然字面不一样,但语义其实很接近,Dense Embedding 通常能把它们映射到比较近的位置,所以特别适合做语义检索。
实际工程里,这一类模型常见的代表有 BGE 和 GTE 系列,比如 bge-large-zh、bge-m3,或者 gte-large 等。它们本质上做的都是同一件事:尽量让语义相近的文本,在向量空间里离得更近。
1.1 GTE算法
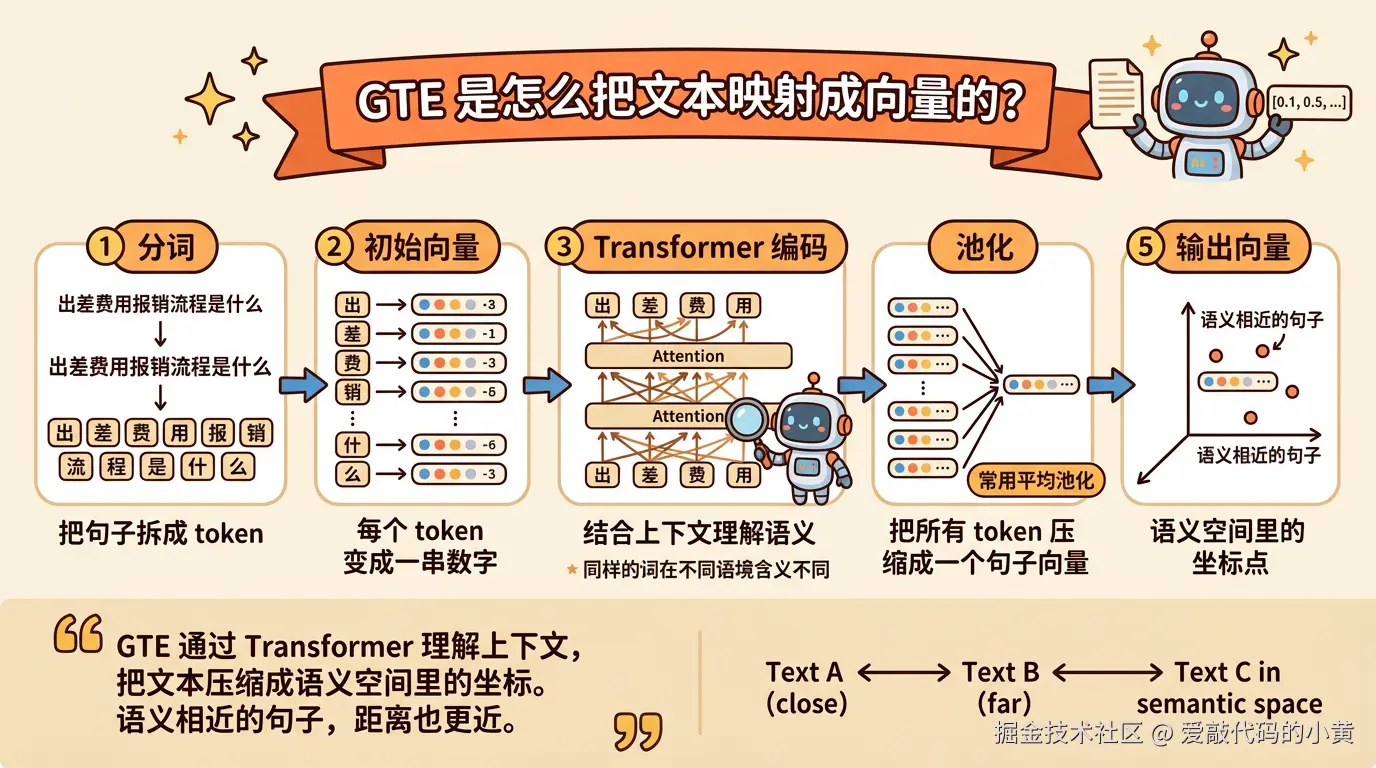
GTE 这类密集嵌入模型,本质上是在做一件事: 把文本映射成一个能够表示语义的向量。 你可以把它理解成,模型先读一句话,理解它大概在说什么,然后再给这句话分配一个语义坐标。以后系统做检索时,就不再只是比关键词,而是去比较这些语义坐标之间的距离。距离越近,通常说明语义越接近;距离越远,通常说明语义差别越大。
2. 稀疏嵌入(Sparse Embedding)
另一类是稀疏嵌入,也就是 Sparse Embedding。
它更偏向关键词和稀疏特征,对专业术语、编号、错误码、实体词会更敏感。
比如用户搜的是产品型号、法条编号、报错代码、专有名词,这时候单靠 Dense 不一定最稳,因为语义模型有时候能理解大意,但未必能稳稳抓住关键词。在这种场景下,Sparse 或全文检索往往更有效。
这里一个非常经典的代表就是 BM25。它虽然不是大模型时代才出现的方法,但在检索系统里一直非常实用,尤其适合做关键词召回。所以在很多实际系统里,Dense 和 BM25 并不是互相替代,而是一起使用,形成混合检索。
2.1 BM25算法
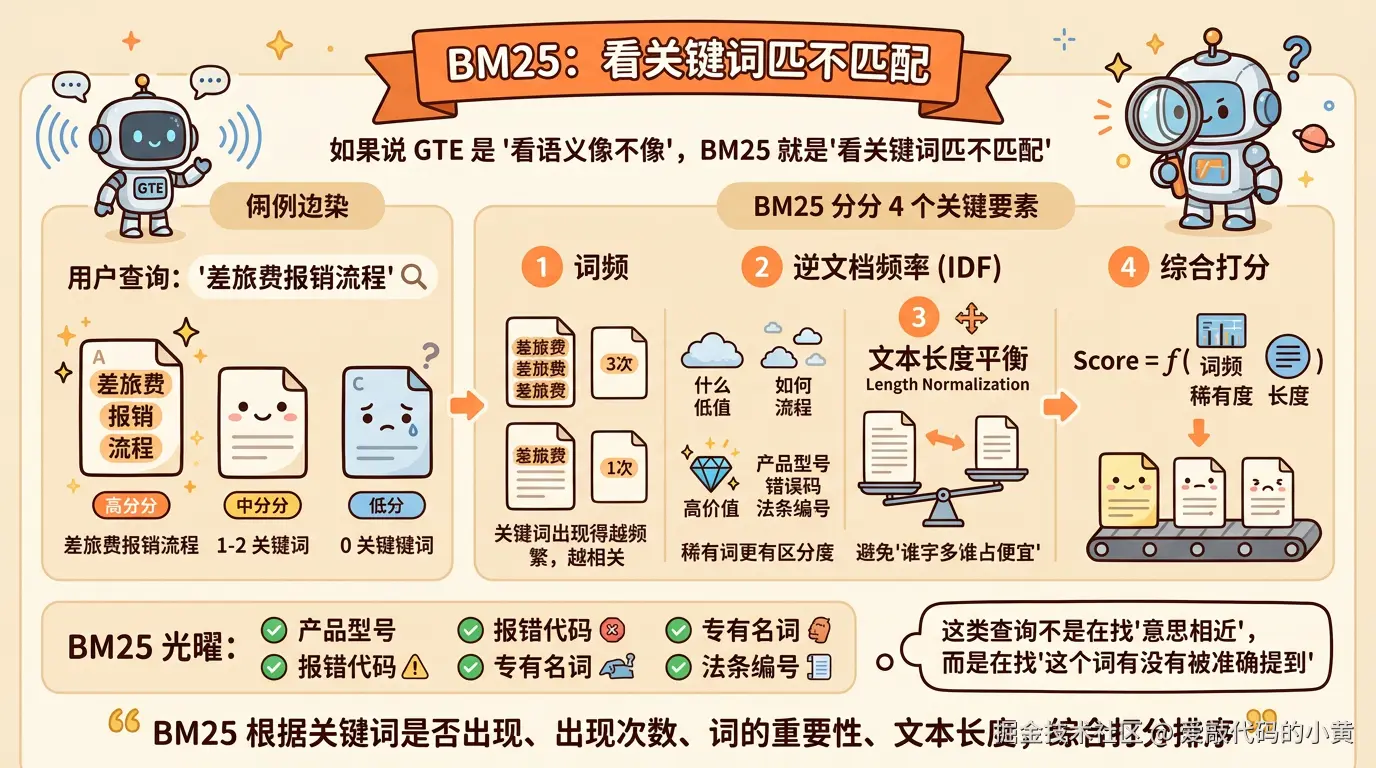
BM25 可以理解成一种基于关键词相关性的排序算法。它会根据查询词有没有出现、出现了多少次、这个词在整个语料里是否稀有,以及文本长度是否合适,来判断一段文本和问题的匹配程度。它不擅长理解深层语义,但对术语、编号、错误码、专有名词这类关键词非常敏感,所以在很多 RAG 系统里,BM25 依然是很重要的基础能力。
3. 向量数据库
做完 Embedding 之后,还需要把这些向量和原始文本一起存起来,这就是向量数据库的工作。
它解决的不是如何理解文本,而是如何高效地存和如何快速地找。
它通常负责几件事:存储向量、做相似度搜索、保存原文和元数据、支持过滤检索,以及配合混合检索和索引优化。在这一类系统里,Milvus 是一个很典型的代表,也是业界比较常用的向量数据库之一。
真正进入向量数据库的,通常不只是一个向量,还会包括对应的 chunk 原文、来源文档、页码、标签、时间、业务字段等信息。
因为最终系统返回给用户的,不是一个抽象向量,而是一段可读、可追踪、可用的知识。
七、RAG 的检索,不只是向量搜索
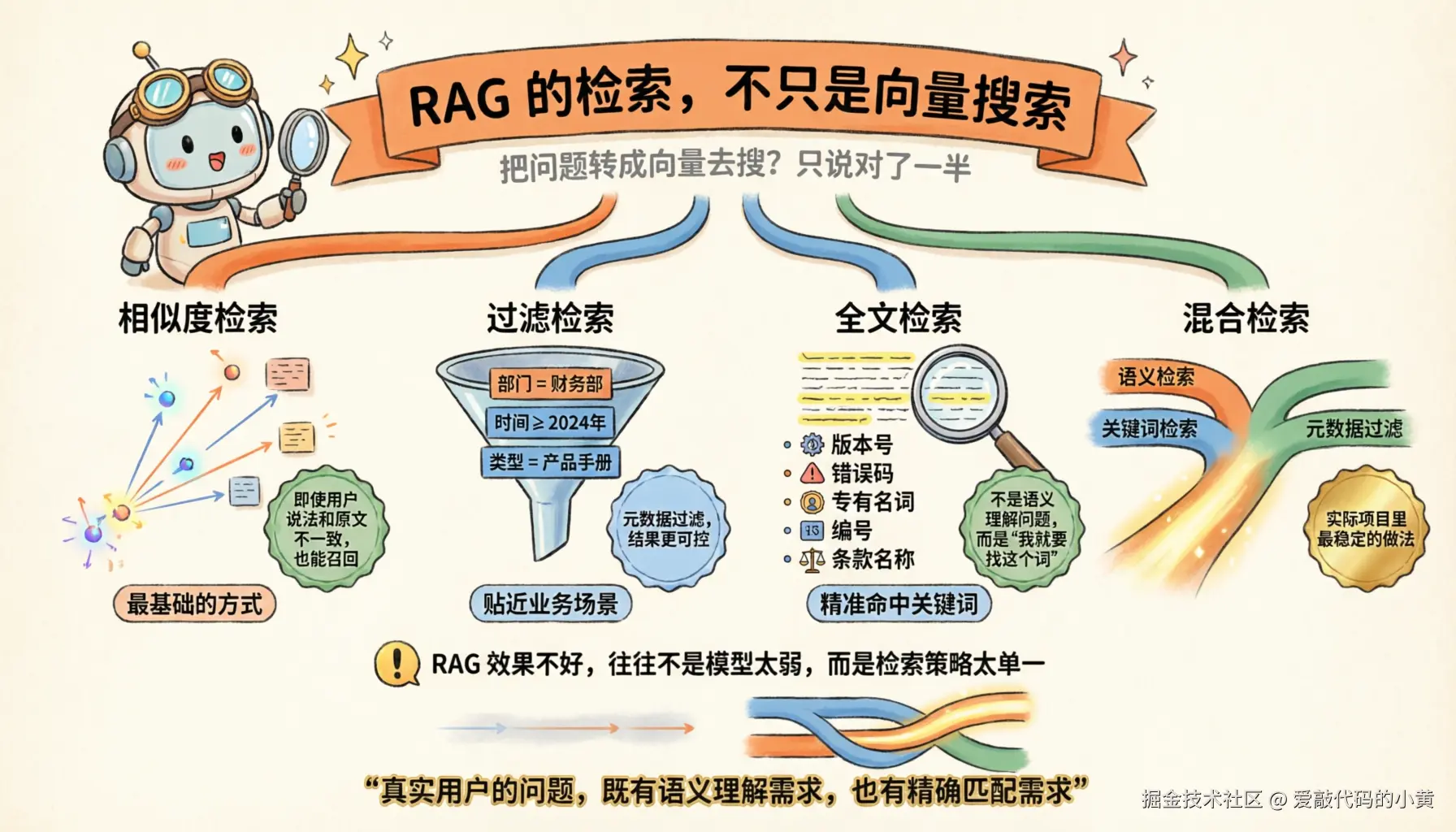
初学 RAG 时,很容易把它理解成一句话:把问题转成向量,然后去向量数据库里搜。
这当然没错,但只说对了一半。真实场景里的检索,通常是多种方式的组合。
1. 相似度检索
这是最基础的一种方式。
把用户问题也转成向量,再找最相似的 chunk。
它的优势是:即使用户的说法和文档原文不完全一致,也有机会召回到相关内容。
2. 过滤检索
有些时候,仅靠语义相似还不够。
比如你希望:
- 只查某个部门的文档
- 只查 2024 年之后的制度
- 只查产品手册,不查会议纪要 这时候就需要元数据过滤。它能让检索结果更可控,也更贴近业务场景。
3. 全文检索
全文检索擅长精准命中关键词。
对于这些内容,它往往特别有用:版本号、错误码、专有名词、编号、条款名称
现实里,很多问题并不只是语义理解问题,而是我就要找这个词。
这种时候,纯向量检索并不一定最优。
4. 混合检索
所以在很多实际项目里,最稳定的做法往往是混合检索,也就是把:
- 语义检索
- 关键词检索
- 元数据过滤 结合起来一起用。
因为真实用户的问题,往往既有语义理解需求,也有精确匹配需求。
单一路径,很难兼顾两边。
所以很多时候,RAG 效果不好,不是模型太弱,而是检索策略太单一。
八、为什么召回之后,还要做 Rerank?
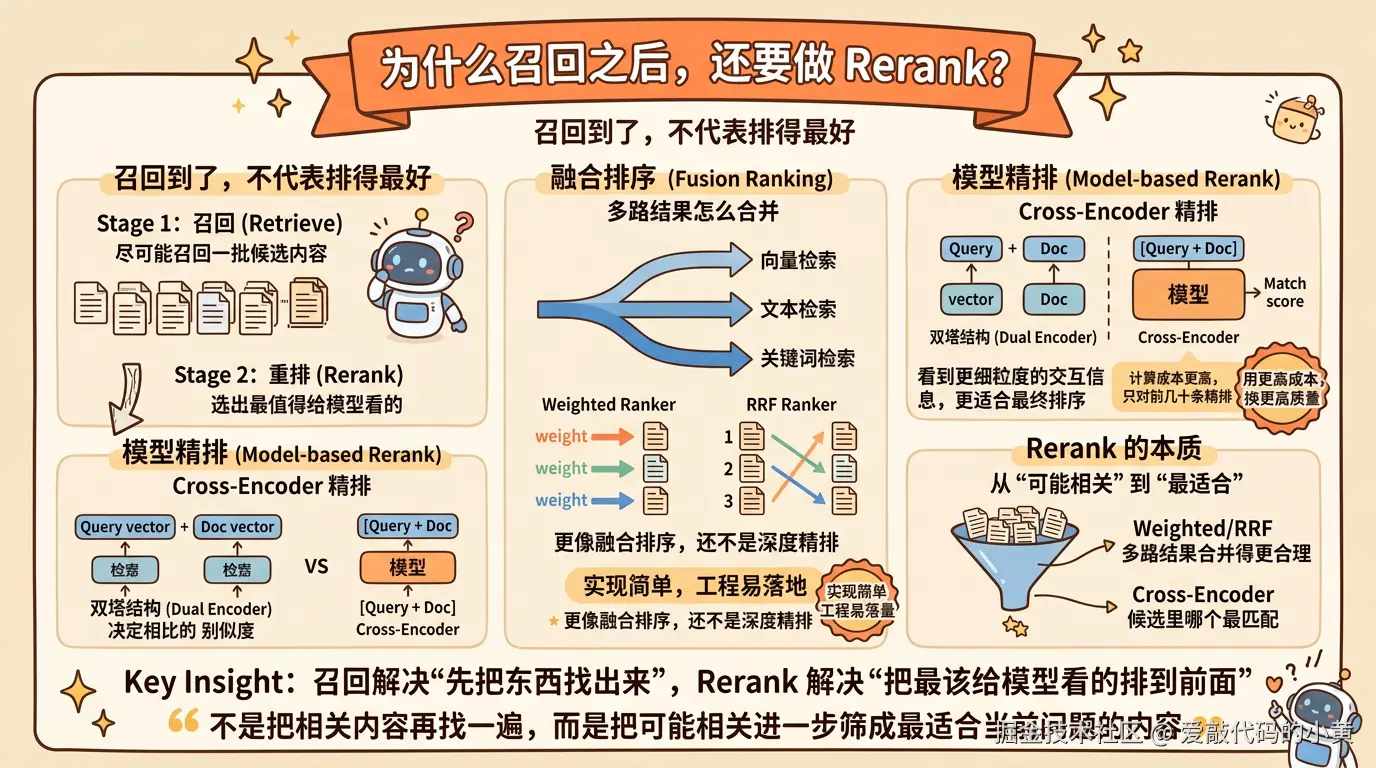
因为召回到了,不代表排得最好。
系统可能一次召回了 10 条都相关的内容,但真正最适合回答当前问题的那条,未必排在最前面。
如果不再做一次排序优化,最终交给模型的上下文就可能不是最优的。
所以在 RAG 里,常见做法通常不是召回完就结束,而是再加一层 Rerank,也就是重排。
你可以把它理解成两阶段:
- 先尽可能召回一批候选内容
- 再从候选里选出最值得给模型看的内容
1. 融合排序
有些场景下,系统并不是只有一路召回,而是会同时结合向量检索、全文检索、关键词检索等多种方式。
这时候首先要解决的问题,不是文本理解得够不够深,而是多路结果怎么合并。
常见方法有两种:
- Weighted Ranker: 给不同召回通道设置不同权重,再综合排序
- RRF Ranker: 不过度依赖绝对分数,而更关注一条结果在多个列表中的相对排名 这类方法的优点是实现简单、工程上容易落地,而且对混合检索非常实用。
但它们本质上更像融合排序,还不是严格意义上的深度精排。
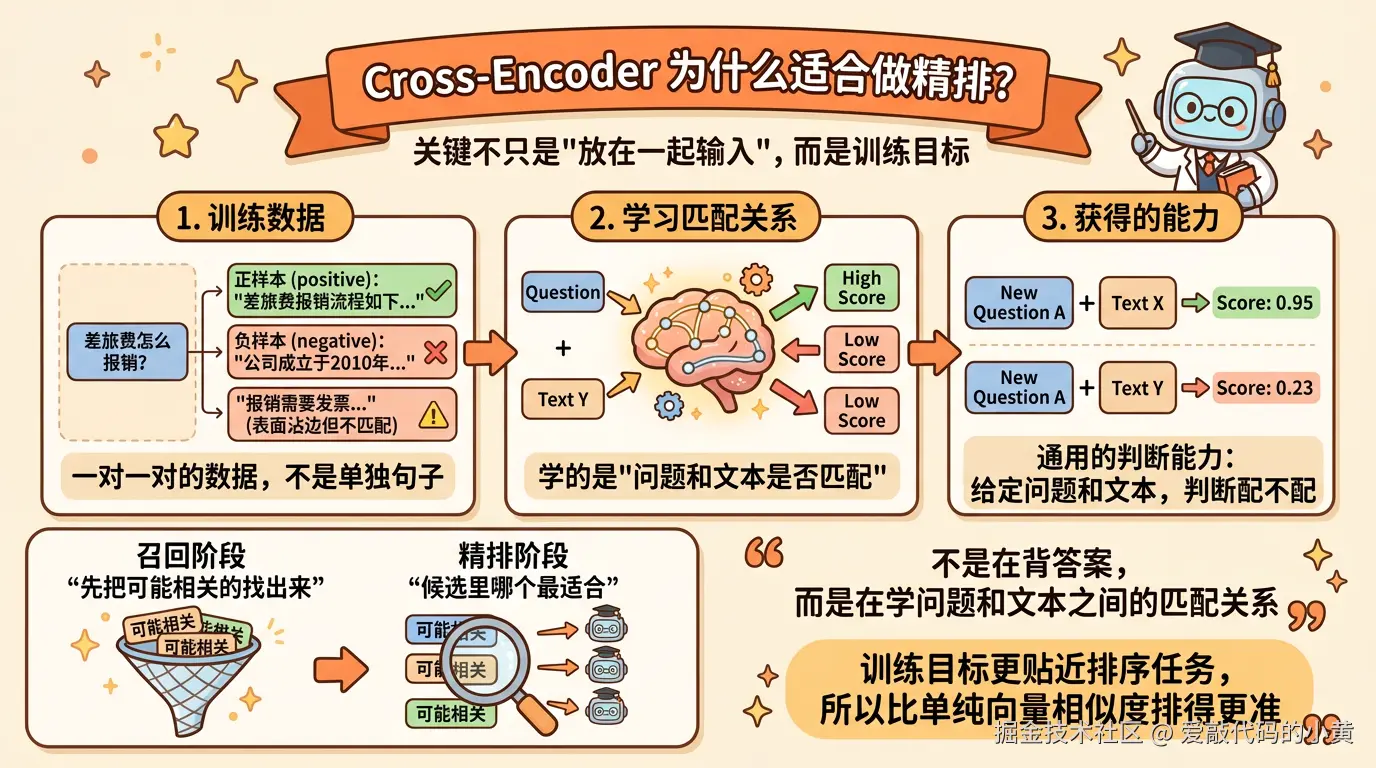
2. 模型精排
如果想进一步判断哪段内容最适合当前问题,通常还会引入专门的精排模型,比如 Cross-Encoder 类的 reranker。
它和前面的向量检索有一个很大的区别。
向量检索通常属于双塔结构,也就是先把问题和文本分别编码成两个向量,再通过向量相似度判断它们是否接近;
而 Cross-Encoder 则是把问题和候选文本作为一对输入,一起送进模型,让模型直接输出一个匹配分数。
这样做的好处是,模型看到的不再是两个彼此独立的向量,而是问题和文本之间更细粒度的交互信息,所以通常更适合做最终排序。
也正因为如此,Cross-Encoder 类方法往往比普通向量相似度更准,尤其适合用来判断这段内容到底是不是最适合回答当前问题。
不过它的代价也更高。因为每一个候选文本,都要和当前问题单独配对,再跑一遍模型,所以计算成本会明显高于普通向量检索。
也因此,在实际工程里,它一般不会用来做大规模召回,而是放在召回之后,对前几十条候选结果再做一次精排。
所以从工程角度看,Cross-Encoder 类精排模型本质上是在用更高的计算成本,换取更高质量的排序结果。
2.1 Cross-Encoder 为什么能做精排
3. Rerank 的本质
Rerank 的意义可以概括成一句话:不是把相关内容再找一遍,而是把可能相关进一步筛成最适合当前问题的内容。
- Weighted Ranker 和 RRF 解决的是多路结果怎么合并得更合理
- Cross-Encoder 解决的是这些候选里,哪个和当前问题最匹配 召回解决的是先把东西找出来,而 Rerank 解决的是把最该给模型看的内容排到前面。
九、RAG 最后一公里:怎么把检索结果交给模型?
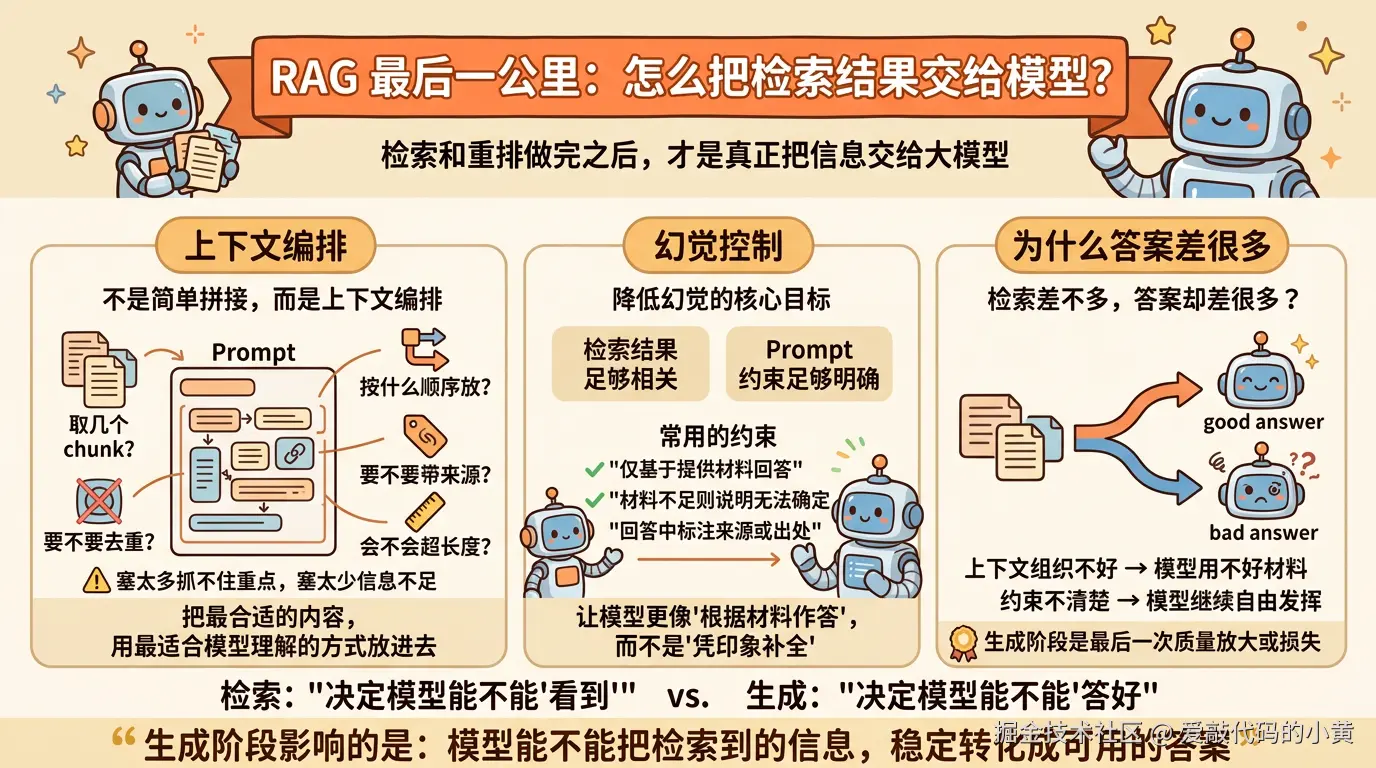
检索和重排做完之后,下一步才是真正把信息交给大模型,也就是生成阶段。
很多文章讲 RAG,讲到检索和重排就差不多结束了。
但真正决定回答质量的,往往还包括最后一步:检索到的内容,究竟怎么交给模型。
1. 上下文编排
生成阶段最常见的做法,是把检索到的若干 chunk 拼进 Prompt,再连同用户问题一起发给模型。
但这一步并不是简单拼接,而更像是在做上下文编排。
比如,取几个 chunk,按什么顺序放,要不要去重,要不要带来源,内容会不会超出上下文长度,这些都会直接影响最终回答质量。
因为上下文不是塞得越多越好。塞太多,模型可能抓不住重点;塞太少,信息又可能不足。
所以这一层真正要解决的问题,不是怎么把内容放进去,而是怎么把最合适的内容,用最适合模型理解的方式放进去。
2. 幻觉控制
生成阶段另一个核心目标,是尽量降低幻觉。
RAG 不能彻底消灭幻觉,但可以明显降低它出现的概率。前提通常有两个:一是检索结果本身足够相关,二是 Prompt 约束足够明确。
常见做法包括:
- 要求模型仅基于提供材料回答
- 如果材料不足,就直接说明无法确定
- 要求在回答中标注来源或出处 这些约束的本质,都是尽量减少模型脱离材料自由发挥,让它更像是在根据材料作答,而不是凭印象补全答案。
3. 为什么检索差不多,答案却差很多
很多时候,同样是 RAG,前面的检索结果看起来差不多,但最终回答效果还是会有明显差异。
原因就在于,生成阶段并不是一个机械的拼接动作,而是整条链路里的最后一次质量放大,或者质量损失。
如果上下文组织得不好,模型即使拿到了相关材料,也未必能用好。
如果约束不清楚,模型即使看到了证据,也可能继续自由发挥。
所以从工程上看,生成阶段真正影响的是:模型能不能把检索到的信息稳定转化成可用的答案。
说得更直接一点,检索决定模型能不能看到,而生成决定模型能不能答好。
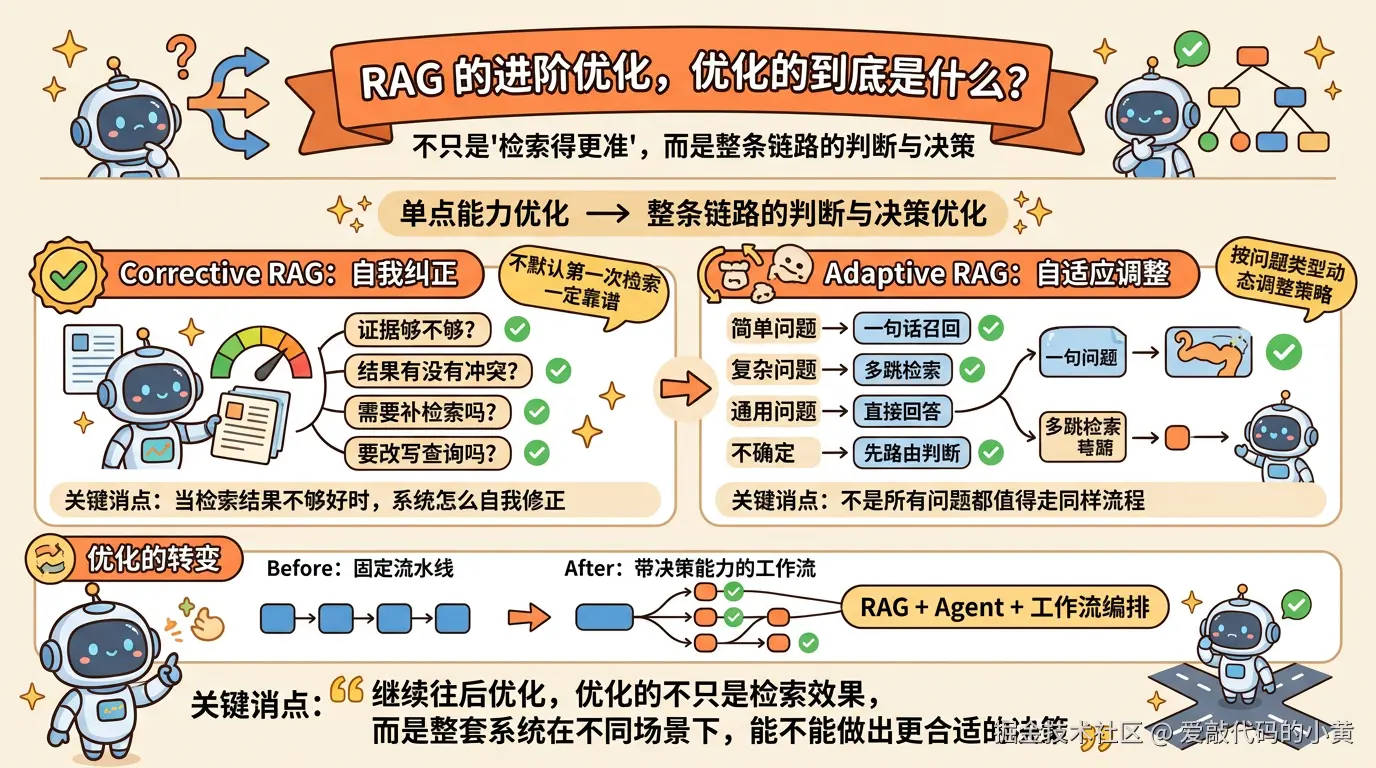
十、RAG 的进阶优化,优化的到底是什么?
如果说前面讲的,更多还是标准 RAG 的主链路,那么再往后走,很多优化已经不只是检索得更准一点这么简单了。
因为在真实系统里,问题往往不只是能不能检索到,还包括:
- 这次检索结果靠不靠谱
- 证据够不够支撑回答
- 要不要补一次检索
- 不同问题是不是应该走不同流程 也就是说,RAG 的优化重点,正在从单点能力优化,逐渐走向整条链路的判断与决策优化。
Corrective RAG(自我纠正的RAG)
Corrective RAG 可以理解成一种带纠偏能力的 RAG。
它不默认第一次检索结果一定靠谱,而是会进一步判断:当前证据是不是不足,检索结果之间有没有冲突,如果这次检索不理想,是否需要补检索、改写查询,或者调整后续流程。
所以它优化的,已经不只是检索,而是当检索结果不够好时,系统怎么自我修正。
Adaptive RAG(自适应RAG)
Adaptive RAG 更强调按问题类型动态调整策略。
因为不是所有问题,都值得走同样一套固定流程。
有些问题一句话就能召回,有些问题需要多跳检索,有些问题甚至根本不该走知识库,而应该直接回答,或者先做路由判断。
所以到了这一步,RAG 就不再只是固定流水线,而更像是一套带决策能力的工作流。
这也是为什么现在很多人会把 RAG 和 Agent、工作流编排放在一起讨论。
因为继续往后优化,优化的往往已经不只是检索效果,而是整套系统在不同场景下,能不能做出更合适的决策。
十一、结尾
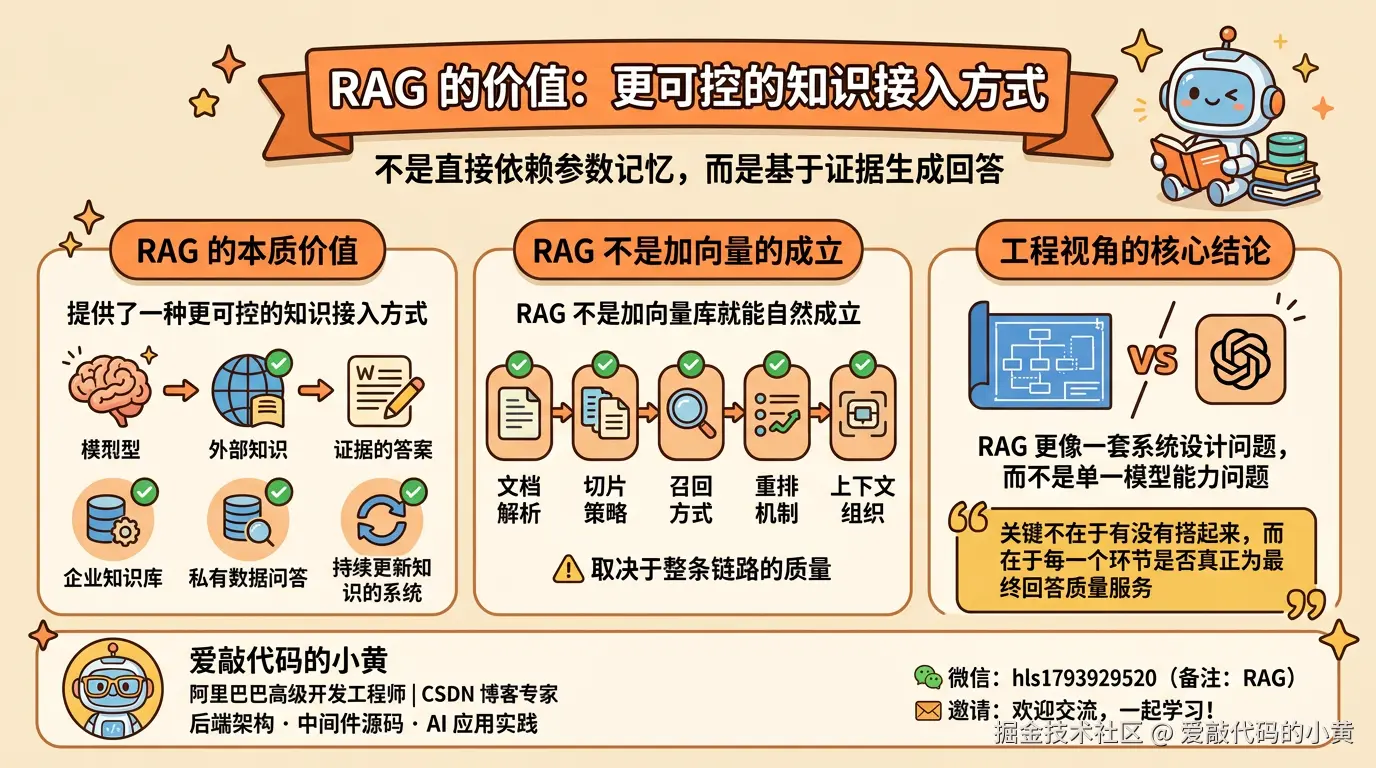
回过头看,RAG 的价值并不在于引入了多少新概念,而在于它提供了一种更可控的知识接入方式。
它让大模型在生成答案之前,不是直接依赖参数记忆,而是先从外部知识中检索证据,再基于证据生成回答。
这件事对于企业知识库、私有数据问答、以及需要持续更新知识的系统来说,意义非常明确。
但与此同时,RAG 也不是加一个向量库就能自然成立的方案。
它最终效果,取决于整条链路的质量,包括文档解析、切片策略、召回方式、重排机制,以及上下文组织方式。
所以从工程视角看,RAG 更像一套系统设计问题,而不是单一模型能力问题。
这也是我这次梳理之后最明确的一个结论:RAG 的关键,不在于有没有搭起来,而在于每一个环节是否真正为最终回答质量服务。
如果你也在学习 RAG、Agent 架构,或者正在做 AI 应用落地相关的事情,欢迎来找我交流。
我是爱敲代码的小黄,阿里巴巴高级开发工程师,CSDN 博客专家,平时会持续分享后端架构、中间件源码,以及 AI 应用实践相关内容。
如果这篇文章对你有帮助,也欢迎加我微信:hls1793929520
备注RAG,我拉你进群一起交流学习。
我们下期再见。