Graphiti:构建智能记忆系统的完整指南
Graphiti是一个强大的知识图谱构建框架,专为大模型应用提供结构化记忆能力。本文将详细介绍如何快速上手Graphiti,构建属于自己的智能记忆系统。
什么是Graphiti?
Graphiti 是一款面向智能体应用的时序知识图谱 开源框架,由 Zep 团队推出,主打动态时序感知的知识图谱构建与检索,弥补了传统 GraphRAG 仅适配静态文档的短板。
Graphiti 以三元组(实体 - 关系 - 实体) 为基础构建知识网络,区别于普通知识图谱,天然搭载双时序追踪能力,记录关系生命周期与数据变更历史,完整留存上下文演变过程。
核心优势
- 时序能力:精准记录事实、关系随时间的变化,支持时间点回溯查询,自动处理信息矛盾与旧关系失效;
- 增量处理:以独立片段形式增量摄入数据,保留数据溯源,支持持续更新;
- 混合检索:融合语义向量检索 + BM25 全文检索 + 图结构检索,结合节点距离重排,检索效率更高;
- 高适配拓展:支持自定义领域实体类型,兼容非结构化文本、结构化 JSON 多类数据源;
- 高性能可扩展:大模型调用并行化优化,保障时序不乱序,查询毫秒级响应,适配大数据场景。
与 GraphRAG 核心差异
- GraphRAG:聚焦静态文档、批量处理、依赖大模型摘要,无完善时序能力,延迟高;
- Graphiti:面向动态业务数据、持续增量更新、混合检索架构,原生时序管理,低延迟、可定制性强。
快速开始
1. 安装和配置Neo4j数据库
方案A:Neo4j Desktop
- 下载并安装Neo4j Desktop
- 创建新的数据库项目
- 设置数据库密码(默认用户名为
neo4j) - 确保数据库运行在默认端口
7687上
方案B:Docker部署(适合生产环境)
css
docker run -d \
--name neo4j \
-p 7474:7474 -p 7687:7687 \
-e NEO4J_AUTH=neo4j/your_password \
neo4j:5.26.02. 配置LLM客户端
Graphiti支持多种大模型提供商,推荐使用OpenAI兼容格式。
ini
import os
from graphiti_core.llm_client.config import LLMConfig
# 配置LLM客户端
llm_config = LLMConfig(
api_key=os.getenv("DASHSCOPE_API_KEY"), # 阿里云通义千问API密钥
model="qwen-plus", # 主力模型,用于复杂推理任务
small_model="qwen-flash", # 轻量级模型,用于简单任务
base_url=os.getenv("DASH_SCOPE_BASE_URL"), # API基础URL
)3. 创建Graphiti实例
完整的Graphiti实例配置包含以下几个核心组件:
ini
from graphiti_core import Graphiti
from graphiti_core.llm_client.openai_client import OpenAIGenericClient
from graphiti_core.embedder.openai_embedder import OpenAIEmbedder, OpenAIEmbedderConfig
from graphiti_core.reranker.openai_reranker import OpenAIRerankerClient
# 创建Graphiti实例
graphiti = Graphiti(
"bolt://localhost:7687",
"neo4j",
"password",
llm_client=OpenAIGenericClient(config=llm_config),
embedder=OpenAIEmbedder(
config=OpenAIEmbedderConfig(
api_key=os.getenv("DASHSCOPE_API_KEY"),
embedding_model="text-embedding-v4", # e.g., "mistral-embed"
base_url=os.getenv("DASH_SCOPE_BASE_URL"),
)
),
config=LLMConfig(
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="qwen-flash",
base_url=os.getenv("DASH_SCOPE_BASE_URL"),
)
)
) 核心组件说明:
- LLM Client:处理复杂的自然语言理解和生成任务
- Embedder:将文本转换为高维向量,用于相似度计算
- Cross Encoder:对搜索结果进行重排序,提高相关性。注意,这个地方不是重排模型qwen3-rerank,而是一个小模型用于重排。(而且Qwen的重排模型不支持OpenAI兼容格式)
4. 初始化索引和约束
首次运行Graphiti时,需要初始化数据库索引和约束,以优化查询性能和保证数据完整性:
python
# 异步初始化索引和约束
await graphiti.build_indices_and_constraints()
print("✅ 索引初始化完成")这个步骤会:
- 创建必要的数据库索引,加速查询操作
- 设置数据约束,确保数据一致性
- 初始化图数据库schema
5. 准备数据
Graphiti支持多种数据格式,包括纯文本和JSON结构化数据。
ini
episodes = [
# 文本类型数据:自然语言描述
{
'content': '王小清是北京市司法局局长。她此前曾任北京市朝阳区人民法院院长。',
'type': EpisodeType.text,
'description': '播客文字稿',
},
{
'content': '担任司法局局长期间,王小清的任期为2011年1月3日至2017年1月3日。',
'type': EpisodeType.text,
'description': '播客文字稿',
},
# JSON类型数据:结构化信息
{
'content': {
'name': '李明远',
'position': '省长',
'state': '广东省',
'previous_role': '副省长',
'previous_location': '深圳市',
},
'type': EpisodeType.json,
'description': '播客元数据',
},
{
'content': {
'name': '李明远',
'position': '省长',
'term_start': '2019年1月7日',
'term_end': '至今',
},
'type': EpisodeType.json,
'description': '播客元数据',
},
]数据类型说明:
- EpisodeType.text:纯文本内容,Graphiti会自动提取实体和关系
- EpisodeType.json:结构化数据,Graphiti会直接解析JSON结构
6. 批量添加数据
使用异步方式批量添加数据到知识图谱中:
python
async def add_episodes_batch():
"""批量添加剧集数据到Graphiti"""
for i, episode in enumerate(episodes):
# 处理不同类型的内容格式
if isinstance(episode['content'], str):
episode_body = episode['content']
else:
episode_body = json.dumps(episode['content'], ensure_ascii=False)
# 添加剧集到知识图谱
await graphiti.add_episode(
name=f'财经大讲堂 {i}', # 剧集名称
episode_body=episode_body, # 内容主体
source=episode['type'], # 内容类型
source_description=episode['description'], # 来源描述
reference_time=datetime.now(timezone.utc), # 时间戳
)
print(f'✅ 已添加剧集:财经大讲堂 {i} ({episode["type"].value})')
# 执行批量添加
await add_episodes_batch()关键参数说明:
- name:剧集的唯一标识符
- episode_body:实际内容,支持文本或JSON格式
- source:内容类型(text/json)
- source_description:人类可读的描述信息
- reference_time :内容的时间戳,用于时间相关的查询
核心概念
添加事件(Episodes)
每一个事件在图数据库中都是一个单独的节点,每添加一个事件Graphiti会自动识别相关的事件并通过 MENTIONS 与之关联。
三种 Episode 类型
- text:非结构化文本数据
ini
await graphiti.add_episode(
# 命名:简洁、唯一、贴合知识主题(Graphiti核心标识)
name="气候预测系统AI_ClimateNet研发突破",
# 图记忆核心:只保留**关键事实**,精简冗余描述,适配知识图谱存储
episode_body=(
"麻省理工学院(MIT)研究人员发布AI系统ClimateNet,"
"可高精度预测气候模式;该系统能提前3周预警重大气象事件,"
"可大幅提升灾害应急响应能力与农业规划效率。"
),
source=EpisodeType.text,
# 中文源描述,简洁明确
source_description="科技杂志文章",
# 保留原时间戳(知识事件的时间锚点)
reference_time=datetime(2023, 11, 15, 9, 30),
)- message:对话格式的消息,每条对话必须是"speaker:message"的格式
ini
await graphiti.add_episode(
name="客户支持对话_01",
episode_body=(
"用户:你好,我的Allbirds鞋子出现质量问题,仅使用两个月就出现鞋底开胶脱落的情况。"
"客服:非常抱歉给你带来不好的体验,麻烦提供一下你的订单编号。"
),
source=EpisodeType.message,
source_description="线上客服聊天记录",
reference_time=datetime(2024, 3, 15, 14, 45),
)- json:结构化文本,Graphiti 可直接解析产品属性、实体关系。
python
product_data = {
"产品ID": "PROD001",
"产品名称": "男士超轻羊毛跑鞋",
"主体颜色": "深灰色",
"鞋底颜色": "中灰色",
"核心材质": "羊毛",
"专属科技": "超轻发泡材质",
"销售价格": 125.00,
"库存状态": True,
"最后更新时间": "2024-03-15T10:30:00Z"
}
# 存入Graphiti图记忆(结构化字典原生支持,解析效率最高)
await graphiti.add_episode(
name="产品信息更新_PROD001", # 中文命名+唯一ID,便于检索
episode_body=product_data, # 直接传递字典,Graphiti最优格式
source=EpisodeType.json,
source_description="Allbirds产品目录更新",
reference_time=datetime.now(),
)Graphiti 支持使用 add_episode_bulk 批量添加Episode。
ini
product_data = [
{
"产品ID": "PROD001",
"产品名称": "男士超轻羊毛跑鞋",
"主体颜色": "深灰色",
"鞋底颜色": "中灰色",
"材质": "羊毛",
"核心科技": "超轻发泡中底",
"价格": 125.00,
"库存状态": True, # 修正Python语法:True 首字母大写
"最后更新时间": "2024-03-15T10:30:00Z"
},
......
]
# 批量生成Graphiti episodes(高性能批量导入)
bulk_episodes = [
RawEpisode(
# 中文命名规则:唯一、可检索、适配图谱索引
name=f"产品信息更新_{product['产品ID']}",
# 结构化JSON数据,Graphiti最优解析格式
content=json.dumps(product, ensure_ascii=False), # ensure_ascii=False 保留中文
source=EpisodeType.json,
source_description="Allbirds产品目录批量更新",
reference_time=datetime.now()
)
for product in product_data
]
# 批量写入图记忆(效率远高于单条添加)
await graphiti.add_episode_bulk(bulk_episodes)自定义实体类型和边缘类型
流程:
- 通过pydantic.BaseModel定义实体类型和边类型,并添加映射表
entity_types、edge_types、edge_type_map。 - Graphiti 从文本中提取实体,并用自定义类型进行分类。每个实体都经过相应的 Pydantic 模型验证,自定义属性从文本中提取并填充。
- Graphiti 识别提取实体之间的关系,并用自定义类型进行分类,经由 Pydantic 模型验证。
ini
# Search for only specific entity types
search_filter = SearchFilters(
node_labels=["Person", "Company"] # Only return Person and Company entities
)
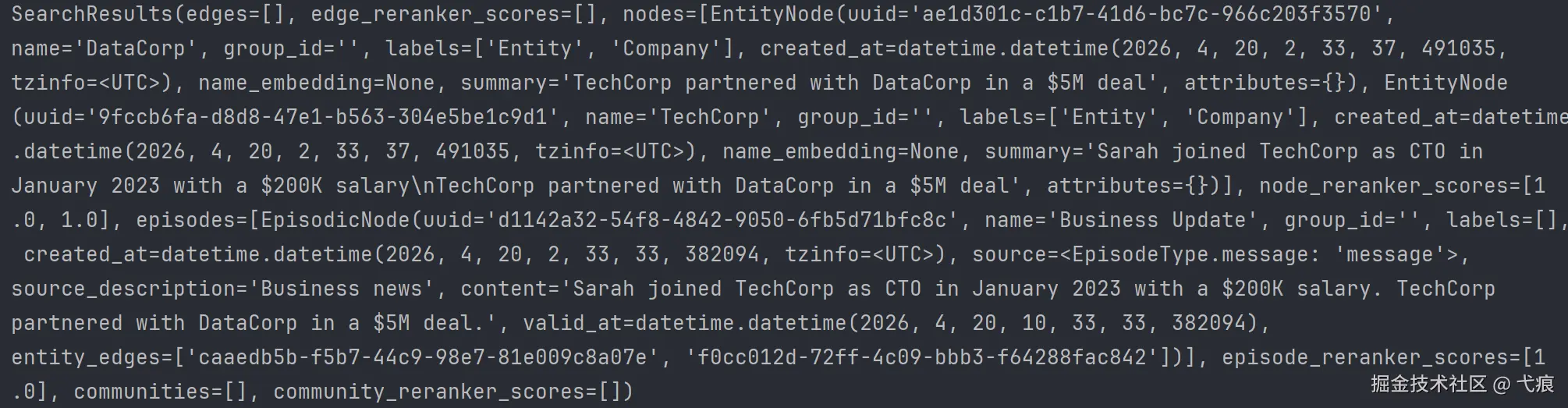
results = await graphiti.search_(
query="Who works at tech companies?",
search_filter=search_filter
)
# Search for only specific edge types
search_filter = SearchFilters(
edge_types=["Employment", "Partnership"] # Only return Employment and Partnership edges
)
results = await graphiti.search_(
query="Tell me about business relationships",
search_filter=search_filter
)
注意:自定义实体类型属性不能使用 Graphiti 核心 EntityNode 类已使用的受保护名称:
uuid,name,group_id,labels,created_at,summary,attributes,name_embedding
社区Communities
社区(CommunityNode 对象):Graphiti 中代表相关实体节点组的核心对象,是图中关联实体的聚合单元。
-
生成社区:
await graphiti.build_communities()。- 使用 Leiden 算法 将强连接的节点聚合为社区。
- 社区包含
summary字段会汇总所有成员实体的摘要信息,既能提供图的高层合成信息,也能保留边的细粒度事实数据。 - 每次调用
build_communities()方法时,会先删除所有已存在的社区,再重新创建新社区。
scss
[CommunityNode(uuid='5911b9ae-fe19-4d41-9cf6-15eae996e96c', name='The summary details recent financial investments, partnerships, and product launches involving TechCorp, DataCorp, and GreenEnergy, including funding amounts, equity stakes, alliance values, and pricing for a new AI Analytics Suite.', group_id='', labels=['Community'], created_at=datetime.datetime(2026, 4, 20, 2, 47, 59, 788326, tzinfo=datetime.timezone.utc), name_embedding=[-0.007104264572262764.......-
更新社区:添加新事件(episode)时,传入参数
update_communities=True- 新增节点加入图后,根据其相邻节点中占比最多的社区,自动归属到对应社区
- 使用标签传播算法(Label Propagation)
图命名空间(Graph Namespacing)
Graphiti 通过
group_id参数实现图命名空间 功能,可在同一个 Graphiti 实例中创建相互隔离的图环境,让多个独立的知识图共存且互不干扰。
- 同一实例下,不同命名空间的数据完全隔离,不会相互影响
- 无需部署多个 Graphiti 服务,即可管理多套独立知识图,为不同业务领域创建专用知识图(如产品、客户、运营)
工作原理:
- 图中的每个节点、每条边 都可以绑定一个
group_id - 相同
group_id的节点和边,组成一个独立、隔离的子图 - 操作(增 / 查 / 改)时指定
group_id,仅作用于对应命名空间内的数据 - 不同
group_id的数据完全隔离,不会交叉查询或覆盖
- 添加事件并指定命名空间
ini
await graphiti.add_episode(
name="customer_interaction",
episode_body="Customer Jane mentioned she loves our new SuperLight Wool Runners in Dark Grey.",
source=EpisodeType.text,
source_description="Customer feedback",
reference_time=datetime.now(),
group_id="customer_team" # 核心:指定命名空间
)- 手动添加事实三元组并指定命名空间。节点、边必须使用相同的
group_id,才能归属到同一命名空间。
ini
# 定义统一命名空间
namespace = "product_catalog"
# 创建节点(绑定group_id)
source_node = EntityNode(
uuid=str(uuid.uuid4()),
name="SuperLight Wool Runners",
group_id=namespace
)
target_node = EntityNode(
uuid=str(uuid.uuid4()),
name="Sustainable Footwear",
group_id=namespace
)
# 创建边(必须使用相同group_id)
edge = EntityEdge(
group_id=namespace,
source_node_uuid=source_node.uuid,
target_node_uuid=target_node.uuid,
created_at=datetime.now(),
name="is_category_of",
fact="SuperLight Wool Runners is a product in the Sustainable Footwear category"
)
# 添加三元组到图
await graphiti.add_triplet(source_node, edge, target_node)- 在指定命名空间内查询数据:查询时传入
group_id,仅返回该命名空间下的结果。
ini
# 基础搜索(限定命名空间)
search_results = await graphiti.search(
query="Wool Runners",
group_id="product_catalog"
)
# 高级节点专属搜索(限定命名空间)
from graphiti_core.search.search_config_recipes import NODE_HYBRID_SEARCH_RRF
node_search_config = NODE_HYBRID_SEARCH_RRF.model_copy(deep=True)
node_search_config.limit = 5
node_search_results = await graphiti._search(
query="SuperLight Wool Runners",
group_id="product_catalog",
config=node_search_config
)图检索
两种基础检索方式
-
混合检索(Hybrid Search)
await graphiti.search(query)- 原理:融合语义相似度检索 + BM25 关键词检索 ,并通过互反排序融合(RRF) 进行结果重排。
-
节点距离重排检索(Node Distance Reranking)
await graphiti.search(query, focal_node_uuid)- 原理:在混合检索基础上,根据节点在图中的距离权重排序,距离目标节点越近优先级越高。
ini
query = "Can Jane wear Allbirds Wool Runners?"
jane_node_uuid = "123e4567-e89b-12d3-a456-426614174000"
def print_facts(edges):
print("\n".join([edge.fact for edge in edges]))
# 1. 混合检索(宽泛结果)
results = await graphiti.search(query)
print_facts(results)
# 输出:
# The Allbirds Wool Runners are sold by Allbirds.
# Men's SuperLight Wool Runners has a runner silhouette.
# Jane purchased SuperLight Wool Runners.
# 2. 节点距离重排检索(精准聚焦 Jane)
results = await graphiti.search(query, jane_node_uuid)
print_facts(results)
# 输出:
# Jane purchased SuperLight Wool Runners.
# Jane is allergic to wool.
# The Allbirds Wool Runners are sold by Allbirds.可配置化高级检索
-
graphiti._search()- 比
search()更灵活、可高度自定义 - 需要传入
SearchConfig配置对象,包括四个关键字段 - 返回
SearchResults对象,包含:节点列表、边列表、社区列表
- 比
-
SearchConfig结构limit:返回结果数量限制- 节点检索配置
- 边检索配置
- 社区检索配置
-
预定义检索配方:为降低使用成本,Graphiti 提供
search_config_recipes.py内置配置
| 检索类型 | 说明 |
|---|---|
| COMBINED_HYBRID_SEARCH_RRF | 全类型混合检索(节点 + 边 + 社区),RRF 重排 |
| COMBINED_HYBRID_SEARCH_MMR | 全类型混合检索,MMR 重排 |
| COMBINED_HYBRID_SEARCH_CROSS_ENCODER | 全类型混合检索,交叉编码器重排 |
| EDGE_* | 仅检索边,支持多种重排策略 |
| NODE_* | 仅检索节点,支持多种重排策略 |
| COMMUNITY_* | 仅检索社区,支持多种重排策略 |
三种重排技术
-
互反排序融合(RRF)
- 作用:融合多种检索算法(BM25 + 语义检索)的结果
- 原理 :对每个结果计算
1/排名分数,求和后重新排序 - 优势:综合不同算法优点,检索更稳定、准确
-
最大边际相关性(MMR)
- 作用 :平衡结果相关性 与多样性
- 原理:优先选择既相关又不重复的结果,避免冗余
- 优势:覆盖查询的多个维度,信息更全面
-
交叉编码器(Cross-Encoder)
-
作用 :将查询 + 结果一起编码,精准计算相关性
-
优势:比单独编码查询 / 文本精度更高
-
三种实现:
OpenAIRerankerClient(默认)GeminiRerankerClient(低成本、低延迟)BGERerankerClient(开源本地模型,需安装sentence_transformers)
-
CRUD 操作
核心类结构
Graphiti 使用 8 个核心类管理图数据,采用抽象基类 + 实现类继承结构:
-
抽象基类(不可直接使用)
Node:节点抽象基类Edge:边抽象基类
-
可实例化 / 支持 CRUD 的实现类
EpisodicNode(事件节点)EntityNode(实体节点)EpisodicEdge(事件边)EntityEdge(实体边)
-
社区专用类
CommunityNode(社区节点)CommunityEdge(社区边)
操作详解
-
所有节点 / 边以 UUID 作为唯一标识,增 / 改 / 查 / 删 都基于 UUID
-
必须依AsyncDriver,所有 CRUD 操作必须传入异步数据库驱动
AsyncDriver -
保存(新增 / 更新)→
save():- 存在则更新(MERGE) :UUID 已存在 → 更新属性
- 不存在则创建:UUID 不存在 → 新增节点 / 边
- 适用于所有实现类:
EpisodicNode/EntityEdge等
-
删除(硬删除)→
delete()- 永久删除节点 / 边(硬删除,不可恢复)
- 使用
DETACH DELETE:同时删除节点及其所有关联边,避免图断裂
-
查询(按 UUID 获取)→
get_by_uuid()
python
async def save(self, driver: AsyncDriver):
result = await driver.execute_query(
"""
MERGE (n:Entity {uuid: $uuid}) # 按UUID匹配,不存在则创建
SET n = {uuid: $uuid, name: $name, name_embedding: $name_embedding, summary: $summary, created_at: $created_at}
RETURN n.uuid AS uuid
""",
uuid=self.uuid,
name=self.name,
summary=self.summary,
name_embedding=self.name_embedding,
created_at=self.created_at,
)
return result
async def delete(self, driver: AsyncDriver):
result = await driver.execute_query(
"""
MATCH (n:Entity {uuid: $uuid}) # 匹配UUID
DETACH DELETE n # 硬删除节点+关联边
""",
uuid=self.uuid,
)
return result
async def get_by_uuid(cls, driver: AsyncDriver, uuid: str):
records, _, _ = await driver.execute_query(
"""
MATCH (n:Entity {uuid: $uuid})
RETURN
n.uuid As uuid,
n.name AS name,
n.created_at AS created_at,
n.summary AS summary
""",
uuid=uuid,
)
# 封装为 EntityNode 对象返回
nodes = [EntityNode(...)]
return nodes[0]手动添加事实三元组
添加事件时会先进行LLM提取,而手动添加事实三元组是直接操作 Neo4j 数据库。
事实三元组(Fact Triple) = 源节点 + 目标节点 + 连接边
- 边中存储具体的事实信息(fact)
- 是知识图谱最基础的数据单元
- 自动去重:对比图中已存在的节点和边,重复则不新增
ini
# 源节点
source_node = EntityNode(
uuid=source_uuid,
name=source_name,
group_id=""
)
# 目标节点
target_node = EntityNode(
uuid=target_uuid,
name=target_name,
group_id=""
)
# 关系边(必须关联源、目标节点 UUID)
edge = EntityEdge(
group_id="",
source_node_uuid=source_uuid,
target_node_uuid=target_uuid,
created_at=datetime.now(),
name=edge_name,
fact=edge_fact
)
await graphiti.add_triplet(source_node, edge, target_node)