文章目录
- 网络爬虫核心知识与技能指南
-
- [1. 爬虫的概念](#1. 爬虫的概念)
- [2. 爬虫的分类](#2. 爬虫的分类)
- [3. 爬虫的工作流程](#3. 爬虫的工作流程)
- [4. HTTP基本原理](#4. HTTP基本原理)
- [5. 熟练使用浏览器开发者工具](#5. 熟练使用浏览器开发者工具)
- [6. 使用Socket发送网络请求](#6. 使用Socket发送网络请求)
- 总结与建议
网络爬虫核心知识与技能指南
1. 爬虫的概念
网络爬虫(Web Crawler),也称为网络蜘蛛(Web Spider)或网络机器人(Web Robot),网络爬虫是一种按照特定规则自动抓取互联网信息的程序或脚本。它模拟人类浏览网页的行为,但能以更高效率和更大规模获取网络数据。
2. 爬虫的分类
网络爬虫根据系统结构、实现技术和应用目标的不同,可以分为以下几种主要类型:
| 分类类型 | 核心特点 | 典型应用 |
|---|---|---|
| 通用网络爬虫 (General Purpose Web Crawler) | 爬行范围和数量巨大,目标是尽可能多地抓取互联网上的各种网站信息,不针对特定网站。 | 搜索引擎(如百度、Google)的数据抓取。 |
| 聚焦网络爬虫 (Focused Web Crawler) | 针对特定网站或特定类型网站进行定制开发,抓取范围有限,主要用于特定需求的数据抓取,也称主题网络爬虫(Topical Crawler)。 | 特定领域信息收集、竞品分析、舆情监控。 |
| 增量式网络爬虫 (Incremental Web Crawler) | 在上一次抓取的基础上,只抓取新增或有更新的网页,减少重复抓取,提高效率,适用于需要频繁更新数据的场景。 | 新闻网站、论坛等内容更新较快的网站。 |
| 深层网络爬虫 (Deep Web Crawler) | 专门抓取存在于互联网深层的页面,这些页面通常不能通过静态链接获取,需要提交表单或特定查询才能访问。 | 需要登录后才能访问的内容、隐藏在搜索表单后的数据库查询结果。 |
此外,实际的网络爬虫系统通常是几种爬虫技术相结合实现的。
3. 爬虫的工作流程
一个典型的网络爬虫工作流程包括以下几个核心步骤:
- 发送请求 (Send Request):爬虫首先通过HTTP或其他协议向目标URL发起请求,获取网页的HTML内容。这通常借助HTTP请求库(如Python中的Requests库)来实现。
- 获取响应 (Get Response):目标网站服务器接收到请求后,会返回一个响应(Response),其中包含了请求的网页内容(如HTML代码、JSON数据或二进制数据等)以及状态码等信息。
- 解析响应与提取数据 (Parse Response and Extract Data):爬虫对获取的HTML等内容进行解析,并提取需要的信息(如URL链接、文本、图片、视频等)。常用的解析工具有正则表达式、XPath、Beautiful Soup等。
- 存储数据 (Store Data) :爬虫将提取出的有用数据存储到数据库、文件或其他存储介质(如关系型数据库、NoSQL数据库、JSON文件等)中,以备后续分析或展示。
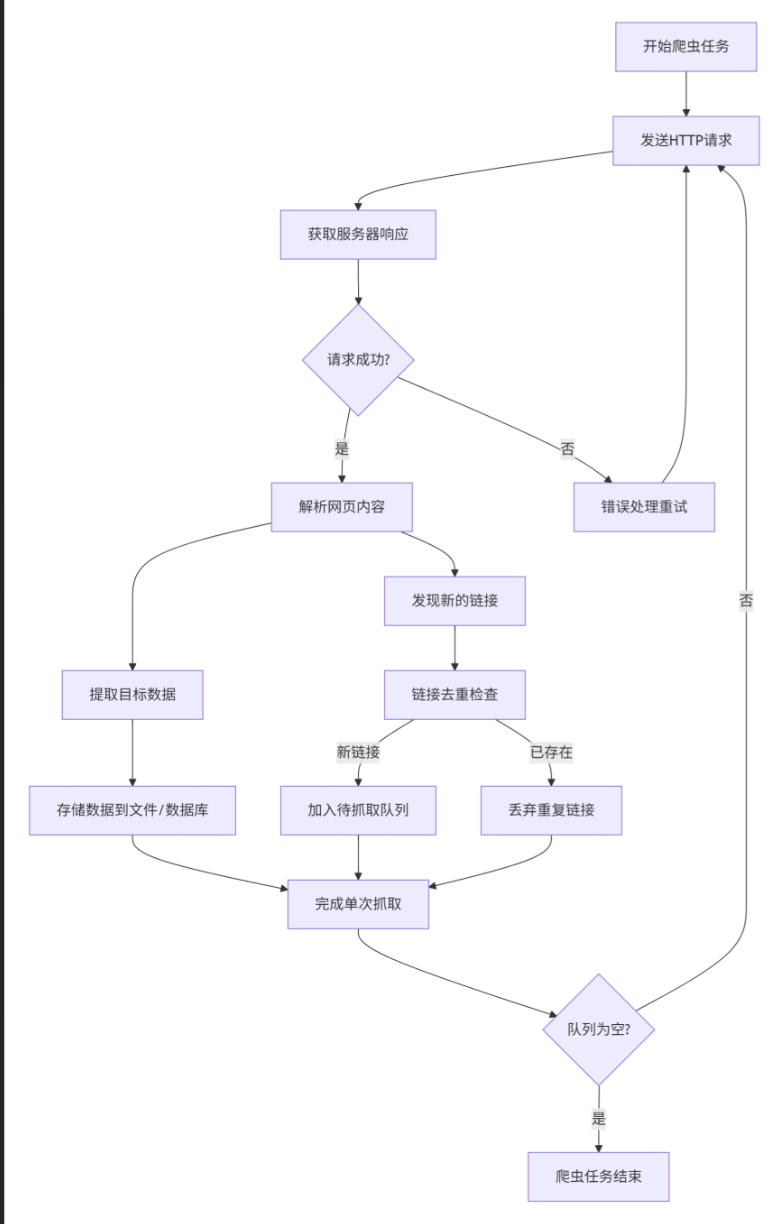
此外,在爬虫运行过程中,通常还需要URL管理 (从一个或多个初始URL开始,递归或迭代地发现新的URL,构建待抓取队列)和遵守规则(如尊重robots.txt协议,合理控制访问频率,避免对服务器造成过大负担)等环节。
4. HTTP基本原理
理解HTTP(HyperText Transfer Protocol)是理解爬虫如何与Web服务器交互的基础。
- 基本概念:HTTP是应用层协议,是万维网数据通信的基础。它规定了客户端(如浏览器、爬虫)和服务器之间请求和响应的格式与规则。
- 请求(Request) :客户端向服务器发送请求以获取资源。一个HTTP请求主要由以下部分组成:
- 请求行 (Request Line):包含请求方法(如GET, POST)、请求的URL和HTTP协议版本。
- 请求头 (Request Headers) :包含关于客户端和环境的信息,如
User-Agent(浏览器身份标识)、Host、Cookie、Referer等。爬虫常需模拟或设置这些头信息以正常访问或规避反爬机制。 - 请求体 (Request Body):主要在POST等方法中携带发送给服务器的数据(如表单数据、JSON等)。
- 响应(Response) :服务器处理请求后返回给客户端的结果。一个HTTP响应主要包括:
- 状态行 (Status Line):包含HTTP协议版本、状态码和状态信息。
- 响应头 (Response Headers) :包含服务器信息、资源信息等,如
Content-Type(内容类型)、Set-Cookie等。 - 响应体 (Response Body):服务器返回的实际内容,如HTML文档、JSON数据、图片等,这是爬虫主要关注的部分。
- 常用状态码 :
200 OK: 请求成功。301 Moved Permanently: 永久重定向。404 Not Found: 请求的资源不存在。403 Forbidden: 禁止访问。500 Internal Server Error: 服务器内部错误。
- Session 和 Cookie:HTTP是无状态协议。Cookie和Session机制用于维持客户端与服务器之间的状态(如登录状态)。爬虫有时需要处理Cookie以保持会话。
5. 熟练使用浏览器开发者工具
浏览器开发者工具(DevTools)是爬虫开发者分析网页、调试请求的利器。
- Elements(元素)面板:用于查看和编辑网页的DOM结构。可以帮助你定位需要提取数据的HTML元素及其选择器(如CSS选择器、XPath)。
- Network(网络)面板 :这是爬虫分析中最常用的面板 。它记录了页面加载过程中所有网络请求的详细信息。
- 可以查看每个请求的详细URL 、请求头 (包括Cookie、User-Agent等)、请求方法 、响应头 和响应体。
- 筛选XHR(Ajax请求)或Fetch请求 often 能快速找到动态加载数据的接口。
- 通过"Copy"功能可以方便地将请求复制为cURL命令,进而转换为Python等语言的代码片段。
- Console(控制台)面板:可以执行JavaScript代码,用于测试一些页面上的脚本或交互。
- Application(应用)面板:可以查看和操作本地存储,如Cookie、Local Storage、Session Storage。
常用操作:打开开发者工具(F12),刷新页面,在Network面板中观察请求,筛选出获取数据的关键请求,分析其请求参数和响应格式。
6. 使用Socket发送网络请求
虽然高级的爬虫通常使用现成的HTTP库(如Python的requests),但了解底层的Socket通信有助于更深入地理解网络请求过程。
- Socket概念:Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口,允许不同主机或同一主机上的不同进程之间进行网络通信。
- 基本步骤 (以TCP连接为例):
- 创建Socket对象。
- 连接到目标服务器的指定端口(HTTP通常是80,HTTPS是443)。
- 通过Socket发送 符合HTTP协议格式的请求报文(需要自己拼接请求行、请求头和请求体)。
- 通过Socket接收 服务器返回的响应数据(需要自己解析响应头和响应体)。
- 关闭连接。
python
# 一个非常简单的使用Python socket模块发送HTTP GET请求的例子
import socket
# 创建TCP socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 连接到目标服务器的80端口
s.connect(('example.com', 80))
# 拼接HTTP GET请求(注意换行符和最后的空行)
request = "GET / HTTP/1.1\r\nHost: example.com\r\nConnection: close\r\n\r\n"
# 发送请求(需要编码为bytes)
s.send(request.encode())
# 接收响应数据
response = b''
while True:
part = s.recv(1024)
if not part:
break
response += part
# 关闭连接
s.close()
# 打印响应(包含响应头和响应体)
print(response.decode())注意 :这只是最基本演示。实际中,你需要处理HTTPS (需要SSL/TLS加密)、重定向 、连接复用 、大数据接收等复杂情况。因此,在绝大多数爬虫开发中,更推荐使用高级的、功能完善的HTTP客户端库。
总结与建议
掌握网络爬虫技术需要理论与实践相结合。建议按照以下路径学习:
- 夯实基础:首先理解HTTP协议和Web通信原理,这是万变不离其宗的核心。
- 熟练工具:多多使用浏览器开发者工具,学会分析网页结构、追踪网络请求,这是后续编写爬虫的"侦察"环节。
- 选择语言与库 :Python是爬虫领域的热门选择,其
requests(发送请求)、BeautifulSoup和lxml(解析HTML)、scrapy(框架)等库生态丰富。 - 动手实践:从简单的静态网页抓取开始,逐步挑战需要处理Cookie、Session、动态加载(如Ajax)、反爬机制(验证码、IP封锁)的复杂站点。
- 遵守规范 :始终尊重
robots.txt协议,合理控制访问频率,避免对目标网站服务器造成过大压力,在法律和道德框架内使用爬虫技术。
希望这份指南能为你系统学习网络爬虫提供一个清晰的路线和坚实的基础。祝你学习顺利!