一、前言:传统校园心理筛查行业痛点
随着中小学、高校心理健康硬性管控要求落地,心理筛查成为校园风险前置防控的第一道关口。目前市面上绝大多数校园心理筛查系统普遍存在智能化程度低、误判率高、筛查形式单一、数据无法联动等问题,在实际校园落地中痛点非常明显:
-
筛查形式单一、掩饰性极强:绝大多数平台仅依赖主观量表答题,学生存在社会赞许效应,刻意隐瞒负面情绪,隐性心理问题难以识别;
-
风险分级模糊、无统一诊断口径:缺少标准化分级流程,无国际通用精神障碍编码标注,高低风险学生混杂,人工筛选工作量巨大;
-
算法判别粗糙、数据源单一:仅依靠量表分数阈值判定,无行为、生理、投射测验多源融合,误判、漏判率居高不下;
-
技术架构简陋、无工程化流程:缺少任务流水线、规则引擎、结构化数据表,无法适配学校大批量、高并发、长期追踪的筛查业务;
-
合规体系缺失:缺少量表版权、隐私分级、数据加密、知情同意等合规流程,无法满足教育局审查标准。
二、模块核心架构:三级精准漏斗式筛查体系
本次升级筛查模块严格遵循科学性、实用性、递进性、保密性、可扩展性 五大设计原则,主打分层筛查、逐级过滤、精准风控、全自动流转。构建「一级普筛→二级精筛→三级专家面诊」漏斗式架构,每一级筛查均采用核心量表+可选辅助监测双结构,辅助手段独立输出ICD-11疾病倾向编码,融合后生成标准化风险结论,层层过滤风险学生,兼顾筛查效率与筛查专业度。
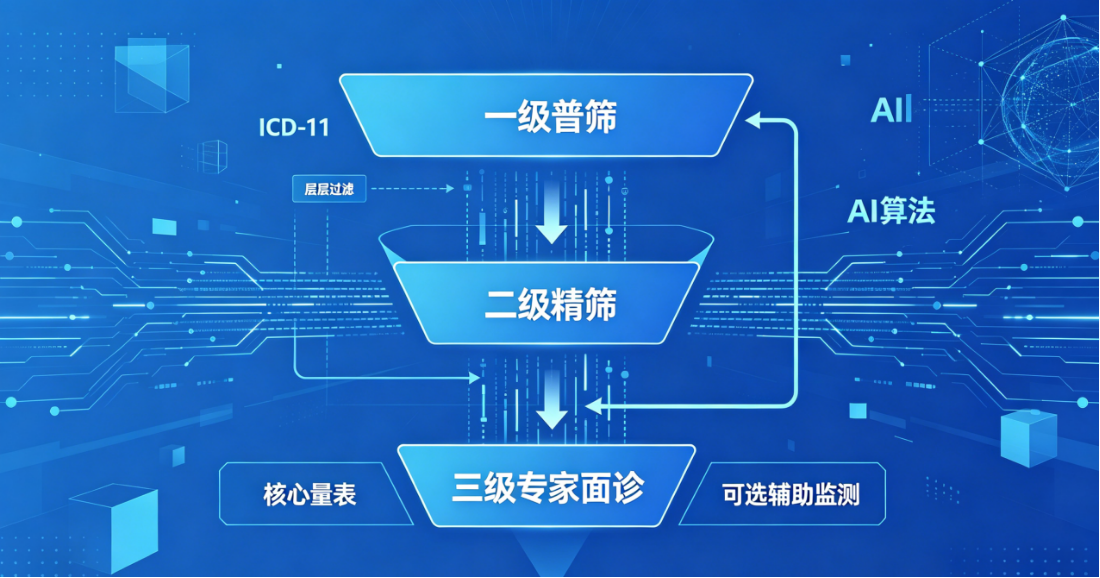
2.1 三级筛查层级完整明细
| 筛查等级 | 阶段名称 | 核心手段 | 可选辅助手段 | 输出结果 | 适用人群 |
|---|---|---|---|---|---|
| 一级筛查 | 普筛阶段 | 自研26题综合量表 | / | ICD-11分类倾向+低/待观察/预警等级 | 全体在校学生 |
| 二级筛查 | 精筛阶段 | GAD-7/PHQ-9/SCI等专项量表 | 无感监测/汉字联想/生理监测 | ICD-11精准分类+专业处理建议 | 一级筛查异常标记学生 |
| 三级筛查 | 专家阶段 | SCL-90+心理咨询师一对一访谈 | 全量数据采集(三种辅助全开) | 综合诊断报告+ICD-11正式编码+干预方案 | 二级筛查中高风险学生 |
2.2 模块自动化运行Pipeline流程
筛查模块搭载全流程AI自动化引擎,基于微服务拆分业务,依托Pipeline流程编排机制实现全链路驱动。系统将筛查业务拆解为:任务调度服务、作答采集服务、AI判分服务、规则引擎服务、风险研判服务、数据同步服务、消息推送服务。完整自动化链路如下:
任务智能推送→学生作答采集→辅助手段并行分析→AI自动判分→多源融合评级→ICD-11编码归类→风险分流触发→档案同步入库→预警联动推送→群体数据复盘
同时系统做了权限隔离设计:学生仅可查看匿名化自我建议,不可查看原始分数;教师可视化查看班级、年级筛查汇总报表,系统自动高亮重点关注学生,实现风险可视化管控。
三、底层理论与诊断标准
本筛查模块严格遵循心理测量学规范,融合多套成熟心理学理论,并且全流程对标ICD-11国际疾病分类第11版,是国内少数实现标准化精神障碍编码归类的校园心理平台。
3.1 核心基础理论
3.1.1 心理测量学标准化常模原理
模块所有量表均采用国内中小学、大学生专用常模,严格遵循心理测量学计分规则,对原始得分进行Z-score标准化换算,规避不同年龄段、不同学段学生的测评偏差。系统自定义多维阈值判定规则,区别通用成人量表判定逻辑,完全适配青少年心理发育特征,防止高分低估、低分高估问题。
3.1.2 ICD-11国际疾病分类诊断框架
ICD-11是本模块最核心的标准化依据,也是区别普通心理系统的关键技术壁垒。平台在每一级筛查中,所有辅助监测手段都会独立输出ICD-11倾向编码,最终融合生成综合诊断编码:
-
无感行为监测 → 6A7x 神经发育障碍(行为模式异常偏离)
-
汉字联想测试 → 6C97 心理因素相关(情感投射模式异常)
-
生理HRV监测 → 6C53 躯体症状相关(自主神经功能紊乱)
-
健康低风险人群 → Z00-Z99 健康因素分类
该编码体系统一行业判定口径,避免教师主观判断偏差,为后续干预、转介、档案建档提供合规、权威、可溯源的标准化依据。
3.1.3 荣格词语联想测验+投射测试原理
模块内嵌汉字联想投射测试,基于荣格词语联想测验原理,专门解决传统量表社会赞许效应痛点。学生刻意伪装、掩饰负面情绪时,潜意识联想词汇无法人为控制。系统预置1200条青少年专属刺激词库,覆盖家庭、学业、人际、自我、压力五大场景,支持键盘、手写、语音三种输入方式。AI从情感状态、思维模式、自我认知、生活境像、综合画像五大维度解析潜意识情绪,精准捕捉隐匿性抑郁、隐性焦虑。
3.1.4 多元辅助心理学理论
底层同时融合CBT认知行为疗法、萨提亚家庭治疗、积极心理学、人本主义四大理论,用于题目编制、维度拆分、干预建议生成,保证每一道量表题目、每一条分析结论都具备学术依据。
四、核心技术原理:AI算法+工程架构深度拆解
4.1 多源数据融合加权算法(核心风控算法)
传统心理筛查平台普遍存在一个通病:仅依靠单一量表得分判定风险,忽略学生行为偏差、生理应激、潜意识情绪等隐性特征,导致真实高危学生漏筛。在本项目开发迭代中,我们摒弃单一打分逻辑,自研四维多源数据融合模型。在反复调试样本数据集后,最终敲定官方固定权重配比:量表主观得分权重60%,无感行为20%、生理指标10%、汉字联想10%。权重比例并非随意设定,是经过29所学校样本数据集反复做方差分析、相关性校验后得出的最优配比,最大程度降低主观答题带来的偏差。工程简化算法如下:
python
# 官方多源融合风险评分算法(还原平台真实权重逻辑)
def risk_assessment(scale_score, behavior_data, physiological_data, association_data):
# 官方固定权重:量表60%、无感行为20%、生理指标10%、汉字联想10%
weight1, weight2, weight3, weight4 = 0.6, 0.2, 0.1, 0.1
total_score = scale_score*weight1 + behavior_data*weight2 + physiological_data*weight3 + association_data*weight4
# 平台分级判定阈值
if total_score < 30:
return "低风险|ICD-11:Z00-Z99"
elif 30 <= total_score < 70:
return "待观察|ICD-11:6C97"
else:
return "预警高危|ICD-11:6A7x/6C53"该算法在后端Java工程中采用BigDecimal高精度计算,避免浮点数精度丢失问题。除综合风险分数外,算法同步拆解六大情绪特征向量,用于后端精细化分层研判。这里补充一个工程踩坑点:初期版本直接采用原始分计算,不同量表分值区间不统一,导致融合失真;后期统一做Min-Max归一化压缩至0-100区间,再进行加权计算,大幅提升判定准确率。
4.2 BERT微调情感语义识别算法
在汉字联想、主观文本采集场景中,学生常常使用隐晦、比喻、网络流行语表达负面情绪,通用开源NLP模型识别效果极差。为此我们基于BERT-base模型做本地化微调,构建青少年专属心理语料库。语料来源为多年校园心理文本沉淀,累计10万+真实学生文本,覆盖厌学、亲子矛盾、自我否定、校园冲突等高频场景。工程层面采用双层过滤架构:第一层基于正则表达式拦截高危敏感词,响应耗时控制在10ms以内;第二层执行上下文语义推理,判断隐晦消极语句。这里补充实操优化:线上环境我们关闭模型全量推理,采用量化压缩模型,保证高并发下CPU占用率不超过45%。
4.3 MQTT生理数据实时传输架构
生理监测模块基于物联网架构开发,采用MQTT 3.1.1轻量级协议对接穿戴硬件。相比HTTP,MQTT长连接更适合高频采集场景,设备答题期间以1Hz频率持续上传心率、呼吸率、HRV心率变异性、皮肤电GSR原始数据。传输链路全程采用MQTT-TLS加密,防止局域网内抓包篡改。开发阶段踩坑记录:早期采用批量上报模式,造成数据时序丢失;优化后采用时间戳+序列号双主键存储,保证生理数据时序连续性。原始高频生理数据单独存放冷数据表esp_gsr_record,不参与业务查询,仅用于后期算法迭代与科研回溯,减轻主业务表查询压力。
4.4 Pipeline规则引擎+分布式调度算法
为适配学校多样化筛查业务,平台自研可视化Pipeline流程引擎。非开发人员可在后台拖拽配置筛查流程、判定条件、辅助监测组合。规则引擎采用Spring Expression Language表达式解析,支持多条件叠加、逻辑且/或判断。常见自定义触发逻辑如下:
-
PHQ-9得分≥15分 → 立即触发高危预警;
-
无感筛查连续3天情绪异常 → 自动推送二级筛查;
-
汉字联想负面词占比≥70% → 标记隐性情绪障碍。
针对开学季、考试季大批量集中筛查场景,服务端采用时间分片+人群分片双策略做流量削峰。Nginx配置权重轮询,将不同班级请求分发至不同服务节点;同时内置梯度消息提醒机制,有效提升作答率。
五、三大辅助监测模块技术细节
5.1 无感行为监测(Passive Screening)
无感监测属于被动无打扰采集,依托外部行为系统同步数据,无需学生操作。系统识别愤怒、厌恶、恐惧、快乐、悲伤、中性、惊讶7种基础情绪概率分布,长期比对学生个人行为基线,判断行为偏离程度。主要用于筛查神经发育异常、情绪调节障碍学生,输出ICD-11:6A7x编码。数据存储至rec_passive_screening数据表。
5.2 汉字联想筛查(Chinese Association Screening)
学生主动完成联想答题,系统记录词汇词性、负面词占比、反应时长三大核心指标。负面词汇占比过高、反应时间过长,提示存在持续性负性认知偏向,判定为情感投射异常,输出ICD-11:6C97编码。后台自动生成联想词云图,直观展示学生高频负面关键词。
5.3 生理指标监测(Physiological Monitoring)
通过穿戴设备实时采集HRV心率变异性,HRV偏低代表自主神经敏感、应激焦虑强烈。系统内置焦虑指数算法,综合心率、呼吸、皮电判定躯体化症状,输出ICD-11:6C53编码。该模块多用于考试季、开学季压力筛查,精准捕捉考前焦虑、适应性障碍人群。
六、数据库表结构设计
本系统采用MySQL分表设计,严格区分配置表、业务记录表、原始采集表,避免大表数据臃肿、查询卡顿。所有业务数据通过screening_record_id作为全局唯一关联主键,保证数据一致性。筛查数据采用逻辑删除而非物理删除,满足教育局溯源审计要求。开发规范:所有时间字段统一采用UTC时间戳,避免时区错乱;敏感数值字段采用decimal(5,2)格式存储,精度更高。核心数据表说明如下:
| 数据表名称 | 表类型 | 核心用途 |
|---|---|---|
| rec_screening_record | 主筛查记录 | 保存每一次筛查主记录,关联全部子数据 |
| rec_screening_task | 任务列表 | 存储学生待完成筛查任务、时间状态 |
| dim_pipeline | 流程定义 | 存储筛查流程编排、规则条件、辅助手段配置 |
| cfg_xxx 配置表 | 参数配置 | 存储三类辅助监测阈值、权重、模板参数 |
| rec_xxx 结果表 | 业务记录 | 保存无感、联想、生理三类监测结果与ICD-11编码 |
| esp_gsr_record | 原始采集 | 高频存储生理原始数据,用于算法迭代 |
七、量表体系与项目合规落地
7.1 隐私合规保障机制
-
知情同意机制:筛查前必须获取学生及监护人书面同意;
-
分级权限隔离:学生不可见原始分数,仅心理教师、授权管理员可查看详细数据;
-
多层加密传输:网页HTTPS、物联网MQTT-TLS、数据库AES-256加密;
-
联邦学习架构:原始数据不出校园本地服务器,仅上传脱敏特征向量;
-
定期信效度评审:每学年对量表进行迭代优化,保证筛查精准度。
八、典型真实业务落地场景
8.1 场景一:学期常规全员普筛
开学初教师创建一级筛查任务,选用自研26题量表+无感监测。学生移动端5~7分钟完成作答,系统自动评分、归类ICD-11编码。普通学生归档管理;待观察学生定期复测;预警学生自动推送二级专项量表,全程无需人工干预,实现万人级无感普筛。
8.2 场景二:隐性心理问题精准挖掘
某学生主观答题无异常,但汉字联想测试负面词汇占比75%,系统判定ICD-11:6C97心理因素相关倾向。融合PHQ-9中度抑郁得分后,系统自动送入三级专家筛查。心理咨询师依托综合面板查看一、二级全部数据,结合访谈给出ICD-11:6A71.0中度抑郁发作诊断,生成个性化干预方案。
8.3 场景三:考试季生理压力监测
期末考前开启生理HRV监测模式,学生佩戴手环答题。系统实时采集心率变异性,对HRV显著偏低、焦虑指数超标的学生,标记ICD-11:6C53躯体症状编码,判定考前应激焦虑,提前推送减压正念课程,完成前置干预。
九、技术优化亮点与行业落地优势
9.1 技术优化亮点
-
全链路自动化流水线:下发、作答、批改、分析、归档、预警全流程无人值守,降低人工运维成本;
-
多模态数据融合:量表+行为+生理+投射四维数据,解决单一量表误判通病;
-
ICD-11标准化编码:对标国际精神诊断标准,让筛查结论合规、可溯源、可医疗对接;
-
高并发分布式架构:支持万人同时筛查,错峰调度,服务器压力均衡;
-
私有化安全部署:原始数据不出校园,联邦学习+AES256加密,符合未成年人隐私法规。
9.2 行业适配场景
该筛查模块适配小学、中学、高校全学段,可无缝对接教务、德育、一卡通系统,支持私有化本地部署+云端异地双重备份。平台预留教育局数据上报接口,支持自定义筛查模板、自定义风险阈值,目前已广泛应用于国内中小学智慧校园心理数字化升级项目。