text
Field of study that givescomputers the ability to learnwithout being explicitlyprogrammed.
使计算机无需明确编程即可学习的研究领域
--Arthur Samuel(1959)What's Machine learning
通过编程使计算机能够进行成千上万次自我对弈,来得到最优解

如果跳棋程序只进行10场自我对弈,而不是数万场,那么它学习到的策略和模式将非常有限,无法充分探索棋局的各种可能性,也无法有效优化自己的决策。这会使其性能显著下降,无法达到通过大量自我对弈所获得的强大水平
Machine Learning Algorithms
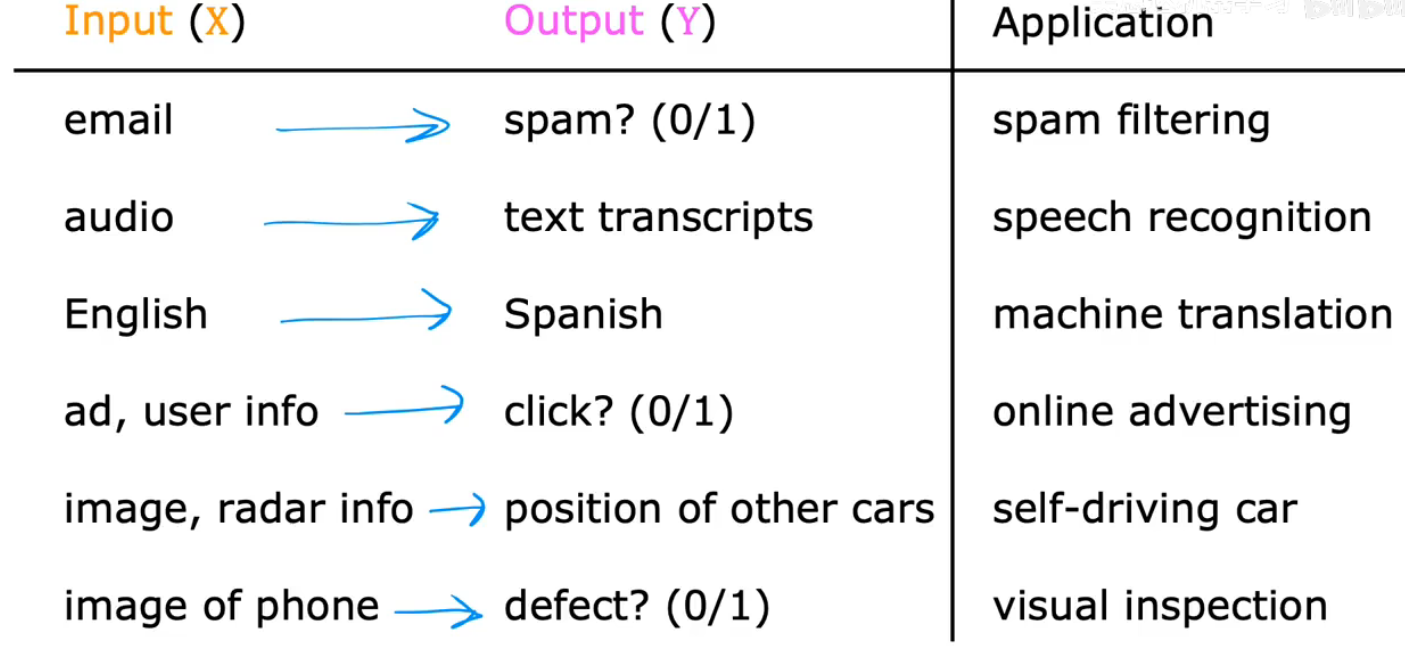
- 监督学习(Supervised learning) <- used more in real-world applications(rapid advancements)
- 非监督学习(Unsupervised learning)
- 强化学习(Reinforcement learning)
- 应用学习算法的实用建议 <- Practical advice for applying learning algorithms(How to use)
Supervised learning
关键特征:给学习算法提供学习的例子(Learns from being given "right answers")
Right answers 是指给定输入x的正确标签y,通过观察输入x和期望标签y的正确配对 学习算法最终学会,仅通过输入而不需要输出标签来给出相当准确的预测和猜测
监督学习 = 给算法"题目 + 标准答案"
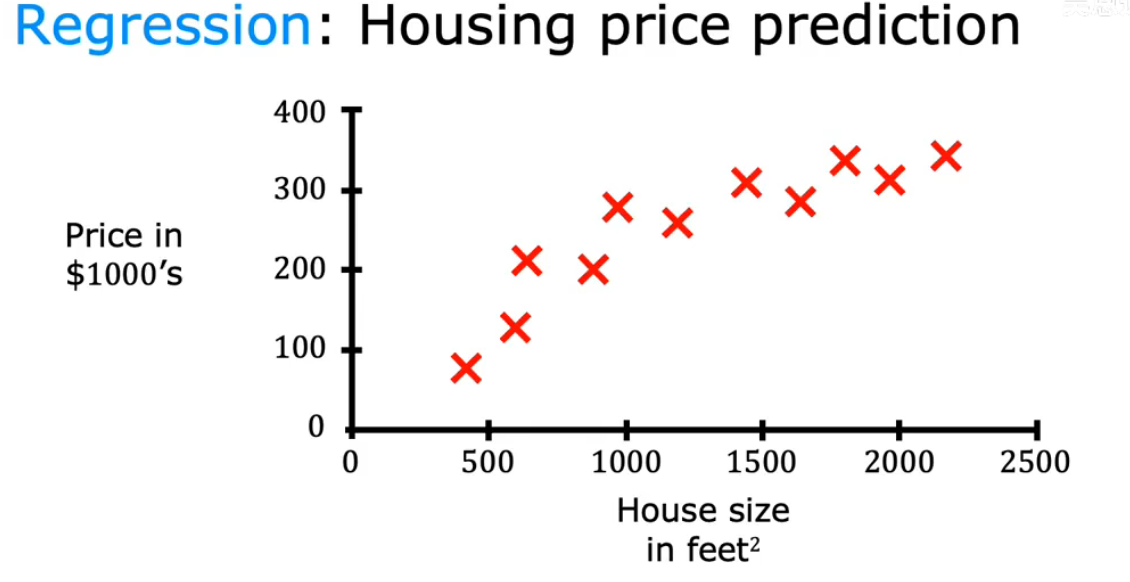
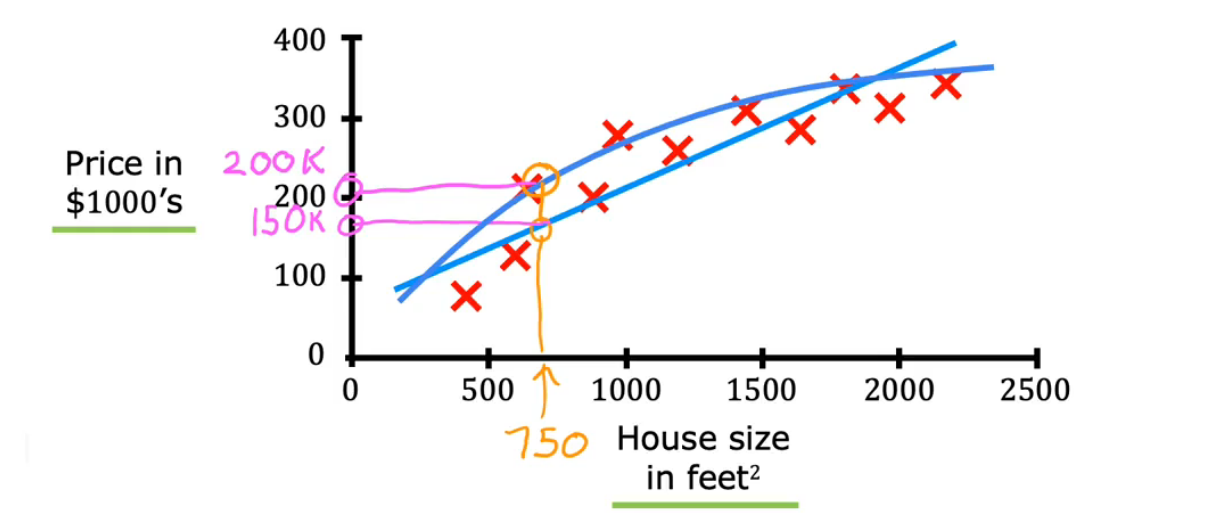
我们给算法提供了一个数据集 其中所谓的正确答案,也就是标签或正确的价格y,是为图上的每一栋房子给出的
针对这个房价的预测是监督学习中特定类型 称为回归(Regression)
infinitely many possible outputs -> Predict a number
通过回归,从无限多的可能数字中预测一个数字
分类(Classification)
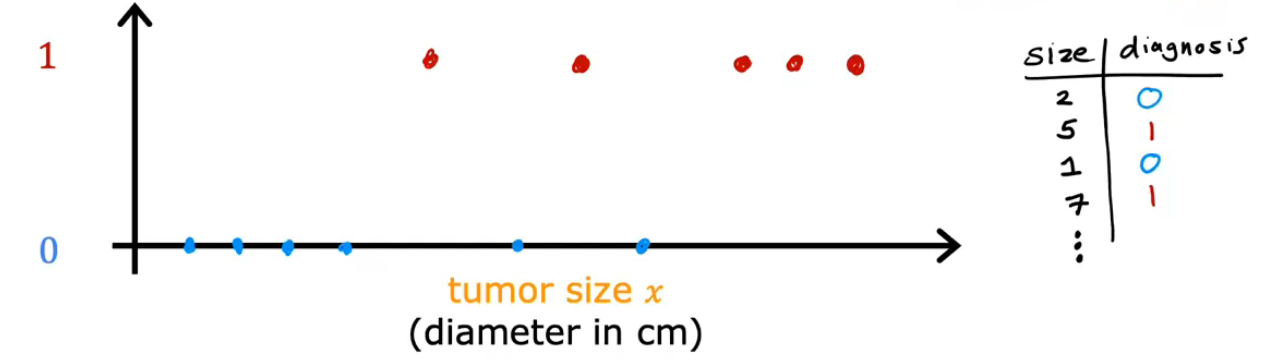
和回归的区别:预测的可能输出或类别数量很少,这种情况下会有两种输出(zero or one & benign or malignant),因为在这个例子中只有两个可能的输出

分类算法预测类别(Predict Categories):类别可以是非数字
可能的输出数量较少(small number of possible outputs)
可以使用多个输入值来预测输出
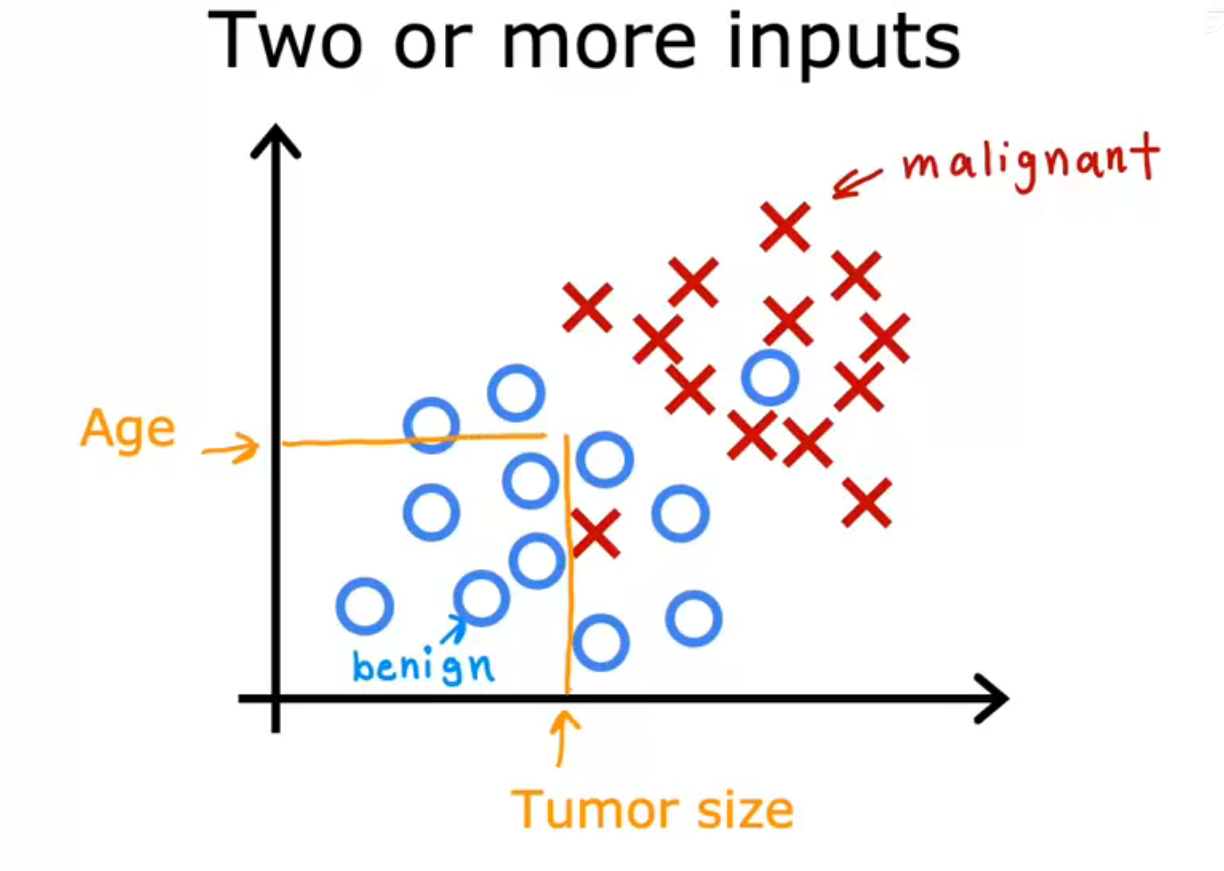
可以通过测量患者的肿瘤大小并记录患者的年龄
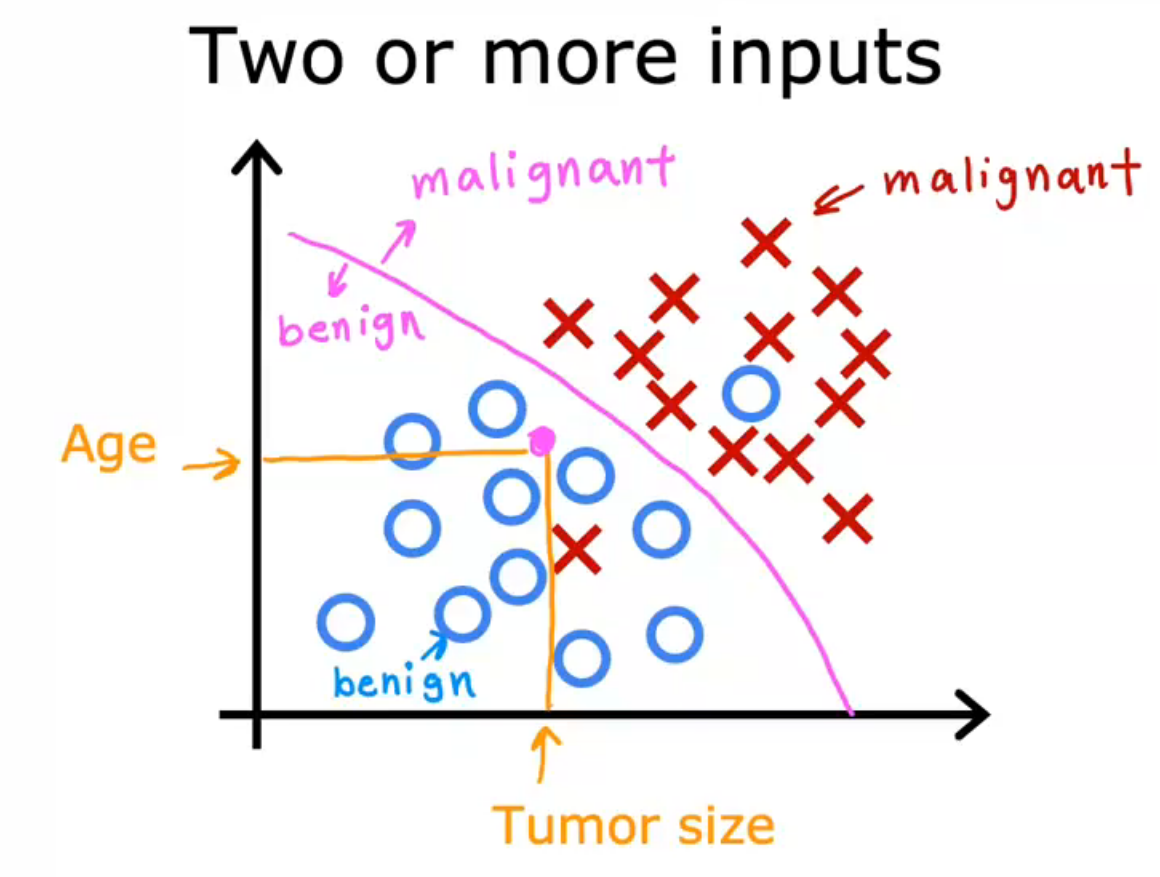
如何鉴定:学习算法会摘找到一些边界,将恶性肿瘤与良性肿瘤分开,学习算法必须决定如何为这些数据拟合一条边界线
Unsupervised learning
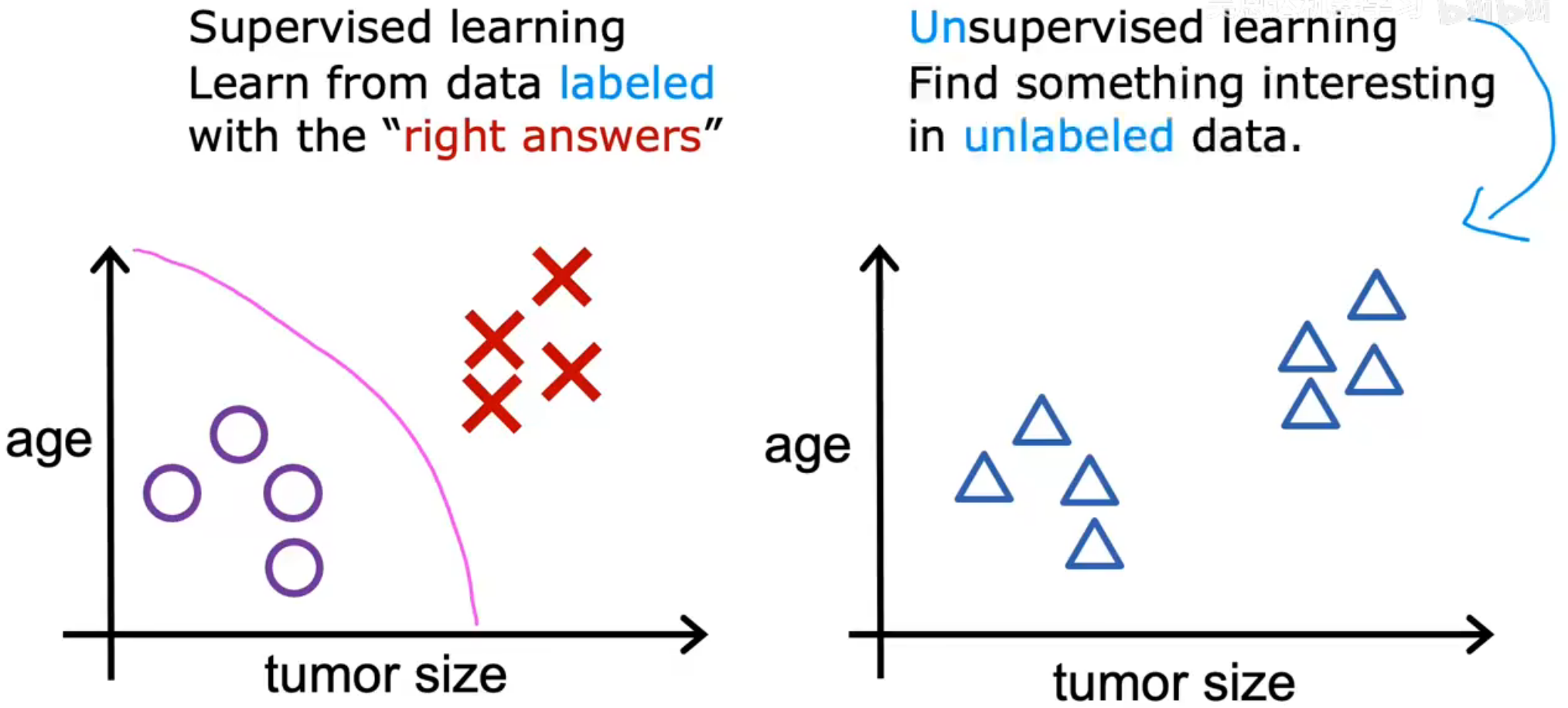
非监督学习不会指定正确的输出,而是让算法自己找出有什么有趣的东西或可能存在的模式或结构
之所以称之为无监督学习是因为我们并不是试图监督算法为每个问题给出某个所谓的正确答案输入,相反,我们让算法自己找出有什么有趣的东西或可能存在的模式或结构
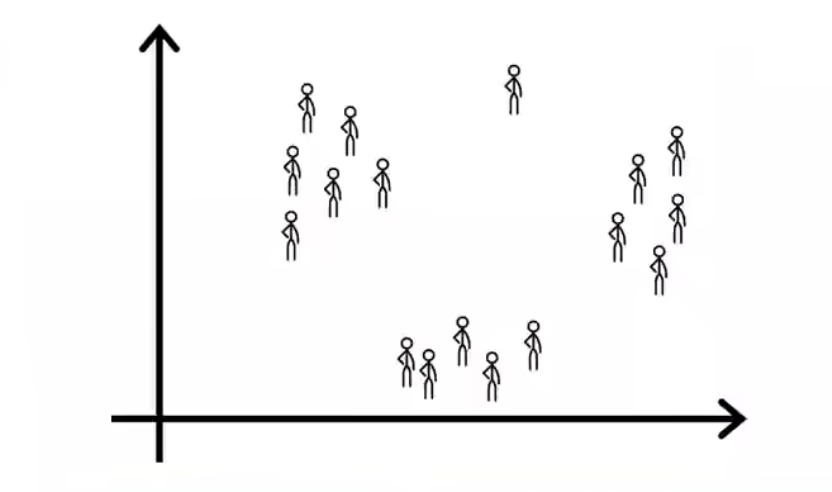
一个监督学习算法可能会决定将数据分为两个不同的组或两个不同的簇
聚类算法(Clustering Algorithm):将未标记的数据放入不同的簇中
Google News
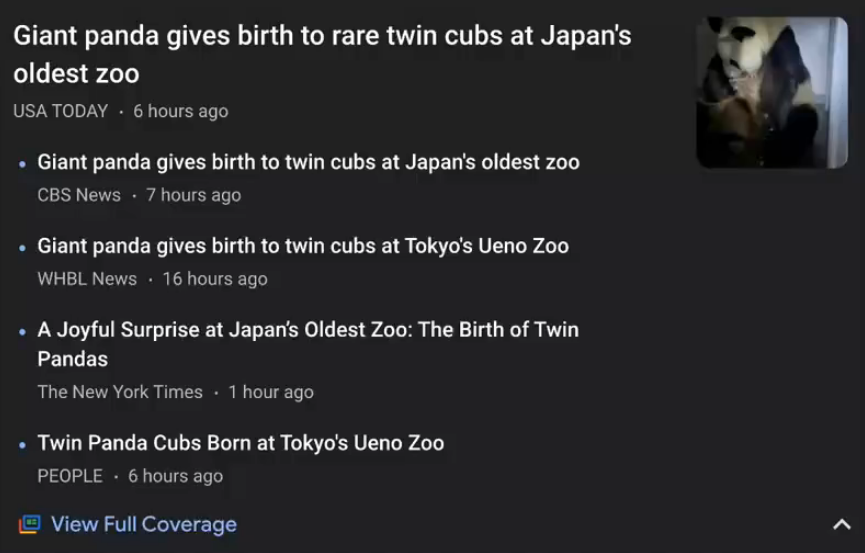
对信息进行自动分组
DNA Microarray
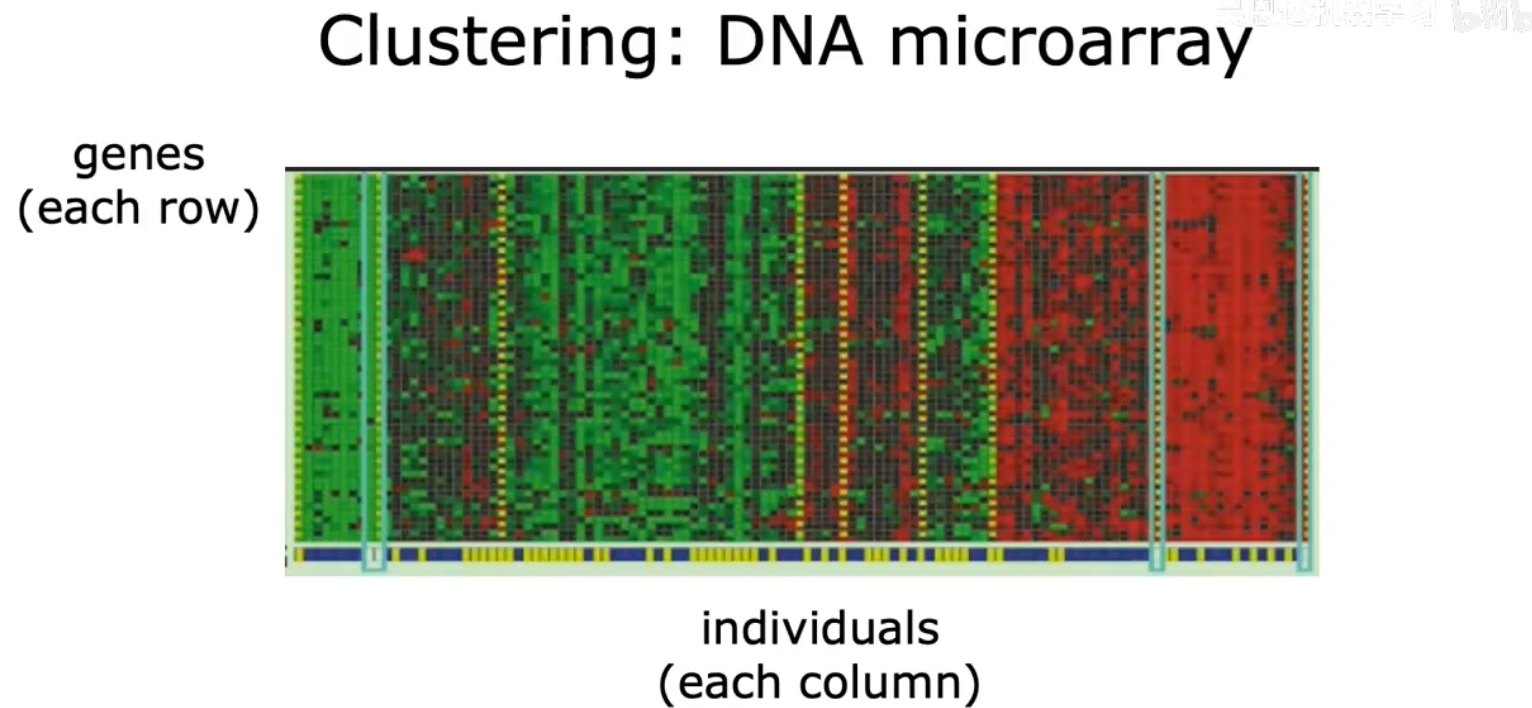
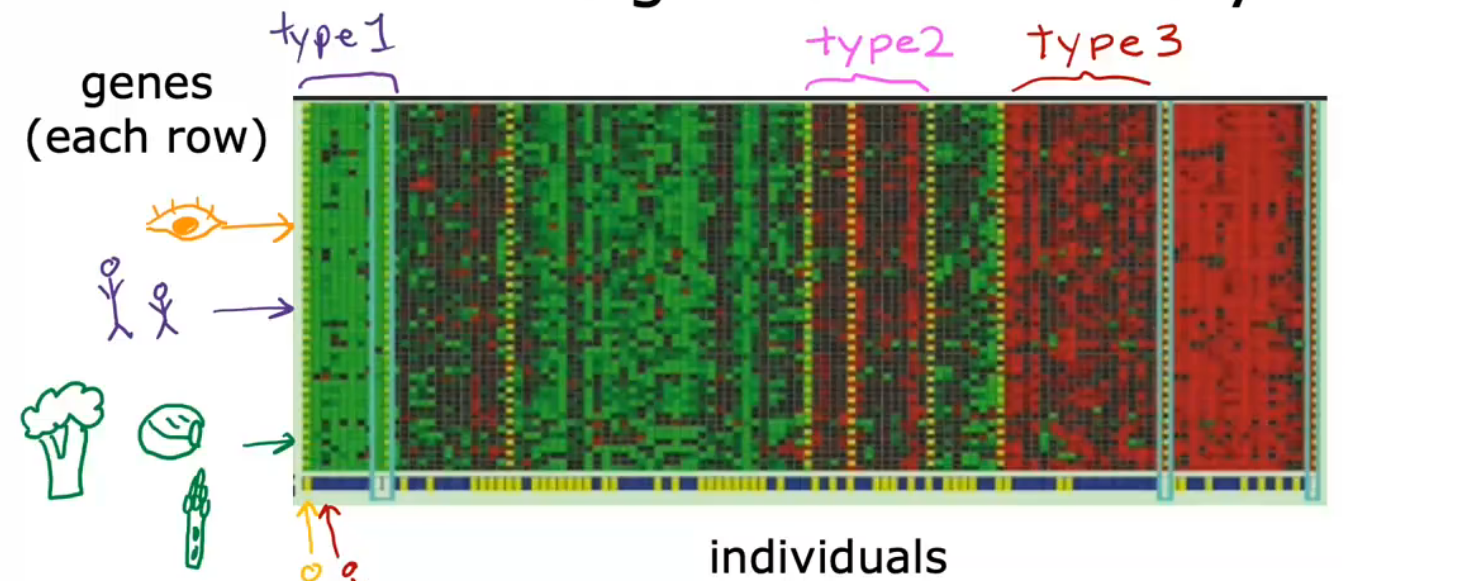
不会先告诉算法有什么什么类型,而是提供一堆数据,让算法自动在数据中找到机构,并自动找出主要的个体类型,这就是无监督学习
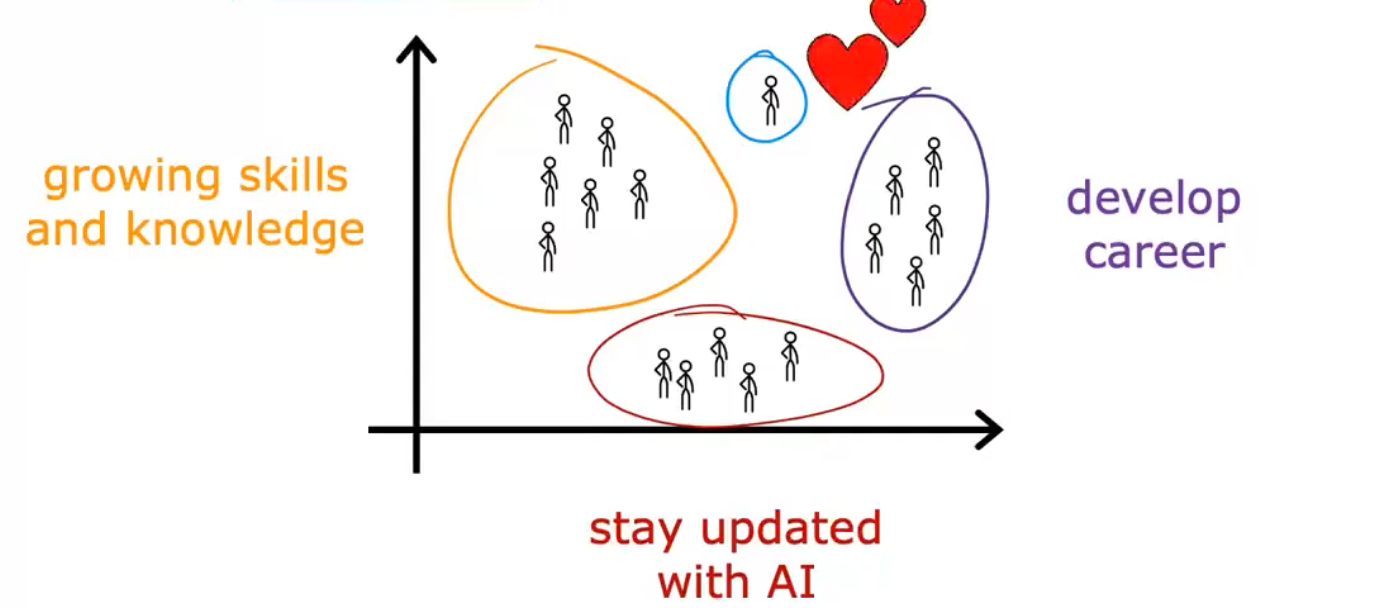
Grouping customers(客户信息数据库)
根据数据将客户分成不同的市场细分,从而高效的为客户服务
Concept:
- Data only comes with inputs x, but not output labels y.
- Algorithm has to find structure in the data.
Learning Type: - Clustering(聚类算法):将相似的数据点分组在一起(Group similar datapoints together.)
- Anomaly Detection(异常检测):找出异常数据点(Find unusual data points)
- Dimensionality Reduction(降维):将一个大型数据集压缩成一个更小的数据集 同时尽可能少地丢失信息(Compress data using fewer numbers)

Jupyter Notebooks
Conda环境配置
常用的conda指令:
创建新的python环境 conda create -n env_name python=3.x
查看已有的python环境 conda env list
进入已有的python环境 conda activate env_name
退出当前的python环境 conda deactivate
常用的pip指令: pip install -r requirements.txt 根据requirements.txt的内容安装所需的包 pip install package_name 安装包
pip install ............... --timeout 6000 pip
换清华源后缀: -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple --trusted-host=https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple可以直接Vscode安装插件