从 ReAct 到 Plan-and-Execute:AI Agent 长任务执行的架构演进
引言:当单步推理遭遇长任务
在 AI Agent 的架构演进史中,ReAct(Reasoning + Acting)无疑是一座重要的里程碑。它通过将"思考(Thought)"与"行动(Action)"交织循环,让 LLM 首次具备了在工具环境中自主探索的能力。无论是调用搜索引擎、操作数据库,还是与 API 交互,ReAct 都展现出了惊人的即时决策能力。
然而,当 Agent 从简单的"查询天气"迈向"重构后端服务、运行全量测试并提交 PR"这类长程任务时,ReAct 的架构瓶颈开始显现。作为长期深耕 AI Agent 工程落地的架构师,我观察到:单步推理模式在长任务场景下存在系统性的能力边界。这正是 Plan-and-Execute 范式兴起的根本原因。
本文将从 论文理论、工程架构、源码实现 三个层面,系统解析为何必须将规划与执行显式分离,以及这一分离如何在现代 Agent 系统中落地。
一、ReAct 的结构性局限:短视的每一步
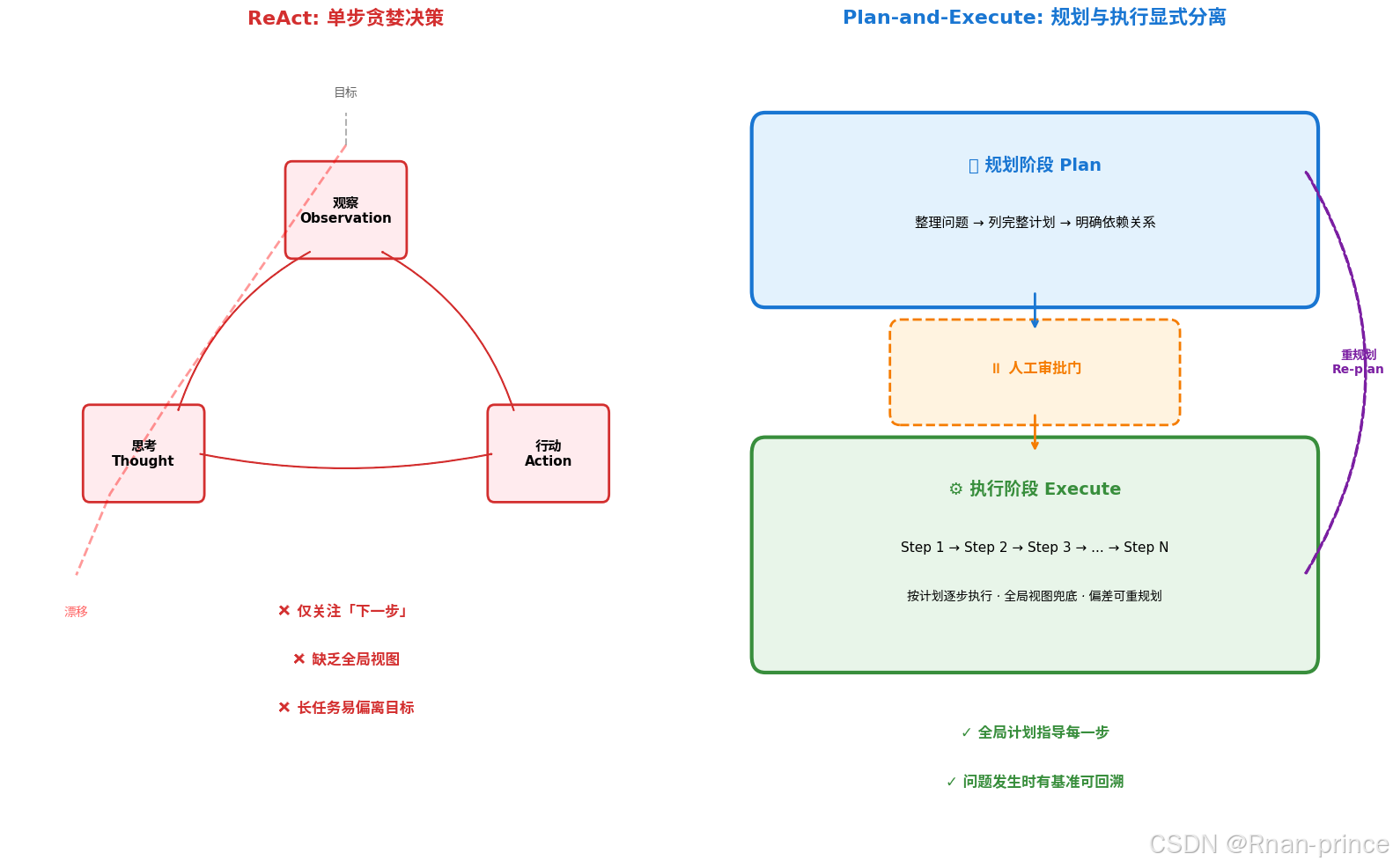
ReAct 的核心循环是:观察(Observation)→ 思考(Thought)→ 行动(Action)。问题在于,这里的 Thought 本质上只关注"下一步如何执行",是一种局部的、贪婪的决策机制。
这种设计在短任务中表现优异,但在长任务中会产生两个致命问题:
1. 目标漂移(Goal Drift)
处理长任务时,ReAct 的每一步都在当前上下文窗口内做局部最优决策。就像一个人在迷雾中行走,只看得到脚下的一步路。当任务涉及"重构后端→运行测试→提交 PR"这类多阶段目标时,Agent 很容易在第三步陷入某个具体的测试用例调试,而忘记了最初的重构目标。上下文窗口的有限性使得初始目标被逐渐稀释,最终行动轨迹偏离原始意图。
2. 方向修正能力匮乏
当执行过程中遇到意外(如测试失败、API 变更、权限不足)时,ReAct 缺乏全局视图可供参照。它只能在当前上下文中临时调整下一步行动,这种"头痛医头"的局部修正是低效的。想象一个架构师在重构过程中发现某处设计缺陷------ReAct 会选择在当前文件打补丁,而拥有全局计划的架构师会审视整个模块依赖关系,决定是否回退到更早的阶段重新设计。
本质矛盾:ReAct 将"规划"与"执行"耦合在每一个时间步中,导致规划粒度被压缩为单步,丧失了长程任务的结构性。
二、论文层:Plan-and-Solve Prompting 的理论奠基
这一认知在学术界有明确的理论支撑。ACL 2023 论文《Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models》(arXiv 2305.04091)系统地揭示了"规划先行"的必要性。
问题诊断:Zero-Shot CoT 为何频繁失败?
研究团队发现,Zero-Shot Chain-of-Thought 在数学推理、逻辑推理等任务上,错误主要集中在两类:
- 计算错误:中间步骤的数值运算出错
- 步骤遗漏:关键推理步骤被跳过,导致结论不成立
根本原因并非模型计算能力不足,而是模型在尚未厘清全局结构时就开始逐步推理。这本质上与 ReAct 在长任务中的困境同源:缺乏宏观规划指导的微步骤推理,容易陷入局部陷阱。
方法论:显式两阶段提示
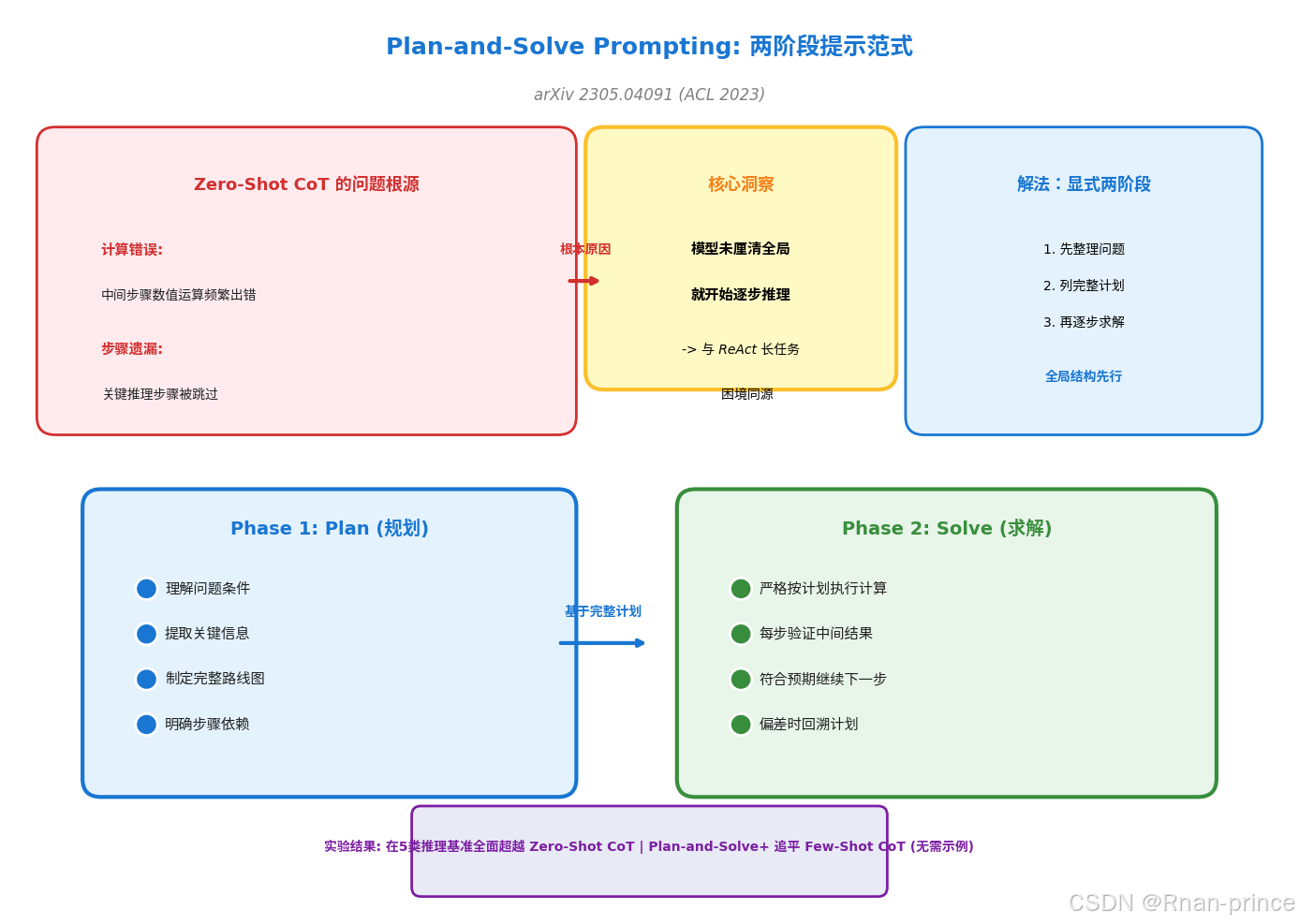
Plan-and-Solve 提出将提示词拆分为两个明确的阶段:
第一阶段:规划(Plan)
- 整理问题条件与目标
- 列出完整的求解路线图
- 明确每一步的输入输出依赖
第二阶段:求解(Solve)
- 严格按照计划逐步执行计算
- 每一步验证是否符合预期
- 遭遇偏差时以计划为基准调整
实验结果
该方法在 GSM8K、AQuA 等 5 类推理基准上全面超越 Zero-Shot CoT;其增强版 Plan-and-Solve+ 更是在无需手工示例的情况下,追平了需要精心构造 Few-Shot 示例的 Few-Shot CoT。
对 Agent 架构的启示 :虽然论文聚焦于数学推理任务,但其核心结论与 Agent 系统设计高度一致------规划与执行是两种本质不同的认知任务,只有显式分开,长任务才能稳定运行、不偏离目标。
三、工程层:Orchestrator-Subagents 模式
理论需要转化为可落地的架构。Anthropic 在工程实践中提出的 Orchestrator-Subagents 模式,是 Plan-and-Execute 范式在分布式 Agent 系统中的典型实现。
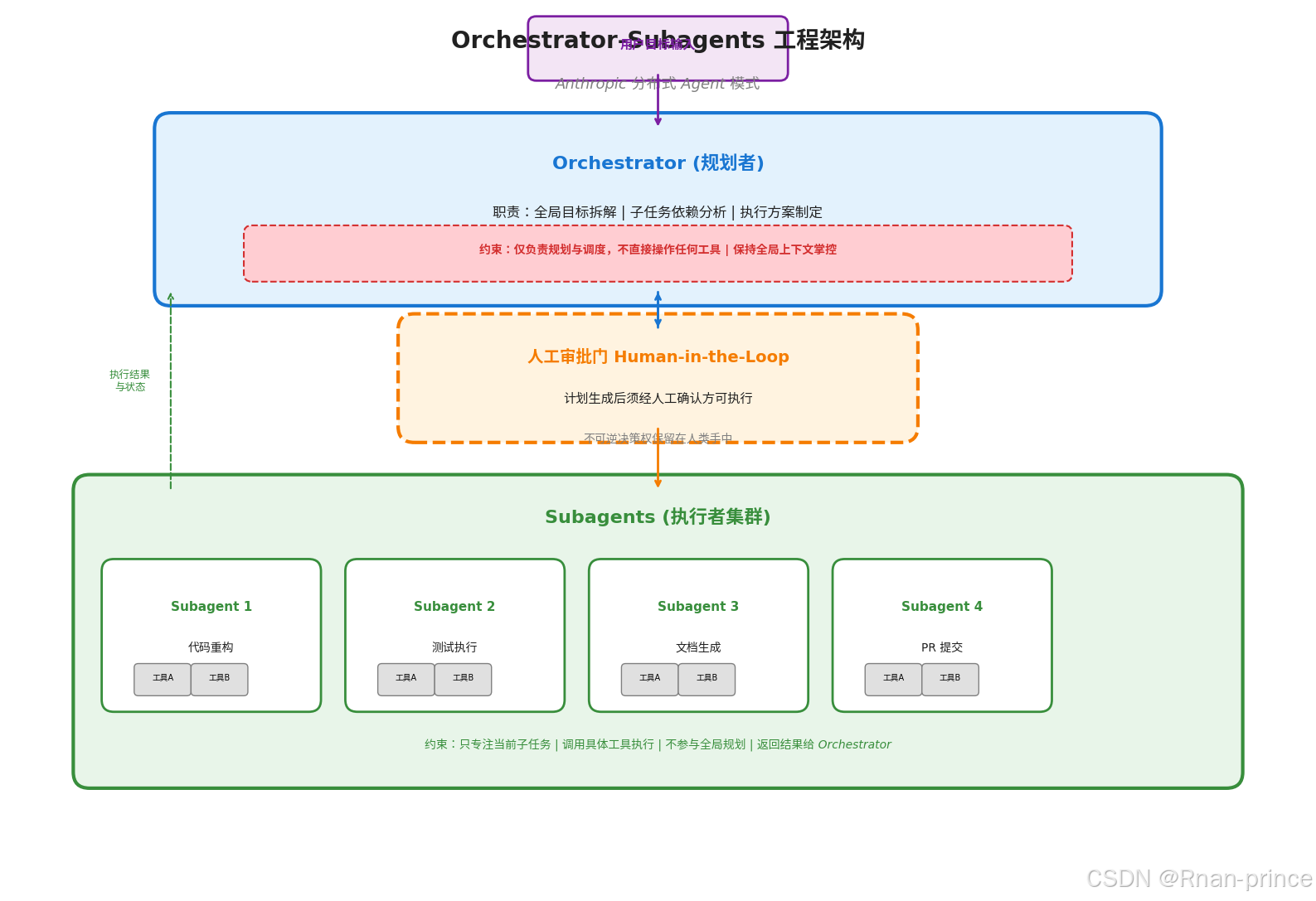
角色分离:两种认知任务两种实体
Orchestrator(规划者)
- 职责:接收用户的高层次目标(如"将单体应用拆分为微服务"),将其拆解为若干有依赖关系的子任务,制定完整的执行方案。
- 约束 :仅负责规划与调度,不直接操作任何工具。它保持对全局上下文的掌控,确保子任务之间的依赖关系、数据流转和一致性约束得到满足。
- 认知模式:抽象、全局、依赖推理。
Subagent(执行者)
- 职责:接收 Orchestrator 分配的单一子任务(如"将用户服务模块提取为独立 Docker 容器"),调用具体工具(代码编辑、编译、测试)完成执行。
- 约束 :只专注当前步骤的输入输出,不参与全局规划。它将执行结果(成功/失败/日志)返回给 Orchestrator。
- 认知模式:具体、局部、操作导向。
人工审批门(Human-in-the-Loop)
在 Orchestrator 生成完整计划后,系统引入一个关键的控制节点:人工审批。
- 计划必须经过人类确认后方可进入执行阶段
- 不可逆操作(如代码提交、数据删除、费用支出)的决策权保留在人类手中
- 审批通过后,Subagents 才能按序启动
这一设计不是简单的"安全兜底",而是对规划质量的外部验证。人类可以通过阅读计划,发现 Orchestrator 是否误解了意图、是否遗漏了关键步骤、是否选择了不合适的工具链。
四、源码层:Claude Code Plan Mode 的实现解析
理论最终要在代码中跑起来。Anthropic 的 Claude Code 在其实现中提供了一个精妙的范例------Plan Mode。通过分析其 queryLoop 的核心逻辑,我们可以看到 Plan-and-Execute 如何在单一事件循环中落地。
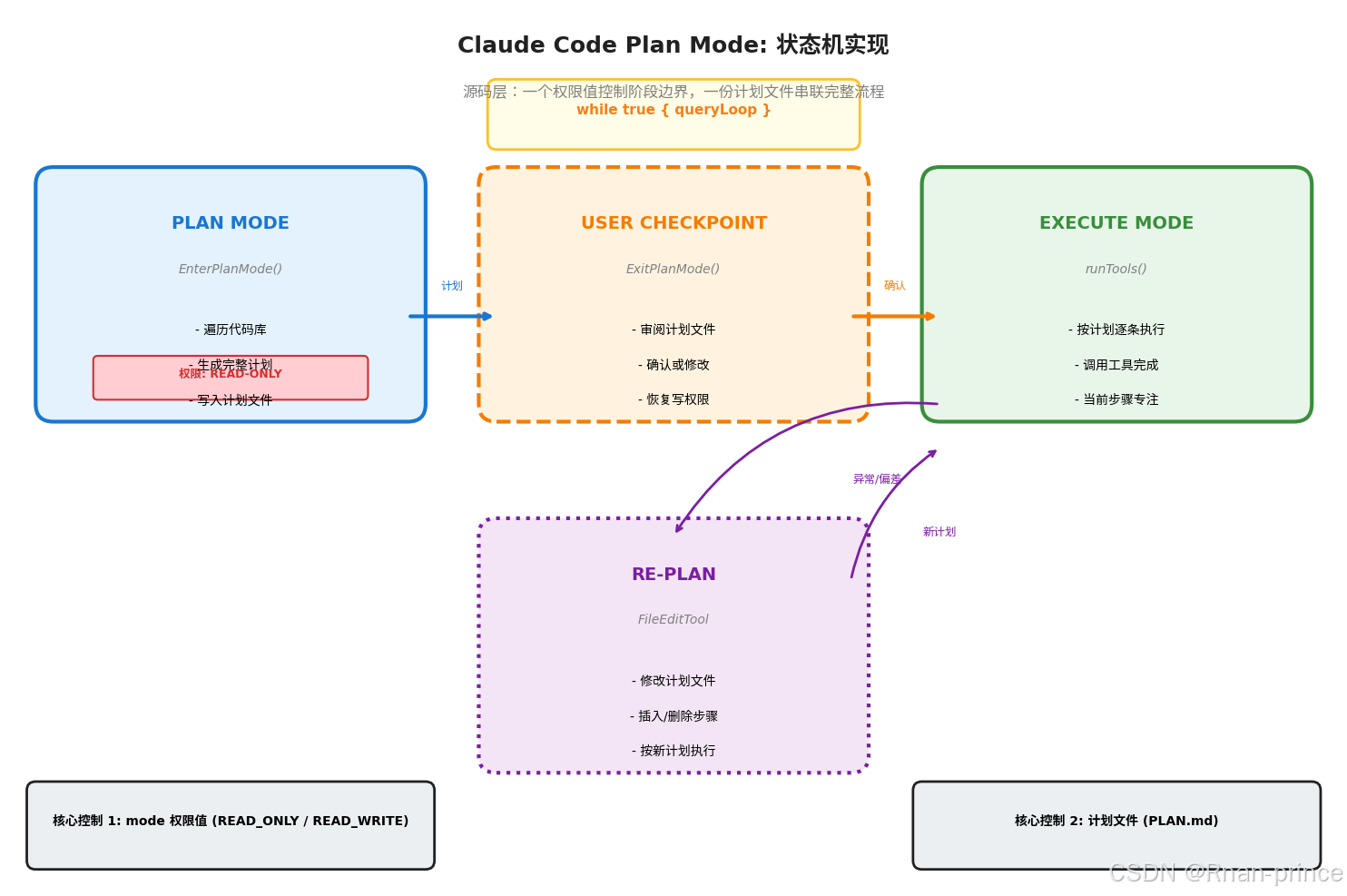
架构核心:权限值 + 计划文件
整个系统在一个 while true 循环中运行,但通过两个极简的抽象实现了阶段隔离:
- 权限值(Mode):控制当前 Agent 处于"规划态"还是"执行态",决定工具调用的可用范围
- 计划文件(Plan File):持久化的执行蓝图,串联起完整的任务生命周期
阶段一:Plan(规划)
当用户输入复杂任务时,系统调用 EnterPlanMode,此时 Agent 进入只读状态:
- 可以遍历代码库、读取文件、分析依赖关系
- 所有写操作(文件编辑、命令执行)被禁用,防止在思考阶段就产生副作用
- 将生成的完整计划写入计划文件(如
PLAN.md),包含步骤列表、每步的工具调用、预期结果和回滚策略
这一阶段对应 Orchestrator 的职责:全局分析,产出结构化计划。
阶段二:用户审批
规划完成后,系统调用 ExitPlanMode,暂停循环,等待用户确认:
- 用户可审阅计划文件,提出修改意见
- 若计划有误,可要求重新生成(Re-plan)
- 确认无误后,用户批准,系统恢复写操作权限
这是人工审批门的源码实现,将不可逆的决策权明确保留在人类手中。
阶段三:Execute(执行)
审批通过后,runTools 启动,Agent 进入执行态:
- 按计划文件逐条执行,每完成一步更新进度
- 子任务被派发给具体的工具模块(类比 Subagent)
- 执行者只关注当前步骤,不重新规划
阶段四:Re-plan(重规划)
执行过程中若遭遇意外(如某步骤工具返回错误、环境发生变化),系统不强行继续,也不局部修修补补:
- 通过
FileEditTool修改计划文件 - 可在当前步骤后插入新步骤、删除不可行步骤、或回退到某一步重新执行
- 修改后的计划成为新的执行基准,下一步按新计划执行
工程本质:一个权限值控制阶段边界(规划态 ↔ 执行态),一份计划文件串联完整流程。这种设计保持了 ReAct 循环的简洁性,但通过 Mode 切换和文件持久化,显式地引入了全局规划层。
五、三层总结:从认知科学到代码实现
回顾 Plan-and-Execute 的演进路径,我们可以看到一个清晰的知识堆栈:
| 层级 | 代表 | 核心贡献 | 解决的问题 |
|---|---|---|---|
| 论文层 | Plan-and-Solve Prompting (arXiv 2305.04091) | 提供"先规划、再执行"的提示词范式 | Zero-Shot CoT 的计算错误与步骤遗漏;从理论上证明规划先行的必要性 |
| 工程层 | Anthropic Orchestrator-Subagents | 将思路转化为可上线的分布式 Agent 架构 | 长任务的目标漂移与局部修正困境;引入人工审批门保障安全 |
| 源码层 | Claude Code Plan Mode | 以 mode 值 + 计划文件,在单一 while true 中实现完整流程 |
在单体内核中落地规划-审批-执行-重规划的闭环 |
核心理念贯穿始终:
规划与执行是两种不同的认知任务。规划需要全局抽象能力,执行需要局部操作能力。只有显式分离两者,长任务才能在复杂环境中稳定运行、不偏离目标。
结语:Agent 架构的"慢思考"与"快思考"
诺贝尔经济学奖得主丹尼尔·卡尼曼提出人类思维有两套系统:系统 1(快速、直觉、自动)和系统 2(缓慢、逻辑、刻意)。
ReAct 像是 Agent 的"系统 1"------快速响应环境,适合短平快的工具调用。而 Plan-and-Execute 则是 Agent 的"系统 2"------在遇到重大、复杂、长程任务时,先停下来思考全局,制定战略,再分步战术执行。
作为 Agent 架构师,我们的任务不是抛弃 ReAct,而是明确其适用边界,并在长任务场景中引入 Plan-and-Execute 的显式分层。未来的 Agent 系统,必将是这两种认知模式的有机融合:用 Plan 保障方向正确,用 Execute 保障落地效率,用 Human-in-the-Loop 保障最终决策权。
这不仅是一种工程技巧,更是对智能体认知结构的深层理解。
(本文涉及的论文 arXiv 2305.04091 及 Claude Code 相关实现细节,建议读者结合原文进一步研读。)