很多人一开始学深度学习,最容易卡住的不是代码,而是这些词:
-
模型
-
参数
-
loss
-
梯度
-
反向传播
-
参数更新
这些词单独看都好像认识,但一连起来就会发虚。
尤其是刚接触 YOLO 的时候,经常会看到:
-
模型在训练
-
loss 在下降
-
梯度在回传
-
参数在更新
可如果你不知道这些东西之间到底是什么关系,那后面看检测模型、结构图、训练日志时,就容易变成"看过,但没真正懂"。
这一篇就从最简单的: 开始,一步一步走到神经网络,把这条链真正串起来。
一、先从最简单的模型开始:( y = wx + b )
这个式子你应该不陌生。
它本质上是一个函数。
给它一个输入 ( x ),它就输出一个结果 ( y )。
比如:
那么:
这件事本身其实就已经很接近"模型"了。
1. 什么叫模型
在机器学习和深度学习里,模型本质上就是一个函数:给它一个输入,它会给你一个输出。最简单时,这个函数可以写成:
这里我故意把输出写成 ( ),而不是直接写 ( y )。
因为在机器学习里:
-
:通常表示真实答案
-
这里的 x 是输入,ŷ 是模型预测值,w 和 b 是模型内部可调的量。只要 x 给定,参数也给定,模型就会算出一个确定的输出。
模型根据输入 ( x ),算出一个预测值 ( )。
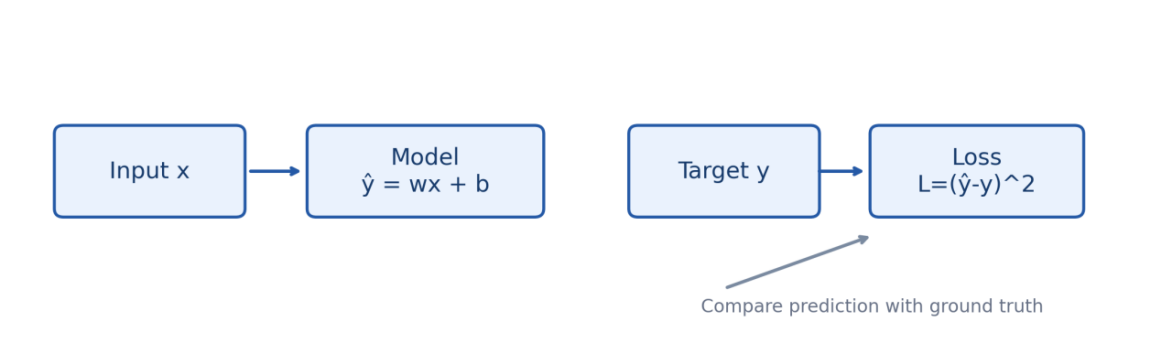
图 1 最简单的训练链:输入 x 经模型得到预测值 ,再与真实值 y 比较,得到 loss。
二、参数到底是什么
在这个模型里,x 是输入,不由训练决定;真正可以被训练不断调整的是 w 和 b。它们就是参数。
1. 参数不是一句空话
很多资料喜欢说"模型有很多参数",但不解释参数到底是什么。
其实参数一点都不玄。
你可以直接把它理解成:
你可以把参数理解成模型里的"旋钮":旋钮拧到不同位置,模型输出就会不同。
对于
来说:
• w 控制斜率,也就是输入变化时输出变化得有多快。
• b 控制截距,也就是在 x = 0 时输出的基准位置。
它们会影响模型输出,所以它们就是参数。
因此,训练模型并不是在"背公式",而是在"找一组更合适的参数"。
2. 为什么参数重要
因为模型好不好,不在于"有没有公式",而在于:
参数取什么值。
比如同一个公式:
情况 1
情况 2
虽然都是同一种模型形式,但参数不同,输出就完全不同。
所以训练模型,说白了就是:
找到一组更合适的参数,让模型输出更接近真实答案。
三、真实答案和预测答案,怎么比较
模型现在已经能输出预测值了:
但只有预测值还不够。
因为你不知道它预测得好不好。比如模型输出 7,这到底算对还是算错?
你必须拿它和真实答案比较。
假设真实答案是:
那么你就要比较:
真实值 ??? 预测值
两者越接近,说明模型越好。
两者差得越多,说明模型越差。
四、loss 是什么
这时候就需要一个东西,把"差得多不多"变成一个明确的数字。
这个数字就叫 loss(损失)。
可以先把它理解成:
模型当前这次预测错得有多严重。
1. 最简单的一种 loss:平方误差
对于 ( =wx+b ) 这种很简单的模型,我们常用一种 loss:
这里:
:预测值
:真实值
:
这个公式的意思非常直白:
-
如果预测值和真实值一样,差是 0,loss 就是 0
-
如果差得越远,平方后会更大,loss 就越大
2. 为什么要平方
这里顺手说一下平方的原因。
如果只写:
那会出现正负抵消的问题。
比如:
错 3,得到 ( +3 )
错 -3,得到 ( -3 )
从"错得多严重"这个角度看,它们都错了 3。
所以通常会平方,变成:
这样:
-
一定是非负数
-
错得越多,惩罚越大
五、把模型代入 loss,关键一步来了
我们知道:
又知道:
把模型输出代进 loss 里,就得到:
L = (wx+b-y)^2
这一行特别关键。
因为从这一刻起,loss 不再只是"预测和真实的差距"这么简单了,
它已经变成了一个和参数有关的函数。
也就是说:
loss 依赖于参数 ( w ) 和 ( b )
这就是后面一切的根源。
六、为什么梯度会和 loss 有关系
这就是很多初学者最卡的地方。
不是因为"梯度天生就和 loss 相关",
而是因为:
-
模型输出依赖参数
-
loss 依赖模型输出
-
所以 loss 最终也依赖参数
我们刚才已经写出来了:
你看,loss 里面是不是已经有 ( w ) 和 ( b ) 了?
所以你当然可以问:
-
( w ) 稍微改一点,loss 会怎么变?
-
( b ) 稍微改一点,loss 会怎么变?
而这种"某个量改一点,另一个量怎么变"的问题,
就是导数 / 偏导 / 梯度在解决的问题。
七、先区分三个概念:导数、偏导、梯度
这里不要混。
1. 导数
如果一个函数只有一个变量,比如:
那对 ( x ) 求导,就叫导数。
2. 偏导
如果一个函数有多个变量,比如:
那你可以分别对 ( w )、( b ) 求导,这时候叫偏导。
比如:
3. 梯度
把多个偏导数组合起来,就叫梯度。
对于这个例子来说,梯度可以理解成:
所以梯度不是一个神秘新东西,
它本质上就是:
"loss 对各个参数的偏导数组成的一组方向信息"
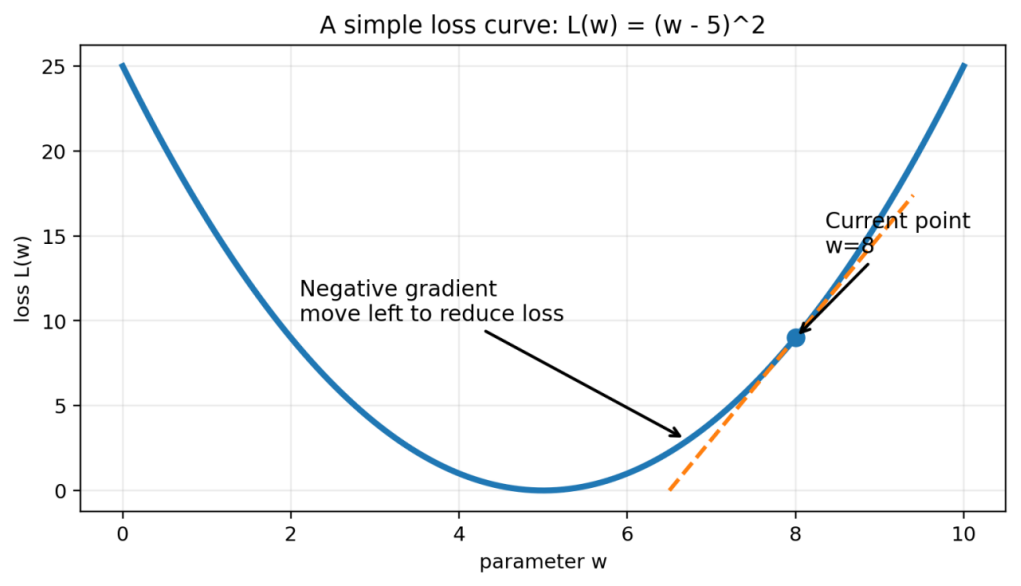
图 2 以 L(w)=(w-5)² 为例:当前位置的斜率由导数给出,沿负梯度方向移动,loss 更可能减小。
八、真正算一次:loss 对参数的梯度
我们现在有:
L = (wx+b-y)^2
下面分别对 w 和 b 求偏导。
1. 对 w 求偏导
L = (wx+b-y)^2
把里面这一坨先记成:
u = wx+b-y
那:
L = u^2
根据求导法则:
而
所以:
2. 对 b 求偏导
同理:
九、这两个式子到底说明了什么
我们先看这部分:
wx+b-y
它其实就是:
也就是:
预测值减真实值
所以这两个梯度可以写成更直观的形式:
1. 如果预测偏大
如果:
那么:
这时:
这说明:
如果继续把 b 增大,loss 在当前位置附近会更倾向于增大。
所以更新时就应该往反方向走,也就是减小 ( b )。
2. 如果预测偏小
如果:
那么:
此时:
这说明:
如果把 ( b ) 增大,loss 反而有机会减小。
所以这时更新公式里"减去负数",就会让 b 变大。
3. 为什么梯度绝对值大,说明更敏感
这是因为局部近似下,有一个很重要的关系:
它的意思是:
当参数 发生一个很小变化
时,
loss 的变化量大约由梯度决定。
所以:
-
如果
那么同样改一点
-
如果
那么同样改一点
这就是"梯度大,说明更敏感"的真正原因。
十、来一个带数字的完整例子
只讲公式容易抽象,我们直接算一次。
假设现在有一条样本:
-
输入 x=2
-
真实值 y=7
模型当前参数是:
-
( w=1 )
-
( b=0 )
1. 先算预测值
模型公式:
代入:
模型预测出来是 2。
2. 再算 loss
用平方误差:
loss 是 25,说明当前预测得不太行。
3. 再算梯度
对 ( w )
对 ( b )
4. 这两个负号是什么意思
负号的意思不是"错了",而是:
如果你把参数往大方向改,loss 有机会下降。
因为更新通常写成:
假设学习率 ,那么:
更新后得到:
5. 再看更新后的预测
这时:
L=(7-7)^2=0
你会发现,这一步更新后,模型恰好就对了。
这个例子非常小,但它已经完整展示了训练的核心逻辑:
-
用当前参数做预测
-
计算 loss
-
计算 loss 对参数的梯度
-
按梯度方向更新参数
-
让 loss 变小
十一、训练到底是在干什么
看到这里,你其实已经能把训练说清楚了。
训练并不是"模型自己突然变聪明"。
训练本质上就是:
不断调整参数,让 loss 尽量变小
所以训练过程的核心可以概括成:
输入 预测
计算 loss
求梯度
更新参数
这条链,后面学任何深度学习模型都会遇到。
十二、从 ( y=wx+b ) 到神经网络,中间到底差了什么
到这里你可能会问:
现在这个模型这么简单,
可神经网络不是很复杂吗?
那它和这个简单式子到底是什么关系?
答案是:
神经网络本质上还是函数,只不过函数更复杂、参数更多、层数更多
1. 线性模型太简单了
这个模型只能表示很简单的线性关系。
如果现实问题更复杂,比如图像识别、目标检测,那一个 肯定不够。
所以就需要把多个这样的计算单元叠起来。
2. 一个简单"神经元"也可以写成类似形式
最基本的神经元,可以写成:
然后再过一个激活函数:
这里:
-
-
-
你可以看到,它还是从 来的,只是多了一步非线性变换。
激活函数的作用是让模型不再只会表示线性关系,而能拟合更复杂的模式。
3. 多个神经元组合起来,就变成网络
如果你把很多个这样的单元堆起来,就会变成:
-
第一层做一轮变换
-
第二层再做一轮变换
-
第三层继续做
于是整个模型就变成了一个更复杂的函数。
比如一个两层网络可以写成:
这里:
-
-
-
-
这时候参数已经不再只有一个 和一个
,而是变成了一大堆。
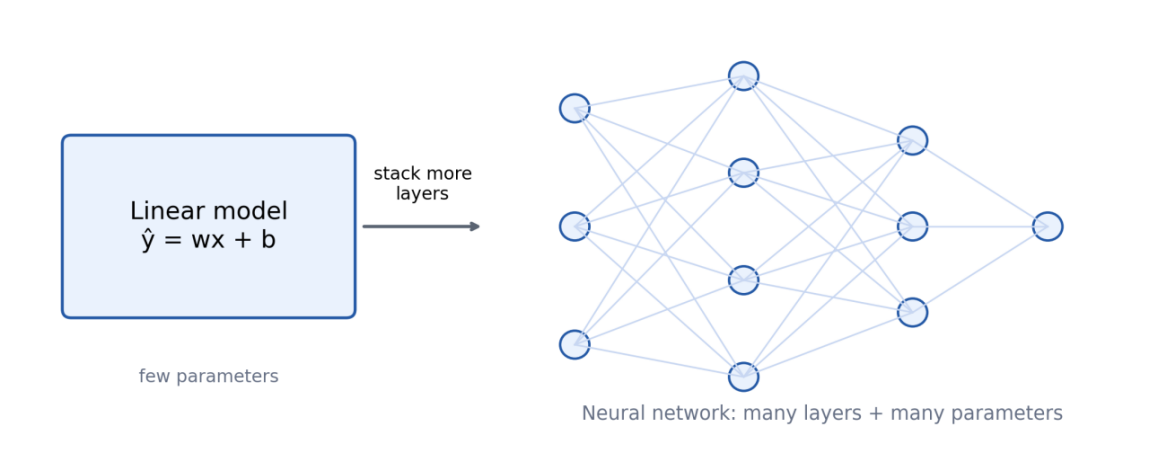
图 4 从单个线性模型到多层神经网络:变化的是函数复杂度和参数规模,不变的是训练逻辑。
但本质没变:
模型仍然是函数,参数仍然是那些可学习的系数
十三、神经网络里的 loss 和梯度,逻辑变了吗
没有变。
逻辑还是同一套,只是对象更复杂了。
1. 神经网络的预测
仍然可以写成:
这里:
-
-
-
-
2. loss 还是用来衡量预测和真实的差距
代入模型输出后:
你会发现,这和前面那个线性模型完全同构。
前面是:
现在只是把简单的 换成了复杂的
。
本质还是:
loss 依赖参数。
3. 所以仍然要求梯度
因为 loss 依赖参数,所以仍然要研究:
也就是:
loss 对各个参数的梯度
然后继续更新参数,让 loss 下降。
所以你要牢牢记住:
从线性模型到神经网络,变化的是函数的复杂程度,不变的是训练逻辑。
十四、前向传播和反向传播,到底是什么
这两个词后面会反复出现,现在可以一起讲清楚。
1. 前向传播(forward)
前向传播就是:
输入数据,经过模型,得到输出,再算出 loss。
也就是这条路:
你可以理解成"从前往后算"。
2. 反向传播(backward)
反向传播就是:
从 loss 出发,反过来计算 loss 对各个参数的梯度。
也就是这条路:
更准确地说,是把梯度从后往前一层层传回去。
它背后最核心的数学工具,就是链式法则。
3. 为什么叫反向传播
因为前向时,数据流动方向是:
输入 → 中间层 → 输出 → loss
反向时,梯度流动方向是反过来的:
loss → 输出层参数 → 中间层参数 → 前面层参数
所以叫"反向传播"。
十五、optimizer 在干什么
前面已经有了:
-
参数
-
loss
-
梯度
那 optimizer(优化器)在干嘛?
它的任务很简单:
根据梯度,决定怎么更新参数。
最常见的基础形式就是梯度下降:
其中:
-
-
-
1. 学习率是什么
学习率就是"每次改参数时迈多大步"。
如果学习率太大:
-
可能一步跨过头
-
loss 反而震荡甚至发散
如果学习率太小:
-
训练会很慢
-
很久都收敛不了
所以训练不是"有梯度就完了",
还要考虑每次按梯度改多少。
十六、图像任务里,这套逻辑还成立吗
完全成立。
只是输入从一个简单数字 ,变成了一张图像。
参数从 两个数,变成了几百万个参数。
输出也不再只是一个数,而可能是:
-
一个类别
-
多个框
-
多个类别概率
-
坐标回归结果
但底层逻辑没变。
1. 在图像分类里
输入是一张图片,模型输出一个类别预测。
然后和真实类别比较,算 loss,再更新参数。
2. 在目标检测里
输入是一张图片,模型输出很多框、类别、分数。
然后和真实标注比较,算检测任务的 loss,再更新参数。
也就是说,YOLOv8 虽然比 复杂得多,
但本质仍然是在做这件事:
输入 模型输出
计算 loss
求梯度
更新参数
十七、把整条链最后完整写一遍
现在我们把这一篇的核心关系,用最完整的形式写出来。
1. 线性模型版本
模型:
损失:
代入后:
梯度:
更新:
2. 神经网络版本
模型:
损失:
代入后:
梯度:
更新:
你会发现,神经网络只是把简单的 升级成了更复杂的
。
训练逻辑没有换。
十八、这一篇里最容易混的几个点
1. 参数不是输入
参数是模型内部要学习的量,
输入是你喂给模型的数据。
-
-
不要混。
2. loss 不是模型本身
模型负责预测,loss 负责评价预测得好不好。
模型是:
loss 是:
一个负责"算结果",一个负责"打分"。
3. 梯度不是"误差本身"
误差是预测和真实之间的差。
梯度是"参数变化时,loss 怎么变"。
它们有关,但不是一个东西。
4. 反向传播不是更新参数
反向传播是算梯度 。
优化器才是拿梯度去更新参数。
这个区别一定要记住。
十九、小结
从最简单的:
出发,可以把整套逻辑看成这样:
-
模型本质上是函数
-
参数是模型里可以学习、可以调整的系数
-
模型根据输入给出预测值
-
loss 用来衡量预测值和真实值的差距
-
因为 loss 依赖参数,所以可以对参数求梯度
-
梯度告诉我们参数往哪个方向改,loss 更可能下降
-
优化器根据梯度更新参数
-
神经网络只是把简单函数换成了更复杂的函数,训练逻辑不变
|----------|----------------------------------|
| 模型 | 模型本质上是一个带参数的函数。 |
| 参数 | 参数是模型里可以通过训练不断调整的量,例如 w、b。 |
| loss | loss 用一个数字把"预测得好不好"表达出来。 |
| 梯度 | 梯度描述参数微小变化时,loss 会朝什么方向、以多快速度变化。 |
| 反向传播 | 反向传播负责把 loss 对各层参数的梯度算出来。 |
| 优化器 | 优化器根据梯度真正去更新参数。 |