今天参加了Google BwA 杭州场(Gemma 4 专题全国首发)线下活动,感觉挺有意思的。这篇文章简单总结一下活动的主要内容。


关于MoE模型
本地大模型的一大问题就是运行速度慢。会上说的让我比较印象深刻的一个点就是,Gemma 4有多个版本,其中26B版本的性能相比31B差距不大,但是速度比31B快好几倍。
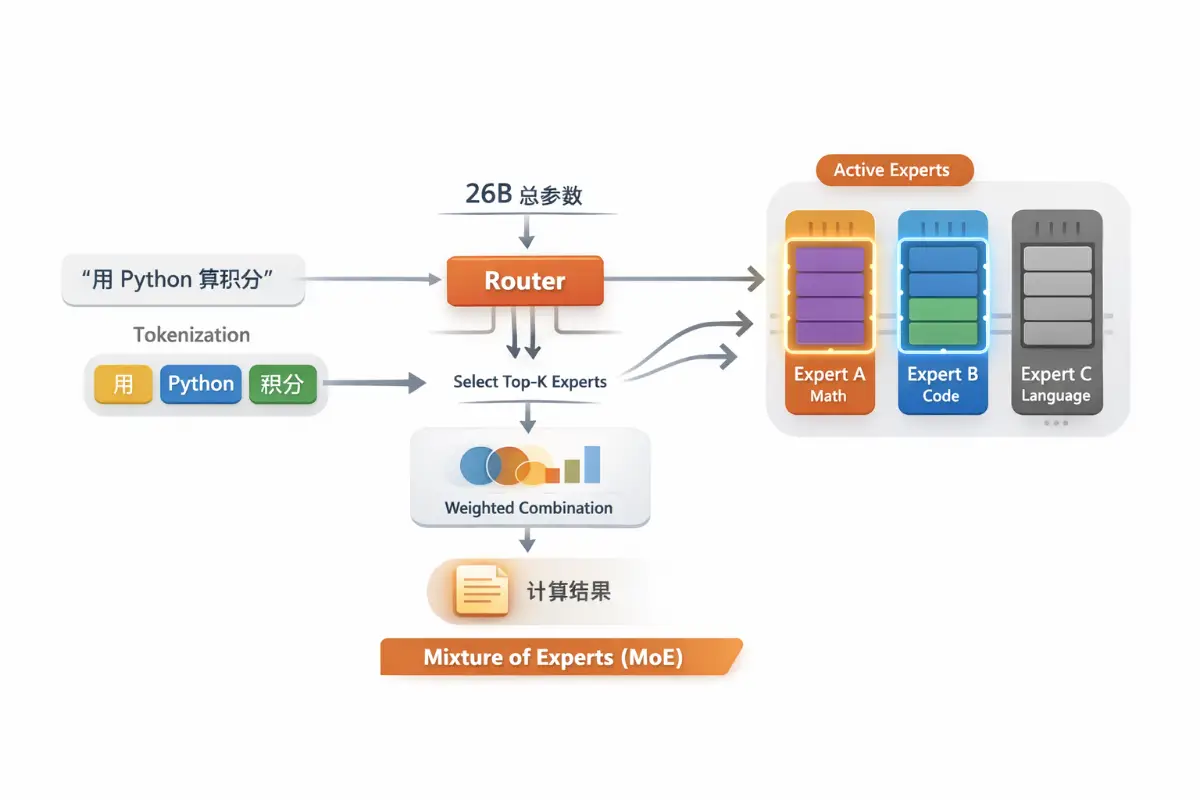
原因是26B是MoE模型。26B完整名字是26B A4B,这里的A4B指的是Active 4B,也就是每次实际只激活4B参数(B是Billion的缩写,1B = 10亿)。
我对大模型的实现了解不多,所以问了一下ChatGPT,对MoE模型给出了通俗的解释:

Gemma 4 模型微调
活动中,我们实际跟着老师做了两项任务。
第一个任务是Gemma 4模型的微调,这个任务代码放在一个叫hello-rocm的项目里面,用于ROCM项目的入门科普。其中ROCM是一个类似CUDA的项目,用于AMD显卡。
下载了这个Notebook以后,可以上传到Google Colab里面运行。Colab提供了远程高性能的 Jupyter Notebook 开发环境,对于本地没有高性能开发环境的人来说很方便,而且是免费的。
https://colab.research.google.com/
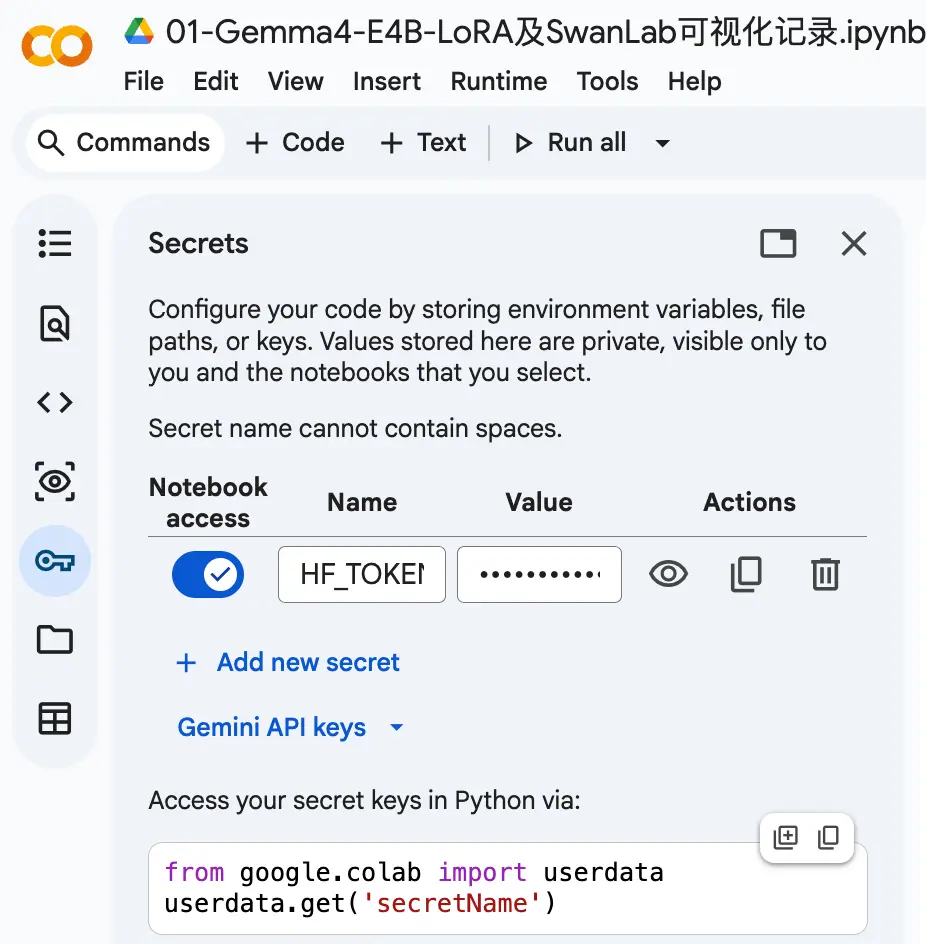
需要说明的是,这里面用到了一个HF_TOKEN的环境变量,需要去Hugging Face注册账号并创建一个access token,然后设置到Colab的Secrets中。
在Android Studio中使用Gemma 4开发
Gemma 4可以在多种平台体验和使用。

其中一种就是Android Studio,Agent模式可以调用本地模型开发代码。
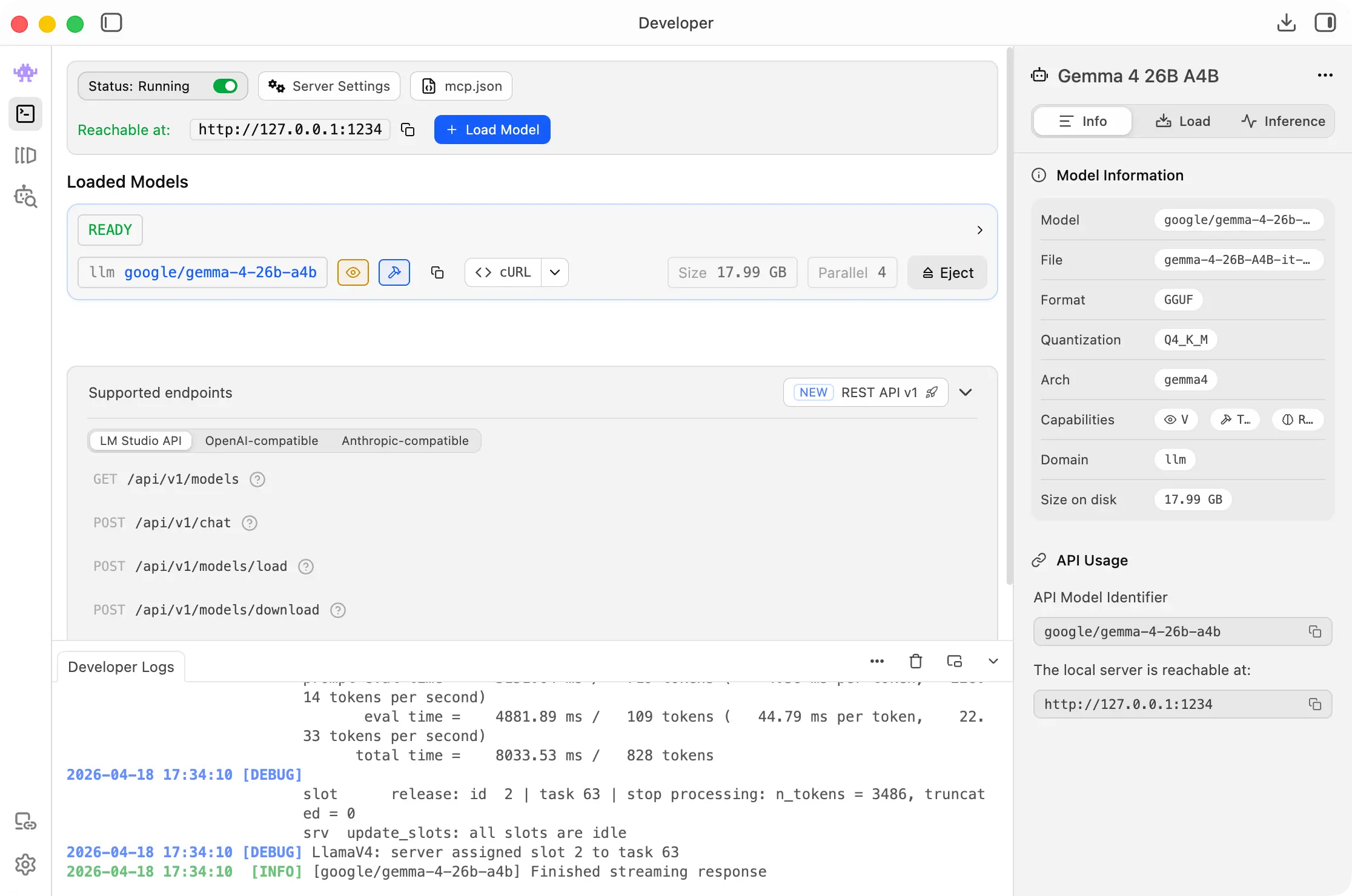
下载LM Studio 或者 Ollama ,安装对应的模型,推荐Gemma 4 26B A4B。
以LM Studio为例,下载好模型以后,切到Developer页面,开启本地的端口就可以了。
然后在Android Studio中按照官方文档去配置就行了。
https://developer.android.com/studio/gemini/use-a-local-model?hl=zh-cn
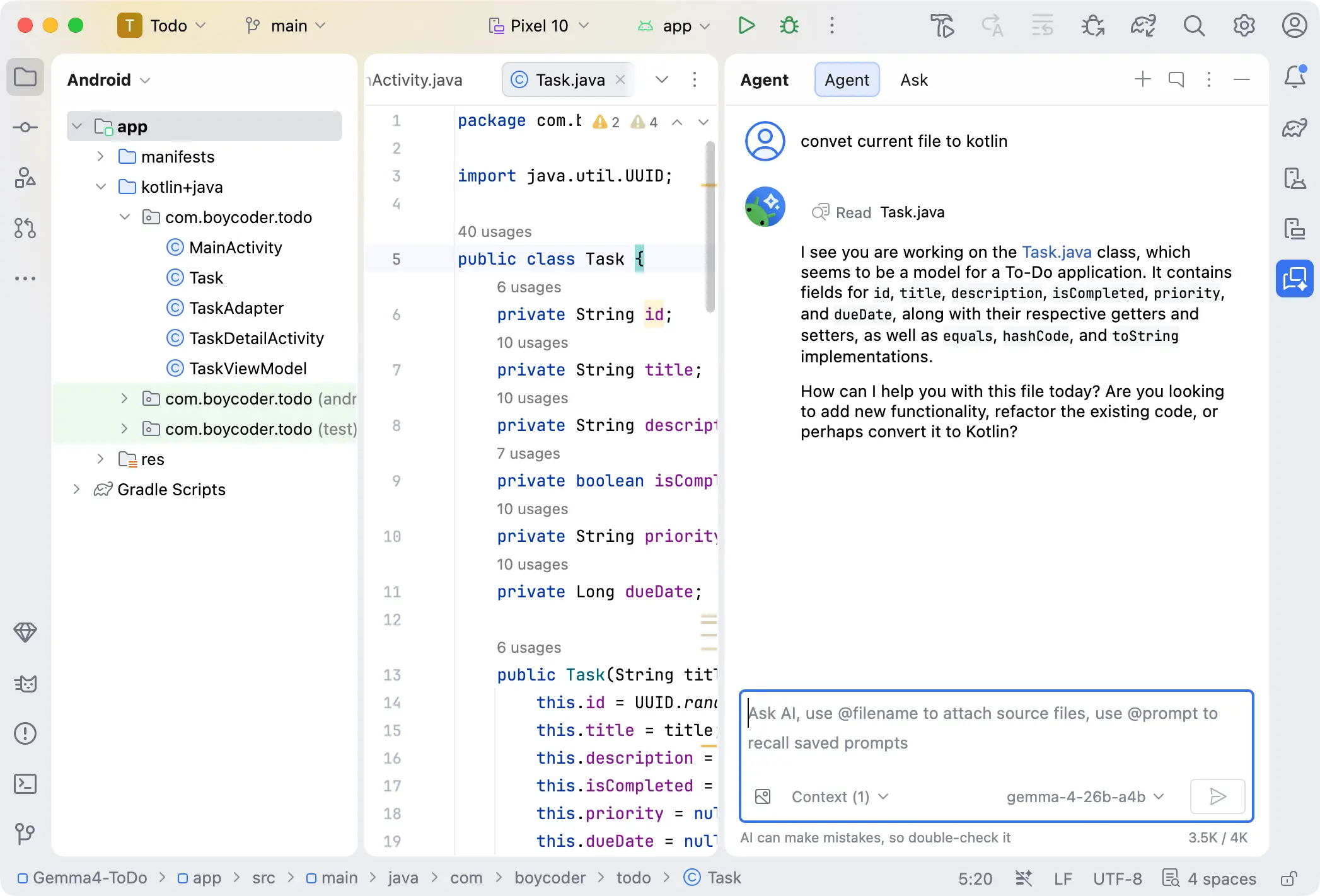
但是我实际测试的时候遇到了一些问题,Agent并没有按照我的要求去修改代码,而是直接把代码输出来了,需要我人工去复制粘贴,我尝试换了提示词,没有成功。但是现场看到有人使用时是正常工作的。
总的来说感觉这个模型目前还不成熟。如果以后成熟了,用这种本地模型去开发一些不那么复杂的代码还是可以的。
常用的一种思路就是用比较强的大模型去对项目的整体结构先做一个完整的规划,然后到具体的实现细节,再让相对弱一些但是性价比高的模型去实现。
下面是我实际运行的效果。
这篇文章就简单总结到这里,对这个活动感兴趣但是没机会参加的,可以参考一下。
如果觉得文章有帮助,欢迎分享转发,也欢迎关注我的公众号"搬砖的小明",及时获取更新