一、引言
分布式锁怎么选?这个问题没有标准答案。
但有一条铁律:场景决定技术。
你的系统如果只是防止重复执行、避免资源浪费,Redis 足够了。如果你的系统一旦锁失效会造成数据损坏、金钱损失,那 Redis 就不够,你需要 ZooKeeper 或者 etcd。
为什么?往下看。
二、Redis 分布式锁:甜蜜的陷阱
2.1 最简单的锁,最要命的坑
用 Redis 做分布式锁,99% 的开发者都会这么写:
bash
SET lock_key 1 NX PX 10000一条命令,原子操作,10 秒过期。看起来完美。
但它有三个致命的坑。
第一坑:锁过期,业务还没完。
你设了 10 秒过期。但业务因为 GC 停顿、网络抖动、磁盘 IO 阻塞,跑了 15 秒。锁在第 10 秒自动释放了。此时另一个线程抢到锁,你的业务还没跑完,两个线程同时操作共享资源------数据一致性直接崩盘。
这就是经典的 Zombie Worker 问题:客户端在锁过期后仍然以为自己持有锁,继续执行临界区代码。
第二坑:释放锁,删了别人的。
你跑完业务,执行 DEL lock_key。但此时锁已经过期了,被其他客户端抢走了。你这一删,删的是别人的锁。其他客户端还在"被保护"地跑业务呢,你又可以进来加锁了------互斥性荡然无存。
第三坑:SETNX + EXPIRE,原子性陷阱。
bash
SETNX lock_key 1 # 执行完,服务器挂了
EXPIRE lock_key 10 # 这行没执行锁永远不释放,系统死锁。
这三坑,每一个都是生产事故的高发区。
2.2 Redisson 的"看门狗":给锁续命
Redisson 的解决方案是 Watchdog(看门狗)机制。
加锁成功后,Redisson 会启动一个后台线程,默认每 10 秒检查一次(lockWatchdogTimeout / 3)。如果业务还没完成,就自动把锁的过期时间重置为 30 秒。只要客户端活着,锁就永远不过期。业务执行完,主动 unlock,看门狗随之退出。
注意:看门狗只在你不主动指定锁过期时间(leaseTime = -1)时才生效。如果你手动指定了过期时间,Redisson 认为你清楚自己在干什么,不会启动看门狗。
2.3 解决"误删锁":Lua 脚本的原子操作
释放锁不能直接 DEL,要先校验这个锁是不是"我"加的。
Redisson 的做法是:加锁时,Value 存的是一个唯一 ID(UUID + 线程 ID)。释放锁时,用 Lua 脚本原子地校验并删除:
Lua
if redis.call("GET", KEYS[1]) == ARGV[1] then
return redis.call("DEL", KEYS[1])
else
return 0
endRedis 保证 Lua 脚本执行期间不会插入其他命令,校验和删除是一体的。
2.4 主从切换:最隐蔽的雷
以上所有方案,都假设 Redis 是单机。但生产环境你一定会用主从 + Sentinel 做高可用。
这里藏着一个致命的场景:
-
Client A 在主节点上成功加了锁
-
主节点还没来得及把这条数据同步给从节点,就挂了
-
Sentinel 把从节点提升为新主节点
-
Client B 连接到新主节点,加锁------成功了
-
此时 A 和 B 都以为自己持有锁
主从异步复制导致了锁状态的丢失。主从切换的时间窗口内,互斥性被打破。
这是 Redis 分布式锁最大的结构性缺陷,无法在单实例模型下彻底解决。
2.5 Redlock:Redis 官方的高可用方案
为了解决主从切换导致的锁丢失,Redis 作者 Antirez 提出了 Redlock 算法。
Redlock 的核心思想是:不依赖单个 Redis 实例,而是向 N 个独立的 Redis 主节点(通常 5 个)同时申请锁。客户端只有在超过半数(N/2 + 1)的节点上成功加锁,才算获取锁成功。
流程大致如下: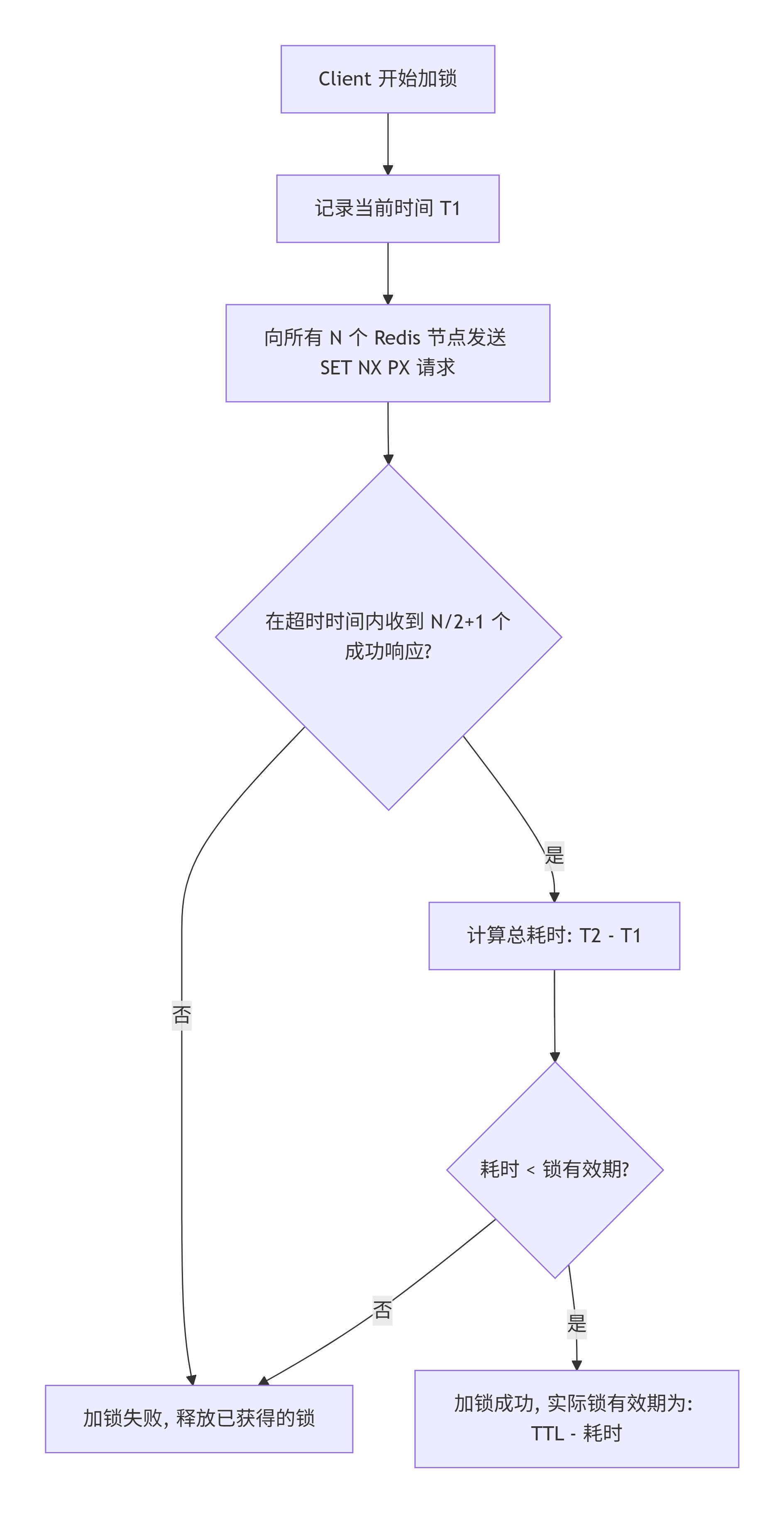
Redlock 的巧妙之处在于:只要半数以上节点正常工作,锁就不会丢失。即使少数节点宕机或网络分区,锁依然可用。
2.6 Redlock 的争议:一场轰动业界的辩论
2016 年,DDIA 的作者 Martin Kleppmann 发表了一篇博客,标题是《How to do distributed locking》,对 Redlock 提出了尖锐的质疑。
Martin 的核心论点是:Redlock 依赖系统时钟的准确性,而在分布式系统中,时钟是不可靠的。
Redlock 在两个关键环节使用了本地时间:
-
锁的过期时间基于 Redis 节点的本地时钟
-
客户端计算锁有效期时,依赖两次本地时间的差值
Martin 举了一个反例:客户端 A 获取锁后,在操作共享资源前发生了 GC Stop-The-World。GC 期间锁过期了。客户端 B 获取到锁。GC 结束后,客户端 A 继续执行------两个客户端同时操作共享资源。
GC 只是冰山一角。还有:
-
网络延迟和重传
-
Page fault 导致的磁盘交换
-
虚拟机热迁移时的暂停
-
NTP 时钟同步导致的时钟回退
-
闰秒问题
其中时钟回退是最致命的------如果 NTP 同步把系统时间往回拨了几十毫秒,依赖时间比较的锁有效性判断会直接失效。
Martin 将分布式锁的使用场景分为两类:
-
Efficiency(效率型) :目标是避免重复工作、节省资源。锁失效的代价很小,比如多发了封邮件、多跑了一次报表。
-
Correctness(正确性型) :目标是防止并发操作破坏数据一致性。锁失效的代价是灾难性的,比如重复扣款、文件损坏。
Martin 的结论是:Redlock 对于 Efficiency 场景足够,但对于 Correctness 场景不安全。
2.7 Antirez 的回应
面对质疑,Antirez 也发表了长文回应。
他的核心观点是:
-
时钟问题被夸大了。合理的 NTP 配置可以将时钟漂移控制在毫秒级,远小于锁的过期时间(通常是几十秒)。
-
GC 问题不是 Redlock 独有的。任何基于超时的锁机制都会受 GC 影响,ZooKeeper 的 session 超时同理。
-
可以通过 fencing token(栅栏令牌)来增强安全性:每次加锁成功时返回一个单调递增的 token,共享资源在写入时校验 token,拒绝过期的写入。
Antirez 强调,Redlock 是在"高性能 "和"足够安全"之间做的工程权衡。如果追求绝对安全,任何依赖时间的锁都不够,但这在工程上并不现实。
这场辩论没有绝对的赢家。但它揭示了一个核心事实:任何依赖超时机制的分布式锁,都无法在理论上做到绝对正确。
三、ZooKeeper 分布式锁:可靠性的代价
3.1 核心原理:临时顺序节点 + Watcher
ZooKeeper 的锁实现,用四个字概括:优雅且可靠。
它的核心机制是:临时顺序节点 + Watcher 监听机制。
流程如下:
-
所有客户端在
/locks目录下创建一个临时顺序节点 (Ephemeral Sequential),ZK 自动分配递增序号,如lock-0000000001、lock-0000000002 -
客户端获取
/locks下所有子节点并排序,判断自己是否是最小序号 -
如果是最小序号,获取锁成功;否则,对前一个节点(不是父节点)注册 Watcher,进入等待
-
前一个节点的客户端释放锁(删除节点)或宕机(临时节点自动删除),Watcher 触发,当前客户端重新检查自己是否是最小序号
-
重复步骤 3-4,直到获取锁
这个机制的精妙之处在于:
-
临时节点 :客户端会话断开时,ZK 自动删除节点,锁自动释放,绝不死锁。
-
顺序节点:全局唯一、单调递增,天然保证公平性,不会饿死。
-
监听前一个节点:避免"羊群效应"。如果所有等待者都监听父节点,一个节点删除会导致所有客户端同时唤醒,造成惊群。
3.2 底层支撑:ZAB 协议
ZooKeeper 之所以能保证锁的强一致性,底层依赖的是 ZAB(ZooKeeper Atomic Broadcast)协议。
ZAB 是专为 ZooKeeper 设计的原子广播协议,有两个核心模式:
-
消息广播模式:Leader 接收写请求,将事务 Proposal 广播给所有 Follower。收到半数以上 Ack 后,Leader 发送 Commit 指令,Follower 执行提交。
-
崩溃恢复模式:Leader 宕机时,集群选举新 Leader,新 Leader 确保已提交的事务在所有节点上一致。
这意味着:任何一次锁的创建或删除,都必须经过过半节点的确认。不存在 Redis 主从切换时的那种"写入主节点但未同步到从节点"的信息丢失窗口。
3.3 ZK 锁的"坑":Session 超时
ZK 锁并非完美。它的核心"坑"在于 Session 超时。
ZK 客户端与服务器之间维持一个 Session,有超时时间(通常是 30-60 秒)。如果客户端因为:
-
GC Stop-The-World 超过 SessionTimeout
-
网络长时间抖动
-
机器负载过高导致心跳线程无法及时发送
Session 就会过期,临时节点被 ZK 自动删除,锁被释放。
而此时,客户端的业务逻辑可能还在执行------它以为自己还持有锁,实际上已经"裸奔"了。
这和 Redis 的"锁过期业务没完"是同一个问题,只是触发条件从"主动设置的 TTL"变成了"被动检测的 Session 超时"。
解决思路有两个:
-
增大 SessionTimeout:比如设到 60 秒甚至更长,降低误判概率。但代价是,客户端真的宕机时,锁要等 60 秒才能释放。
-
业务层面做幂等:无论用什么锁,共享资源的操作都应该设计成幂等的。锁只是减少冲突,不能 100% 依赖。
3.4 ZK 锁的性能代价
强一致性是有成本的。
每一次加锁,ZK 需要:
-
客户端 → Leader(创建节点请求)
-
Leader → 所有 Follower(Proposal 广播)
-
所有 Follower → Leader(Ack 确认)
-
Leader → 所有 Follower(Commit 指令)
-
Leader → 客户端(响应)
至少 2 个网络 RTT(往返时间),加上磁盘写入。实测 P99 加锁延迟约 8-10ms,而 Redis 单机锁只有 1-2ms。
这就是为什么说 ZK 是"宁可慢,不可错"的悲观锁。
四、Redis vs ZooKeeper:终极对比
4.1 架构对比图


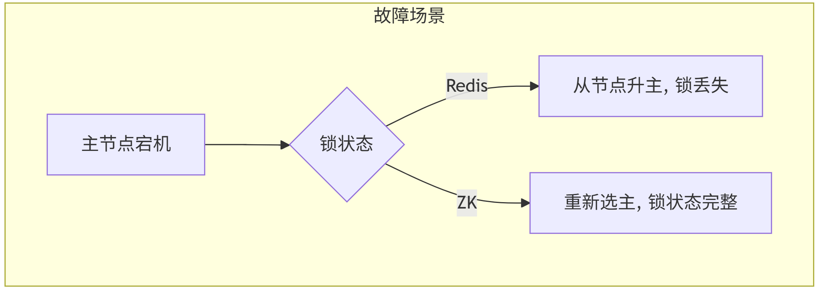
4.2 维度对比表
| 维度 | Redis(单机 / Redisson) | Redis Redlock | ZooKeeper |
|---|---|---|---|
| 一致性模型 | 最终一致 | 最终一致(依赖时钟) | 强一致(ZAB 协议) |
| 加锁延迟(P99) | 1-2ms | 2-5ms | 8-10ms |
| 锁自动释放 | TTL 过期 | TTL 过期 | 临时节点(Session 过期) |
| 主从切换安全性 | ❌ 不安全 | ⚠️ 部分改善 | ✅ 安全 |
| 客户端崩溃恢复 | TTL 内无法释放 | TTL 内无法释放 | Session 超时后自动释放 |
| 公平性 | 不支持(竞争式) | 不支持 | ✅ 支持(顺序节点) |
| 实现复杂度 | 低 | 中 | 中高 |
| 运维复杂度 | 低 | 中 | 高 |
4.3 核心差异的本质
Redis 的设计哲学是 AP(可用性 + 分区容错),ZooKeeper 的设计哲学是 CP(一致性 + 分区容错)。
Redis 的主从复制是异步的,追求极致的写入性能。数据从主节点同步到从节点有时间窗口,这个窗口内的一致性无法保证。
ZooKeeper 的写入必须经过过半节点的确认,牺牲了部分写入性能,换来了强一致性保证。在网络分区时,ZK 宁可拒绝服务,也不会让两个客户端同时拿到锁。
Redis 锁的"高性能"建立在接受小概率不一致之上;ZooKeeper 的"高可靠"是以增加网络往返和协调开销为代价。
五、选型指南
没有银弹,只有场景。
选择 Redis 的场景
-
秒杀扣库存(允许极小概率的超卖)
-
定时任务去重(跑两次问题不大)
-
缓存击穿保护(多重建一次缓存没大事)
-
任何 Efficiency 型场景
选择 ZooKeeper 的场景
-
金融交易(重复扣款不可接受)
-
分布式文件写入(文件损坏不可逆)
-
库存扣减(精确到个位数的库存)
-
任何 Correctness 型场景
折中选择:etcd
如果你想要强一致性(像 ZK),又想要更简单的 API 和运维(像 Redis),可以考虑 etcd。
etcd 基于 Raft 共识算法,提供线性一致性的分布式锁(Lease + Compare-And-Swap)。P99 延迟约 4-5ms,介于 Redis 和 ZK 之间,且避免了 ZK 的 Session 超时不可控问题。
Kubernetes 用 etcd 做配置中心,其可靠性经过了大规模生产验证。
最后的忠告
-
不要裸写 Redis 锁。用 Redisson 或 Redlock 库,它们帮你处理了续期、误删、可重入等细节。
-
锁的粒度要尽量小。锁住整个方法是性能杀手。
-
共享资源的操作要做幂等设计。锁只是减少冲突,不是解决冲突的唯一手段。
-
如果你用 Redis 做 Correctness 型锁,至少加上 fencing token。每次加锁返回递增 token,写共享资源时带上 token,资源方拒绝过期 token 的写入。
-
监控锁的持有时长。如果经常有锁持有超过 TTL 的情况,说明你的 TTL 设置不合理,或者业务逻辑有问题。
分布式锁这个话题,本质是在"性能"和"正确性"之间做权衡。理解了两种方案的核心原理和边界条件,你就能做出正确的技术决策。