机器学习(Machine Learning)是从数据中自动提取模式、优化性能指标的自动化过程(An automated process of extracting patterns from data and optimizing performance criteria)。
1 机器学习基本定义
1.1 核心思想
机器学习是从数据中学习一个映射函数 f:X→Y(Learn a mapping function f:X→Y from data),将输入空间映射到输出空间。
- 包含四大要素:数据(Data)、模型(Model)、损失函数(Loss Function)、优化(Optimization)
- 模型分为两类:
- 预测型(Predictive):对未来 / 新数据做预测
- 描述型(Descriptive):挖掘数据内在规律
1.2 Mitchell 经典定义(1997)
一个计算机程序在任务 T 、性能度量 P 、经验 E 下,若性能随经验提升,则称为学习。
A computer program is said to learn from experience E with respect to task T and performance measure P, if its performance on T improves with E.
2 机器学习学习范式
2.1 基础范式
-
监督学习(Supervised Learning) 使用带标签 数据,学习条件概率 p(y∣x),用于分类、回归、排序。Uses labeled data to learn p(y∣x), for classification, regression, ranking.
-
无监督学习(Unsupervised Learning) 仅使用无标签 数据,学习边缘概率 p(x),用于聚类、降维。Uses only unlabeled data to learn p(x), for clustering, dimensionality reduction.
-
半监督学习(Semi-supervised Learning) 同时使用标签 + 无标签数据,适合标注成本高场景。Uses both labeled and unlabeled data, for high annotation cost scenarios.
-
直推式学习(Transductive Learning) 只预测给定测试集,不泛化到其他未知样本。Predicts only given test points, no generalization to new points.
2.2 进阶范式
-
在线学习(Online Learning) 多轮迭代,训练测试混合,最小化累积损失。Train/test mixed, minimize cumulative loss.
-
强化学习(Reinforcement Learning) 与环境交互获得奖励,最大化长期回报。Interact with environment for rewards, maximize long-term return.
-
**主动学习(Active Learning)**主动查询标签,用更少数据达到监督效果。Query labels actively to achieve supervised performance.
-
小样本学习(Few-shot Learning) 从极少量样本学习,模拟人类学习能力。Learn from very few examples like humans.
3 机器学习核心任务
3.1 分类(Classification)
输出离散类别(Output discrete categories)f:Rn→{1,2,...,k}
3.2 回归(Regression)
输出连续数值(Output continuous values)f:Rn→R
3.3 排序(Ranking)
按规则对样本排序,如搜索结果排序。Order items by criteria, e.g., web search.
3.4 聚类(Clustering)
无监督分组,将相似样本归为一类。Group similar unlabeled samples.
3.5 降维 / 流形学习(Dimensionality Reduction)
高维→低维,保留关键信息。High-dim → low-dim, keep important information.
3.6 转录(Transcription)
非结构化数据→离散文本(Unstructured → text)f:Rn→Ak(m)
3.7 机器翻译(Machine Translation)
源语言→目标语言(Language A → Language B)f:Axk(n)→Ayk(m)
3.8 结构化输出(Structured Output)
输出含复杂关系的数据结构,如图文描述、视频解释。
Output structured data with internal relationships.
3.9 异常检测(Anomaly Detection)
识别分布异常的样本。
Identify samples with abnormal distribution.
3.10 生成与采样(Synthesis & Sampling)
生成与训练集相似的新样本,如文生图、语音合成。
Generate new similar samples, e.g., text-to-image, speech synthesis.
3.11 缺失值填充(Missing Value Imputation)
预测并补全缺失特征 xi。
Predict and fill missing entries xi.
3.12 去噪(Denoising)
从污染样本 x~ 恢复干净样本 xp(x∣x~)
3.13 密度估计(Density Estimation)
学习数据概率分布(Learn probability distribution)pmodel:R^n→R
4 性能指标(Performance Metrics)
使用定量指标评估模型,指标必须与任务匹配。Quantitative metrics are task-specific.
- 准确率(Accuracy):预测正确的样本占全部样本的比例
- 错误率(Error rate):预测错误的样本占全部样本的比例
- 精确率(Precision):模型预测为正的样本中,真正是正样本的比例。(我预测的正例,有多准?)
- 召回率(Recall):所有真实正样本中,被模型成功找出来的比例。(我有没有漏掉正例?)
5 数据表示(Data Representation)
5.1 设计矩阵(Design Matrix)
N 个样本(samples),P 个特征(features)N:X∈R^(N×P)
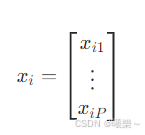
5.2 特征向量
第 i 个样本表示为 P 维向量
6 线性回归(Linear Regression)
6.1 模型公式
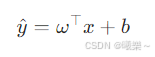
- ω:权重向量(Weight vector)
- b:偏置(Bias)
6.2 均方误差 MSE
衡量预测值与真实值的平均平方距离。值越小,拟合越好。
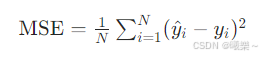
6.3 训练目标
线性回归的训练目标就是:找到最优的权重 ω,让训练集上的 MSE 最小。
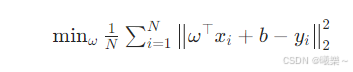
6.4 闭式解
线性回归可以直接通过数学公式一步算出最优 ω,不需要迭代。
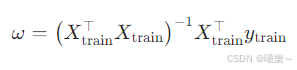
7 泛化、欠拟合、过拟合
7.1 泛化(Generalization)
模型在未见过的新数据上的表现,是机器学习核心目标。
Performance on unseen data is the core goal.
7.2 欠拟合(Underfitting)
模型太简单,训练误差高,测试误差高。(效果都不好)
Model too simple, high train & test error.
7.3 过拟合(Overfitting)
模型记住训练数据 ,训练误差极低,测试误差很高。(训练好,测试差)
Model memorizes training data, good train, bad test.
7.4 控制方法
- 调整模型容量(Adjust model capacity)
- 增加训练数据(Increase training data)
- 正则化(Regularization):
- 不过拟合:模型平滑,预测稳健
- 过拟合:曲线疯狂抖动,死记数据
- 加正则化:曲线被 "拉平",不再乱抖
L1正则化:让部分权重直接变成 0 ,实现特征选择。
L2正则化:让权重变小,趋近于0,让模型更平滑。
- 选择合适假设空间(Proper hypothesis space)
8 PAC 学习框架(Probably Approximately Correct)
8.1 泛化误差(Generalization Error)
模型在真实分布 D 上的期望误差
8.2 经验误差(Empirical Error)
训练集上的平均误差R^(h)=m1∑i=1m1h(xi)=c(xi)
8.3 核心结论
ER\^(h)=R(h)PAC 给出样本复杂度、泛化边界、置信度的理论保证。
9 损失函数与优化
9.1 损失函数
损失函数用来衡量模型预测值 与真实标签之间的差异。
训练的本质就是:让这个差异尽可能小。
单样本损失:对一个样本 (xi,yi),模型输出 f(xi),损失函数L把它们映射成一个实数,表示误差大小。
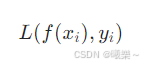
9.2 总损失(含正则化)
把所有样本的损失取平均+为了防止过拟合,加一个正则项 ,惩罚过于复杂的模型。
R(Θ):正则化项(如 L1、L2 正则)
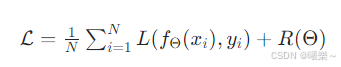
9.3 优化目标
寻找最优参数 Θ,最小化总损失minΘL
优化方法
- 梯度下降(Gradient Descent) 沿着损失函数的负梯度方向更新参数,一步步靠近最小值。
- **闭式解(Closed-form Solution)**线性回归专用,一步直接算出最优解。
- Adam、RMSprop、SGD深度学习最常用的优化器。