很多人第一次给 Agent 加"定时任务"能力,直觉上会这样做:
- 用户说"明天早上 9 点提醒我写周报"
- 服务端解析出一个时间
- 到点后调用一段固定逻辑
这套思路并不完全错,但它只适合"预先写死的动作"。一旦用户的目标变成"明天 9 点查一下 AI 新闻并发到我邮箱""每小时同步一次数据库里的异常记录""下周一早上根据最新数据生成摘要再通知我",你会发现一个问题:
真正需要被调度的,不是某个固定函数,而是一段未来才执行的任务意图。
这也是 OpenClaw、豆包这类 Agent 产品在定时任务设计上的共同思路。它们本质上不是给模型塞了一个 Cron,而是把"未来要做什么"保存下来,到时间后再重新启动一轮 Agent Loop,让模型结合工具去完成当时的任务。
这篇文章我想讲清楚的核心结论只有一个:
Agent 的定时任务,本质上不是"定时调用某个 tool",而是"把自然语言任务持久化,然后在未来重新拉起一轮带工具的 Agent 执行链路"。
围绕这个结论,我们用 NestJS + LangChain + TypeORM + @nestjs/schedule 实现一个完整的工程化方案。它不只是能"设个提醒",而是具备下面几种能力:
- 让模型理解用户的定时请求
- 把任务保存到数据库,而不是只放在内存里
- 支持一次性任务、周期任务和 Cron 表达式任务
- 服务重启后自动恢复已启用任务
- 到点后重新启动一轮 Agent Loop,通过 tool 完成真正的业务动作
如果你正在做 AI Agent、Workflow Agent、自动化助手或者任何需要"延迟执行"的 AI 应用,这套设计会比"直接绑一个 Cron 回调"更接近真实产品。
为什么 Agent 的定时任务不能只理解成 Cron
传统后端里的定时任务,一般是"时间到了,执行一段确定逻辑"。比如:
- 每天 0 点清理缓存
- 每 5 分钟拉一次订单
- 每小时跑一次统计
它们的共同点是:动作在编码阶段就已经确定了。
但 Agent 场景不一样。用户输入的通常是自然语言目标,系统未必知道未来具体会调用哪个工具、以什么顺序调用、是否要先检索再发邮件、是否要先查库再生成摘要。
举个例子:
明天上午 10 点,帮我查一下 OpenAI 最近一周的更新,如果有 API 相关改动,就发邮件提醒我。
如果你把它实现成"定时调用 send_mail",显然不对。因为到明天 10 点时,系统应该先搜索、再判断、最后决定是否发邮件。
所以,从工程视角看,Agent 定时任务应该拆成两层:
- 调度层:负责决定"什么时候执行"
- 执行层:负责决定"到点后具体怎么做"
前者属于 Scheduler,后者属于 Agent。
这两个层次如果混在一起,系统很快会变得难扩展。你会不断地往"定时任务回调函数"里硬塞逻辑,最后把一个原本应该由模型决策的动态任务,改造成一堆 if-else 拼出来的伪 Agent。
一个更贴近真实产品的架构
如果把这套系统画成数据流,核心链路其实很清楚:
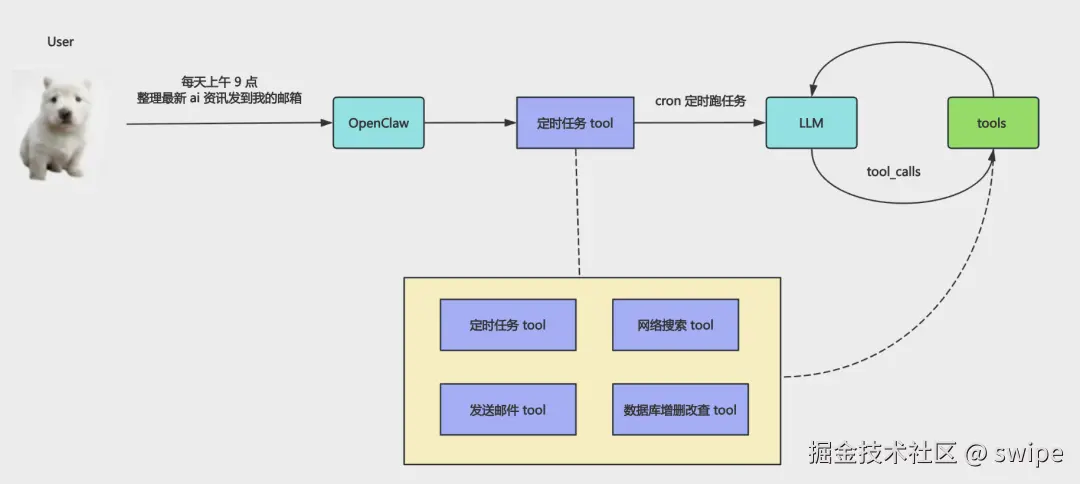
- 用户发出自然语言请求,比如"1 小时后提醒我整理日报"
- 对话 Agent 判断这是一个定时任务需求
- Agent 调用
cron_job这类管理型 tool,而不是立刻执行业务动作 - 系统把任务持久化到数据库,并注册到调度器
- 到点后,由调度器拉起一个"任务执行 Agent"
- 这个执行 Agent 再根据保存下来的
instruction调用send_mail、web_search、db_users_crud等业务 tool
也就是说,定时任务本身并不直接等价于"某个工具调用"。它只是把未来的一轮 Agent 执行预定下来。
这和很多产品里的体验是一致的:
- 现在只创建任务,不直接完成任务
- 到未来某个时刻,系统再真正执行
- 执行时仍然是 Agent 风格,而不是单一函数调用
技术选型:为什么是 Nest + LangChain + Schedule + TypeORM
这套方案里,我比较推荐下面这个组合:
NestJS:适合做模块化后端,依赖注入、Provider、Module 之间的组织成本比较低LangChain:适合把模型、消息、tool 调用和 agent loop 串起来@nestjs/schedule:直接复用 Nest 的调度体系,支持cron / interval / timeoutTypeORM:把任务和业务数据持久化到数据库里,避免"服务一重启,任务全没了"
如果只是做 Demo,你完全可以不用 ORM、直接放内存。但如果目标是接近真实产品,这么做有两个明显问题:
- 任务无法持久化,进程重启就丢
- 任务无法被管理,用户看不到列表、也没法停用或恢复
因此,这里更值得学习的不是"怎么用 NestJS 写一个定时器",而是怎么把 Agent、数据库、调度器和工具调用组织成一条闭环链路。
先做最小闭环:让 Agent 真正能调 Tool
在讨论定时任务之前,应该先把最小的 Agent Loop 跑通。因为未来执行的任务,本质上还是靠这条链路完成。
项目初始化非常直接:
bash
nest new cron-job-tool
pnpm install @langchain/core @langchain/openai zod @nestjs/config然后在 AppModule 里引入配置模块,并准备模型配置:
env
OPENAI_API_KEY=sk-xxx
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
MODEL_NAME=qwen-plus这里的重点不是具体用哪个模型,而是把模型能力封装成可注入的 Provider。这样后面不管是对话 Agent,还是任务执行 Agent,都可以复用同一个 CHAT_MODEL。
接下来先实现一个最简单的 tool,比如查询用户信息。这个 tool 很适合用来验证 Agent Loop 是否真的打通,因为它既有结构化入参,也有明确的输出结果。
ts
const queryUserArgsSchema = z.object({
userId: z.string().describe('用户 ID,例如: 001, 002, 003'),
});
const queryUserTool = tool(
async ({ userId }: { userId: string }) => {
const user = database.users[userId];
if (!user) {
return `用户 ID ${userId} 不存在。可用的 ID: 001, 002, 003`;
}
return `用户信息:
- ID: ${user.id}
- 姓名: ${user.name}
- 邮箱: ${user.email}
- 角色: ${user.role}`;
},
{
name: 'query_user',
description: '根据用户 ID 查询用户信息。',
schema: queryUserArgsSchema,
},
);这段代码本身并不复杂,真正关键的是它在整个链路中的位置:
zod schema用来约束模型的参数生成tool(...)把业务能力包装成模型可调用的工具- 输出尽量返回对模型友好的自然语言或结构化文本,方便下一轮推理继续使用
很多人写到这里就停了,觉得"tool 已经定义好了"。但真正决定系统是否可用的,是后面的 Agent Loop。
ts
async runChain(query: string): Promise<string> {
const messages: BaseMessage[] = [
new SystemMessage(
'你是一个智能助手,可以在需要时调用工具来完成任务。',
),
new HumanMessage(query),
];
while (true) {
const aiMessage = await this.modelWithTools.invoke(messages);
messages.push(aiMessage);
const toolCalls = aiMessage.tool_calls ?? [];
if (!toolCalls.length) {
return String(aiMessage.content ?? '');
}
for (const toolCall of toolCalls) {
if (toolCall.name === 'query_user') {
const args = queryUserArgsSchema.parse(toolCall.args);
const result = await queryUserTool.invoke(args);
messages.push(
new ToolMessage({
tool_call_id: toolCall.id || '',
name: toolCall.name,
content: result,
}),
);
}
}
}
}这段循环才是整个系统的地基。
它做的事情可以理解为:
- 把用户问题交给模型
- 如果模型不需要工具,就直接返回答案
- 如果模型发起 tool call,就执行对应工具
- 把工具结果再作为
ToolMessage喂回模型 - 继续下一轮推理,直到模型输出最终回答
这也是为什么后面"定时任务到点后执行"时,我们不会直接写一个 sendEmail(),而是重新走一遍同样的 Agent Loop。
流式输出不是锦上添花,而是用户体验底线
一旦系统进入 tool 调用场景,响应时间通常会明显变长。模型要思考、要决定是否调用工具、工具执行也有耗时。如果这时候还是纯阻塞响应,用户会觉得系统"卡住了"。
所以更合理的做法是把非工具调用阶段的文本内容流式输出,再把工具调用部分留在服务端完成。
ts
async *runChainStream(query: string): AsyncIterable<string> {
const messages: BaseMessage[] = [
new SystemMessage('你是一个可以调用工具的智能助手。'),
new HumanMessage(query),
];
while (true) {
const stream = await this.modelWithTools.stream(messages);
let fullAIMessage: AIMessageChunk | null = null;
for await (const chunk of stream as AsyncIterable<AIMessageChunk>) {
fullAIMessage = fullAIMessage ? fullAIMessage.concat(chunk) : chunk;
const hasToolCallChunk =
!!fullAIMessage.tool_call_chunks &&
fullAIMessage.tool_call_chunks.length > 0;
if (!hasToolCallChunk && chunk.content) {
yield chunk.content as string;
}
}
if (!fullAIMessage) return;
messages.push(fullAIMessage);
const toolCalls = fullAIMessage.tool_calls ?? [];
if (!toolCalls.length) return;
// 执行工具并把结果回填到 messages
}
}这里有一个很容易忽略的点:不要在已经出现 tool_call_chunks 之后继续把中间文本往前端吐。
原因很简单。模型在决定调用工具前,可能会先输出一些半成品内容。如果你把这些内容提前展示,用户会看到一段看似完整、实际又会被后续工具结果推翻的回答。
因此,更稳妥的做法是:
- 还没进入工具调用阶段时,可以流式返回文本
- 一旦出现工具调用,就把本轮结果先收完,执行工具后再进入下一轮
对应到 Nest 里,用 SSE 暴露一个流式接口即可:
ts
@Sse('chat/stream')
chatStream(@Query('query') query: string): Observable<MessageEvent> {
const stream = this.aiService.runChainStream(query);
return from(stream).pipe(
map((chunk) => ({
data: chunk,
})),
);
}Tool 最好调用 Service,而不是直接写死在 Demo 里
很多教程为了省事,会把数据直接写成对象字面量,tool 内部直接操作这份内存数据。作为最小演示可以接受,但一旦你想把系统做成可扩展结构,这种写法很快会卡住。
更好的方式是:
- 业务逻辑放在 Service 里
- tool 只负责把模型输入映射成 Service 调用
- Agent 不直接依赖具体业务实现细节
这样做有两个直接好处:
- 你的 Service 既能给 HTTP 接口用,也能给 tool 用
- 业务逻辑和 LLM 编排逻辑分层更清楚
如果先用一个内存版 UserService 做过渡,你会发现这个重构方向几乎不需要改 Agent Loop,只是把 tool 的执行体从"直接查对象"改成了"调用 service"。
这一步很重要,因为后面把数据库 CRUD 封装成 tool,本质上就是同样的思路,只是数据源从内存换成了 TypeORM。
把数据库 CRUD 封装成 Tool,Agent 才真的开始接近"能做事"
如果一个 Agent 只能查内存里的 mock 数据,它仍然只是 Demo。真正开始有工程味道,通常发生在它第一次能通过工具读写数据库的时候。
这里我建议直接上 TypeORM:
bash
pnpm install --save @nestjs/typeorm typeorm mysql2
pnpm install class-validator用户实体可以先保持克制,不要一上来建太复杂:
ts
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number;
@Column({ length: 50 })
name: string;
@Column({ length: 50 })
email: string;
@CreateDateColumn({ type: 'timestamp' })
createdAt: Date;
@UpdateDateColumn({ type: 'timestamp' })
updatedAt: Date;
}这个 Entity 的教学价值不在于字段多少,而在于它把后面的三件事串起来了:
- HTTP 接口的常规 CRUD
- TypeORM 对数据库表的映射
- Agent 可调用的
db_users_crud工具
UsersService 则负责真正的数据操作:
ts
@Injectable()
export class UsersService {
@Inject(EntityManager)
entityManager: EntityManager;
create(createUserDto: CreateUserDto) {
return this.entityManager.save(User, createUserDto);
}
findAll() {
return this.entityManager.find(User);
}
findOne(id: number) {
return this.entityManager.findOne(User, { where: { id } });
}
update(id: number, updateUserDto: UpdateUserDto) {
return this.entityManager.update(User, id, updateUserDto);
}
remove(id: number) {
return this.entityManager.delete(User, id);
}
}到了这一步,再把它包装成 db_users_crud tool 就顺理成章了。这个 tool 的意义不只是"让模型也能增删改查",更关键的是它证明了一件事:
Agent 的工具层完全可以复用现有业务服务,而不需要另起一套 AI 专用数据访问逻辑。
这会极大降低你把 AI 能力接入既有系统的成本。
真正的关键:怎么建模"定时任务"
进入正题之后,最容易犯的错误就是直接把"定时任务"理解成 cron expression。这会让你的系统天然偏向开发者视角,而不是用户视角。
从产品语义上看,用户常见的定时需求其实有三类:
- 某个时间点执行一次
- 每隔一段时间重复执行
- 按一个明确的日历规则执行
对应到实现层,最适合的建模就是三种任务类型:
at:在某个具体时间点执行一次every:按固定间隔重复执行cron:按 Cron 表达式重复执行
这是一个很重要的判断:
对大多数 AI Agent 产品来说,
at和every应该是默认能力,cron更适合作为进阶能力,而不是默认入口。
原因很简单。普通用户不会说"请帮我创建一个 0 0 9 * * 1-5 的任务"。他们更可能说:
- 10 分钟后提醒我喝水
- 每小时同步一次库存
- 明天早上 9 点帮我发邮件
这些需求天然更适合 at 和 every。只有当用户明确知道自己在做什么,或者你的系统本来就是面向开发者,cron 才应该成为一等入口。
为什么定时任务一定要持久化
如果任务只存在内存里,那么下面这些能力几乎都做不了:
- 查看任务列表
- 开关任务
- 服务重启后恢复任务
- 追踪最近执行时间
- 给任务增加审计、失败重试和状态管理
因此,真正的产品级方案一定会有一张任务表。
ts
export type JobType = 'cron' | 'every' | 'at';
@Entity()
export class Job {
@PrimaryGeneratedColumn('uuid')
id: string;
@Column({ type: 'text' })
instruction: string;
@Column({ type: 'varchar', length: 10, default: 'cron' })
type: JobType;
@Column({ type: 'varchar', length: 100, nullable: true })
cron: string | null;
@Column({ type: 'int', nullable: true })
everyMs: number | null;
@Column({ type: 'timestamp', nullable: true })
at: Date | null;
@Column({ default: true })
isEnabled: boolean;
@Column({ type: 'timestamp', nullable: true })
lastRun: Date | null;
@CreateDateColumn({ type: 'timestamp' })
createdAt: Date;
@UpdateDateColumn({ type: 'timestamp' })
updatedAt: Date;
}这张表的设计里,最值得注意的是 instruction 字段。
它保存的不是"某个工具调用 JSON",而是未来要执行的自然语言任务。
比如用户说:
明天晚上 10 点提醒我写日报
最终存进去的应该是:
type = atat = 明天 22:00instruction = 提醒我写日报
而不是把整句用户原话原封不动塞进去,更不是提前把它编译成某个具体函数调用。
这是因为未来执行时,真正负责"怎么做"的仍然是 Agent,而不是调度层。
JobService 的职责不是"执行任务",而是"管理运行时"
很多人做到这里,会把业务执行逻辑也塞进 JobService 里。短期能跑,长期会把调度和执行耦合死。
更合理的职责划分是:
JobService:管理任务存储、恢复、启停、运行时注册JobAgentService:真正执行到点后的自然语言指令
先看 JobService 的调度侧逻辑:
ts
async onApplicationBootstrap() {
const enabledJobs = await this.entityManager.find(Job, {
where: { isEnabled: true },
});
for (const job of enabledJobs) {
await this.startRuntime(job);
}
}这一段很短,但它解决了一个非常现实的问题:服务重启之后,已启用任务怎么恢复。
如果没有这一步,你的"定时任务"只是一个活在当前进程生命周期里的假任务。
再看 startRuntime 这个核心方法,它根据任务类型决定注册哪种运行时:
cron对应CronJobevery对应setIntervalat对应setTimeout
也就是说,数据库保存的是统一任务模型,而运行时注册时才映射到底层调度机制。
这层抽象很有价值,因为它让你的上层 Agent 不需要关心底层是 CronJob 还是 setTimeout。上层只需要知道:我创建了一个某类型的任务,它会在未来被触发。
cron_job 这个 Tool,管理的是任务,不是业务动作
如果你前面已经把 query_user、db_users_crud 这类工具做好,接下来最容易犯的错误是:把 cron_job 也写成一个"顺手帮你把事情做了"的工具。
这会造成语义混乱。
正确理解应该是:
db_users_crud是业务工具send_mail是业务工具web_search是业务工具cron_job是调度管理工具
它负责的是:
list:列出任务add:创建任务toggle:启用/停用任务
它不应该在当前轮对话里,把未来才该执行的业务动作提前做掉。
这也是为什么 instruction 字段要设计得很克制。创建任务时,模型必须把用户原始请求拆成两部分:
- 什么时候执行
- 到时要做什么
例如:
1 分钟后给我发一个笑话到邮箱
正确拆法应该是:
- 时间部分:
1 分钟后 - 指令部分:
给我发一个笑话到邮箱
当前轮只做"创建任务"这件事,而不是现在就去发邮件。
这条规则听起来简单,但实际非常重要。否则你会得到一种诡异体验:
- 用户说"明天提醒我喝水"
- 系统现在立刻提醒一次
- 同时明天又提醒一次
这不是"Agent 很智能",而是执行边界没处理清楚。
Prompt 设计,决定了 Agent 会不会把定时任务用错
很多人以为 Scheduler 搭起来就够了,实际上对定时任务这种场景,Prompt 约束非常关键。
你至少要明确三件事:
- 什么时候该选
at - 什么时候该选
every - 创建未来任务时,不要在当前轮直接执行业务动作
一个比较实用的 System Prompt 约束,可以写成类似下面这样:
ts
new SystemMessage(`
你是一个通用任务助手,可以调用 query_user、send_mail、web_search、
db_users_crud、cron_job 等工具。
定时任务类型选择规则:
- "X分钟/小时/天后""明天某个时间点"这类一次性未来任务,使用 cron_job + type=at
- "每X分钟/每小时/每天"这类循环任务,使用 cron_job + type=every
- 用户明确给出 Cron 表达式时,使用 cron_job + type=cron
在创建 cron_job.add 时,instruction 只能保留"未来要做什么"这部分内容,
不能把"什么时候执行"再带进去,也不能在当前轮直接执行这个动作。
`);这段 Prompt 的价值不在于写得多优雅,而在于它把"调度"和"执行"这两个阶段彻底分开了。
从工程角度看,这比单纯优化模型回答语气重要得多。
为什么还需要一个 time_now Tool
如果用户说"10 分钟后提醒我喝水",模型要把它转换成 at 类型任务,就必须知道当前时间。
这时候,如果你只是指望模型"凭空理解现在是什么时间",结果通常不稳定。最稳妥的做法,是明确提供一个获取服务器当前时间的工具。
ts
@Injectable()
export class TimeNowToolService {
readonly tool;
constructor() {
this.tool = tool(
async () => {
const now = new Date();
return {
iso: now.toISOString(),
timestamp: now.getTime(),
};
},
{
name: 'time_now',
description: '获取当前服务器时间。',
},
);
}
}这类工具看起来不起眼,但它能明显提升"相对时间表达"的可用性。对于定时任务场景,它几乎属于必备工具,而不是可选优化。
到点后不要只打印日志,而要重新启动一轮 Agent
如果到这里你只是把任务触发后写成:
ts
this.logger.log(`run job ${job.id}, ${job.instruction}`);那它仍然只是一个"会触发的定时器",还不是一个真正的 Agent 定时任务系统。
真正的关键,在于任务触发时要重新拉起一轮专用的 Agent Loop。
这个执行 Agent 的职责很纯粹:
- 接收一段
instruction - 绑定业务工具
- 让模型自己决定调用哪些工具完成任务
- 输出执行结果
实现上可以单独抽一个 JobAgentService:
ts
@Injectable()
export class JobAgentService {
private readonly modelWithTools: Runnable<BaseMessage[], AIMessage>;
constructor(
@Inject('CHAT_MODEL') model: ChatOpenAI,
@Inject('SEND_MAIL_TOOL') private readonly sendMailTool: any,
@Inject('WEB_SEARCH_TOOL') private readonly webSearchTool: any,
@Inject('DB_USERS_CRUD_TOOL') private readonly dbUsersCrudTool: any,
@Inject('TIME_NOW_TOOL') private readonly timeNowTool: any,
) {
this.modelWithTools = model.bindTools([
this.sendMailTool,
this.webSearchTool,
this.dbUsersCrudTool,
this.timeNowTool,
]);
}
async runJob(instruction: string): Promise<string> {
const messages: BaseMessage[] = [
new SystemMessage('你是一个用于执行后台任务的智能代理。'),
new HumanMessage(instruction),
];
while (true) {
const aiMessage = await this.modelWithTools.invoke(messages);
messages.push(aiMessage);
const toolCalls = aiMessage.tool_calls ?? [];
if (!toolCalls.length) {
return String(aiMessage.content ?? '');
}
// 分发工具调用并把 ToolMessage 回填给模型
}
}
}这里有一个非常重要的边界控制:
执行 Agent 不应该再注入 cron_job 本身。
否则你可能会得到递归任务生成:
- 一个任务到点后
- 执行 Agent 又创建了新的定时任务
- 新任务再触发后继续生成新任务
除非你的产品明确需要这种能力,并且做了额外约束,否则默认最好禁止。
从模块设计上看,Tool 应该被抽成独立层
当系统开始同时服务"实时对话 Agent"和"后台任务 Agent"时,最好把工具层单独抽成一个模块。
例如:
LlmService负责模型实例SendMailToolService负责邮件工具WebSearchToolService负责搜索工具DbUsersCrudToolService负责数据库 CRUD 工具TimeNowToolService负责当前时间工具CronJobToolService负责任务管理工具
这样做有两个直接收益:
- 业务工具可以在多个 Agent 之间共享
- 你可以非常清楚地控制"哪些工具暴露给哪个 Agent"
比如:
- 对话 Agent:可以注入
cron_job - 后台任务 Agent:不注入
cron_job
这种差异化暴露,在复杂系统里会非常常见。工具不是越多越好,而是要和 Agent 的职责边界匹配。
一次完整链路,到底是怎么跑起来的
把前面的模块拼起来之后,一条完整请求的执行路径会是这样:
用户输入:
明天上午 9 点,搜索一下最近的 AI Agent 新闻,如果有值得关注的更新,就发邮件告诉我。
系统内部执行:
- 对话 Agent 理解这是一个未来执行任务
- 它不会立刻调用
web_search或send_mail - 它会调用
cron_job.add - 保存任务:
type=atat=明天 09:00instruction=搜索一下最近的 AI Agent 新闻,如果有值得关注的更新,就发邮件告诉我 - 到第二天 9 点,调度器触发任务
JobAgentService读取instruction- 执行 Agent 先调用
web_search - 根据结果判断是否需要
send_mail - 最终完成这一轮任务,并更新
lastRun
这条链路和"定时调用某个 API"最大的区别在于:未来真正执行什么,是到触发时才由 Agent 决定的。
这才是 Agent 定时任务比传统 Cron 更有价值的地方。
这套方案里最容易踩的几个坑
1. 把定时任务写成"当前轮直接执行"
这是最常见的错误。用户说"明天提醒我",系统却现在先执行一遍,说明你没有把"创建任务"和"执行任务"分开。
2. 把 instruction 存成工具调用代码
比如存成 send_mail({...})、db_users_crud({...}) 这种形式。短期看似方便,长期会让任务失去灵活性,也会让系统更难升级。
更稳妥的方式,是存自然语言任务描述,把执行权留给未来的 Agent。
3. 只支持 Cron,不支持 at / every
这通常是从后端工程师视角出发的设计,而不是从产品语义出发。大多数用户根本不会直接给你 Cron 表达式。
4. 任务只保存在内存里
只要服务一重启,任务就没了。这类系统做 Demo 可以,做产品不行。
5. 执行 Agent 可以再次无限创建定时任务
如果不做边界隔离,系统可能出现自我复制式任务膨胀。默认应该禁止执行 Agent 再使用 cron_job,除非你明确需要递归调度能力。
6. 忽略时区和时间语义
"明天早上 9 点"这种表达,实际一定涉及时区。你的服务器时区、数据库时区、用户时区如果没统一,任务执行时间很容易错位。
工程上还可以继续增强什么
如果你准备把这套方案真正推向生产环境,我建议至少继续补这几个能力:
- 失败重试:任务执行失败后是否重试、重试几次、间隔多久
- 幂等控制:同一任务重复触发时怎么避免重复副作用
- 执行日志:记录每次任务触发时的输入、工具调用、结果和错误
- 权限边界:不同用户能创建什么任务、能调用哪些工具
- 任务审计:谁创建的、什么时候创建的、什么时候停用的
- 并发控制:同一任务未完成时,下一次周期触发是否允许并发执行
- 任务结果通知:执行完成后是写日志、写数据库,还是反向通知用户
尤其是并发控制,经常会被低估。比如一个 every 1 minute 的任务,如果单次执行需要 90 秒,就会出现重叠执行问题。这个在 AI Agent 场景里尤其常见,因为模型调用和外部工具调用都可能拉长链路耗时。
一个实用的选型判断
如果你只是做教学 Demo,最小方案可以是:
- 内存任务表
setTimeout / setInterval- 简单 tool 调用
但如果你要做一个稍微像样一点的 Agent 应用,我更推荐的默认方案是:
- 用数据库持久化任务
- 用
at / every / cron三种类型抽象任务语义 - 用专门的
cron_jobtool 管理任务,而不是混进业务工具里 - 到点后重新启动一轮 Agent Loop,而不是直接调用某个固定函数
这套方案的好处是,你并没有为了"支持定时任务"而破坏 Agent 本身的开放式执行能力。调度层只是负责"未来触发",真正的业务决策仍然交给 Agent 和 tool 体系完成。
这才是它最有工程价值的地方。
总结
OpenClaw 式的定时任务,关键不在于用了哪一个 Scheduler,也不在于是不是支持 Cron 表达式,而在于你有没有把这件事想清楚:
未来被调度的对象,不应该是某个写死的函数,而应该是一段未来重新交给 Agent 执行的任务意图。
一旦接受这个设计,很多实现细节都会顺理成章:
- 为什么任务要持久化到数据库
- 为什么
instruction应该保存自然语言而不是工具代码 - 为什么要区分
at / every / cron - 为什么当前轮只创建任务,不立刻执行
- 为什么到点后要重新跑一轮 Agent Loop
从教学 Demo 到真实产品,中间最重要的一步,往往不是"工具再多一点",而是把调度、执行、持久化和 Agent 编排这几层边界真正理顺。
如果你正在做 Agent 系统,这一类"未来执行"的能力,值得一开始就按这个方向搭,而不是等系统长复杂了,再从一堆硬编码回调里往回重构。