日常开发中,要说数据结构选型碰到最多的场景,我觉得就是Redis。Redis提供了字符串、哈希、列表、集合、有序集合这5种基本数据类型,再加上Bitmap、HyperLogLog、GEO这些扩展类型,同一个业务需求摆在面前,选哪个类型来实现,「这里面全是数据结构的选型判断」。因此你还是得熟悉一下各种数据结构的优缺点的,它还是跟你业务开发有关的。
我举几个例子。
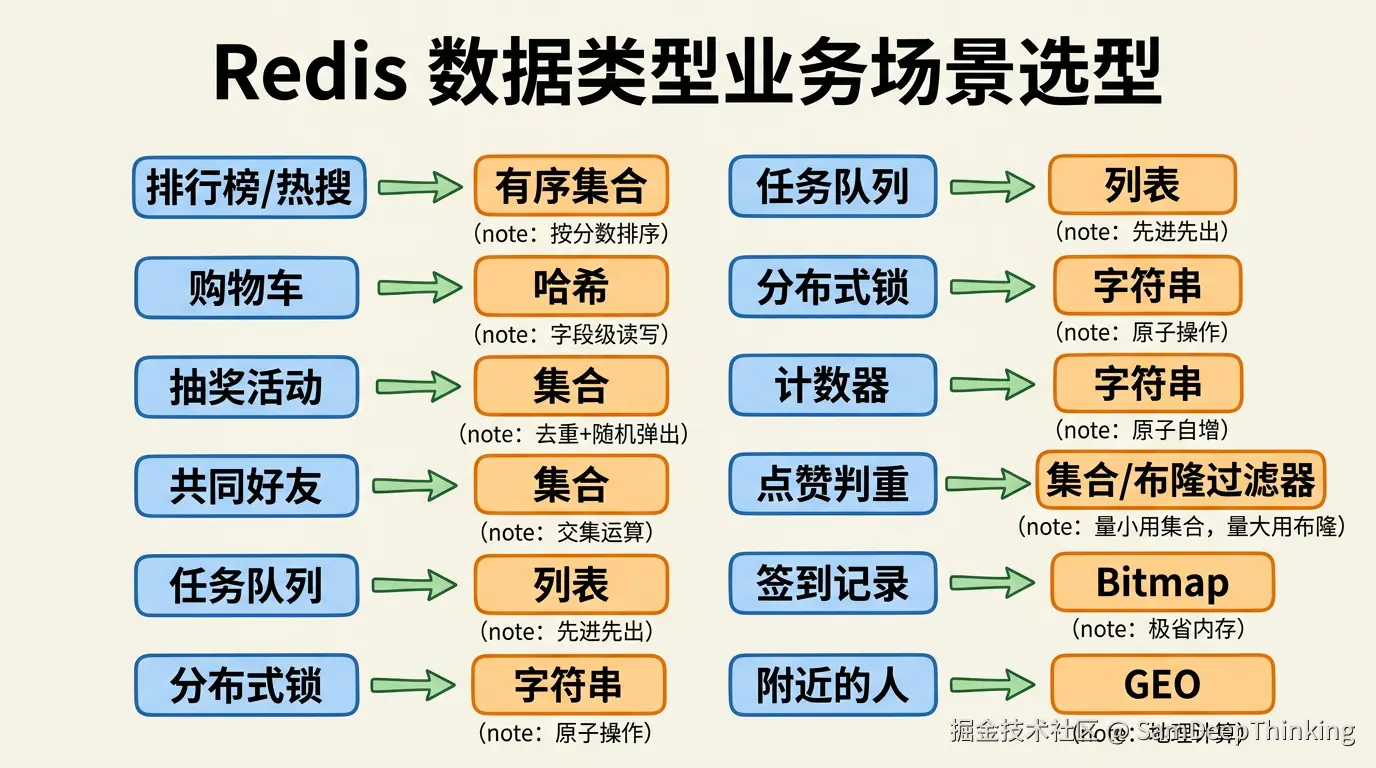
做排行榜,用有序集合。ZADD写入数据时带上分数,ZINCRBY实时更新分数,ZREVRANGE一条命令直接拿到Top N。不管是热搜榜、积分榜还是直播间的打赏排行,只要涉及「按某个数值排序并实时更新」的场景,有序集合都是最常见的选择。如果你用字符串存一个JSON数组来做排行榜,每次更新一个用户的分数就要把整个数组反序列化出来、改值、重新排序、再序列化写回去。高并发场景下这个方案撑不住。
做购物车,常用的方案是哈希。用户ID做key,商品ID做field,数量做value。用户加购就HINCRBY给对应商品数量加1,删除商品就HDEL,查看整个购物车就HGETALL。如果用字符串存一整个JSON对象,改一个商品的数量就要读出整个购物车、改完再整个写回去,并发场景下容易出现互相覆盖的问题,网络传输的数据量也更大。
做抽奖,用集合。把参与者的用户ID用SADD加进去,天然去重,同一个用户加多少次都只算一个。开奖的时候SPOP随机弹出中奖者,或者用SRANDMEMBER随机取但不移除。如果你用列表来做,用户可能重复参加,还得自己写去重逻辑。
做共同好友,用集合的交集运算。用户A的好友列表是一个集合,用户B的好友列表是另一个集合,SINTER一条命令就能算出共同好友。你在应用层自己用两个List去算交集,数据量一大,性能差距就出来了。
简单的异步任务队列用列表。生产者LPUSH把任务推进去,消费者BRPOP阻塞等待,天然的先进先出。正式的消息队列场景当然会用Kafka或者RocketMQ,但很多内部的轻量级异步任务,用列表就够了。
分布式锁用字符串。SET lock_key unique_value NX EX 30一条命令搞定,NX保证同一时刻只有一个客户端能拿到锁,EX设置过期时间防止死锁。
阅读量、点赞数这种计数器也用字符串。INCR原子自增,高并发下不会出现计数错乱,比你在应用层读出来加1再写回去靠谱得多。
点赞和收藏这种功能比单纯的计数器多一层复杂度:不仅要计数,还要判重。用户点过赞了就不能再点,你得快速判断某个用户是否已经对某条内容点过赞。数据量不大的时候,用集合就行,每条内容一个集合,SADD把点赞用户ID加进去,SISMEMBER判断是否已赞。但遇到百万级点赞的热门内容,一个集合要存上百万个用户ID,内存开销很大。有大厂在技术峰会上公开分享过,他们在「是否赞过」这类判重场景下,最终选的是布隆过滤器。布隆过滤器用位数组加多个哈希函数做概率判重,100万条记录只需要约1.2MB内存就能控制在1%以内的误判率,相比集合存百万个成员要节省几十倍的内存。误判的影响是:极少数没点过赞的用户可能被误认为已赞,但已赞的用户不会漏判。在点赞这种业务场景下,偶尔的误判影响有限,但省下来的内存很可观。同一个「判重」需求,几百个赞用集合,百万级赞用布隆过滤器,选择完全取决于数据量级。
这些场景在实际项目里天天碰到。你做技术方案评审的时候,用哪种类型、为什么用这个不用那个,得说得清楚。
每一次选择背后都是对数据结构特点的判断。有序集合能做排行榜,是因为它内部维护了按分数排序的结构,天然支持范围查询。哈希能做购物车,是因为支持字段级别的独立读写,不需要整体序列化。集合能做共同好友,是因为支持数学意义上的交集运算。你不知道这些数据结构各自的特点和适用场景,就没办法做选型,也说不清楚选择的理由。
下面这张表整理了Redis常见的业务场景和推荐的数据类型选择,做技术方案的时候可以直接对照:
| 业务场景 | 推荐数据类型 | 常用命令 | 选它的原因 |
|---|---|---|---|
| 排行榜/热搜 | 有序集合 | ZADD/ZREVRANGE/ZINCRBY | 按分数排序,支持范围查询和实时更新 |
| 购物车 | 哈希 | HINCRBY/HDEL/HGETALL | 字段级读写,避免整体序列化 |
| 抽奖/去重集合 | 集合 | SADD/SPOP/SRANDMEMBER | 天然去重,支持随机弹出 |
| 共同好友/标签交集 | 集合 | SINTER/SUNION/SDIFF | 内置集合运算 |
| 异步任务队列 | 列表 | LPUSH/BRPOP | 先进先出,支持阻塞弹出 |
| 分布式锁 | 字符串 | SET NX EX | 原子操作,支持互斥和超时 |
| 计数器(阅读量/点赞) | 字符串 | INCR/INCRBY | 原子自增,并发安全 |
| 点赞/收藏判重 | 集合或布隆过滤器 | SADD/SISMEMBER或BF.ADD/BF.EXISTS | 量小用集合精确判重,量大用布隆过滤器省内存 |
| 对象缓存/Session | 哈希或字符串 | HSET/HGET或SET/GET | 需要局部更新用哈希,整体读写用字符串 |
| 用户签到记录 | Bitmap | SETBIT/BITCOUNT | 一个用户一年只需46字节 |
| 附近的人 | GEO | GEOADD/GEORADIUS | 置地理位置计算 |
这个道理不只在Redis里成立。给MySQL表加索引,也是在做数据结构选型。InnoDB默认用B+树索引,B+树的非叶子节点只存索引键不存行数据,一个16KB的页能装大量键值,树的高度很矮,几次磁盘IO就能定位到数据行。联合索引为什么要遵循最左前缀原则?因为B+树的排序是按索引列顺序来的,跳过第一列直接查第二列,索引用不上。你理解了B+树的结构,这些规则就不用死记硬背。Java里ArrayList和LinkedList怎么选、HashMap创建时要不要指定初始容量,这些日常开发决策的背后也全是对数据结构优缺点的判断。
去大厂面试,数据结构也确实绕不开。面试官让你手写LRU缓存,考的不是你能不能背出模板代码。他想看的是你的推导过程:按访问时间淘汰,意味着需要O(1)查找,所以用哈希表;也需要维护访问顺序且O(1)移动和淘汰,所以用双向链表。两个组合起来刚好满足所有需求。这个从需求推导出数据结构组合的过程,和你在项目里做Redis选型、做索引设计时的思路是一样的。面试考的和工作中用的,是同一个能力。
做了这么多年开发,我觉得数据结构的价值不在于你能手写多少种算法实现,而在于你面对一个具体的业务需求时,脑子里有足够多的候选方案,知道每种方案的优缺点和适用场景,能快速做出合理的选择并说清楚原因。这个选型能力,是日常开发、技术方案评审、大厂面试里都用得到的底层能力。没有捷径,得靠对数据结构特点的理解一点点积累起来。
学数据结构不是为了手写红黑树,而是为了面对具体业务需求时,你知道该选什么、为什么选它。
希望这篇内容可以帮到你。
我的知乎名是:
- SamDeepThinking
最近写的秒杀专栏的地址是:www.zhihu.com/column/c_20...