NLP学习笔记13:BERT系列模型------从预训练到 RoBERTa 与 ALBERT
作者:Ye Shun
日期:2026-04-19
一、前言
在现代自然语言处理的发展历程中,BERT(Bidirectional Encoder Representations from Transformers) 是一个里程碑式模型。
它由 Google 在 2018 年提出,最重要的意义不只是"又一个新模型",而是它真正推动了 NLP 研究范式的转变:
- 从任务专用模型转向通用预训练模型
- 从大量人工特征工程转向端到端表示学习
- 从"为每个任务重新建模"转向"预训练 + 微调"
在 BERT 出现之前,虽然词向量、RNN、LSTM、Attention、Transformer 已经为 NLP 奠定了很多基础,但真正让"预训练语言模型"大规模走进主流应用的,是 BERT 及其后续变体。
这篇笔记将系统介绍:
- BERT 的核心结构与输入表示
- BERT 的两个经典预训练任务
- BERT 为什么能实现双向上下文建模
- BERT 的微调方式与实践建议
- 主流 BERT 变体模型的核心改进
- 中文 BERT 模型的使用思路
二、BERT 是什么
BERT 全称是:
- Bidirectional Encoder Representations from Transformers
直译过来就是:
- 基于 Transformer 的双向编码表示
这个名字里有两个特别重要的关键词:
1. Encoder
BERT 使用的是 Transformer 的 编码器(Encoder) 部分,而不是完整的 Encoder-Decoder 架构。
这意味着 BERT 更擅长:
- 句子理解
- 文本表示
- 分类
- 序列标注
- 句子匹配
而不是直接做开放式长文本生成。
2. Bidirectional
BERT 最大的创新之一,是它能够在预训练时同时利用:
- 左侧上下文
- 右侧上下文
也就是说,BERT 不再像传统单向语言模型那样只能"从左往右"或"从右往左"看文本,而是尽可能同时理解两边信息。
这就是它所谓的双向上下文建模能力。
三、BERT 的输入表示
虽然我们输入给 BERT 的是文本,但模型真正接收的是向量。
BERT 的输入表示通常由三部分相加得到:
1. Token Embeddings
Token Embedding 表示词或子词本身的语义信息。
例如:
- "自然"
- "语言"
- "处理"
在进入模型前,都会先被转换为向量。
2. Position Embeddings
Transformer 本身没有循环结构,因此无法天然感知词序。
所以 BERT 会加入位置嵌入,让模型知道:
- 当前 token 在序列中的第几个位置
3. Segment Embeddings
在句对任务中,例如:
- 句子 A
- 句子 B
BERT 需要区分这两个句子分别属于哪一段,因此会加入 Segment Embedding。
例如:
- 句子 A 的 token 对应 segment id = 0
- 句子 B 的 token 对应 segment id = 1
4. 特殊标记
BERT 还会在输入序列中引入一些特殊 token:
[CLS]:放在序列开头,常用于分类任务[SEP]:用于分隔句子[MASK]:预训练时用于掩码预测
例如句对输入常写成:
text
[CLS] 句子A [SEP] 句子B [SEP]四、BERT 的核心架构
BERT 基于 Transformer Encoder 堆叠而成。
每一层编码器主要包括:
- 多头自注意力机制(Multi-Head Self-Attention)
- 前馈神经网络(Feed-Forward Network)
- 残差连接(Residual Connection)
- 层归一化(LayerNorm)
可以把 BERT 理解为:
多层 Transformer 编码器叠加起来,对每个输入位置生成上下文相关的表示。
一个简化的编码器层示意如下:
python
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048):
super().__init__()
self.self_attn = MultiheadAttention(d_model, nhead)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, src):
src2 = self.self_attn(src, src, src)[0]
src = src + self.norm1(src2)
src2 = self.linear2(F.relu(self.linear1(src)))
src = src + self.norm2(src2)
return src虽然这只是一个非常简化的结构,但已经体现了 BERT 的核心计算思路。
五、BERT 的两个经典预训练任务
BERT 之所以能学到强大的语言表示能力,关键在于它使用了两个经典的预训练任务。
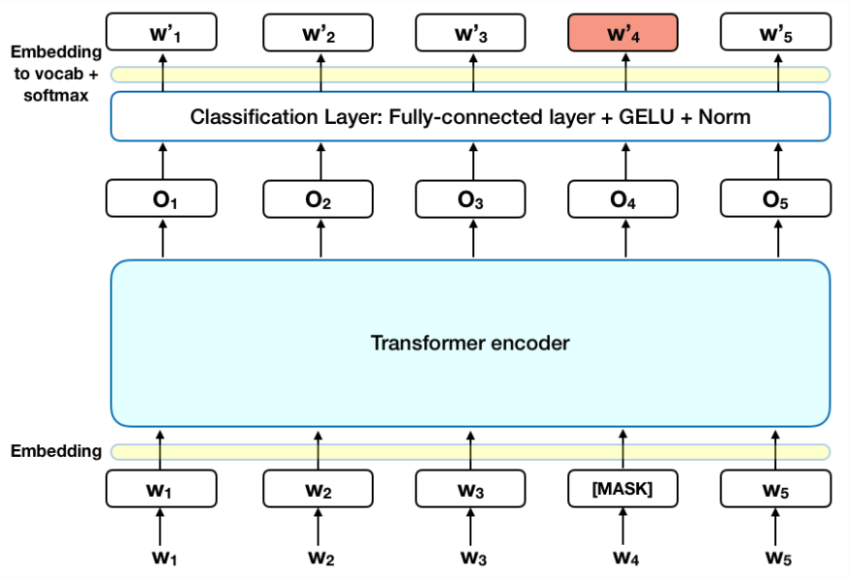
1. 掩码语言模型(Masked Language Model, MLM)
这是 BERT 最核心的训练方式。
做法是:
- 在输入序列中随机选取 15% 的 token
- 对这些 token 做遮盖、替换或保持不变
- 让模型根据上下文预测原始词
例如:
- 原句:
预训练模型很强大 - 输入:
预训练 [MASK] 很强大 - 目标:预测
模型
MLM 的优点非常重要:
- 因为被遮住的位置不能直接看到自己
- 所以模型必须综合利用左右两侧上下文
这正是 BERT 双向建模能力的关键来源。
2. 下一句预测(Next Sentence Prediction, NSP)
BERT 原始论文中还引入了 NSP 任务,用来判断两个句子是否在原文中连续出现。
例如:
正样本:
- 句子 A:
预训练模型很强大 - 句子 B:
它们可以迁移到很多任务中
负样本:
- 句子 A:
预训练模型很强大 - 句子 B:
今天天气不错
NSP 的目标是帮助模型学习:
- 句间关系
- 句子连贯性
- 语篇层次信息
不过后来很多研究发现,NSP 并不是 BERT 成功的决定性因素,因此后续一些变体模型(例如 RoBERTa)会选择移除它。
六、BERT 为什么重要
BERT 的意义并不只是"效果更好",而是它几乎重塑了 NLP 的标准工作流。
1. 统一了很多理解类任务的建模方式
很多任务都可以基于 BERT 的输出再接一层任务头来完成:
- 文本分类
- 情感分析
- 句子匹配
- 命名实体识别
- 问答
2. 极大减少了特征工程需求
过去做很多任务时需要手工设计:
- 词频特征
- n-gram 特征
- 词典特征
- 句法特征
而 BERT 往往通过预训练自动学到了更丰富、更抽象的语义表示。
3. 推动了"预训练 + 微调"范式普及
从 BERT 之后,NLP 中大量任务的标准流程变成:
- 选择一个预训练模型
- 针对具体任务加载任务头
- 用少量下游数据微调
- 得到可用模型
这套思路影响深远,后面的 RoBERTa、ALBERT、ELECTRA、DeBERTa 乃至大语言模型,都延续了这种思路。
七、BERT-base 与 BERT-large
BERT 原始论文中最常见的两个版本是:
| 参数 | BERT-base | BERT-large |
|---|---|---|
| 层数 | 12 | 24 |
| 隐藏维度 | 768 | 1024 |
| 注意力头数 | 12 | 16 |
| 参数量 | 110M | 340M |
通常来说:
BERT-base更适合教学、实验和普通任务BERT-large效果更强,但训练和推理成本更高
八、BERT 的微调方式
BERT 的一个巨大优势是:微调非常方便。
不同任务只需要在 BERT 输出的基础上接一个小型任务层即可。
1. 文本分类
对于分类任务,最常见的做法是使用 [CLS] 对应的向量,接一个全连接层进行分类。
例如:
- 情感分析
- 新闻分类
- 意图识别
2. 序列标注
对于 NER、词性标注这类任务,通常使用:
- 每个 token 的输出向量
再接分类器预测标签。
3. 问答任务
对于抽取式问答,常见做法是预测:
- 答案起始位置
- 答案结束位置
4. 典型微调流程
一个标准流程通常如下:
- 加载预训练模型
- 准备下游任务数据
- 添加任务输出层
- 使用较小学习率微调
- 在验证集上监控效果
示例如下:
python
from transformers import BertForSequenceClassification, Trainer
model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
)
trainer.train()九、BERT 微调中的实践建议
1. 学习率要小
BERT 在预训练阶段已经学到很强的通用能力,因此微调时通常使用较小学习率,例如:
2e-53e-55e-5
如果学习率过大,容易破坏预训练好的参数。
2. epoch 不需要太多
很多下游任务中:
- 2 到 4 个 epoch 往往就足够
训练太久反而可能过拟合。
3. batch size 常用 16 或 32
这通常是在效果和显存之间的平衡选择。
4. 长文本要注意最大长度限制
BERT 常见最大长度为:
- 512 token
文本过长时需要:
- 截断
- 分段
- 滑窗
十、高效微调方法
随着模型越来越大,研究者也提出了很多参数高效微调方法。
1. 全参数微调
特点:
- 所有参数都更新
- 通常效果最好
- 但成本最高
2. 特征提取(冻结 BERT)
做法:
- 冻结 BERT 主体参数
- 只训练顶层任务头
优点:
- 更省计算资源
缺点:
- 效果一般不如全参数微调
3. Adapter
做法:
- 在每层之间插入轻量适配模块
- 只训练这些新增模块
优点:
- 参数高效
- 便于多任务切换
4. Prompt / Prompt Tuning
做法:
- 把任务重新包装成"填空"或"提示"形式
例如情感分类可以改写为:
- "这部电影很好看,所以它是 MASK 的。"
这种方法在小样本任务中尤其有价值。
十一、主流 BERT 变体模型
BERT 之后,研究者提出了大量变体模型。它们往往不是推翻 BERT,而是在训练策略、参数设计、效率或效果上进一步优化。
1. RoBERTa
RoBERTa 全称是:
- Robustly Optimized BERT Pretraining Approach
它的主要改进包括:
- 更大的 batch size
- 更长的训练时间
- 更多训练数据
- 移除 NSP 任务
- 使用动态 masking
RoBERTa 的核心思想其实很直接:
不是 BERT 架构不够强,而是原始 BERT 训练得还不够充分。
因此,RoBERTa 往往被看作"训练更充分的 BERT"。
2. ALBERT
ALBERT 全称是:
- A Lite BERT
它的核心目标是:
- 减少参数量
- 提高训练效率
主要做了两件事:
参数共享
不同层之间共享部分参数,减少模型冗余。
嵌入分解
把词嵌入矩阵拆成更小的部分,降低参数量。
ALBERT 的优势是:
- 参数显著减少
- 模型更轻量
- 训练和部署更高效
3. DistilBERT
DistilBERT 是一个蒸馏版本的 BERT。
它通过知识蒸馏,把大模型的知识迁移到更小模型中。
优点:
- 推理更快
- 模型更小
- 适合资源受限场景
4. ELECTRA
ELECTRA 的核心创新是:
- 不再只做 MLM
- 而是用"替换词检测"训练模型
它让模型判断一个 token 是否被生成器替换过。
优点是:
- 训练更高效
- 样本利用率更高
5. SpanBERT
SpanBERT 更关注对连续文本跨度(span)的建模,适合:
- 阅读理解
- 关系抽取
- 需要关注片段边界的任务
十二、中文 BERT 模型
BERT 在中文任务中也有大量实践和改进。
常见中文预训练模型包括:
| 模型 | 机构 | 特点 |
|---|---|---|
| BERT-base-chinese | 中文基础版 | |
| BERT-wwm | 哈工大 | 全词遮盖(Whole Word Masking) |
| RoBERTa-wwm-ext | 哈工大 | 扩展语料 + 更强训练 |
| ERNIE | 百度 | 融入更丰富知识信息 |
| NEZHA | 华为 | 相对位置编码 |
1. 什么是全词遮盖(WWM)
中文和英文不同,中文词边界不天然由空格分隔。
例如:
- "自然语言处理"
如果直接按字级别遮盖,可能会变成:
- "自然 MASK 处理"
但这不一定符合"词"层级的语义结构。
所以 WWM(Whole Word Masking)会尽量把整个词作为整体处理,这通常更适合中文任务。
2. 中文任务建议
对于中文任务,通常建议:
- 优先尝试中文 WWM 版本
- 注意分词与 tokenization 的关系
- 如果是专业领域,可继续做领域自适应预训练
十三、中文 BERT 的使用示例
下面是一个最基础的中文 BERT 加载示例:
python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
model = BertModel.from_pretrained("bert-base-chinese")
inputs = tokenizer("自然语言处理很有趣", return_tensors="pt")
outputs = model(**inputs)其中:
tokenizer负责把文本转成 token idmodel负责输出上下文表示
十四、BERT 的局限性
虽然 BERT 非常强大,但它也并不是完美的。
1. 不是天然生成模型
BERT 更擅长理解,而不是自由生成长文本。
2. 输入长度有限
标准 BERT 一般只能处理 512 token 以内的文本。
3. 计算成本较高
尤其是 BERT-large,在训练和推理上都不算轻量。
4. 与预训练目标存在差距
例如 [MASK] 这个 token:
- 在预训练中频繁出现
- 但在真实下游文本中通常不会出现
这会带来一定的训练-推理不一致问题。
十五、BERT 在 NLP 发展中的意义
BERT 的历史地位非常重要,因为它不仅带来了更好的效果,还带来了方法论上的改变。
它让大家意识到:
- 可以先学习通用语言表示
- 再把这种能力迁移到具体任务
从这个意义上说,BERT 是很多后续模型的起点:
- RoBERTa
- ALBERT
- ELECTRA
- DeBERTa
- 甚至后来更大规模的语言模型
它是"预训练时代"的真正代表之一。
十六、总结
BERT 是现代 NLP 最重要的基础模型之一。
它的核心特点可以概括为:
- 基于 Transformer Encoder
- 通过 MLM 实现双向上下文建模
- 通过预训练 + 微调提升下游任务效果
它的后续变体模型,又从不同方向进行了优化:
- RoBERTa:把训练做得更充分
- ALBERT:把参数做得更高效
- DistilBERT:把模型做得更轻量
- ELECTRA:把预训练做得更高效
如果说预训练模型这一章是在回答:
- "为什么现代 NLP 不再从零开始训练?"
那么 BERT 这一章就是在回答:
- "第一个真正改变 NLP 工作流的预训练模型,到底是怎么工作的?"
理解 BERT,不只是理解一个模型本身,更是在理解整个现代 NLP 方法论的起点。
十七、参考学习方向
如果你想继续往后写,这篇后面很适合接:
- RoBERTa 与 BERT 的训练差异详解
- ALBERT 的参数共享机制
- ELECTRA:替换词检测为什么更高效
- DeBERTa:解耦注意力机制
- BERT 在中文任务中的微调实践