视频链接:https://www.bilibili.com/video/BV1g7dZBpEJG/?vd_source=5ba34935b7845cd15c65ef62c64ba82f
仓库链接:https://github.com/LitchiCheng/LLM-learning
最近在阅读《大模型驱动的具身智能:架构、设计与实现》,其中 LLM 不得不提注意力机制,已经有太多好的视频或文章针对于 1706.03762 Attention Is All You Need
https://arxiv.org/abs/1706.03762 进行分析介绍,
下面分享记录下自己学习过程和相关点的理解,节奏上会比较跳跃,不适合系统性学习,
最后用一段代码来测试注意力的计算过程。
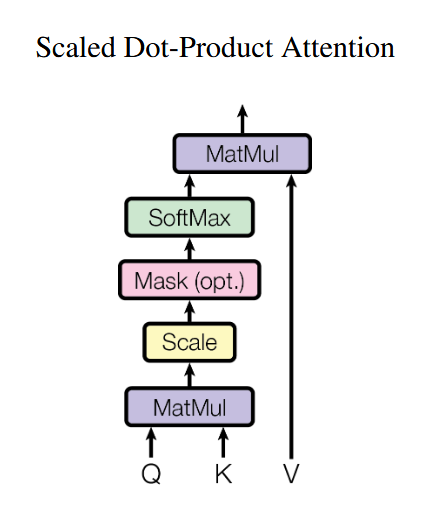
所有注意力都由 3 个向量计算,最后让模型 "看重点",自动决定该关注(权重高)哪些信息、忽略(权重低)哪些信息
- Query(查询 Q)现在要找什么
- Key(键 K)这里有什么信息
- Value(值 V)信息的实际内容
B, L, D 形状的张量是序列模型标准输入格式
batch_size, sequence_length, embedding_dimension
seq_len, embed_dim = 4, 8
world_states = torch.randn(1, seq_len, embed_dim)
[
[
[0.2, -0.5, 0.1, 0.8, -0.3, 0.6, 0.0, 0.4], # 位置0: "球位置"的8维特征
[-0.1, 0.3, 0.7, -0.2, 0.5, -0.4, 0.2, 0.1], # 位置1: "球速度"的8维特征
[0.4, -0.1, 0.2, 0.3, -0.6, 0.8, -0.2, 0.5], # 位置2: "墙壁"的8维特征
[-0.3, 0.6, -0.4, 0.1, 0.7, -0.2, 0.3, 0.0] # 位置3: "目标"的8维特征
]
]dim 设置为 8 是注意力机制的计算的一种编码形式,没有什么物理意义,相当于给每个概念(球位置/速度/墙壁/目标)分配一个 8 维的空间,让模型在这个高维空间里用线性代数(Q/K/V 投影、点积、softmax)来计算"谁该关注谁"。训练后,相似的物理状态会在 8 维空间中靠得更近
默认的 linear 神经网络随机分配了不同的权重(dim*dim),可以用 Q_k.weight 查看
每个 token 都会作为 Query 去查询所有 token 的 Key,决定把注意力放在哪里
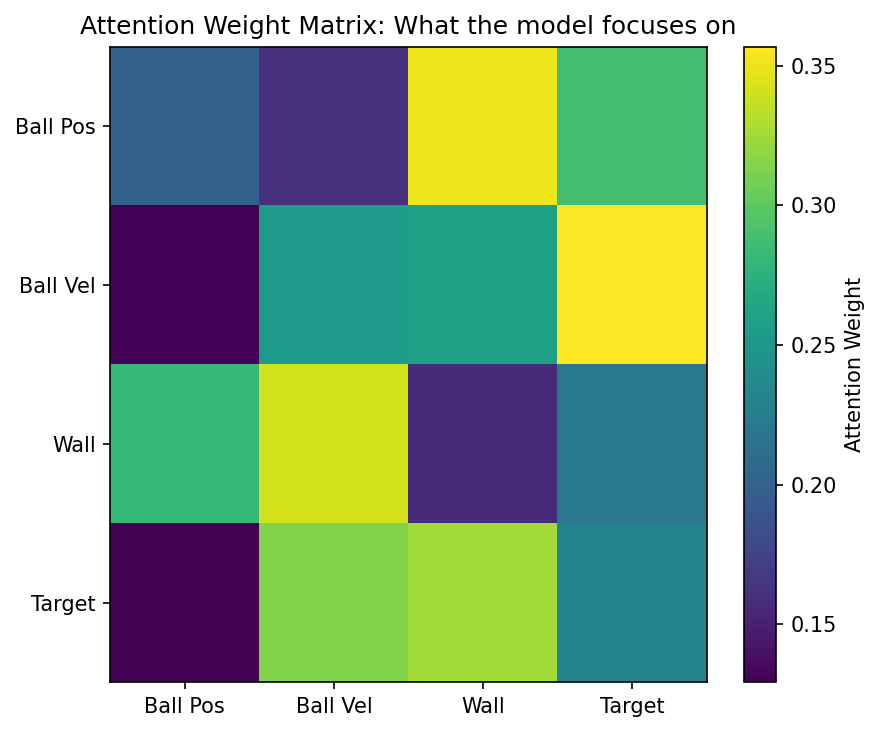
Q_位置 · K_速度^T → 高权重 # 速度和位置强相关(运动学)
Q_位置 · K_墙壁^T → 中权重 # 墙壁限制位置范围
Q_位置 · K_目标^T → 高权重 # 位置相对目标的距离很重要位置的输出会混合速度、目标、墙壁的信息,形成位置和前后速度,距离,目标都有关系的上下关联
Q_速度 · K_位置^T → 高权重 # 速度改变位置
Q_速度 · K_墙壁^T → 高权重 # 即将撞墙时速度会反转(反弹)
Q_速度 · K_目标^T → 中权重 # 速度方向是否朝向目标模型理解到,速度和墙壁有因果关联,这是反事实推理的基础
Q_墙壁 · K_位置^T → 高权重 # 只关注靠近墙壁的物体位置
Q_墙壁 · K_速度^T → 高权重 # 关注朝向墙壁运动的速度
Q_墙壁 · K_目标^T → 低权重 # 与目标关系不大墙壁"知道"什么时候该拦截,什么时候无关
完整的测试代码
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
os.makedirs('/mnt/agents/output', exist_ok=True)
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
class SelfAttention(nn.Module):
def __init__(self, embed_dim):
super().__init__()
self.scale = embed_dim ** -0.5 # 缩放因子 1/√d_k
self.W_q = nn.Linear(embed_dim, embed_dim) # Query 投影
self.W_k = nn.Linear(embed_dim, embed_dim) # Key 投影
self.W_v = nn.Linear(embed_dim, embed_dim) # Value 投影
def forward(self, x, return_attention=False):
Q = self.W_q(x) # [B, seq, dim]
print(self.W_q.weight)
K = self.W_k(x) # [B, seq, dim]
V = self.W_v(x) # [B, seq, dim]
# QK^T / √d_k
scores = torch.matmul(Q, K.transpose(-2, -1)) * self.scale
# scores: [B, seq, seq] - 每个位置对其他位置的关注成都
# Softmax 归一化: 权重高的关注, 权重低的忽略
attn_weights = F.softmax(scores, dim=-1)
out = torch.matmul(attn_weights, V) # [B, seq, dim]
# 输出是 V 的加权组合,权重由 QK 相似度决定
if return_attention:
return out, attn_weights
return out
torch.manual_seed(42)
seq_len, embed_dim = 4, 8
world_states = torch.randn(1, seq_len, embed_dim)
attn_layer = SelfAttention(embed_dim)
output, attention_map = attn_layer(world_states, return_attention=True)
print(f"Input shape: {world_states.shape}")
print(f"Attention weights:\n{attention_map[0].detach().numpy().round(3)}")
fig, ax = plt.subplots(figsize=(6, 5))
labels = ['Ball Pos', 'Ball Vel', 'Wall', 'Target']
im = ax.imshow(attention_map[0].detach().numpy(), cmap='viridis', aspect='auto')
ax.set_xticks(range(seq_len))
ax.set_yticks(range(seq_len))
ax.set_xticklabels(labels)
ax.set_yticklabels(labels)
ax.set_title('Attention Weight Matrix: What the model focuses on')
plt.colorbar(im, ax=ax, label='Attention Weight')
plt.tight_layout()
plt.savefig('/mnt/agents/output/attention_map.png', dpi=150, bbox_inches='tight')
plt.close(fig)
print("Saved: /mnt/agents/output/attention_map.png")