一、面试题目
请详细解释大模型推理中的 KV Cache(Key-Value 缓存) 机制。它的核心原理是什么?为什么它能显著加速推理过程?在工程实现上,它是如何运作的?
二、知识储备
(一) 什么是 KV Cache?
大模型生成文字是"一个词一个词"蹦出来的。每生成一个新词,模型都需要回看之前所有的词。
- 没有 KV Cache: 每次出新词,都要重新计算前面所有词的关联关系,就像每次写新的一行字都要重读整本书。
- 有了 KV Cache: 模型把前面算过的词的"特征(Key 和 Value 向量)"存起来。出新词时,直接从缓存里拿旧数据,只算新词的那一点点逻辑。
(二) 为什么能加速推理?
深度点: 核心在于将 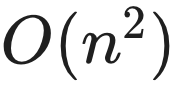 的计算量降低为
的计算量降低为 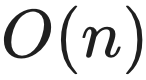 (针对当前生成步)。
(针对当前生成步)。
- 消除重复计算: 自注意力机制中,每个词的
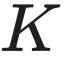 和
和  向量在生成过程中是固定不变的。
向量在生成过程中是固定不变的。 - 从计算密集转为内存密集: 推理的瓶颈往往不在于显卡的算力(TFLOPS),而在于显存的带宽。KV Cache 通过"空间换时间",避开了昂贵的矩阵乘法重复运算。
(三) 如何实现?(逻辑流程)
① 预填充阶段 (Prefill): 用户输入一段话,模型一次性算出所有输入 Token 的 和 ,存入显存。
② 解码阶段 (Decoding):
- 模型生成第
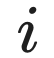 个 Token。
个 Token。 - 算该 Token 的
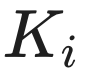 和
和 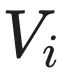 。
。 - 关键动作: 将 , 拼接(Append)到之前缓存的
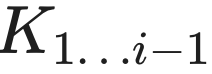 ,
, 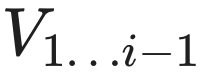 后面。
后面。 - 下一次计算直接引用这个增长的缓存。
三、代码实现
(一) Python 实现 (侧重张量维度的拼接)
Python 端通常直接操作 PyTorch 张量,这是 KV Cache 真正的形态。
python
import torch
def inference_step(input_id, past_key_values=None):
# input_id: 当前步的输入 [batch_size, 1]
# past_key_values: 之前的 KV Cache
# 1. 模型前向传播
outputs = model(input_ids=input_id, past_key_values=past_key_values, use_cache=True)
# 2. 获取输出和更新后的缓存
next_token_logits = outputs.logits[:, -1, :]
new_kv_cache = outputs.past_key_values # 包含了旧的 + 刚算的
return next_token_logits, new_kv_cache
# 在循环中不断传递 new_kv_cache,这就是加速的秘密(二) Node.js 实现 (侧重逻辑流程模拟)
在 Node.js 中处理流式输出时,理解 KV Cache 有助于你优化后端长连接的性能。
javascript
class KVCacheSimulator {
constructor() {
this.cache = { keys: [], values: [] }; // 模拟显存中的 KV 缓存
}
// 模拟模型推理一步
async generateNextToken(inputToken, historyCache) {
// 1. 计算当前 token 的特征 (简化模型)
const { k, v } = this.computeKV(inputToken);
// 2. 将新的 KV 挂载到缓存中
this.cache.keys.push(k);
this.cache.values.push(v);
// 3. 仅使用当前 Q 与 历史所有的 K, V 进行注意力计算
const output = await this.attentionLogic(inputToken, this.cache);
return output;
}
computeKV(token) { return { k: `key_${token}`, v: `val_${token}` }; }
}四、破局之道
在面试最后,用这段话展现你对底层优化的深刻洞察:
回答 KV Cache,核心在于理解 "推理开销的转移"。
你可以告诉面试官:KV Cache 的本质是 利用显存空间换取计算时间,它将 Transformer 推理从 的重复计算陷阱中解救出来。但在工程实践中,它也带来了新挑战------显存碎片化(Memory Fragmentation) 。这也是为什么后来会出现 PagedAttention(vLLM) 这种像操作系统管理内存一样管理 KV Cache 的技术。优秀的 AI 开发者不仅要让模型跑得快,更要能精细化管理每一兆显存,在长上下文和高并发之间找到最佳平衡点。