社交关系、推荐系统、知识图谱......只要你的业务涉及"关系",传统的数据库就会变得越来越慢、越来越复杂。今天,我们就用最通俗易懂的方式,把图数据库 Neo4j 彻底讲明白,让你以后处理"网状"数据时,思路清晰得像开了挂。
一、为什么你的SQL搞不定"朋友的朋友的朋友"?
想象一个简单的社交网络场景:你需要查询"当前用户的好友中,有哪些人也关注了当前用户喜欢的某个博主"。在关系型数据库(如MySQL)中,你可能需要这样写:
bash
SELECT DISTINCT u2.name
FROM users u1
JOIN follows f1 ON u1.id = f1.follower_id
JOIN users u2 ON f1.followee_id = u2.id
JOIN follows f2 ON u2.id = f2.follower_id
JOIN users u3 ON f2.followee_id = u3.id
JOIN likes l ON u3.id = l.user_id AND l.post_id = ?
WHERE u1.id = ?这张SQL不仅写起来痛苦,而且随着关系层数增加,JOIN的数量呈指数级增长,性能急剧下降。更严重的是,当你想要查询"用户和另一个用户之间有多少条路径"、"所有共同关注关系"这类问题时,SQL几乎无法优雅表达。
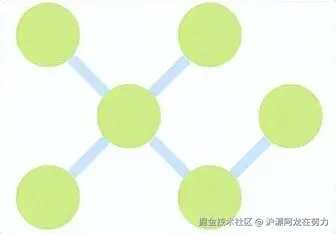
图数据库 正是为解决这类问题而生的。在Neo4j中,数据被存储为节点(Node)和关系(Relationship),关系本身就是一等公民,可以拥有属性和类型。查询"朋友的朋友"变得像描述句子一样自然:
bash
MATCH (me:User {id: 123})-[:FOLLOWS*2]->(friend_of_friend:User)
RETURN friend_of_friend.name*2 表示沿着 FOLLOWS 关系走两步。你甚至不需要关心底层有多少张表,Cypher查询引擎会自动高效地遍历图结构。这种直观性和性能优势,在处理深度关联数据时尤为突出。
二、Neo4j核心概念:节点、关系、路径、标签、属性
在深入学习之前,我们先彻底搞懂几个基础概念。这些概念就像盖房子的砖瓦,理解了它们,Cypher语言就变得自然而然。
2.1 节点(Node)
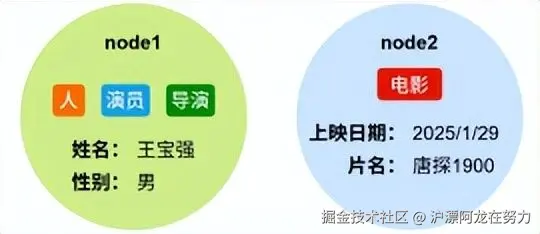
节点代表一个实体对象,比如一个人、一部电影、一个城市。每个节点可以:
-
拥有一个或多个标签(Label)
:标签相当于给节点分类,类似于SQL中的表名。例如 :Person、:Movie。一个节点可以同时有多个标签,比如 :Person:Actor 表示这是一个"人"同时也是"演员"。
-
拥有若干属性(Property)
:属性是键值对,存储具体信息。例如 {name: '王宝强', gender: '男'}。
在Cypher中,节点用一对圆括号表示,括号内可以写变量名、标签和属性:
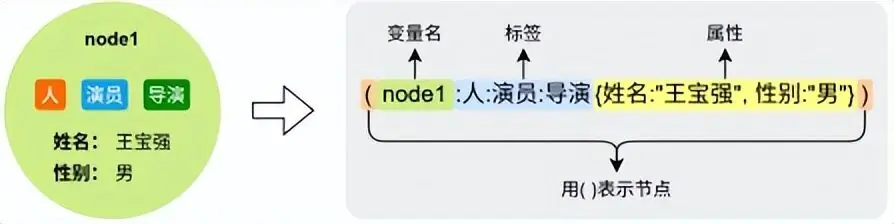
bash
// 一个没有变量名、没有标签、没有属性的匿名节点
()
// 有变量名的节点(变量名用于后续引用)
(p)
// 有标签的节点
(p:Person)
// 有多个标签的节点
(p:Person:Actor)
// 有属性的节点(属性用花括号包裹,键值对之间用逗号分隔)
(p:Person {name: '王宝强', gender: '男'})2.2 关系(Relationship)

关系用于连接两个节点,表示它们之间的某种联系,比如"王宝强出演了《唐探1900》"。每个关系:
-
必须有类型(Type)
:类型是一个大写标识符,例如 :ACTED_IN、:DIRECTED、:FOLLOWS。
-
可以有若干属性(Property)
:例如角色名 {role: '阿鬼'}、获奖标志 {award: true}。
-
有方向
:通常用箭头 → 表示方向,但查询时可以忽略方向。
在Cypher中,关系用方括号加箭头表示,放在两个节点之间:
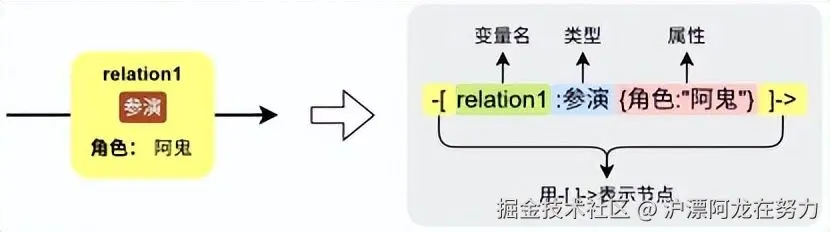
bash
// 基本关系模式:起始节点 - [关系] -> 目标节点
(p1:Person)-[:ACTED_IN]->(m:Movie)
// 关系也可以有变量名和属性
(p1:Person)-[r:ACTED_IN {role: '阿鬼'}]->(m:Movie)
// 无方向关系(用两个短横线,没有箭头)
(p1:Person)-[:FOLLOWS]-(p2:Person)2.3 路径(Path)
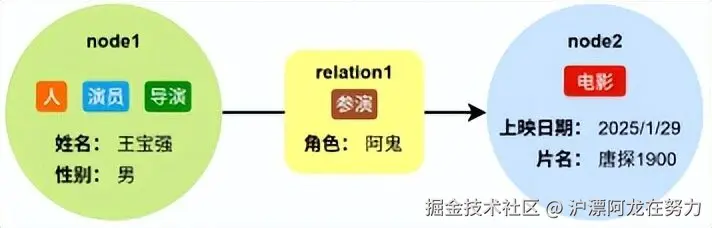
路径是由一系列节点和关系交替连接而成的结构,代表图中一条具体的行走路线。例如:(王宝强)-:ACTED_IN->(电影)<-:ACTED_IN-(刘德华) 表示"王宝强和刘德华演过同一部电影"。
路径在复杂查询中非常有用,我们可以把匹配到的整个路径赋值给一个变量,然后返回或进一步处理。
bash
// 将匹配到的路径存入变量 path 中
MATCH path = (p:Person {name: '王宝强'})-[:ACTED_IN]->(m:Movie)
RETURN path三、Windows下从零安装Neo4j(超详细)
我们选择自由度最高的 OS Deployment 方式,在 Windows 系统上部署 Neo4j 5.26 LTS 社区版。这种方式能让你完全掌控数据库的安装位置、配置文件和启动方式,非常适合学习和生产环境。
3.1 安装JDK 17
Neo4j 是用 Java 编写的,所以必须先安装 Java 运行环境。根据官方文档,Neo4j 5.26 需要 JDK 17 或 JDK 21。我们以 JDK 17 为例。
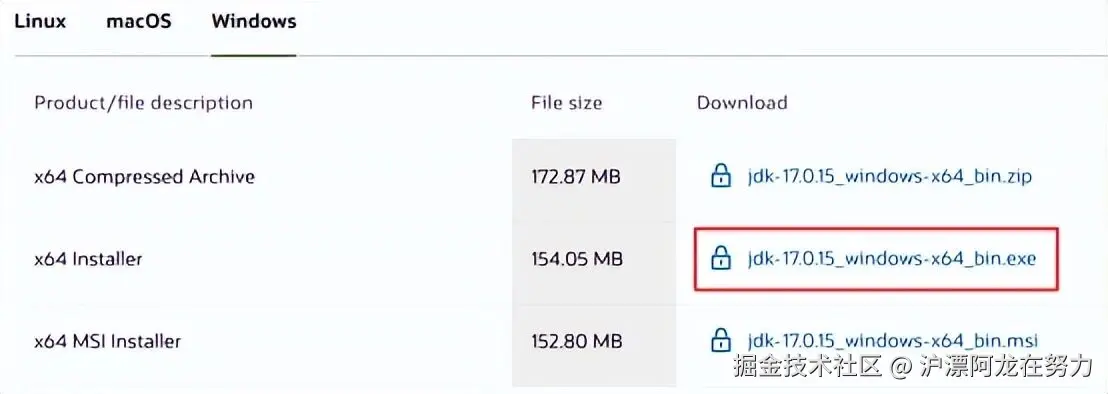
-
下载JDK
:访问 Oracle官网 下载 Windows x64 Installer(如 jdk-17.0.15_windows-x64_bin.exe)。如果你没有Oracle账号,也可以从其他镜像或课程资料中获取。
-
安装JDK
:双击安装包,一路"下一步",记住安装路径(例如 C:\Program Files\Java\jdk-17.0.15)。安装过程中可以取消"公共JRE"的选项,因为JDK自带JRE。
-
配置环境变量
(可选但推荐):
-
打开"系统属性" → "高级" → "环境变量"。
-
新建系统变量 JAVA_HOME,值为你的JDK安装路径(如 C:\Program Files\Java\jdk-17.0.15)。
-
在 Path 变量中添加 %JAVA_HOME%\bin。
-
验证安装
:打开命令提示符(cmd),输入:
-
cmd
-
java --version
-
如果看到类似 openjdk 17.0.15 2025-04-15 LTS 的输出,说明安装成功。
3.2 安装Neo4j社区版
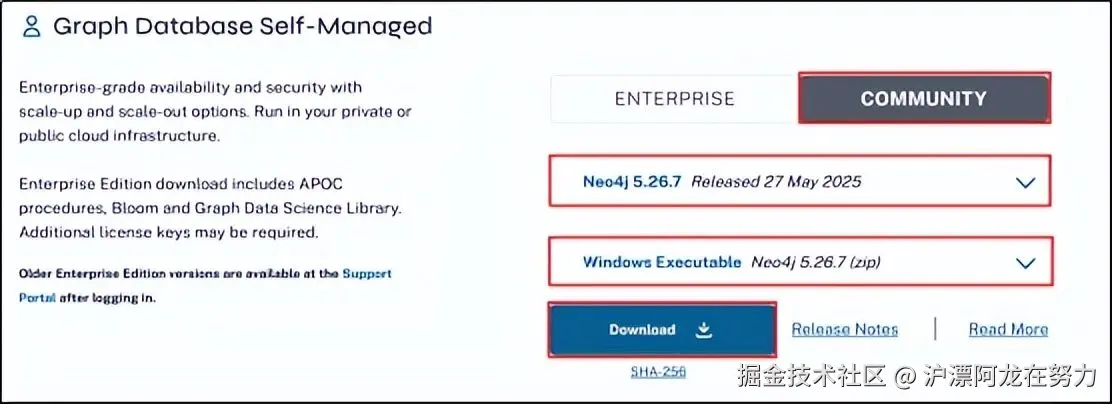
-
下载Neo4j
:访问 Neo4j下载中心,选择 Windows 平台的 zip 压缩包(例如 neo4j-community-5.26.0-windows.zip)。社区版完全免费,功能足够学习和小型项目使用。
-
解压
:将压缩包解压到一个没有中文和空格的目录,例如 D:\neo4j。解压后你会看到 bin、conf、data、logs 等文件夹。
-
配置环境变量
:
-
创建系统变量 NEO4J_HOME,值为 D:\neo4j(你的解压路径)。
-
在 Path 变量中添加 %NEO4J_HOME%\bin。
-
验证安装
:新开一个cmd窗口,输入:
-
cmd
-
neo4j --version
-
如果输出 neo4j version: 5.26.0,说明环境变量配置正确。
3.3 安装Neo4j为Windows服务(可选但推荐)
以管理员身份打开命令提示符(右键"命令提示符" → "以管理员身份运行")。执行以下命令将Neo4j注册为系统服务:
bash
neo4j windows-service install安装成功后,你可以在 services.msc 中看到名为 Neo4j Graph Database - neo4j 的服务,并设置为自动启动。
3.4 启动Neo4j数据库
bash
neo4j start启动日志会显示在控制台。如果一切正常,你会看到类似 Started neo4j 的信息。首次启动可能需要几秒钟来初始化数据库。
3.5 访问Web管理界面
Neo4j 提供了一个基于浏览器的可视化工具 ------ Neo4j Browser。打开浏览器,访问:
bash
http://localhost:7474/browser/你会看到一个连接界面。默认的服务器地址是 bolt://localhost:7687,用户名和密码都是 neo4j。首次登录时,系统会强制要求你修改密码。建议修改为容易记住但安全的密码,例如 Atguigu.123。
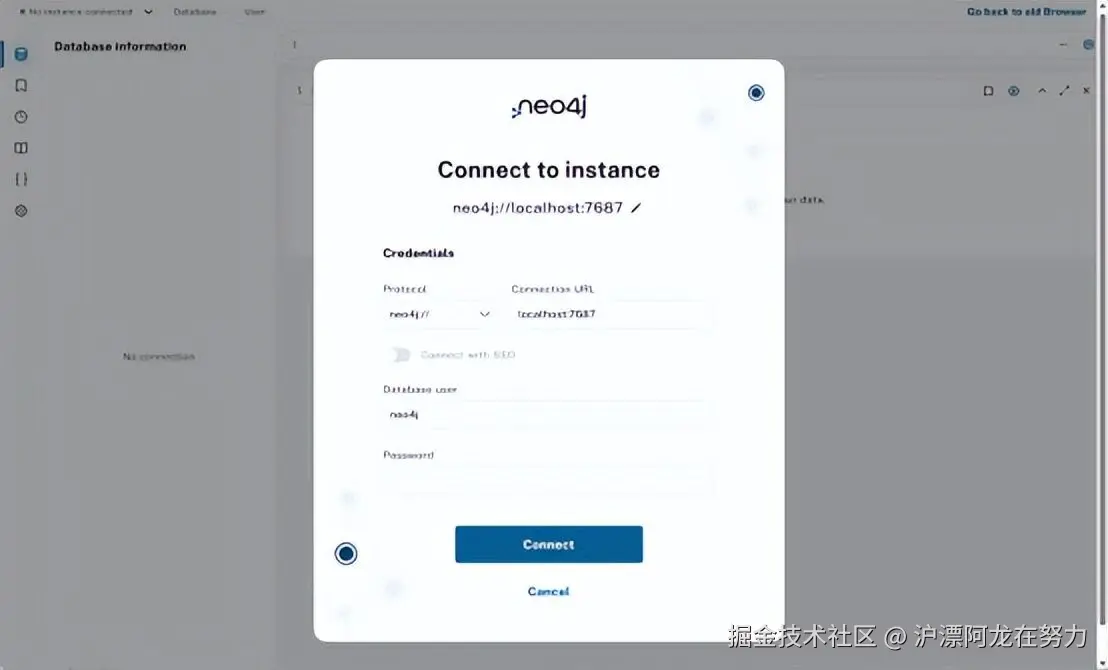
登录成功后,你就可以在输入框中执行Cypher查询了。试试输入 RETURN 'Hello Neo4j!' 然后点击运行按钮(或者按 Ctrl+Enter),应该能看到输出结果。
四、Cypher入门:像画画一样操作数据
Cypher 的设计哲学是"人类可读、易于表达"。它借鉴了SQL的关键词(如 MATCH、RETURN、WHERE),但图形模式的表示方式((节点)-关系->(节点))让查询语句几乎与手绘的草图一模一样。
4.1 创建节点 ------ CREATE
使用 CREATE 语句可以在数据库中插入新节点。我们先创建几个简单的节点,感受一下语法。
bash
// 创建一个没有任何标签和属性的空节点
CREATE ()
// 创建一个带标签的节点
CREATE (p:Person)
// 创建带属性和标签的节点(最常用)
CREATE (n1:Person:Actor {name: '王宝强', gender: '男'})
CREATE (n2:Movie {title: '唐探1900', released: '2025-01-29'})代码解释:
-
n1 和 n2 是变量名(可以任意取),仅在当前语句中有效,用于在后续引用这个节点。
-
Person:Actor 表示同时给节点加上 Person 和 Actor 两个标签,这相当于多分类。
-
属性用花括号包裹,键值对之间用逗号分隔。属性值可以是字符串、数字、布尔值、列表等。
执行上述语句后,数据库中就有了两个孤立的节点,它们之间还没有任何关系。
4.2 查询节点 ------ MATCH ... RETURN
MATCH 用于描述要查找的图形模式,RETURN 指定要返回哪些部分。
bash
// 查询所有节点(数据量大时非常慢,谨慎使用)
MATCH (n)
RETURN n
// 查询所有带有 Person 标签的节点,只返回名字和性别属性
MATCH (p:Person)
RETURN p.name, p.gender
// 按标签和属性精准查询
MATCH (p:Person {name: '王宝强'})
RETURN p注意:MATCH (n) 会扫描整个数据库的所有节点,如果数据量达到几十万条,浏览器可能会卡顿。通常我们会加上标签过滤。
4.3 创建关系 ------ 先匹配再创建
关系不能独立存在,必须连接两个节点。因此,创建关系的标准步骤是:先用 MATCH 找到两个节点,然后用 CREATE 在它们之间建立关系。
bash
// 1. 找到王宝强节点和《唐探1900》节点
MATCH (p:Person {name: '王宝强'}), (m:Movie {title: '唐探1900'})
// 2. 创建 ACTED_IN 关系,方向从 p 指向 m,并带上属性 role
CREATE (p)-[:ACTED_IN {role: '阿鬼'}]->(m)如果你希望关系也有变量名(以便后续返回或修改),可以这样写:
bash
MATCH (p:Person {name: '王宝强'}), (m:Movie {title: '唐探1900'})
CREATE (p)-[r:ACTED_IN {role: '阿鬼'}]->(m)
RETURN r关系方向的意义:虽然 ACTED_IN 关系在语义上是从演员指向电影,但在查询时你可以忽略方向,例如 (p)-:ACTED_IN-(m) 会匹配两个方向的关系。但创建时必须指定方向(除非是无向关系,但Cypher中创建关系必须有方向)。
4.4 查询关系
有了关系之后,我们就可以查询"王宝强演过哪些电影"了:
bash
MATCH (p:Person {name: '王宝强'})-[r:ACTED_IN]->(m:Movie)
RETURN m.title AS 电影名称, r.role AS 角色这条语句的含义:从Person节点出发,沿着ACTED_IN关系到达Movie节点,返回电影标题和关系上的角色属性。AS关键字用于给返回的列起别名(中文也可以,但建议用英文)。
4.5 一次创建完整路径
如果你确信某些节点和关系都不存在,可以用一条CREATE语句同时创建节点和关系,这叫做"创建路径"。
bash
CREATE
(n1:Person:Actor:Singer {name: '刘德华', gender: '男'})
-[:ACTED_IN {roles: ['刘建明']}]->
(m:Movie {title: '无间道', released: '2002-12-12'})这里我们创建了一个有3个标签的Person节点,然后直接通过-:ACTED_IN->连接到一个新创建的Movie节点。注意:如果节点或关系已经存在,再用CREATE会导致重复创建(会多出一个相同的节点)。因此,这种方式只适合从零开始导入数据时使用。日常开发中更推荐MERGE(后面会讲)。
五、Cypher进阶:修改、删除与合并(SET/REMOVE/MERGE)
5.1 修改属性 ------ SET
SET用于添加新属性、更新已有属性或添加新标签。
bash
// 为王宝强添加生日属性和 Singer 标签
MATCH (p:Person {name: '王宝强'})
SET p.birth = '1984-05-29', p:Singer
// 为关系添加属性
MATCH (p:Person {name: '王宝强'})-[r:ACTED_IN]->(m:Movie {title: '唐探1900'})
SET r.roles = ['阿鬼'], r.year = 2025一次SET可以同时设置多个属性,用逗号分隔。添加标签也使用:语法。
5.2 删除属性 ------ REMOVE
REMOVE用于删除属性或移除标签。
bash
// 删除关系上的 role 属性(假设之前有 role: '阿鬼',现在想改成数组形式)
MATCH (p:Person {name: '王宝强'})-[r:ACTED_IN]->(m:Movie {title: '唐探1900'})
REMOVE r.role
SET r.roles = ['阿鬼']
// 移除节点的 Singer 标签
MATCH (p:Person {name: '王宝强'})
REMOVE p:Singer5.3 删除节点和关系 ------ DELETE
删除操作需要特别注意:不能直接删除还有关联关系的节点,否则会报错。必须先删除关系,或者使用DETACH DELETE一次性删除节点及其所有关系。
bash
// 错误示范:如果节点还有关系,下面这条语句会失败
MATCH (p:Person {name: '王宝强'})
DELETE p // 报错:Node still has relationships
// 正确方式1:先删除关系,再删除节点
MATCH (p:Person {name: '王宝强'})-[r]-()
DELETE r, p
// 正确方式2:使用 DETACH DELETE(推荐,一步到位)
MATCH (p:Person {name: '王宝强'})
DETACH DELETE pDETACH DELETE 会自动删除该节点的所有关系,然后再删除节点本身,非常方便。
如果你只想删除关系而保留节点:
bash
MATCH (p:Person {name: '王宝强'})-[r:ACTED_IN]->(m:Movie {title: '唐探1900'})
DELETE r5.4 合并操作 ------ MERGE(避免重复)
MERGE 是 Cypher 中最实用的操作之一。它的行为是:如果模式(节点或关系)存在,就匹配它;如果不存在,就创建它。这相当于 MATCH + CREATE 的组合,并且是原子操作,非常适合数据导入时的去重。
合并节点:
bash
// 合并电影节点:若已存在《唐探1900》则匹配,否则创建
MERGE (m:Movie {title: '唐探1900', released: '2025-01-29'})
// 合并时还可以设置创建或匹配时的额外动作
MERGE (p:Person {name: '王宝强', gender: '男'})
ON CREATE SET p.create_time = datetime() // 仅在创建时设置创建时间
ON MATCH SET p.update_time = datetime() // 仅在匹配到时设置更新时间datetime() 是 Cypher 内置函数,返回当前时间戳(ISO 8601格式)。这样我们可以轻松追踪记录的新增和更新。
合并关系:
bash
MERGE (p:Person {name: '王宝强'})-[r:ACTED_IN {roles: ['阿鬼']}]->(m:Movie {title: '唐探1900'})注意:MERGE 关系时会先分别 MERGE 两个端点节点(确保它们存在),然后再处理关系。所以不需要提前 MATCH 节点。
六、实战数据集:构建"电影-人物"知识图谱(9人10部电影)
为了深入学习高级查询,我们需要一个相对丰富的数据集。下面我将提供一套完整的 Cypher 脚本,包含 9 位人物节点、10 部电影节点,以及导演(DIRECTED)、参演(ACTED_IN)、关注(FOLLOWS)三种关系。你可以按顺序在 Neo4j Browser 中执行。
6.1 清空旧数据(谨慎!会删除所有内容)
bash
MATCH (n) DETACH DELETE n;6.2 创建人物节点(9人)
bash
CREATE
(:Person {name: '张艺谋', birth: '1951-11-14'}),
(:Person {name: '陈凯歌', birth: '1952-08-12'}),
(:Person {name: '巩俐', birth: '1965-12-31'}),
(:Person {name: '葛优', birth: '1957-04-19'}),
(:Person {name: '章子怡', birth: '1979-02-09'}),
(:Person {name: '刘德华', birth: '1961-09-27'}),
(:Person {name: '吴京', birth: '1974-04-03'}),
(:Person {name: '贾玲', birth: '1982-04-29'}),
(:Person {name: '郭帆', birth: '1980-12-15'})6.3 创建电影节点(10部)
bash
CREATE
(:Movie {title: '红高粱', year: 1987, rating: 8.4, genre: ['文艺', '历史']}),
(:Movie {title: '活着', year: 1994, rating: 9.2, genre: ['剧情', '历史']}),
(:Movie {title: '霸王别姬', year: 1993, rating: 9.6, genre: ['剧情', '爱情']}),
(:Movie {title: '英雄', year: 2002, rating: 7.5, genre: ['动作', '武侠']}),
(:Movie {title: '无间道', year: 2002, rating: 9.1, genre: ['犯罪', '悬疑']}),
(:Movie {title: '一代宗师', year: 2013, rating: 8.0, genre: ['动作', '传记']}),
(:Movie {title: '流浪地球', year: 2019, rating: 8.5, genre: ['科幻', '灾难']}),
(:Movie {title: '战狼2', year: 2017, rating: 7.1, genre: ['动作', '军事']}),
(:Movie {title: '你好,李焕英', year: 2021, rating: 7.7, genre: ['喜剧', '家庭']}),
(:Movie {title: '满江红', year: 2023, rating: 7.2, genre: ['悬疑', '历史']})6.4 创建导演关系(DIRECTED)
注意:这里需要先用 MATCH 找到具体的节点变量,然后创建关系。为了简洁,我列出所有9条导演关系。
bash
MATCH (zhang:Person {name: '张艺谋'}), (m1:Movie {title: '红高粱'}),
(m2:Movie {title: '活着'}), (m3:Movie {title: '霸王别姬'}),
(m4:Movie {title: '英雄'}), (m5:Movie {title: '满江红'})
CREATE
(zhang)-[:DIRECTED {award: true}]->(m1),
(zhang)-[:DIRECTED {award: true}]->(m2),
(zhang)-[:DIRECTED {award: false}]->(m3),
(zhang)-[:DIRECTED {award: false}]->(m4),
(zhang)-[:DIRECTED {award: false}]->(m5);
MATCH (chen:Person {name: '陈凯歌'}), (m:Movie {title: '霸王别姬'})
CREATE (chen)-[:DIRECTED {award: true}]->(m);
MATCH (liu:Person {name: '刘德华'}), (m:Movie {title: '无间道'})
CREATE (liu)-[:DIRECTED {award: false}]->(m);
MATCH (wu:Person {name: '吴京'}), (m:Movie {title: '战狼2'})
CREATE (wu)-[:DIRECTED {award: false}]->(m);
MATCH (jia:Person {name: '贾玲'}), (m:Movie {title: '你好,李焕英'})
CREATE (jia)-[:DIRECTED {award: true}]->(m);
MATCH (guo:Person {name: '郭帆'}), (m:Movie {title: '流浪地球'})
CREATE (guo)-[:DIRECTED {award: true}]->(m);注意:有些电影(如《一代宗师》)没有导演关系,这没关系。
6.5 创建参演关系(ACTED_IN)
共11条参演关系,覆盖大部分主要演员和电影。
bash
MATCH (gong:Person {name: '巩俐'}), (m1:Movie {title: '红高粱'}),
(m2:Movie {title: '活着'}), (m3:Movie {title: '霸王别姬'})
CREATE
(gong)-[:ACTED_IN {role: '九儿', award: true}]->(m1),
(gong)-[:ACTED_IN {role: '家珍', award: false}]->(m2),
(gong)-[:ACTED_IN {role: '菊仙', award: false}]->(m3);
MATCH (ge:Person {name: '葛优'}), (m2:Movie {title: '活着'}), (m3:Movie {title: '霸王别姬'})
CREATE
(ge)-[:ACTED_IN {role: '福贵', award: true}]->(m2),
(ge)-[:ACTED_IN {role: '袁四爷', award: false}]->(m3);
MATCH (zhangyi:Person {name: '章子怡'}), (m4:Movie {title: '英雄'}), (m6:Movie {title: '一代宗师'})
CREATE
(zhangyi)-[:ACTED_IN {role: '如月', award: false}]->(m4),
(zhangyi)-[:ACTED_IN {role: '宫二', award: true}]->(m6);
MATCH (liu:Person {name: '刘德华'}), (m5:Movie {title: '无间道'})
CREATE (liu)-[:ACTED_IN {role: '刘建明', award: false}]->(m5);
MATCH (wu:Person {name: '吴京'}), (m7:Movie {title: '流浪地球'}), (m8:Movie {title: '战狼2'})
CREATE
(wu)-[:ACTED_IN {role: '刘培强', award: true}]->(m7),
(wu)-[:ACTED_IN {role: '冷锋', award: true}]->(m8);
MATCH (zhang:Person {name: '张艺谋'}), (m10:Movie {title: '满江红'})
CREATE (zhang)-[:ACTED_IN {role: '秦桧', award: false}]->(m10);
MATCH (jia:Person {name: '贾玲'}), (m9:Movie {title: '你好,李焕英'})
CREATE (jia)-[:ACTED_IN {role: '贾晓玲', award: true}]->(m9);6.6 创建关注关系(FOLLOWS)
共11条关注关系,模拟社交网络中的"关注"行为。
bash
MATCH (gong:Person {name:'巩俐'}), (zhang:Person {name:'张艺谋'}),
(zhangyi:Person {name:'章子怡'}), (chen:Person {name:'陈凯歌'}),
(ge:Person {name:'葛优'}), (liu:Person {name:'刘德华'}),
(wu:Person {name:'吴京'}), (jia:Person {name:'贾玲'}),
(guo:Person {name:'郭帆'})
CREATE
(gong)-[:FOLLOWS]->(zhang),
(zhangyi)-[:FOLLOWS]->(zhang),
(zhang)-[:FOLLOWS]->(chen),
(ge)-[:FOLLOWS]->(chen),
(liu)-[:FOLLOWS]->(zhang),
(gong)-[:FOLLOWS]->(zhangyi),
(wu)-[:FOLLOWS]->(zhang),
(jia)-[:FOLLOWS]->(zhang),
(guo)-[:FOLLOWS]->(zhang),
(liu)-[:FOLLOWS]->(wu),
(zhang)-[:FOLLOWS]->(guo);至此,我们的知识图谱构建完成。你可以执行一些简单查询来验证,例如:
bash
// 查看所有节点和关系(可视化)
MATCH (n) RETURN n LIMIT 25七、高级查询必备技能:过滤、排序、分页、聚合
有了扎实的数据集,我们就可以开始玩真正的图查询了。这些技巧在日常开发中几乎每天都会用到。
7.1 过滤 ------ WHERE
WHERE 子句用于对 MATCH 的结果进行条件筛选。它可以写在 MATCH 后面,也可以紧跟在 MATCH 的节点模式内部(用花括号)。但推荐使用独立的 WHERE,因为更灵活。
基本比较运算符:=、<>、<、<=、>、>=
bash
// 查询出生在1970年之后的人物
MATCH (p:Person)
WHERE p.birth > '1970-01-01'
RETURN p.name, p.birth多条件组合:AND、OR、NOT
bash
// 查询评分高于8分且年份早于2000年的电影
MATCH (m:Movie)
WHERE m.rating > 8.0 AND m.year < 2000
RETURN m.title, m.year, m.rating集合包含:IN
bash
// 查找类型包含"历史"的电影
MATCH (m:Movie)
WHERE '历史' IN m.genre
RETURN m.title, m.genre字符串匹配:CONTAINS、STARTS WITH、ENDS WITH
bash
// 查询名字中包含"张"的人物
MATCH (p:Person)
WHERE p.name CONTAINS '张'
RETURN p.name
// 查询以"流浪"开头的电影
MATCH (m:Movie)
WHERE m.title STARTS WITH '流浪'
RETURN m.title空值判断:IS NULL、IS NOT NULL
bash
// 找出没有出生日期的人物(假设有缺失数据)
MATCH (p:Person)
WHERE p.birth IS NULL
RETURN p.name7.2 排序 ------ ORDER BY
ORDER BY 用于对返回结果进行排序,默认升序(ASC),可以指定 DESC 降序。
bash
// 按电影评分从高到低排序,并取前5名
MATCH (m:Movie)
RETURN m.title, m.rating
ORDER BY m.rating DESC
LIMIT 57.3 分页 ------ SKIP 和 LIMIT
SKIP 跳过前 n 条记录,LIMIT 限制最多返回 n 条记录。两者结合实现分页。
bash
// 第二页:跳过前5条,返回第6-10条(按年份降序)
MATCH (m:Movie)
RETURN m.title, m.year
ORDER BY m.year DESC
SKIP 5
LIMIT 57.4 聚合函数 ------ count、avg、max、min、collect
Cypher 的聚合不需要显式 GROUP BY,只要 RETURN 中同时包含聚合函数和非聚合字段,非聚合字段就会自动成为分组键。
数值聚合:
bash
// 统计演员总数(去重)
MATCH (p:Person)-[:ACTED_IN]->()
RETURN count(DISTINCT p) AS 演员人数
// 每位演员参演了几部电影
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
RETURN p.name, count(m) AS 参演电影数列表聚合:collect() 将多个值聚合成一个列表。
bash
// 每位导演的作品名称列表
MATCH (p:Person)-[:DIRECTED]->(m:Movie)
RETURN p.name, collect(m.title) AS 导演作品输出示例:
张艺谋 | '红高粱', '活着', '霸王别姬', '英雄', '满江红'
其他聚合:avg() 平均值、sum() 总和、max() 最大值、min() 最小值。
bash
// 计算所有电影的平均评分
MATCH (m:Movie)
RETURN avg(m.rating) AS 平均分, max(m.rating) AS 最高分, min(m.rating) AS 最低分八、联合查询与子查询:让查询能力再升级
8.1 联合查询 ------ UNION 和 UNION ALL
当需要将多个查询的结果合并成一个结果集时,使用 UNION(去重)或 UNION ALL(保留重复)。注意每个子查询的返回字段数量和类型必须一致。
bash
// 查询张艺谋作为导演和作为演员的电影(分别标注角色)
MATCH (p:Person {name:'张艺谋'})-[:DIRECTED]->(m:Movie)
RETURN m.title AS 电影名称, '导演' AS 身份
UNION
MATCH (p:Person {name:'张艺谋'})-[:ACTED_IN]->(m:Movie)
RETURN m.title AS 电影名称, '演员' AS 身份结果中会包含张艺谋导演的5部电影和参演的1部电影(《满江红》),并且不会重复(这里本来就没有重复)。
8.2 子查询 ------ CALL {}
子查询允许在一个查询中对每一行输入执行一个独立的查询块,并返回结果。子查询用 CALL (变量) { ... } 包裹,变量是传递给子查询的参数。
经典应用:为每个分组取Top N。例如,找出每位导演评分最高的电影。
bash
MATCH (p:Person)-[:DIRECTED]->()
WITH DISTINCT p // 去重,防止同一个导演被执行多次
CALL (p) {
MATCH (p)-[:DIRECTED]->(m:Movie)
RETURN m.title AS title, m.rating AS rating
ORDER BY rating DESC
LIMIT 1
}
RETURN p.name AS 导演, title AS 最高评分作品, rating AS 评分执行流程:
-
MATCH (p:Person)-:DIRECTED->() 找到所有有导演关系的人,可能有重复(一个导演多部电影)。
-
WITH DISTINCT p 将导演去重,得到唯一的导演列表。
-
对每个导演 p,执行子查询:查找该导演的所有电影,按评分排序,取第一条(最高分)。
-
将子查询返回的 title 和 rating 与导演姓名一起输出。
WITH 的作用:WITH 是 Cypher 中用于在查询阶段之间传递结果的语句,类似于 RETURN 但不会结束查询。它常用来对中间结果进行聚合、排序、去重,然后传递给后续部分。
九、路径模式匹配:挖掘深层关系(变长路径、无向关系)
路径模式匹配是图数据库的核心优势。Cypher 提供了强大的语法来描述任意长度的路径。
9.1 变长路径 ------*minHops..maxHops
bash
// 语法:()-[*N]->() 表示恰好 N 跳
// ()-[*min..max]->() 表示 min 到 max 跳
// ()-[*min..]->() 表示至少 min 跳
// ()-[*..max]->() 表示最多 max 跳
// 示例:查询张艺谋的粉丝的粉丝(2跳关注)
MATCH path = (a:Person)-[:FOLLOWS*2]->(b:Person {name:'张艺谋'})
RETURN path
// 示例:查询张艺谋与任何人的1到3跳关注路径(可能包括他自己)
MATCH path = (zhang:Person {name:'张艺谋'})-[:FOLLOWS*1..3]-(other:Person)
RETURN path注意:变长路径可能会产生大量结果,尤其是在社交网络中,2跳可能就有成百上千条路径。建议总是加上 LIMIT 或在查询中限制最大跳数。
9.2 无向关系匹配
如果你不关心关系方向,可以使用两个短横线 - 代替箭头。
bash
// 查询与巩俐合作过的所有演员(通过电影连接)
// 合作意味着:巩俐-参演->电影<-参演-其他演员
MATCH (gong:Person {name:'巩俐'})-[:ACTED_IN]-(m:Movie)-[:ACTED_IN]-(other:Person)
RETURN DISTINCT other.name这里 (gong)-:ACTED_IN-(m) 匹配两个方向:巩俐→电影 或 电影→巩俐,但因为在我们的模型中关系方向总是从人到电影,所以实际上只会匹配到巩俐→电影。而 (m)-:ACTED_IN-(other) 匹配电影→其他演员,因为关系方向是从演员到电影,所以这里匹配的是反向,但无向关系允许这种匹配。最终结果就是所有和巩俐演过同一部电影的人。
9.3 最短路径与所有路径
Neo4j 还提供了内置函数来查找最短路径和所有路径,这在社交网络分析中非常有用。
bash
// 查找两个节点之间的最短路径(不考虑权重)
MATCH p = shortestPath((a:Person {name:'巩俐'})-[:ACTED_IN|FOLLOWS*]-(b:Person {name:'郭帆'}))
RETURN p
// 查找所有路径(可能爆炸,谨慎使用)
MATCH p = allShortestPaths((a:Person {name:'巩俐'})-[:ACTED_IN|FOLLOWS*]-(b:Person {name:'郭帆'}))
RETURN pshortestPath 和 allShortestPaths 函数要求路径模式中的关系类型可以指定多种(用竖线 | 分隔),并且变长路径不能指定具体长度(用 * 表示任意长度)。
十、保证数据质量:唯一性约束详解
在生产环境中,我们需要防止重复数据的写入。Neo4j 提供了唯一性约束(社区版只支持这一种约束),可以确保某个属性在特定标签的所有节点中唯一。
10.1 创建唯一性约束
bash
// 为 User 节点的 userId 属性创建唯一约束
CREATE CONSTRAINT unique_user_id FOR (u:User) REQUIRE u.userId IS UNIQUE;
// 复合唯一约束(多个属性的组合唯一)
CREATE CONSTRAINT unique_user_name_email FOR (u:User) REQUIRE (u.firstName, u.email) IS UNIQUE;10.2 测试约束效果
bash
// 正常插入两个不同 userId 的用户
CREATE (u1:User {userId: 'u001', name: 'Alice'});
CREATE (u2:User {userId: 'u002', name: 'Bob'});
// 尝试插入重复 userId
CREATE (u3:User {userId: 'u001', name: 'Charlie'});执行第三条语句时,Neo4j 会抛出错误:
bash
Neo.ClientError.Schema.ConstraintValidationFailed
Node(0) already exists with label `User` and property `userId` = 'u001'10.3 查看和删除约束
bash
SHOW CONSTRAINTS; // 列出所有约束
DROP CONSTRAINT unique_user_id; // 删除指定约束注意:唯一性约束的创建需要数据库中已有数据不违反该约束。如果已经存在重复值,创建会失败。
十一、实战应用:用 Python 连接 Neo4j 执行查询
在实际项目中,我们不可能一直在浏览器里手敲 Cypher,而是通过应用程序(Python、Java、JavaScript等)驱动来操作数据库。下面以 Python 为例,演示如何连接 Neo4j 并执行参数化查询。
11.1 安装 Neo4j Python 驱动
bash
pip install neo4j11.2 编写示例代码
bash
from neo4j import GraphDatabase
# 数据库连接配置
URI = "neo4j://localhost:7687" # Bolt 协议地址
AUTH = ("neo4j", "Atguigu.123") # 用户名和密码(改为你自己的)
# 使用 with 语句自动管理连接生命周期
with GraphDatabase.driver(URI, auth=AUTH) as driver:
# execute_query 是官方推荐的高层API(Neo4j 5.x 引入)
# 它自动处理会话和事务,返回结果记录、执行摘要和键名列表
records, summary, keys = driver.execute_query(
"""
// 查询指定导演在某个年份之后执导的电影
MATCH (p:Person {name: $director_name})-[r:DIRECTED]->(m:Movie)
WHERE m.year > $min_year
RETURN p.name AS director, m.year AS year, m.title AS movie
ORDER BY m.year DESC
""",
# 参数化查询,防止 Cypher 注入,同时提高缓存命中率
parameters_={"director_name": "张艺谋", "min_year": 1990},
database_="neo4j" # 指定要操作的数据库(Neo4j 4.0 后支持多数据库)
)
# 打印执行摘要信息(可选)
print(f"查询耗时: {summary.result_available_after} ms")
print(f"返回记录数: {len(records)}")
print("-" * 50)
# 遍历结果记录
for record in records:
# record 类似于一个字典,可以通过键名或索引访问
director = record["director"]
year = record["year"]
movie = record["movie"]
print(f"导演:{director} | 年份:{year} | 电影:{movie}")代码解释:
-
driver.execute_query 是 Neo4j 5.x 引入的便捷方法,内部封装了会话(Session)和事务(Transaction)的创建与关闭。你只需要提供查询语句和参数即可。
-
查询中使用 directorname和min_year 作为占位符,实际值通过 parameters_ 字典传入。这样做不仅安全(防止注入),还能让数据库缓存执行计划,提升性能。
-
返回值 records 是一个列表,每个元素是 Record 对象,支持字典式访问(record"director")和属性式访问(record.director)。
-
summary 包含了查询的元数据,如执行时间、命中记录数、是否更新了数据等。
11.3 执行写入操作
bash
# 创建新节点和关系
records, summary, keys = driver.execute_query(
"""
MERGE (p:Person {name: $name, birth: $birth})
ON CREATE SET p.created = datetime()
RETURN p.name AS name, p.created AS created
""",
parameters_={"name": "雷军", "birth": "1969-12-16"},
database_="neo4j"
)
print(f"创建了用户: {records[0]['name']}")11.4 批量操作与事务
如果需要执行多个写入操作并保证原子性,可以使用 execute_query 的多语句模式(用分号分隔),或者显式开启事务:
bash
with driver.session(database="neo4j") as session:
with session.begin_transaction() as tx:
tx.run("CREATE (n:Person {name: '测试1'})")
tx.run("CREATE (n:Person {name: '测试2'})")
tx.commit() # 提交事务,如果中途出错则自动回滚但大多数情况下,execute_query 已经足够好用,并且会自动重试等。
十二、总结与进阶路线
恭喜你!你已经系统性地掌握了 Neo4j 图数据库的核心知识。从安装配置到 Cypher 语言基础,再到高级查询、约束和 Python 集成,你现在已经具备构建真实图数据应用的能力。
核心回顾
-
图数据库优势
:处理深度关联关系时,性能远超关系型数据库,查询写法直观。
-
Cypher 本质
:描述图模式 (节点)-关系->(节点),就像在画图。
-
增删改查
:CREATE、MATCH、SET、DELETE,配合 MERGE 实现幂等操作。
-
高级查询
:WHERE 过滤、ORDER BY 排序、SKIP/LIMIT 分页、聚合函数、UNION 和子查询。
-
路径匹配
:变长路径 *2、无向关系 -,以及 shortestPath 函数。
-
约束
:唯一性约束保证数据质量。
-
编程集成
:Python 驱动 + 参数化查询,安全高效。
图数据库的世界非常迷人,尤其是当你需要从"关系"中发现洞见时,Neo4j 会让你事半功倍。如果你在实践中遇到任何问题,欢迎查阅 Neo4j 官方文档 或社区论坛。现在,就去创建你自己的第一个图吧!