vLLM v1 Executor --- 系统级架构深度分析
分析范围:
vllm/v1/executor/目录,8个Python文件,~3.5K行代码。Executor 是 v1 推理系统的"执行引擎"------连接调度器与 Worker,负责模型推理的多 GPU / 多节点编排。
Dark Terminal 风格架构图 10 张,见
diagrams/子目录。
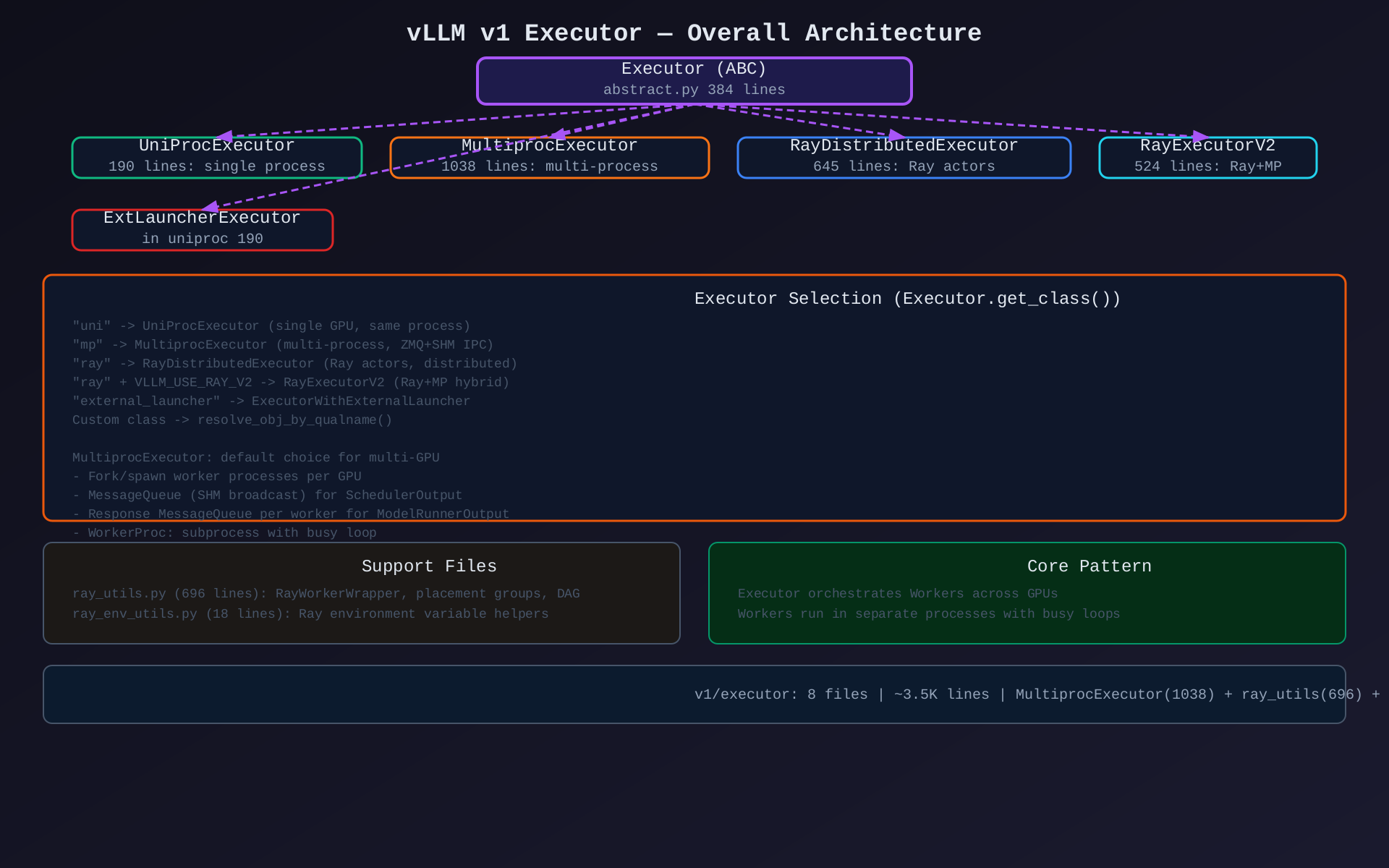
一、整体架构概览
1.1 设计思路
v1 Executor 采用 分层策略 + 广播-收集 架构:
- 抽象基类统一接口 :
Executor(ABC)定义所有执行器的契约 - 4种实现策略可插拔:UniProc / Multiproc / Ray / RayV2,按部署场景选择
- 广播-收集模式:所有分布式执行器统一 broadcast SchedulerOutput + collect ModelRunnerOutput
- 进程隔离:Worker 运行在独立子进程,通过 SHM/IPC 通信,避免 GIL 瓶颈
- 异步执行 :
execute_model()返回FutureWrapper,不阻塞调度器
核心设计哲学:
- Executor 是桥梁:连接 EngineCore(调度决策)和 Worker(GPU 推理)
- 进程隔离安全:Worker crash 不影响主进程,death_pipe 监控
- 零拷贝广播:SHM MessageQueue 实现 SchedulerOutput 的 1-to-N 广播
- 统一接口:无论单 GPU 还是多节点,EngineCore 只与 Executor 交互
1.2 架构模式
| 模式 | 应用 |
|---|---|
| 策略模式 | 4种 Executor 实现(Uni/Multiproc/Ray/RayV2) |
| 工厂方法 | Executor.get_class() 根据配置选择实现 |
| 广播-收集 | SHM broadcast SchedulerOutput + collect ModelRunnerOutput |
| Future 模式 | FutureWrapper 实现异步非阻塞执行 |
| 模板方法 | _init_executor() 由子类覆盖,公共逻辑在基类 |
| 代理模式 | RayWorkerWrapper 代理 Worker 为 Ray Actor |
| 观察者模式 | death_pipe + monitor_workers 监控进程健康 |
1.3 整体运行流程
EngineCore.__init__()
├── Executor.get_class(vllm_config) # 工厂方法选择实现
└── executor._init_executor() # 初始化 Workers
EngineCore.step()
├── executor.execute_model(scheduler_output)
│ ├── Broadcast: scheduler_output -> all workers (SHM)
│ ├── Each worker: execute_model() -> ModelRunnerOutput
│ └── Collect: aggregate ModelRunnerOutput across ranks
└── Return FutureWrapper / ModelRunnerOutput
executor.check_health() # 定期健康检查
executor.collective_rpc(method) # 广播 RPC(lora, profile, sleep...)
executor.shutdown() # 终止所有 Worker二、子模块划分
模块1:Executor ABC(abstract.py,384行)
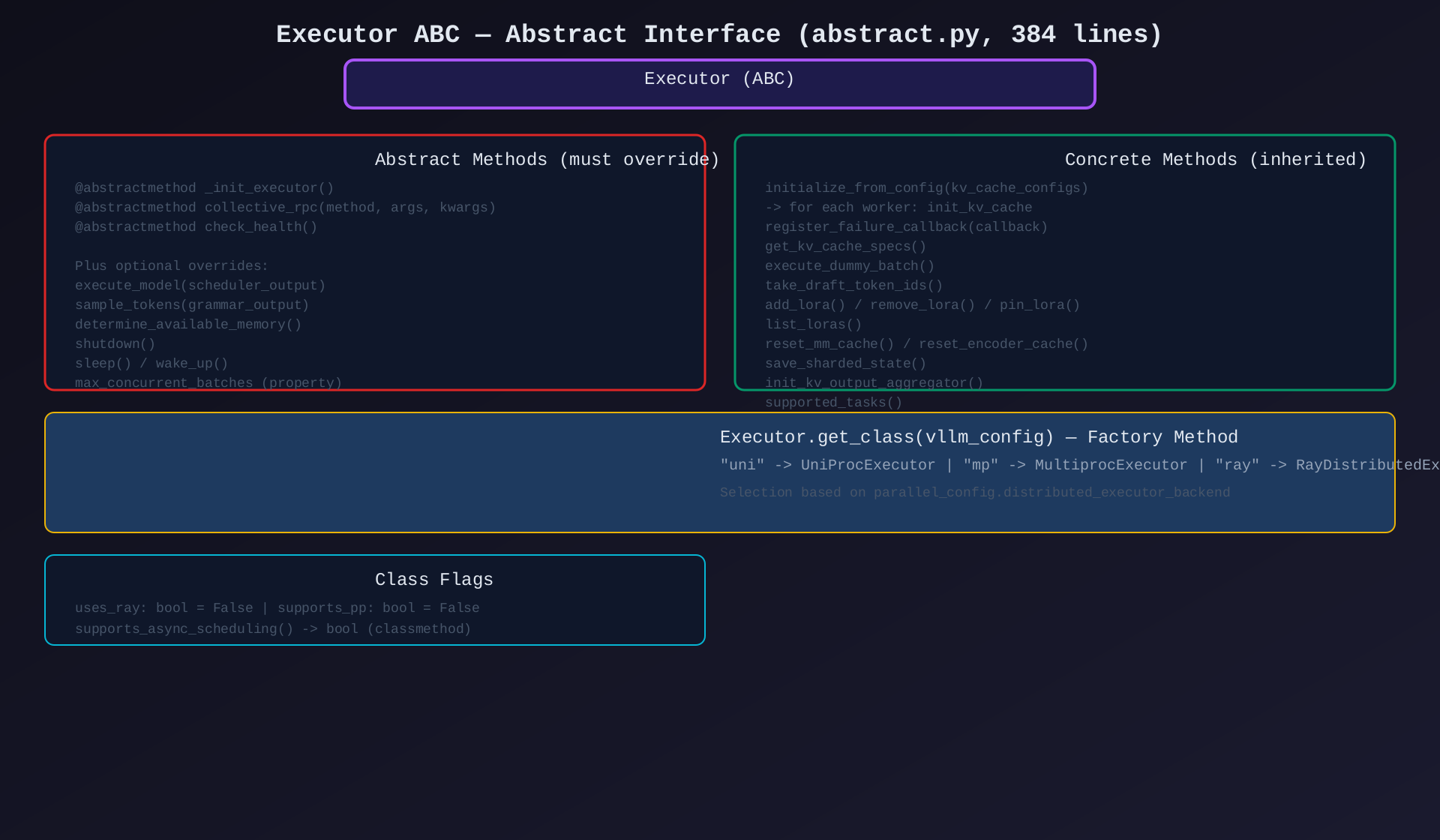
核心作用:所有执行器的抽象基类------定义统一接口、工厂方法、公共逻辑。
关键类/方法:
| 类/方法 | 类型 | 说明 |
|---|---|---|
Executor(ABC) |
类 | 抽象基类,所有执行器的父类 |
get_class(vllm_config) |
静态方法 | 工厂方法,根据配置返回具体实现 |
_init_executor() |
抽象方法 | 子类必须覆盖的初始化逻辑 |
collective_rpc(method, args, kwargs) |
抽象方法 | 广播 RPC 到所有 Worker |
check_health() |
抽象方法 | 健康检查 |
execute_model(scheduler_output) |
方法 | 执行模型推理(含默认实现) |
sample_tokens(grammar_output) |
方法 | 仅采样(跳过模型前向) |
determine_available_memory() |
方法 | 查询可用显存 |
initialize_from_config() |
方法 | 初始化 KV Cache 配置 |
register_failure_callback() |
方法 | 注册失败回调 |
sleep() / wake_up() |
方法 | 休眠/唤醒(用于弹性伸缩) |
max_concurrent_batches |
属性 | 最大并发批次数 |
uses_ray |
类属性 | 是否使用 Ray(默认 False) |
supports_pp |
类属性 | 是否支持流水线并行(默认 False) |
工厂方法选择逻辑:
| 配置值 | 返回类 |
|---|---|
"uni" |
UniProcExecutor |
"mp" |
MultiprocExecutor |
"ray" |
RayDistributedExecutor |
"ray" + VLLM_USE_RAY_V2 |
RayExecutorV2 |
"external_launcher" |
ExecutorWithExternalLauncher |
| 自定义类路径 | resolve_obj_by_qualname() |
架构图 :见 02-executor-abc.svg
模块2:MultiprocExecutor(multiproc_executor.py,1038行)
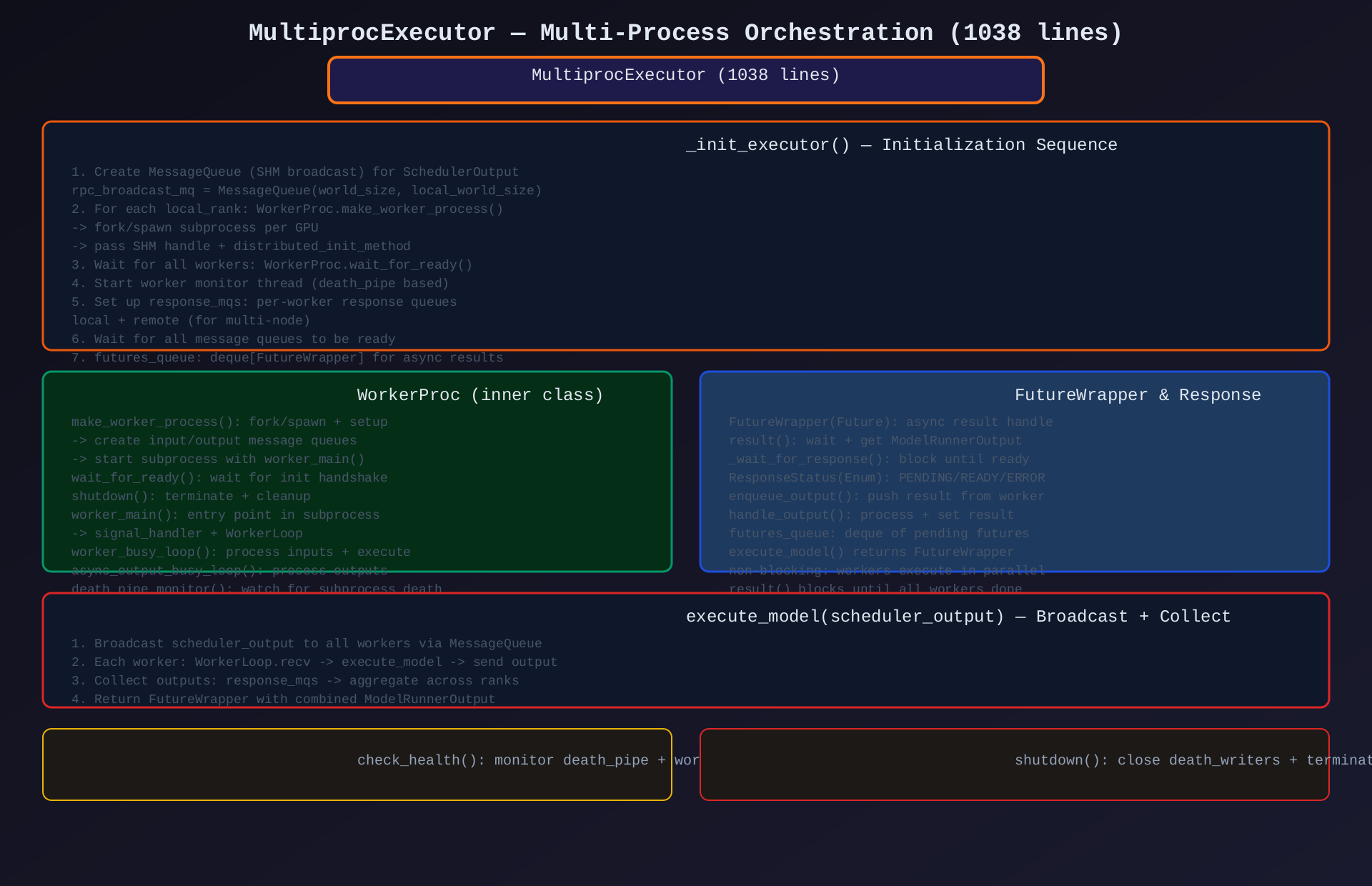
核心作用:多进程执行器------v1 的默认分布式执行后端,每 GPU 一个子进程,SHM IPC 通信。
关键类/方法:
| 类/方法 | 说明 |
|---|---|
MultiprocExecutor |
多进程执行器主类 |
FutureWrapper(Future) |
异步结果包装器 |
WorkerProc |
Worker 子进程管理 |
UnreadyWorkerProcHandle |
未初始化的 Worker 句柄 |
WorkerProcHandle |
已初始化的 Worker 句柄 |
ResponseStatus(Enum) |
响应状态:PENDING/READY/ERROR |
初始化流程 (_init_executor()):
- 创建
rpc_broadcast_mq:SHM 广播队列(SchedulerOutput 1→N) - 为每个 local_rank 创建
WorkerProc.make_worker_process():- fork/spawn 子进程
- 传递 SHM handle + distributed_init_method
WorkerProc.wait_for_ready():等待所有 Worker 初始化完成- 启动
worker_monitor线程(death_pipe 监控) - 建立
response_mqs:每个 Worker 的响应队列 - 等待所有 MessageQueue 就绪
执行流程 (execute_model()):
- 将
scheduler_output广播到rpc_broadcast_mq - 每个 Worker 子进程接收并执行
worker.execute_model() - Worker 通过
worker_response_mq返回ModelRunnerOutput - 收集所有 Worker 响应,聚合成最终结果
- 返回
FutureWrapper(非阻塞)
Worker 子进程内部:
worker_main():子进程入口,注册信号处理器worker_busy_loop():循环接收 input → 执行 → 发送 outputasync_output_busy_loop():异步输出处理循环death_pipe_monitor():监控子进程死亡
架构图 :见 03-multiproc-executor.svg
模块3:WorkerProc & IPC(multiproc_executor.py 内部类 + MessageQueue)
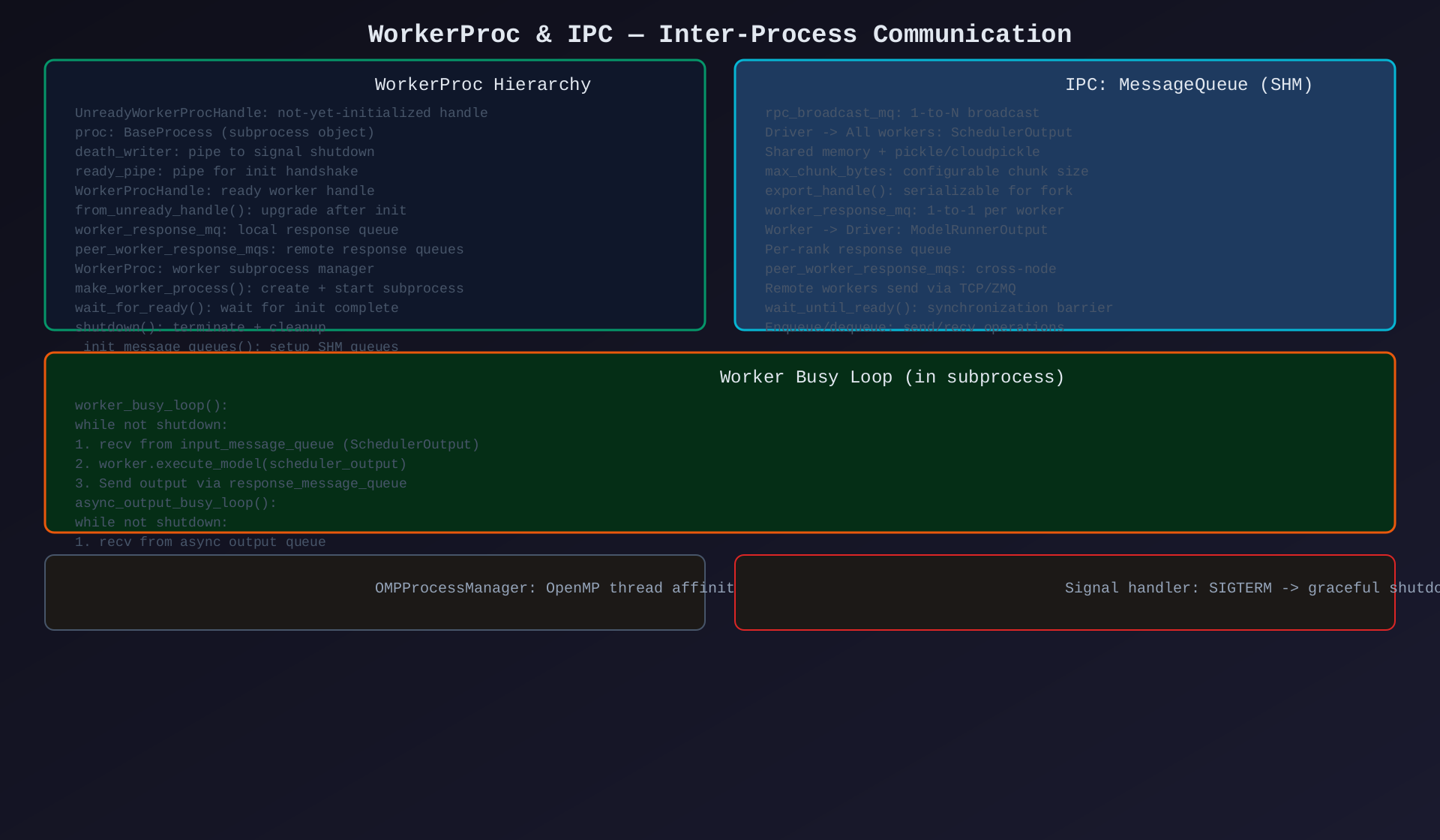
核心作用:Worker 子进程管理 + 进程间通信------确保高效、可靠的数据传输。
WorkerProc 类层次:
| 类 | 说明 |
|---|---|
UnreadyWorkerProcHandle |
未初始化句柄:proc + death_writer + ready_pipe |
WorkerProcHandle |
已初始化句柄:worker_response_mq + peer_worker_response_mqs |
WorkerProc |
子进程管理器:make_worker_process() + wait_for_ready() + shutdown() |
IPC 机制:
| 通道 | 方向 | 协议 | 用途 |
|---|---|---|---|
rpc_broadcast_mq |
Driver → All Workers | SHM + pickle | 广播 SchedulerOutput |
worker_response_mq |
Worker → Driver | SHM | 单 Worker 的 ModelRunnerOutput |
peer_worker_response_mqs |
Remote Worker → Driver | TCP/ZMQ | 跨节点响应 |
death_pipe |
Worker → Monitor | pipe | 子进程死亡通知 |
ready_pipe |
Worker → Driver | pipe | 初始化完成握手 |
关键方法:
| 方法 | 说明 |
|---|---|
WorkerProc.make_worker_process() |
创建子进程 + 设置 IPC |
WorkerProc.wait_for_ready() |
等待所有 Worker 初始化 |
WorkerProc.shutdown() |
终止子进程 + 清理资源 |
WorkerProc._init_message_queues() |
初始化 SHM 消息队列 |
worker_busy_loop() |
Worker 主循环:recv→exec→send |
async_output_busy_loop() |
异步输出处理循环 |
death_pipe_monitor() |
监控子进程健康 |
setup_proc_title_and_log_prefix() |
设置进程标题 |
架构图 :见 04-worker-proc-ipc.svg
模块4:UniProcExecutor(uniproc_executor.py,190行)
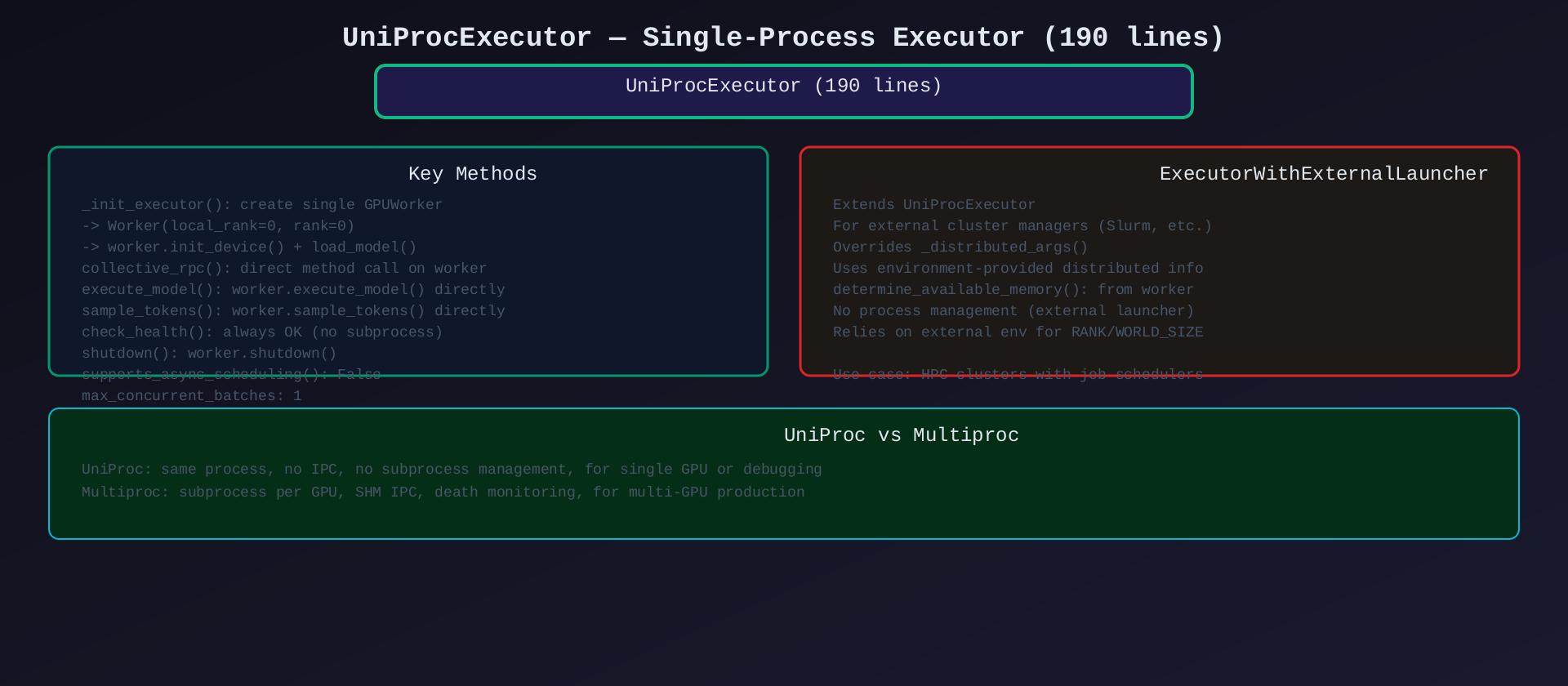
核心作用:单进程执行器------最简单的实现,Worker 与 EngineCore 同进程运行。
关键类/方法:
| 类/方法 | 说明 |
|---|---|
UniProcExecutor |
单进程执行器 |
_init_executor() |
创建单个 GPUWorker,直接 init_device + load_model |
execute_model() |
直接调用 worker.execute_model()(无 IPC) |
sample_tokens() |
直接调用 worker.sample_tokens() |
collective_rpc() |
直接调用 Worker 方法 |
check_health() |
始终返回 OK(无子进程) |
shutdown() |
worker.shutdown() |
max_concurrent_batches |
固定返回 1 |
supports_async_scheduling() |
返回 False |
ExecutorWithExternalLauncher:
| 属性 | 说明 |
|---|---|
| 继承 UniProcExecutor | |
| 用途 | 外部集群管理器(Slurm 等) |
_distributed_args() |
从环境变量获取 RANK/WORLD_SIZE |
determine_available_memory() |
从 Worker 查询 |
架构图 :见 05-uniproc-executor.svg
模块5:RayDistributedExecutor(ray_executor.py,645行)
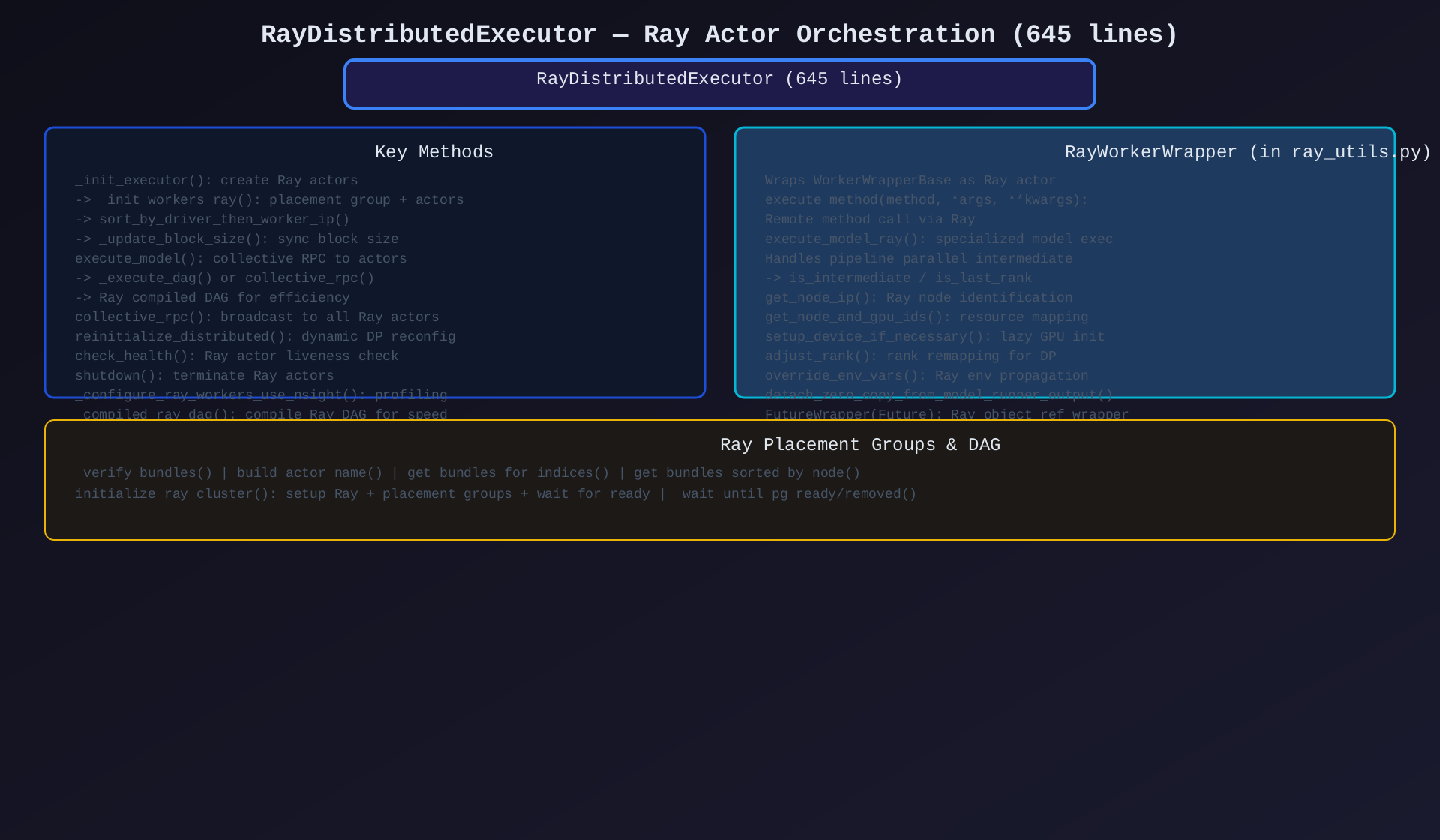
核心作用:Ray 分布式执行器------基于 Ray Actor 的分布式编排,支持 Ray DAG 编译加速。
关键类/方法:
| 类/方法 | 说明 |
|---|---|
RayDistributedExecutor |
Ray 分布式执行器 |
RayWorkerMetaData |
Ray Worker 元数据(actor handle + IP + GPU IDs) |
_init_executor() |
创建 Ray actors + placement groups |
_init_workers_ray() |
初始化 Ray workers(排序、资源分配) |
execute_model() |
执行模型(DAG 或 collective_rpc) |
_execute_dag() |
Ray 编译 DAG 执行路径 |
_compiled_ray_dag() |
编译 Ray DAG |
collective_rpc() |
广播到所有 Ray actors |
reinitialize_distributed() |
动态数据并行重配置 |
check_health() |
Ray actor 存活检查 |
shutdown() |
终止 Ray actors |
Ray 编译 DAG:
_check_ray_cgraph_installation():验证 Ray DAG 编译环境_compiled_ray_dag(enable_asyncio):编译计算图,减少 Ray 调度开销_execute_dag():通过编译 DAG 执行,比逐次 RPC 更高效
架构图 :见 06-ray-executor.svg
模块6:RayExecutorV2(ray_executor_v2.py,524行)
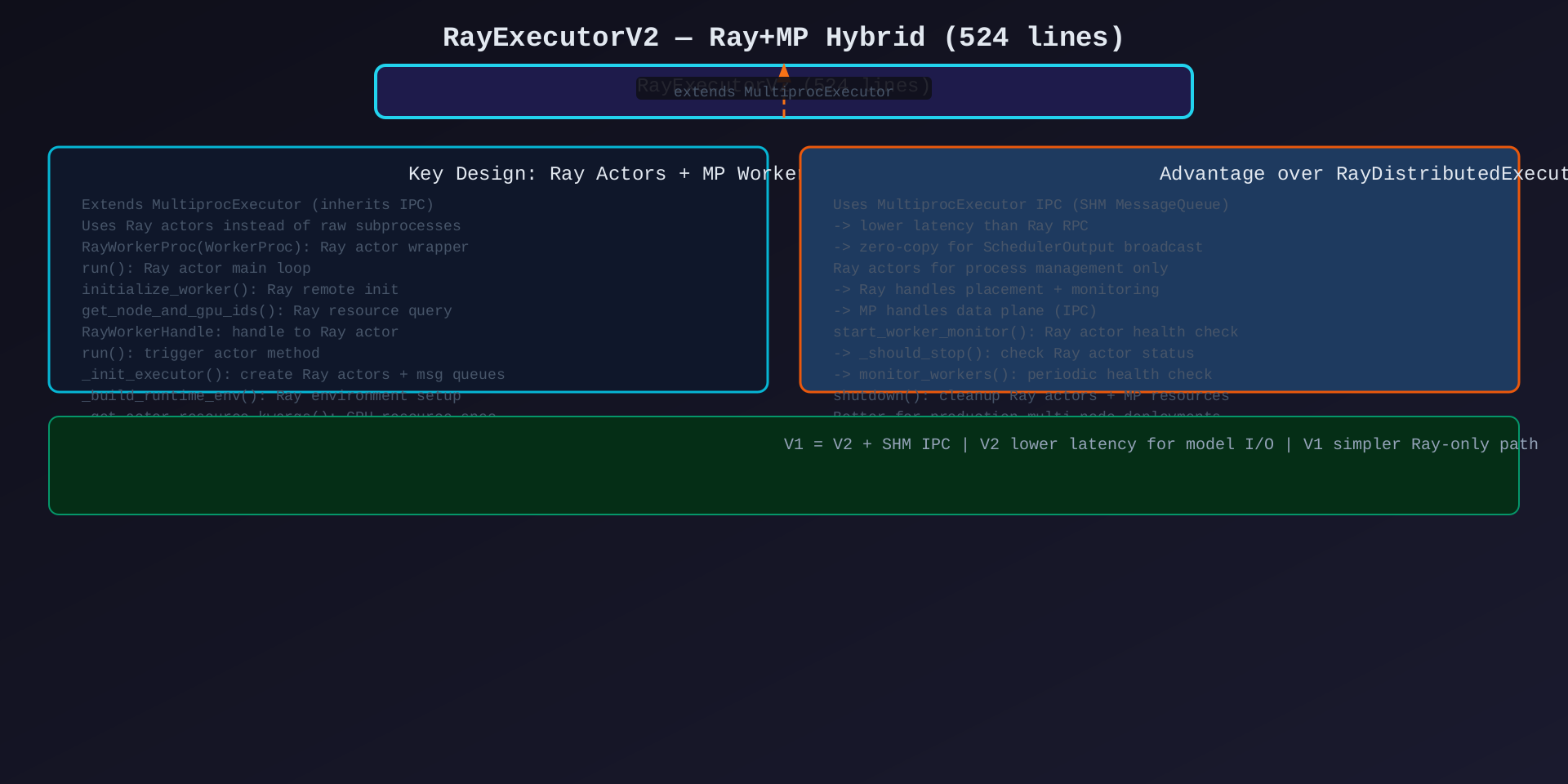
核心作用:Ray + 多进程混合执行器------用 Ray 管理进程,用 SHM IPC 传输数据,兼得两者优势。
关键类/方法:
| 类/方法 | 说明 |
|---|---|
RayExecutorV2(MultiprocExecutor) |
继承 MultiprocExecutor,复用 IPC 机制 |
RayWorkerProc(WorkerProc) |
Ray Actor 包装的 Worker 进程 |
RayWorkerHandle |
Ray Actor 句柄 |
_init_executor() |
创建 Ray actors + SHM MessageQueues |
_build_runtime_env() |
构建 Ray 运行环境 |
start_worker_monitor() |
Ray Actor 健康监控 |
shutdown() |
清理 Ray actors + MP 资源 |
与 RayDistributedExecutor 的对比:
| 维度 | RayDistributedExecutor | RayExecutorV2 |
|---|---|---|
| 数据传输 | Ray RPC(序列化+网络) | SHM MessageQueue(零拷贝) |
| 进程管理 | Ray Actor | Ray Actor |
| 延迟 | 较高(Ray 调度开销) | 较低(SHM 直传) |
| 复杂度 | 纯 Ray | Ray + MP 混合 |
| 适用场景 | 简单分布式 | 高吞吐生产环境 |
架构图 :见 07-ray-executor-v2.svg
模块7:Ray 工具库(ray_utils.py,696行 + ray_env_utils.py,18行)
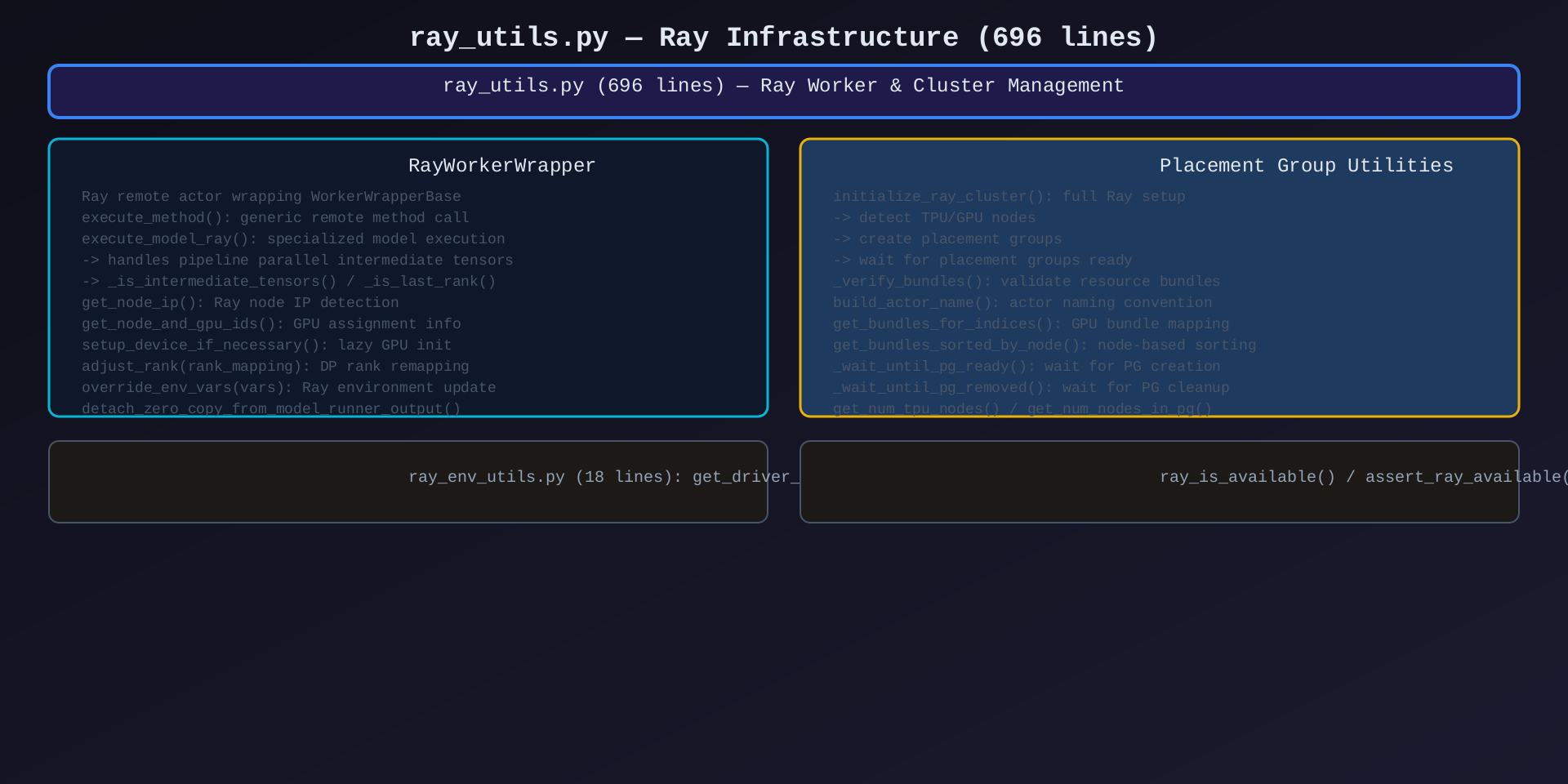
核心作用:Ray 基础设施------Worker 包装、Placement Group 管理、集群初始化。
RayWorkerWrapper(在 ray_utils.py 中定义):
| 方法 | 说明 |
|---|---|
execute_method() |
通用远程方法调用 |
execute_model_ray() |
专用模型执行(含 PP 中间张量处理) |
get_node_ip() |
获取 Ray 节点 IP |
get_node_and_gpu_ids() |
获取 GPU 资源映射 |
setup_device_if_necessary() |
延迟 GPU 初始化 |
adjust_rank() |
DP rank 重映射 |
override_env_vars() |
Ray 环境变量传播 |
detach_zero_copy_from_model_runner_output() |
零拷贝分离 |
Placement Group 工具:
| 函数 | 说明 |
|---|---|
initialize_ray_cluster() |
完整 Ray 集群初始化 |
_verify_bundles() |
验证资源 bundle |
build_actor_name() |
Actor 命名规范 |
get_bundles_for_indices() |
GPU bundle 映射 |
get_bundles_sorted_by_node() |
按节点排序 bundle |
_wait_until_pg_ready() |
等待 PG 创建 |
_wait_until_pg_removed() |
等待 PG 清理 |
get_num_tpu_nodes() |
TPU 节点数 |
get_num_nodes_in_placement_group() |
PG 节点数 |
辅助函数:
| 函数 | 说明 |
|---|---|
ray_is_available() |
检查 Ray 是否可用 |
assert_ray_available() |
断言 Ray 可用 |
FutureWrapper(Future) |
Ray ObjectRef 包装 |
get_driver_env_vars() |
获取 Driver 环境变量 |
架构图 :见 08-ray-utils.svg
三、模块调用关系与数据流
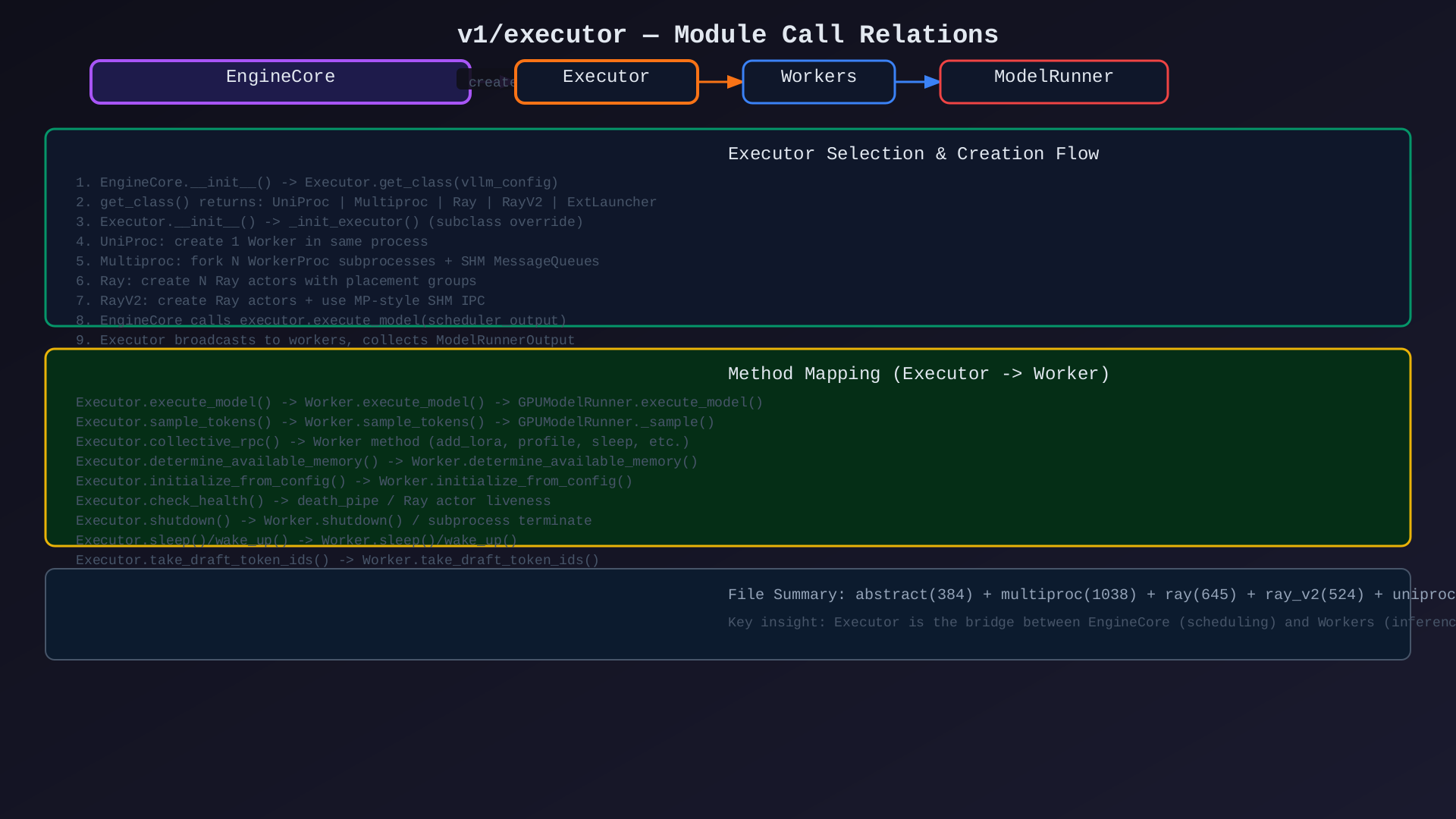
3.1 主要调用链
EngineCore
↓ create
Executor.get_class(vllm_config) -> 选择具体实现
↓
Executor._init_executor() -> 初始化 Workers
├── UniProc: Worker(local_rank=0) 直接创建
├── Multiproc: WorkerProc.make_worker_process() × N
├── Ray: RayWorkerWrapper.as_actor() × N
└── RayV2: RayWorkerProc() × N + SHM queues
EngineCore.step()
↓ execute_model
Executor.execute_model(scheduler_output)
├── Multiproc: broadcast(SchedulerOutput) -> Workers execute -> collect
├── Ray: collective_rpc / _execute_dag
├── RayV2: broadcast(SHM) -> Ray actors execute -> collect(SHM)
└── UniProc: worker.execute_model() 直接调用
↓
ModelRunnerOutput
↓
EngineCore continues scheduling3.2 数据流详图
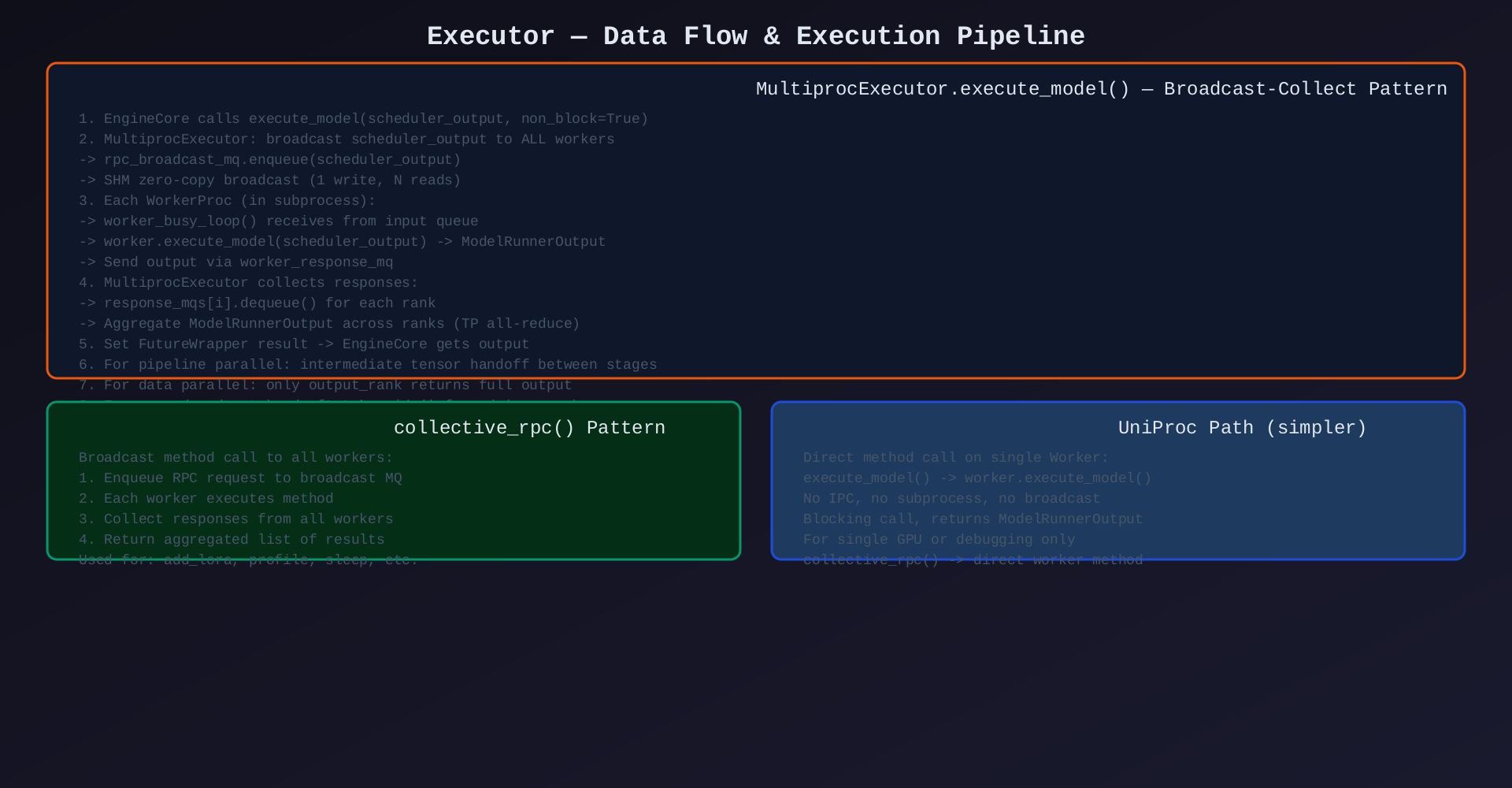
SchedulerOutput (from EngineCore)
↓
Executor.execute_model(scheduler_output)
├── rpc_broadcast_mq.enqueue(scheduler_output) [Multiproc/RayV2]
│ ↓ SHM 零拷贝广播
├── WorkerProc.worker_busy_loop()
│ ├── recv from input queue
│ ├── Worker.execute_model(scheduler_output)
│ │ └── GPUModelRunner.execute_model()
│ │ └── CUDA forward + sampling
│ └── send via worker_response_mq
├── Collect responses from all ranks
│ ├── response_mqs[i].dequeue()
│ └── Aggregate ModelRunnerOutput (TP all-reduce)
└── Set FutureWrapper result
↓
ModelRunnerOutput (returned to EngineCore)3.3 关键交互
| 调用方 | 被调用方 | 数据 | 方式 |
|---|---|---|---|
| EngineCore | Executor | SchedulerOutput | 方法调用 |
| MultiprocExecutor | rpc_broadcast_mq | SchedulerOutput | SHM enqueue |
| WorkerProc | Worker | SchedulerOutput | SHM dequeue → 方法调用 |
| Worker | GPUModelRunner | SchedulerOutput | 方法调用 |
| Worker | worker_response_mq | ModelRunnerOutput | SHM enqueue |
| MultiprocExecutor | response_mqs | ModelRunnerOutput | SHM dequeue + 聚合 |
| UniProcExecutor | Worker | 所有数据 | 直接方法调用 |
| RayDistributedExecutor | RayWorkerWrapper | 所有数据 | Ray RPC |
| RayExecutorV2 | RayWorkerProc | SchedulerOutput | SHM enqueue |
| Executor | Worker | lora/profile/sleep | collective_rpc |
四、设计模式总结
| 模式 | 应用位置 | 说明 |
|---|---|---|
| 策略模式 | 4种 Executor 实现 | 按部署场景选择执行策略 |
| 工厂方法 | Executor.get_class() |
根据配置动态选择实现类 |
| 广播-收集 | Multiproc/Ray 执行 | 统一的 scatter-gather 模式 |
| Future 模式 | FutureWrapper |
异步非阻塞模型执行 |
| 模板方法 | _init_executor() |
基类定流程,子类定细节 |
| 代理模式 | RayWorkerWrapper | 将 Worker 包装为 Ray Actor |
| 观察者模式 | death_pipe + monitor_workers | 监控 Worker 健康状态 |
| 引用计数 | Shared Worker Lock | 多 Worker 共享锁 |
| 进程池 | WorkerProc 池 | N 个 Worker 子进程并行执行 |
五、关键指标
| 指标 | 数值 |
|---|---|
| Executor 总代码量 | ~3.5K 行(8 文件) |
| MultiprocExecutor | 1038 行(最大文件) |
| ray_utils.py | 696 行 |
| RayDistributedExecutor | 645 行 |
| RayExecutorV2 | 524 行 |
| abstract.py | 384 行 |
| UniProcExecutor | 190 行 |
| ray_env_utils.py | 18 行 |
| Executor 实现类型 | 5 种(Uni/MP/Ray/RayV2/ExtLauncher) |
| IPC 机制 | SHM MessageQueue + Ray RPC + pipe |
| 并行支持 | TP + PP + DP + PCP |
六、架构亮点与设计权衡
亮点
- 统一抽象接口 :
Executor(ABC)让 EngineCore 无需关心底层是单 GPU 还是多节点 - SHM 零拷贝广播 :
rpc_broadcast_mq实现 SchedulerOutput 的 1→N 高效广播 - 进程隔离安全:Worker 运行在独立子进程,crash 不影响 Driver,death_pipe 监控
- 异步 Future 模式 :
execute_model()返回FutureWrapper,不阻塞调度器 - RayV2 混合架构:Ray 管理进程 + SHM 传数据,兼得 Ray 弹性调度和 MP 低延迟
- 工厂方法动态选择 :
get_class()按配置自动选择最优执行器 - 弹性伸缩支持 :
sleep()/wake_up()+ DP reinitialize 动态调整资源
权衡
- Multiproc 最复杂:1038 行,包含子进程管理、IPC、death 监控、信号处理------职责较多
- Ray 两套实现:RayDistributedExecutor 和 RayExecutorV2 并存,增加维护成本
- UniProc 不支持异步调度 :
supports_async_scheduling() = False,单 GPU 场景无法利用调度优化 - MessageQueue 阻塞风险:如果 Worker hang,broadcast 可能无限阻塞(有 timeout 但需谨慎)
- Pipeline Parallel 支持有限 :仅 RayDistributedExecutor 通过
_execute_dag()支持 PP - Ray DAG 编译依赖:需要额外安装 ray-cgraph,非标准 Ray 功能
报告生成时间:2026-04-19 | 代码版本:vllm main branch