vLLM v1 Worker --- 系统级架构深度分析
分析范围:
vllm/v1/worker/目录,78+ 文件,~15K 行代码。Worker 是 v1 推理系统的"执行臂"------持有 GPU 资源、运行模型推理、管理 KV Cache。
Dark Terminal 风格架构图 10 张,见
diagrams/子目录。
一、整体架构概览
1.1 设计思路
v1 Worker 采用 进程级执行 + 插件式组合架构:
- 进程隔离:每个 Worker 运行在独立进程中(由 Executor 管理),持有独占 GPU
- 核心-委托分离:GPUWorker 负责生命周期管理,GPUModelRunner 负责推理执行
- Mixin 组合:LoRA / KV Connector / EC Connector 通过 Mixin 注入 ModelRunner
- Staged Writes 批量更新:所有 GPU 状态更新采用"暂存-批量提交"模式,避免逐请求 GPU 写入
1.2 架构模式
| 模式 | 应用 |
|---|---|
| 委托模式 | GPUWorker → GPUModelRunner(生命周期 vs 推理逻辑) |
| Mixin 组合 | LoRAMixin + KVConnectorMixin + ECConnectorMixin |
| 策略模式 | Sampler / AttnBackend / ModelState 可插拔 |
| Staged Writes | Penalties/LogitBias/BadWords 批量 GPU 更新 |
| 享元模式 | EncoderCache / WorkspaceManager 资源复用 |
| 模板方法 | execute_model() 固定骨架,子步骤可覆盖 |
| 代理模式 | WorkerWrapperBase 远程调用代理 |
1.3 整体运行流程
Executor (多进程管理)
↓ fork Worker 进程
GPUWorker.init_device()
→ CUDA setup + distributed init
↓
GPUWorker.load_model()
→ GPUModelRunner 创建 + 权重加载
↓
GPUWorker.determine_available_memory()
→ profile_run() → 测量可用显存
↓
GPUWorker.initialize_from_config()
→ 分配 KV Cache 张量
↓
GPUWorker.compile_or_warm_up_model()
→ torch.compile + CUDA graph capture
↓
推理循环 (每步):
GPUWorker.execute_model(scheduler_output)
→ model_runner._update_states()
→ model_runner._prepare_inputs()
→ model_runner._model_forward()
→ model_runner._sample()
→ model_runner._bookkeeping_sync()
→ AsyncGPUModelRunnerOutput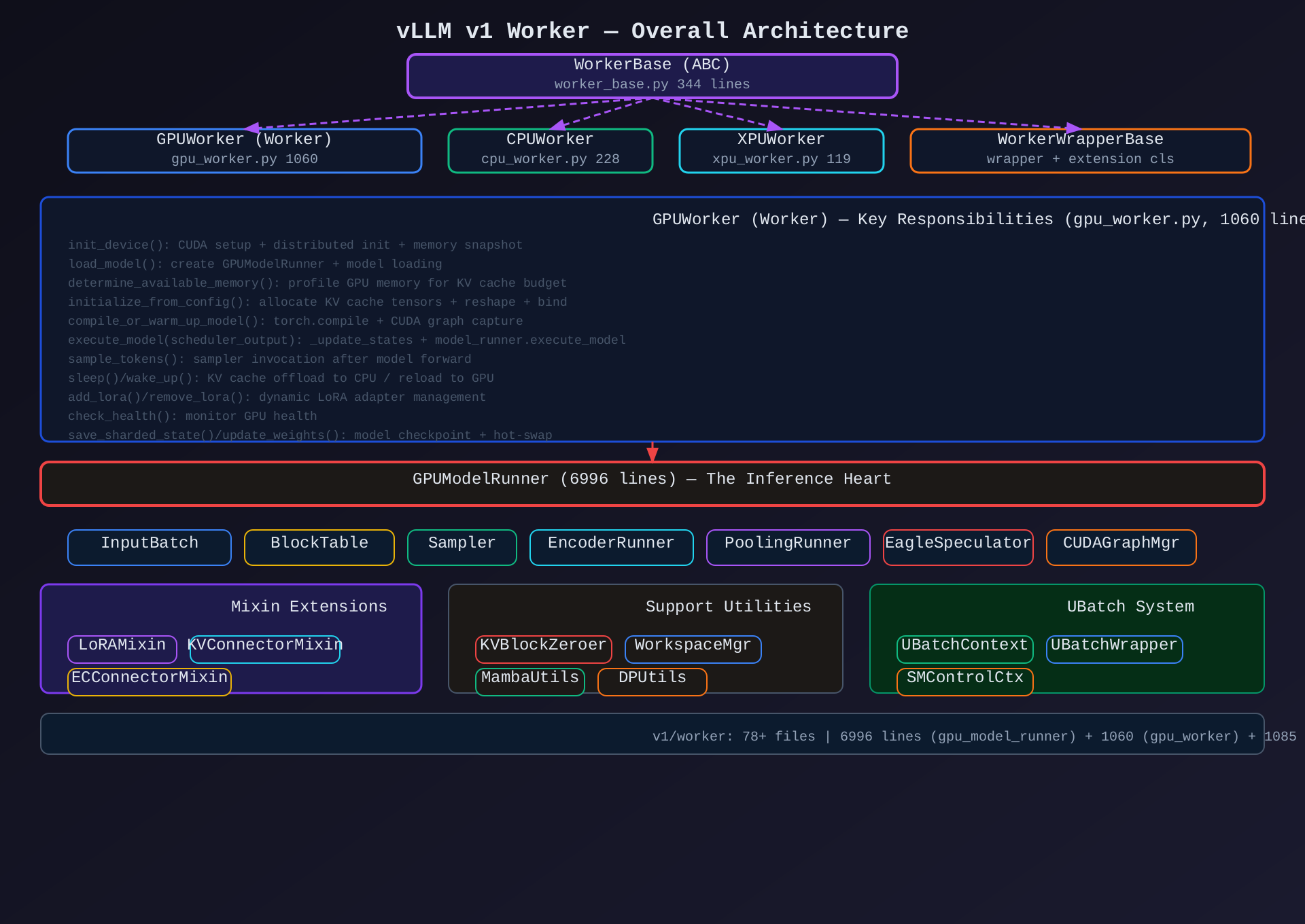
二、子模块划分
模块1:WorkerBase + GPUWorker(worker_base.py 344行 + gpu_worker.py 1060行)
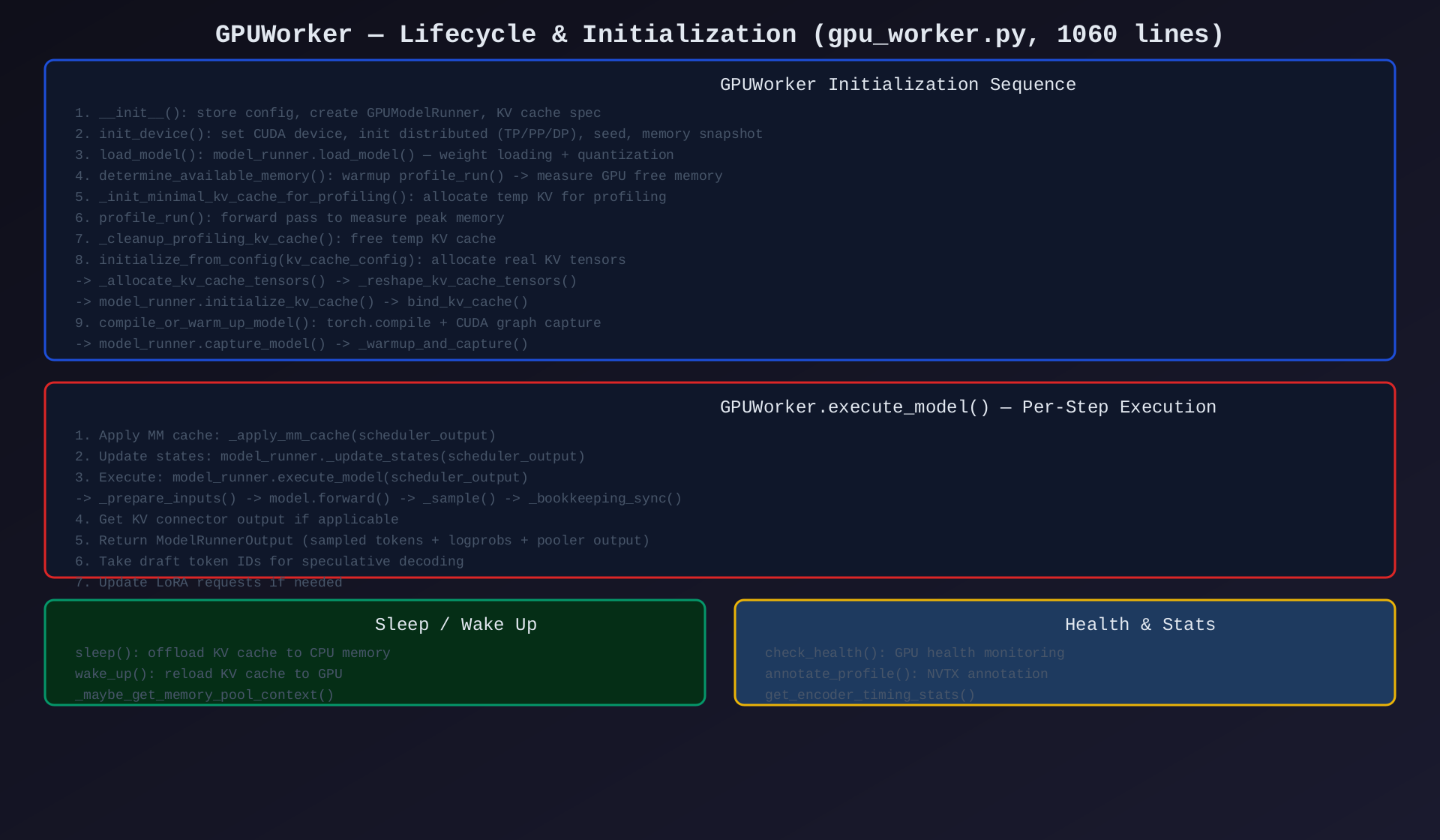
核心作用:Worker 进程的入口和生命周期管理------初始化设备、加载模型、分配 KV Cache、编排推理。
关键类/方法:
| 类/方法 | 说明 |
|---|---|
WorkerBase (ABC) |
Worker 抽象基类 |
WorkerWrapperBase |
远程调用代理 + 扩展类加载 |
Worker(GPUWorker) |
主力 Worker 实现 |
init_device() |
CUDA 设备初始化 + 分布式设置 |
load_model() |
创建 GPUModelRunner + 权重加载 |
determine_available_memory() |
显存探测 + KV budget 计算 |
initialize_from_config() |
KV Cache 张量分配 + reshape + bind |
compile_or_warm_up_model() |
torch.compile + CUDA graph 捕获 |
execute_model() |
推理执行入口 |
sleep() / wake_up() |
KV Cache CPU offload/reload |
add_lora() / remove_lora() |
LoRA 动态管理 |
架构图 :见 01-worker-overall-architecture.svg 和 02-gpu-worker-lifecycle.svg
模块2:GPUModelRunner(gpu_model_runner.py,6996行)

核心作用:v1 推理核心------所有模型前向执行、输入组装、采样、CUDA graph 管理的集中地。
关键方法分组:
| 分组 | 方法 | 职责 |
|---|---|---|
| 状态管理 | _update_states(), _update_streaming_request(), _init_mrope_positions() |
处理 SchedulerOutput,更新请求状态 |
| 输入组装 | _prepare_inputs(), _prepare_input_ids(), _build_attention_metadata() |
组装 InputBatch |
| 模型执行 | execute_model(), _model_forward(), _preprocess() |
前向推理主流程 |
| 采样 | _sample(), _pool(), _bookkeeping_sync() |
采样 + 输出同步 |
| KV Cache | _allocate_kv_cache_tensors(), initialize_kv_cache(), init_fp8_kv_scales() |
KV Cache 生命周期 |
| Attn Backend | initialize_attn_backend(), initialize_metadata_builders() |
Attention 后端初始化 |
| CUDA Graph | capture_model(), _capture_cudagraphs(), profile_cudagraph_memory() |
CUDA graph 捕获 |
| MM Encoder | _execute_mm_encoder(), _gather_mm_embeddings() |
多模态编码器 |
| Profile | profile_run(), _dummy_pooler_run() |
内存探测 |
架构图 :见 03-gpu-model-runner-architecture.svg
模块3:InputBatch(gpu_input_batch.py 1085行 + gpu/input_batch.py 576行)
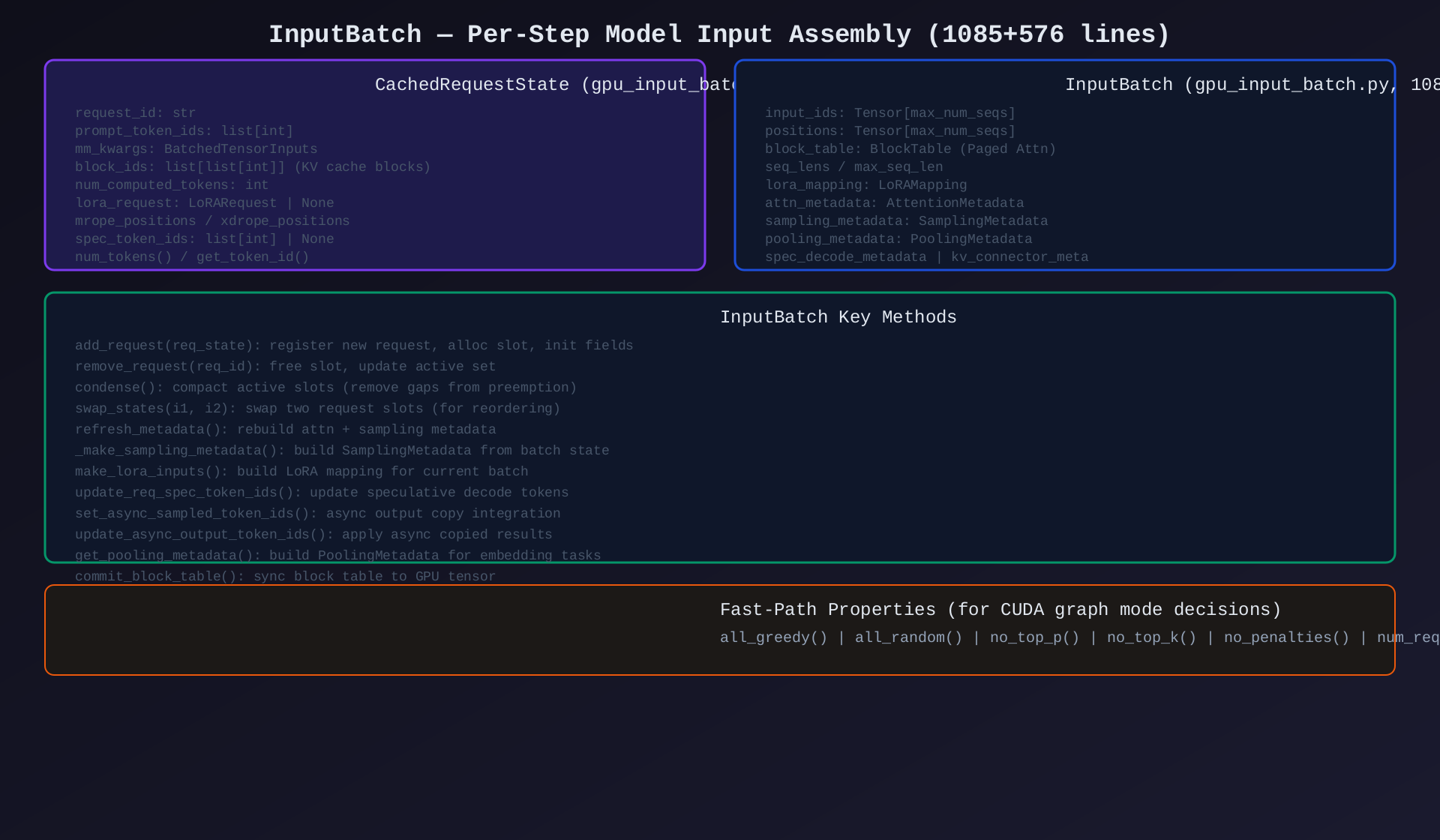
核心作用:每步模型输入的容器------管理 input_ids、positions、block_tables、attn_metadata、sampling_metadata。
关键类/方法:
| 类/方法 | 说明 |
|---|---|
CachedRequestState |
缓存的请求状态(block_ids, token_ids, mm_kwargs) |
InputBatch |
模型输入批处理容器 |
add_request() |
注册新请求,分配 slot |
remove_request() |
移除请求,释放 slot |
condense() |
紧凑化活跃 slots(填补 preemption 空洞) |
swap_states() |
交换两个请求位置 |
refresh_metadata() |
重建 attn + sampling metadata |
_make_sampling_metadata() |
构建 SamplingMetadata |
make_lora_inputs() |
构建 LoRA 映射 |
commit_block_table() |
同步 block table 到 GPU |
| 快速属性 | all_greedy(), all_random(), no_top_p(), no_top_k(), no_penalties() |
架构图 :见 04-input-batch.svg
模块4:BlockTable(block_table.py 373行 + gpu/block_table.py 281行)
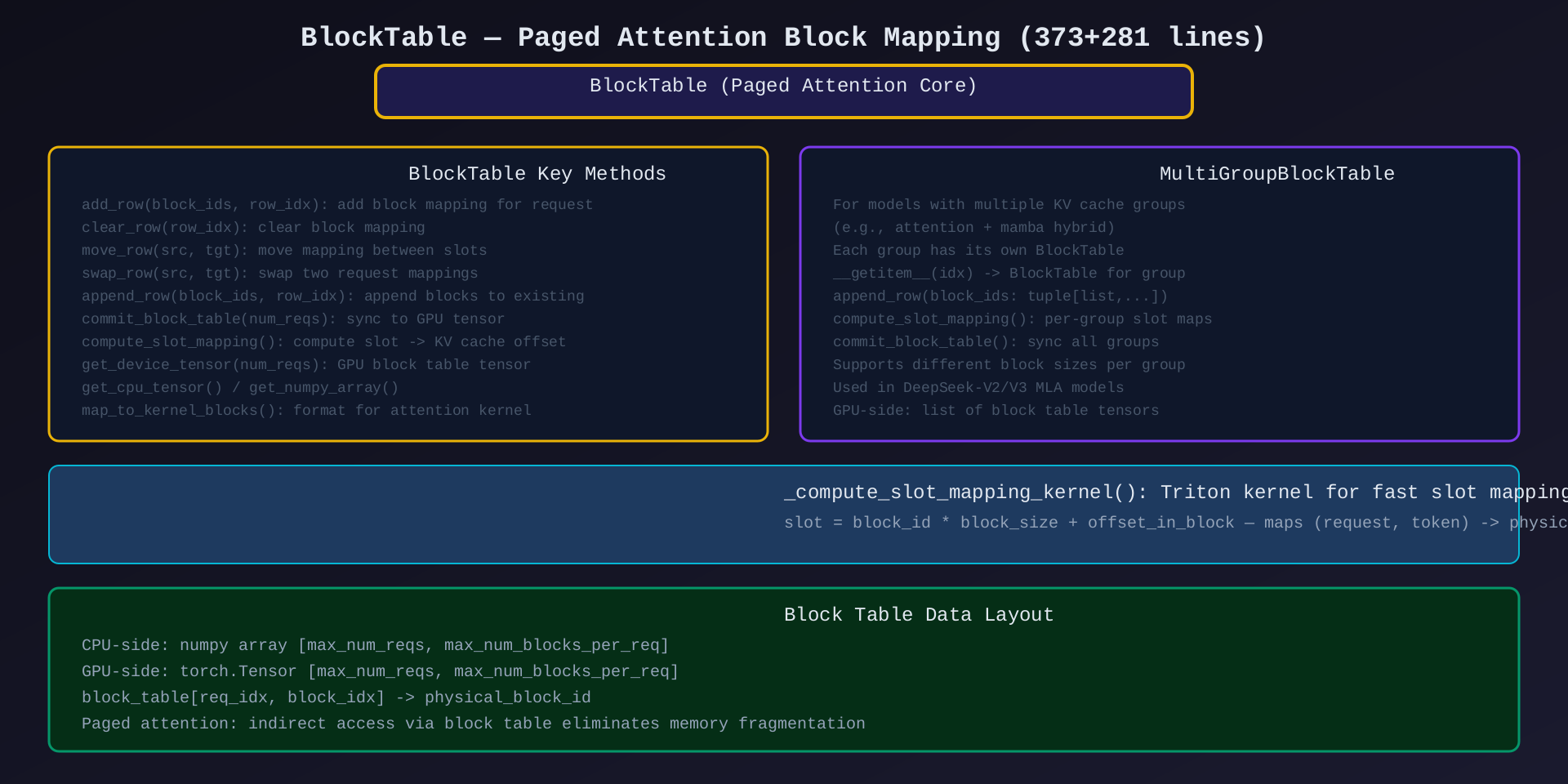
核心作用:Paged Attention 的核心数据结构------将 (request, token) 映射到物理 KV cache block。
关键类/方法:
| 类/方法 | 说明 |
|---|---|
BlockTable |
单组 KV cache 的 block 映射 |
MultiGroupBlockTable |
多组 KV cache(attention + mamba hybrid) |
add_row() / clear_row() / move_row() / swap_row() |
行级操作 |
compute_slot_mapping() |
计算 slot → KV cache 偏移 |
commit_block_table() |
同步 CPU → GPU tensor |
get_device_tensor() |
获取 GPU block table tensor |
_compute_slot_mapping_kernel() |
Triton 内核加速 slot mapping |
架构图 :见 05-block-table.svg
模块5:Sampling Pipeline(gpu/sample/,~1600行)
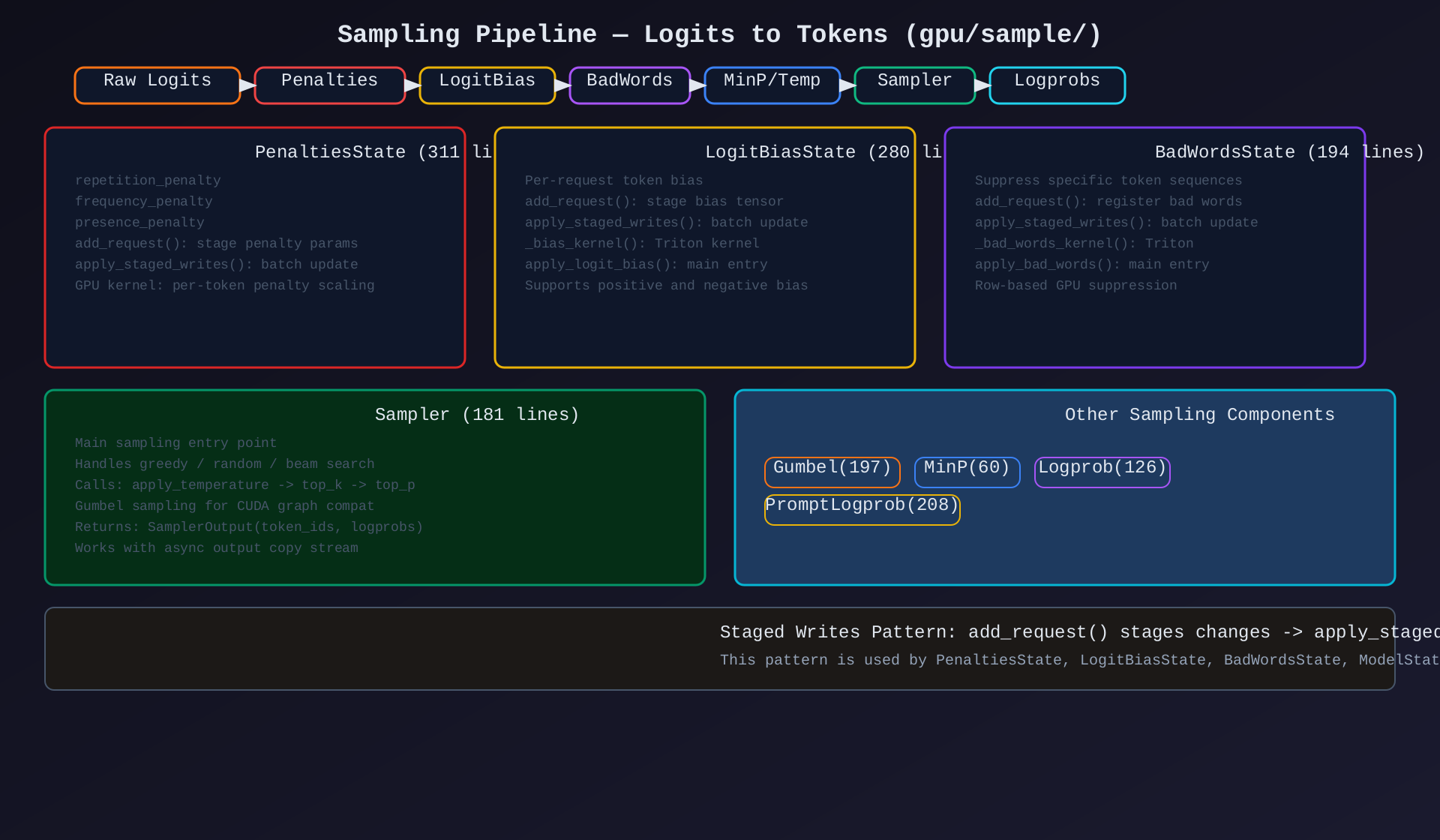
核心作用:logits → sampled tokens 的采样流水线------penalties、bias、bad words、温度、top-k/p 采样。
关键组件:
| 组件 | 行数 | 职责 |
|---|---|---|
PenaltiesState |
311 | repetition/frequency/presence penalty |
LogitBiasState |
280 | per-request token bias |
BadWordsState |
194 | suppress token sequences |
Sampler |
181 | 采样主入口(greedy/random/beam) |
Gumbel |
197 | Gumbel max-trick(CUDA graph 兼容) |
MinP |
60 | minimum probability filtering |
Logprob |
126 | token logprob 计算 |
PromptLogprob |
208 | prompt token logprob |
Staged Writes 模式 :add_request() 暂存变更 → apply_staged_writes() 批量提交到 GPU,避免逐请求 GPU kernel launch。
架构图 :见 06-sampling-pipeline.svg
模块6:Speculative Decoding(gpu/spec_decode/,~2000行)
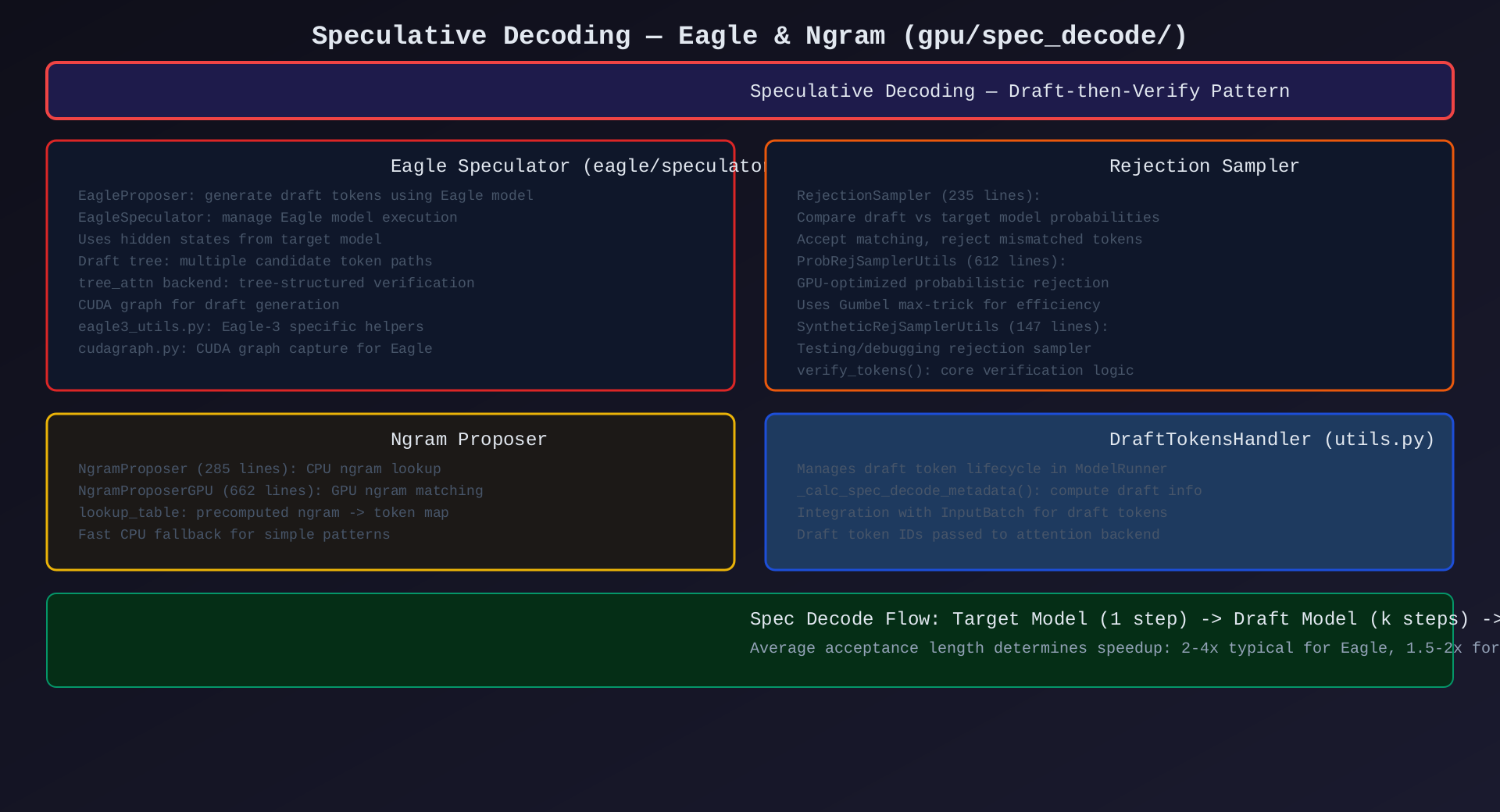
核心作用:投机解码------用小模型(draft)快速生成候选 token,再用大模型(target)验证,实现 2-4x 吞吐提升。
关键组件:
| 组件 | 行数 | 策略 |
|---|---|---|
EagleSpeculator |
820 | Eagle: 利用 target hidden states 生成 draft tree |
RejectionSampler |
235 | 基础拒绝采样验证 |
ProbRejSamplerUtils |
612 | GPU 优化概率拒绝采样(Gumbel max-trick) |
NgramProposer |
285 | CPU ngram 查找表提议 |
NgramProposerGPU |
662 | GPU ngram 匹配提议 |
DraftTokensHandler |
--- | draft token 生命周期管理 |
EncoderCUDAGraph(Eagle) |
81 | Eagle CUDA graph 捕获 |
架构图 :见 07-speculative-decoding.svg
模块7:CUDA Graph & UBatch(~1600行)
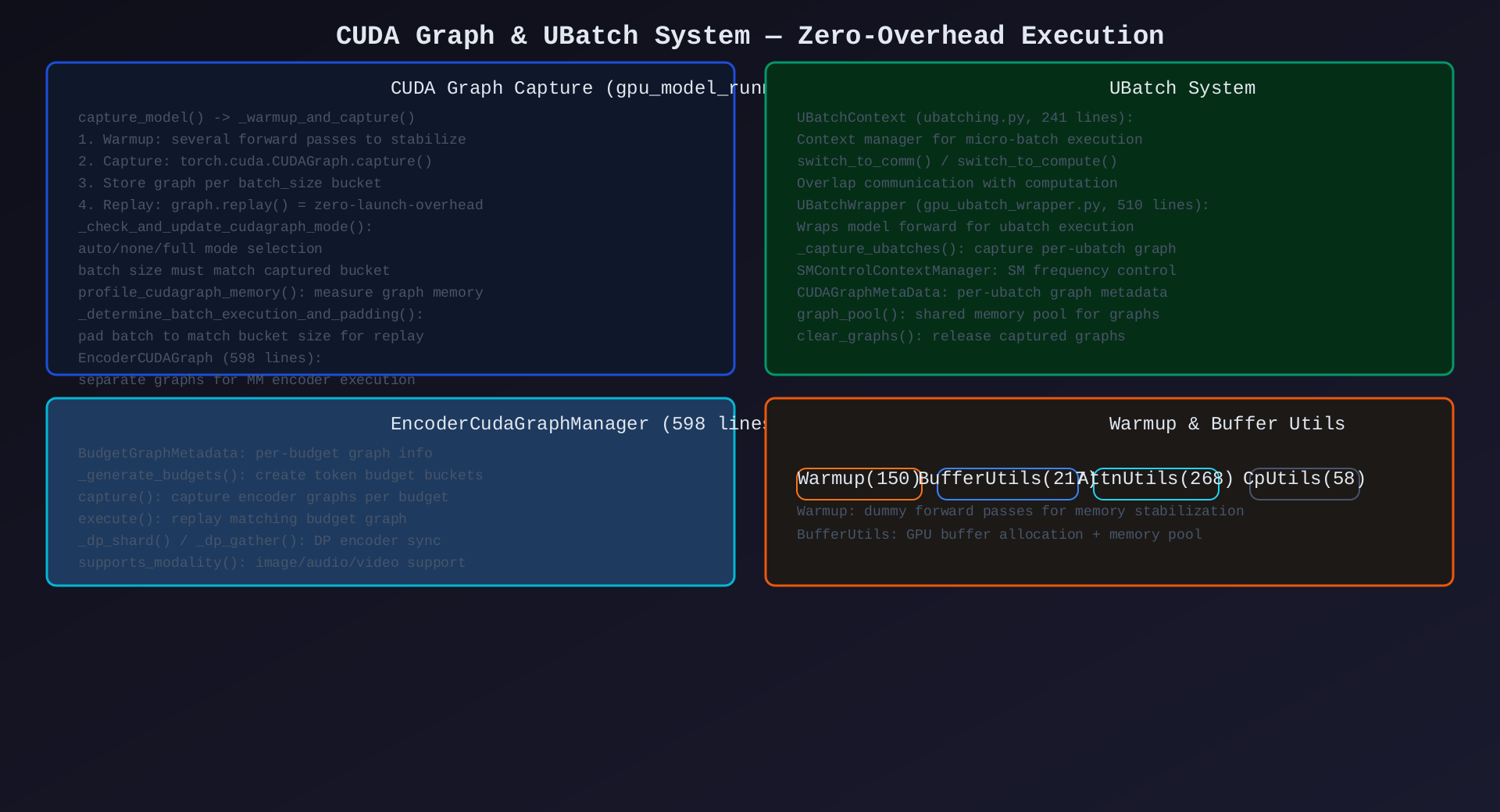
核心作用:零开销执行------CUDA graph 消除 kernel launch 开销,UBatch 实现通信-计算重叠。
关键组件:
| 组件 | 行数 | 职责 |
|---|---|---|
capture_model() |
(in model_runner) | CUDA graph 捕获主流程 |
EncoderCudaGraphManager |
598 | MM 编码器 CUDA graph |
UBatchContext |
241 | micro-batch 上下文管理 |
UBatchWrapper |
510 | model forward 的 ubatch 包装 |
SMControlContextManager |
(in wrapper) | SM 频率控制 |
cudagraph_utils |
435 | CUDA graph 工具函数 |
warmup |
150 | warmup 逻辑 |
架构图 :见 08-cudagraph-ubatch.svg
模块8:MM Encoder & Pooling(gpu/mm/ + gpu/pool/,~600行)
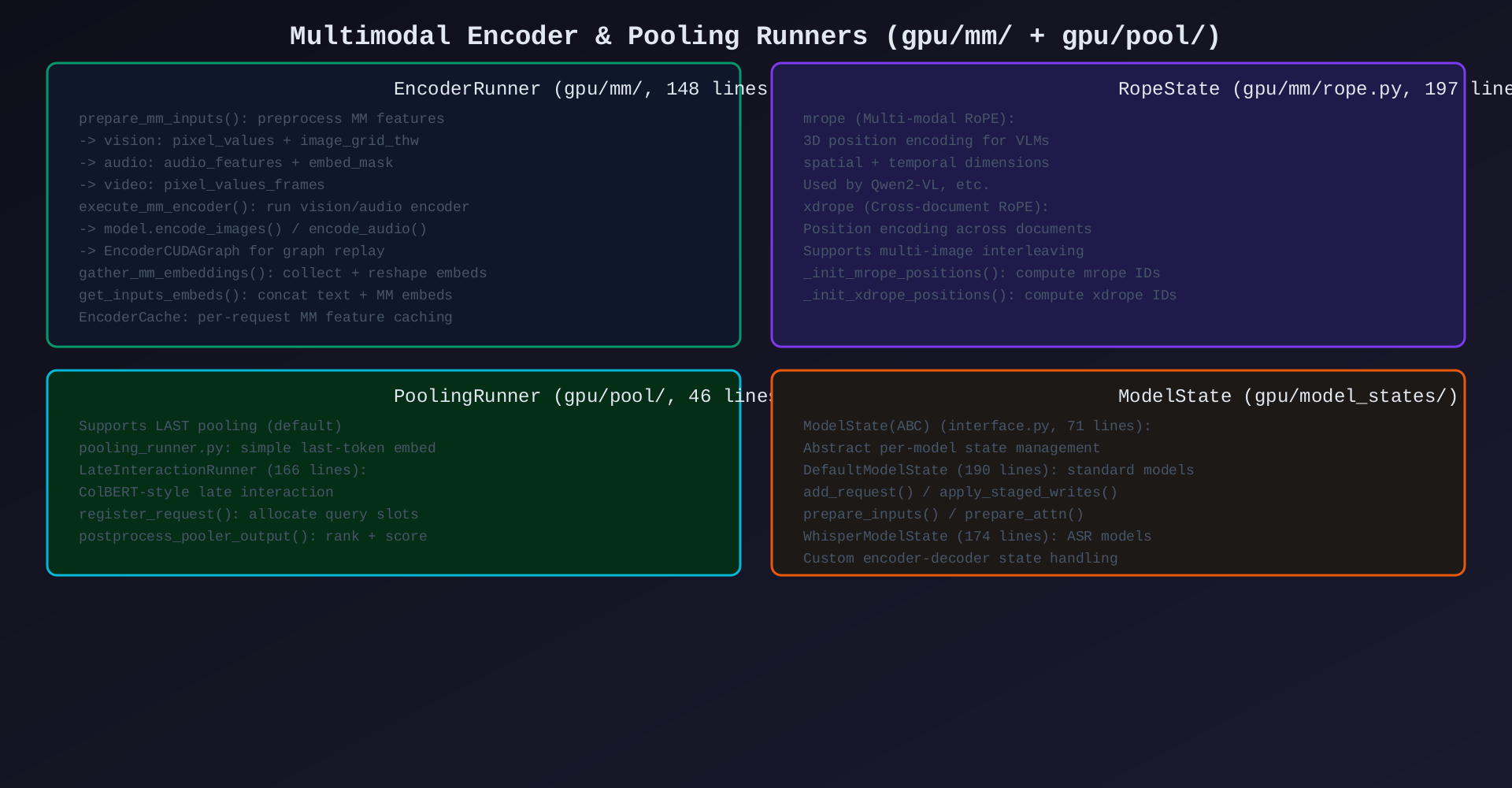
核心作用:多模态编码器执行 + Embedding 池化输出。
| 组件 | 行数 | 职责 |
|---|---|---|
EncoderRunner |
148 | vision/audio encoder 执行 |
EncoderCache |
40 | per-request MM 特征缓存 |
RopeState |
197 | mrope/xdrope 位置编码 |
PoolingRunner |
46 | LAST pooling (embedding) |
LateInteractionRunner |
166 | ColBERT 风格 late interaction |
架构图 :见 09-mm-encoder-pooling.svg
模块9:Mixin 扩展(3个 Mixin,~650行)
核心作用:通过 Mixin 向 GPUModelRunner 注入 LoRA / KV Connector / EC Connector 功能。
| Mixin | 行数 | 职责 |
|---|---|---|
LoRAModelRunnerMixin |
285 | 动态 LoRA 适配器管理 |
KVConnectorModelRunnerMixin |
283 | 跨 Worker KV Cache 传输 |
ECConnectorModelRunnerMixin |
78 | Expert Context 传输 |
模块10:支持工具(~1800行)
| 工具 | 行数 | 职责 |
|---|---|---|
utils.py |
549 | KVBlockZeroer, AttentionGroup, bind_kv_cache, memory utils |
workspace.py |
282 | WorkspaceManager: GPU 工作区管理 + lock/unlock |
mamba_utils.py |
273 | Mamba SSM copy buffers + preprocess/postprocess |
dp_utils.py |
229 | Data Parallel 批量协调 |
ubatch_utils.py |
243 | UBatch 辅助函数 |
gpu/attn_utils.py |
268 | Attention 辅助函数 |
gpu/buffer_utils.py |
217 | GPU 缓冲区分配 |
gpu/model_states/ |
~400 | ModelState ABC + Default + Whisper |
cpu_model_runner.py |
246 | CPU 推理回退 |
cpu_worker.py |
228 | CPU Worker 实现 |
三、模块调用关系与数据流
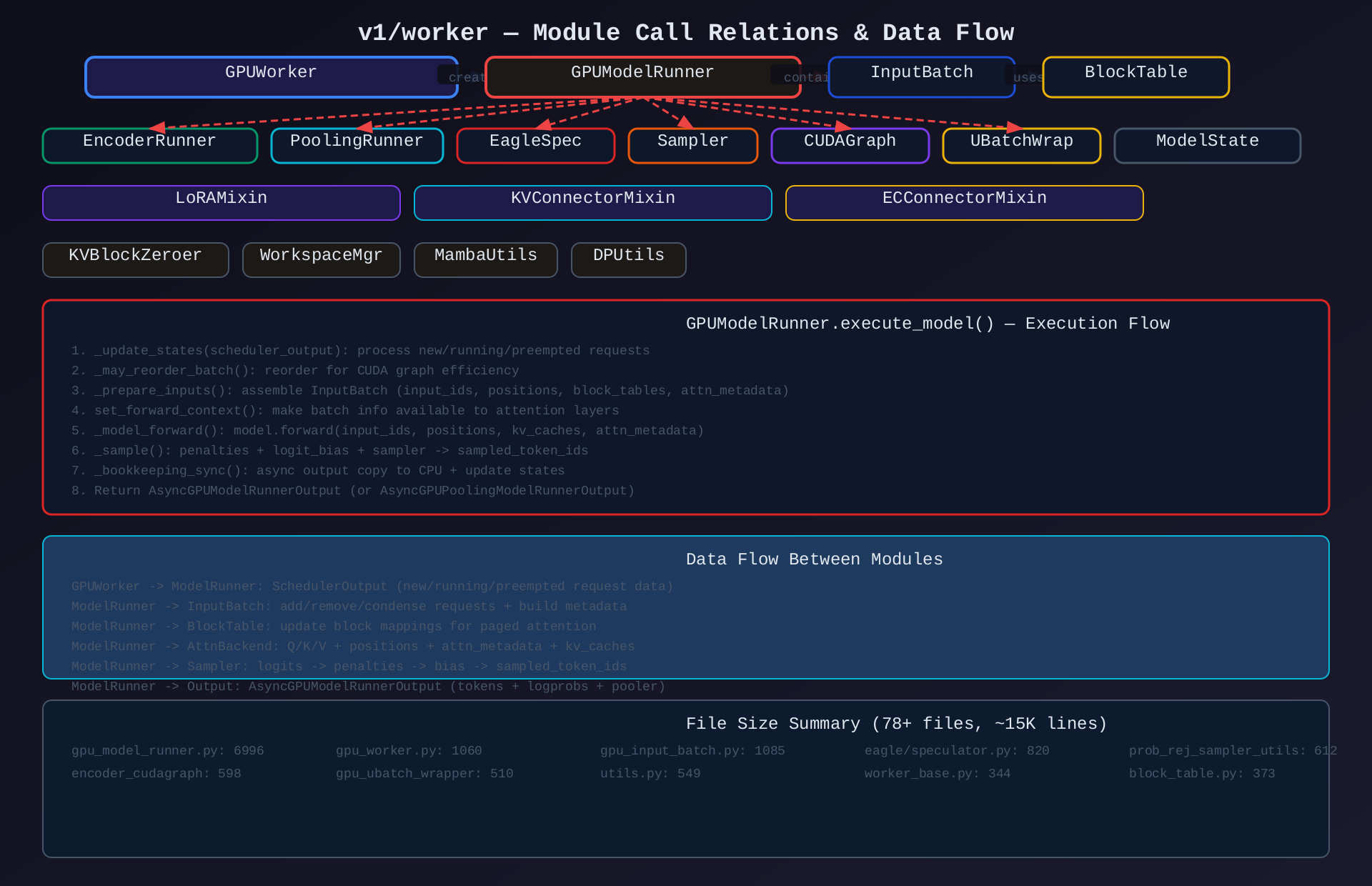
3.1 主要调用链
GPUWorker
├── init_device() → distributed init
├── load_model() → GPUModelRunner.__init__()
├── determine_available_memory() → profile_run()
├── initialize_from_config() → _allocate_kv_cache_tensors() + bind_kv_cache()
├── compile_or_warm_up_model() → capture_model() + torch.compile()
└── execute_model(scheduler_output)
├── _apply_mm_cache()
├── model_runner._update_states(scheduler_output)
│ ├── InputBatch.add_request() / remove_request()
│ ├── BlockTable.add_row() / clear_row()
│ └── ModelState.add_request()
├── model_runner._prepare_inputs()
│ ├── _prepare_input_ids()
│ ├── _get_positions()
│ ├── _build_attention_metadata()
│ └── InputBatch.refresh_metadata()
├── model_runner._model_forward()
│ ├── _preprocess()
│ ├── model.forward(input_ids, positions, kv_caches)
│ └── _determine_batch_execution_and_padding()
├── model_runner._sample()
│ ├── PenaltiesState.apply_staged_writes()
│ ├── LogitBiasState.apply_staged_writes()
│ ├── BadWordsState.apply_staged_writes()
│ └── Sampler(logits, metadata)
└── model_runner._bookkeeping_sync()
└── AsyncGPUModelRunnerOutput.get_output()3.2 数据类型流转
SchedulerOutput (from Engine)
→ GPUWorker.execute_model()
→ GPUModelRunner._update_states()
→ InputBatch: add/remove requests
→ BlockTable: update block mappings
→ ModelState: stage per-request state
→ GPUModelRunner._prepare_inputs()
→ InputBatch: input_ids, positions, block_tables, attn_metadata
→ GPUModelRunner._model_forward()
→ model.forward() → logits
→ GPUModelRunner._sample()
→ sampled_token_ids + logprobs
→ AsyncGPUModelRunnerOutput
→ CPU-staged output (async copy)
→ ModelRunnerOutput (returned to Engine)3.3 关键交互
| 调用方 | 被调用方 | 数据 | 方式 |
|---|---|---|---|
| GPUWorker | GPUModelRunner | SchedulerOutput | 方法调用 |
| ModelRunner | InputBatch | request state | 方法调用 |
| ModelRunner | BlockTable | block_ids | 方法调用 |
| ModelRunner | AttnBackend | Q/K/V + metadata | 方法调用 |
| ModelRunner | Sampler | logits → tokens | 方法调用 |
| ModelRunner | EncoderRunner | MM inputs → embeddings | 方法调用 |
| ModelRunner | KVBlockZeroer | block_ids to zero | 方法调用 |
| Worker | KVCache tensors | allocate/reshape/bind | 直接操作 |
| Worker | WorkspaceManager | GPU workspace lock | 上下文管理器 |
四、设计模式总结
| 模式 | 应用位置 | 说明 |
|---|---|---|
| 委托模式 | GPUWorker → ModelRunner | 生命周期 vs 推理逻辑分离 |
| Mixin 组合 | LoRA + KV + EC Mixin | 功能注入,避免继承爆炸 |
| 策略模式 | Sampler / AttnBackend / ModelState | 可插拔实现 |
| Staged Writes | Penalties/LogitBias/BadWords | 暂存→批量GPU提交 |
| 享元模式 | EncoderCache / WorkspaceManager | 资源复用 |
| 模板方法 | execute_model() | 固定骨架,子步骤可覆盖 |
| 代理模式 | WorkerWrapperBase | 远程调用代理 |
| 上下文管理器 | UBatchContext / WorkspaceManager | 资源自动清理 |
五、关键指标
| 指标 | 数值 |
|---|---|
| Worker 目录总代码量 | ~15K 行(78+ 文件) |
| GPUModelRunner | 6996 行(单一最大文件) |
| GPUWorker | 1060 行 |
| InputBatch | 1085 + 576 行 |
| Sampling Pipeline | ~1600 行 |
| Spec Decode | ~2000 行 |
| CUDA Graph + UBatch | ~1600 行 |
| Mixin 扩展 | ~650 行 |
| 支持模型 | 120+ 种(通过 model_executor) |
| Attention Backend | 12 + 8 MLA |
| 采样组件 | 8 个(penalties/bias/badwords/gumbel/minp/logprob/promptlogprob/sampler) |
六、架构亮点与设计权衡
亮点
- GPUModelRunner 统一推理入口:所有推理逻辑集中管理,便于优化和调试
- Staged Writes 批量更新:避免逐请求 GPU kernel launch,显著降低开销
- CUDA Graph 全覆盖:decode 阶段 graph replay,消除 kernel launch 开销
- Mixin 组合:LoRA/KV/EC 功能注入,不污染核心类
- Async Output Copy:异步 CPU copy stream,推理与输出传输并行
- BlockTable Paged Attention:虚拟内存式 KV 管理,零碎片
- Eagle 投机解码:利用 target model hidden states,高接受率
权衡
- GPUModelRunner 过大(6996行):虽用 Mixin 拆分,核心仍过于复杂
- Staged Writes 一致性:忘记 apply_staged_writes() 会引入 bug
- CUDA Graph 刚性:batch size 必须匹配捕获的 bucket,不支持动态
- Mixin 隐式依赖:Mixin 之间可能有隐式耦合
- UBatch 复杂性:通信-计算重叠增加调试难度
报告生成时间:2026-04-19 | 代码版本:vllm main branch