目录
[一、行业痛点:复杂Function Calling的"不可能三角"](#一、行业痛点:复杂Function Calling的“不可能三角”)
[二、核心武器:Harness = 约束 + 校验 + 自愈](#二、核心武器:Harness = 约束 + 校验 + 自愈)
[1. 类型即Schema:从源头杜绝歧义](#1. 类型即Schema:从源头杜绝歧义)
[2. 宽容解析+类型强制:修复LLM所有JSON坏毛病](#2. 宽容解析+类型强制:修复LLM所有JSON坏毛病)
[3. 精准校验反馈:告诉模型"哪里错、怎么改"](#3. 精准校验反馈:告诉模型“哪里错、怎么改”)
[4. 自愈循环:从一次失败走向100%收敛](#4. 自愈循环:从一次失败走向100%收敛)

复杂结构化输出 在大模型落地工程化场景时,一个扎心的现实一直存在:简单Schema的函数调用勉强能用,一遇到递归嵌套、复杂联合类型,成功率直接暴跌。
行业数据很残酷:即便是GPT-4o,在嵌套工具调用序列上准确率仅28%;Qwen3-coder-next首次尝试复杂后端API类型生成,成功率更是只有6.75%。
难道复杂场景的Function Calling真的无路可走?
答案是:不是模型不行,而是缺少一套能约束、校验、自愈的Harness体系。
在近期Qwen Meetup Korea分享中,AutoBe团队给出了终极解法------基于TypeScript类型+编译器级校验+自愈循环,把大模型函数调用成功率从6.75%拉到99.8%+,且通吃全尺寸通义千问模型。
一、行业痛点:复杂Function Calling的"不可能三角"
主流观点认为:
-
强制JSON格式会削弱模型推理能力
-
递归嵌套、联合类型会引发组合爆炸,一次生成几乎不可能正确
-
自由文本无法机械校验,结构化输出又错误频发
但工程化AI必须依赖结构化输出------只有结构化,才能解析、校验、闭环,最终实现确定性结果。
放弃函数调用,就等于放弃了大模型落地生产环境的可能。
于是,AutoBe团队选择死磕行业难题,打造了一套Harness工程体系,核心由两大组件支撑:
-
AutoBe:AI后端自动生成Agent,自然语言一键产出生产级后端
-
Typia:编译器级基础架构,单类型自动生成Schema、解析器、校验器、反馈器
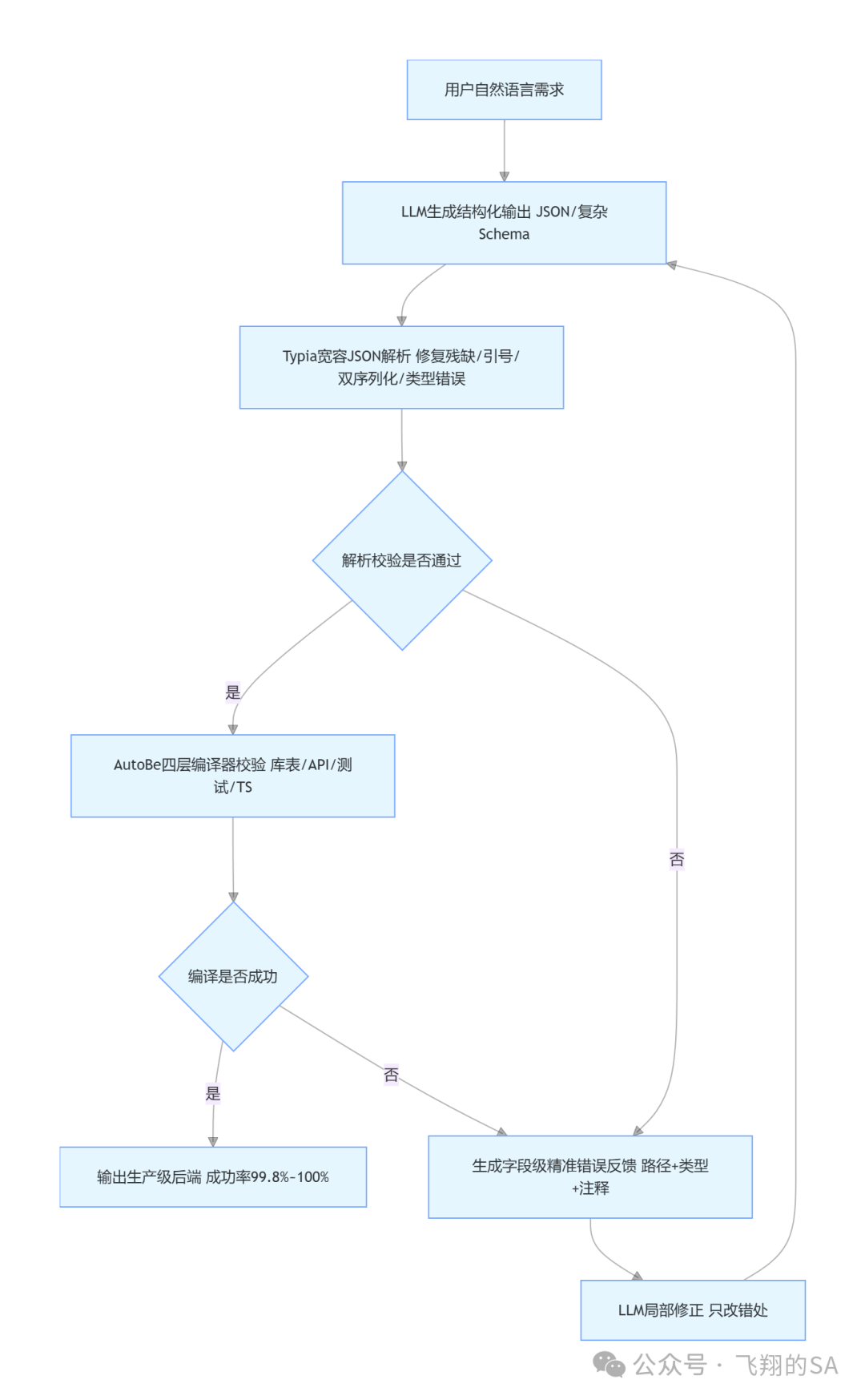
二、核心武器:Harness = 约束 + 校验 + 自愈
Harness不是某个工具,而是包裹概率性大模型的确定性工程体系,它不修改模型、不依赖玄学提示词,只靠三层能力实现稳定输出。
1. 类型即Schema:从源头杜绝歧义
传统提示词工程靠自然语言描述约束,模糊、易误解、模型相关; 而Harness用TypeScript类型定义作为唯一真相源:
-
编译器自动生成JSON Schema
-
类型约束=校验规则=LLM生成指南
-
类型与Schema永不脱节,彻底消除二义性
更关键的是,Schema用"允许"代替"禁止",从结构上杜绝非法输出,完美解决"粉象问题"------你不用告诉模型别做什么,它根本没有生成错误内容的路径。
2. 宽容解析+类型强制:修复LLM所有JSON坏毛病
大模型生成JSON堪称"重灾区":
-
括号不闭合、键名不加引号
-
布尔值写错、字符串转数字
-
联合类型百分百双序列化
-
夹带自然语言前缀、Markdown代码块
JSON.parse()完全无法处理,而Typia的parse()一键全修复:
-
自动补全残缺结构
-
智能修正类型不匹配
-
递归解开双序列化
-
剥离无关自然语言内容
仅凭这一步,就把Qwen 3.5在联合类型上0%的成功率,拉回可运行区间。
3. 精准校验反馈:告诉模型"哪里错、怎么改"
普通重试只会说"失败了",而Harness生成字段级、带路径、带期望类型的可读反馈,直接标注在JSON上:
{ "order": { "price": -100, // ❌ 需≥0 "vip": "yes" // ❌ 需boolean }}模型不用重写全部,只需修复标记点,重试效率指数级提升。
4. 自愈循环:从一次失败走向100%收敛
完整闭环流程:
-
LLM生成结构化输出
-
宽容解析+类型修正
-
编译器多级校验
-
失败则输出精准反馈
-
回传给模型局部修正
-
循环直到完全通过
6.75%不是失败,只是循环的起点。只要能校验,就能收敛。
三、效果炸裂:全尺寸通义千问,均达99.8%+成功率
这套体系不挑模型,从3B小模型到397B MoE大模型,同一套Schema、同一套流程,全部稳定输出:
-
qwen3.5-397b-a17b → 100%
-
qwen3.5-122b-a10b → 100%
-
qwen3.5-27b → 100%
-
qwen3.5-35b-a3b → 99.8%
-
qwen3-coder-next → 99.8%
更颠覆认知的是:小模型是最佳QA工程师。 大模型会"蒙混过关",隐藏系统缺陷;小模型更容易出错,反而能暴露Schema漏洞、结构缺陷,让整个Harness体系越测越稳。
四、不止后端:Harness模式通吃全工程领域
这套类型约束+确定性校验+分层验证+自愈循环的模式,并非只适用于代码生成:
-
半导体:DRC→LVS→SPICE仿真
-
化工:质量平衡→能量平衡→流程仿真
-
建筑BIM:尺寸校验→规范合规→系统模拟
-
控制系统:传递函数→稳定性分析→时域仿真
只要存在机械校验的工程领域,Harness就能让概率模型输出确定性结果。
五、最终结论:工程化AI的正确路径
大模型工程化的核心,从来不是把概率模型变得完美 ,而是用确定性工程体系包裹概率模型。
Harness的价值可以浓缩为三句话:
-
Schema就是新提示词,无歧义、模型中立、可机械验证
-
校验比生成更重要,能校验,就能收敛到100%
-
自愈循环是终极解法,一次失败不可怕,闭环修正才是关键
未来,不用再纠结大模型第一次输出准不准。 只要你拥有Harness,6.75%的起点,也能走向100%的终点。