引言:算力碎片化与"95% 开发成本"的困局
在推进企业智能化升级的道路上,我们常遇到一个令人头疼的"算力拼图"难题:客户的硬件环境往往是"万国牌"的。总部机房可能是标准的 x86 + NVIDIA GPU 集群,而分布在各地的边缘厂区却使用着基于 ARM 架构的华为 Atlas、瑞芯微或算能边缘盒子。传统的视频分析系统,往往被绑定在特定的驱动和指令集上,导致为了兼容不同芯片,不得不维护多套代码分支,甚至部署多套独立系统。
这种底层硬件适配的重复劳动,直接吞噬了企业约 95% 的研发预算,却无法产生任何业务增值。
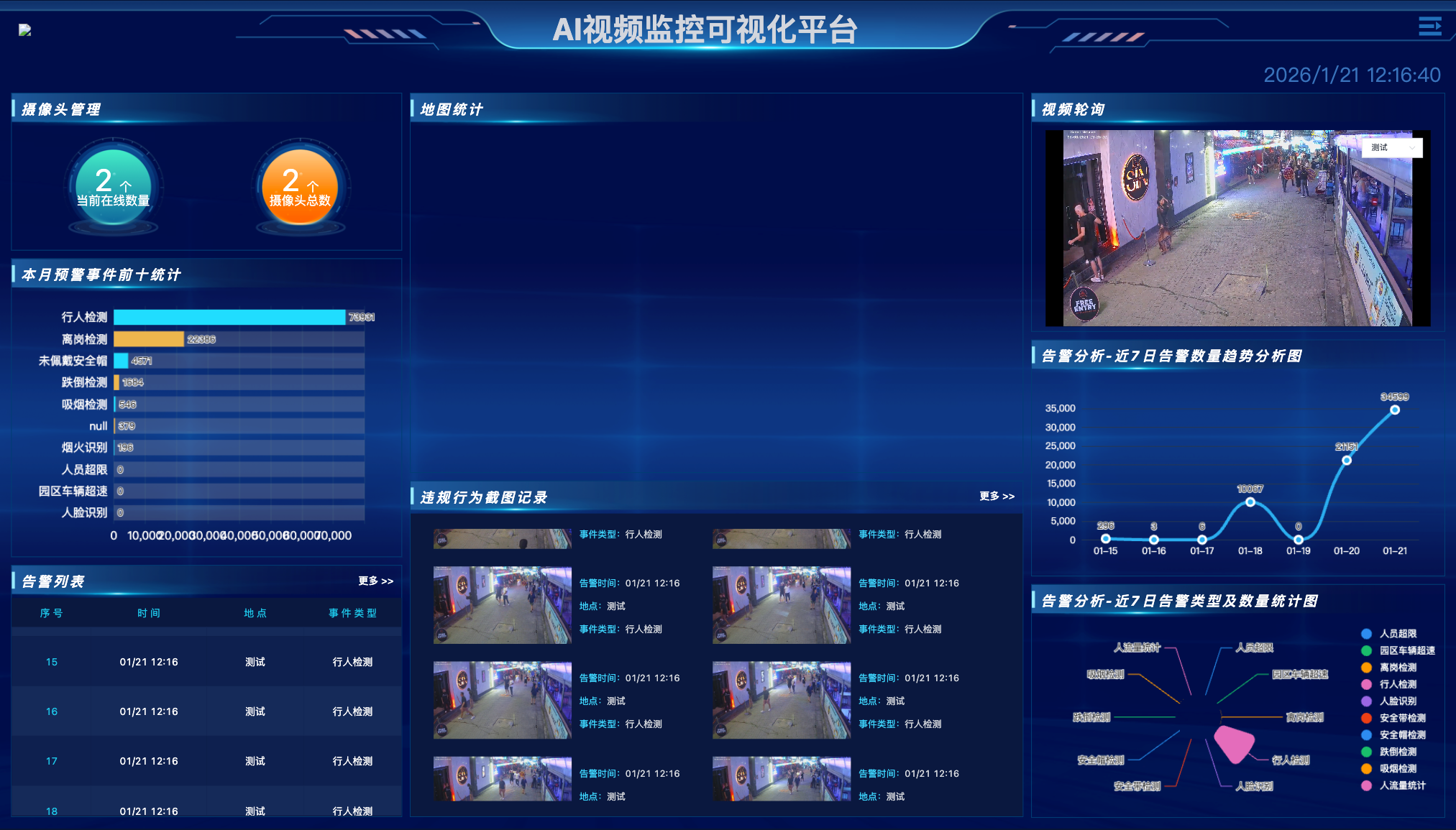
今天,我们将深入剖析 YiheCode Server 的架构设计。这套系统通过"软硬解耦"的微服务架构,实现了从 x86 到 ARM、从 GPU 到 NPU 的全场景覆盖,真正做到了"一套代码,到处运行"。
一、 核心底座:基于容器化与微服务的架构解耦
YiheCode Server 的架构设计哲学在于"分层隔离"。它将业务逻辑与硬件驱动进行了彻底的剥离。
- 后端架构 :基于 Spring Boot 2.7 开发,保证了业务层的高稳定性和跨平台性。
- 部署模式 :采用 Docker 容器化部署,配合 Docker-Compose 进行服务编排。这意味着 Java 后端服务不直接依赖宿主机的操作系统环境,从而天然具备了在 x86 和 ARM 服务器间无缝迁移的能力。
架构拓扑图解:
text
+-------------------------------------------------------+
| 业务应用层 (Vue 2.6) |
| (运行在任意浏览器/终端,与硬件无关) |
+-----------------------+-------------------------------+
|
+-----------------------v-------------------------------+
| 服务网关层 (Spring Boot) |
| (容器化部署,逻辑处理,不涉及视频编解码) |
+-----------------------+-------------------------------+
| (信令/控制)
+-----------+-----------v-----------+-------------------+
| | | |
| +--------v--------+ +----------v-----------+ |
| | x86/ARM 服务器 | | 边缘 NPU/ GPU 节点 | |
| | (Docker Host) | | (算法推理/流媒体处理) | |
| | | | | |
| | ZLMediaKit Node | | 算法盒子 1 (ARM) | |
| | (流媒体分发) | | 算法盒子 2 (x86) | |
| | | | ... (异构芯片) | |
| +-----------------+ +-------------------+ |
+-------------------------------------------------------+二、 深度解析:如何实现 X86 与 ARM 的双模兼容
文档中提到的"全硬件适配",在技术实现上主要依赖于对底层 C++ 组件的差异化打包与调度。
2.1 操作系统与指令集兼容
平台支持 x86 和 ARM 指令集。对于 Java/Spring Boot 编写的后端服务,只需编译一次,即可在两种架构的服务器上通过 Docker 运行。难点在于流媒体和算法依赖的底层库(如 FFmpeg、OpenCV)。
解决方案 :
平台通过维护两套 Docker 镜像:
- X86 镜像:预装针对 Intel/AMD 优化的硬件编解码库。
- ARM 镜像:预装针对国产化芯片(如飞腾、鲲鹏、瑞芯微)优化的软硬编解码库。
2.2 异构计算资源池化 (GPU/NPU)
这是架构设计中最精彩的部分。YiheCode 并没有将算法写死在某一种芯片上,而是设计了一个"边缘计算管理"模块。
- 资源注册:边缘盒子(无论搭载的是 NVIDIA GPU、算能 BM1684 还是其他 NPU)启动后,会向中心注册其算力信息。
- 任务调度 :中心平台根据盒子的芯片类型(
chip_type)和在线状态,动态下发对应的算法模型(.bmodel,.engine等)。
伪代码演示:边缘节点注册逻辑
java
// 边缘盒子心跳上报
@PostMapping("/box/heartbeat")
public void reportStatus(@RequestBody BoxStatus status) {
// 1. 识别硬件指纹
String chipType = status.getChipInfo(); // e.g., "BM1684", "NVIDIA_Jetson"
String osArch = status.getOsArch(); // e.g., "aarch64", "amd64"
// 2. 根据指纹匹配可用算法
List<Algorithm> availableAlgos = algorithmService
.findByChipAndArch(chipType, osArch);
// 3. 下发待执行任务 (Pull 模式)
mediaNodeService.assignTasks(status.getBoxId(), availableAlgos);
}三、 边缘推流与流媒体集群的高可用设计
针对边缘网络环境复杂(如厂区网络不稳定)的问题,架构设计了灵活的**"边缘推流 + 中心分发"机制。
3.1 智能流转策略
根据边缘节点的硬件性能和网络状况,系统自动选择最优的流媒体传输模式:
| 传输模式 | 适用硬件/场景 | 技术原理 |
|---|---|---|
| 中心拉流 (Pull) | 高性能 x86 服务器 | 中心 ZLMediaKit 节点主动通过 RTSP 拉取 IPC 视频流,适合内网环境 |
| 边缘推流 (Push) | 低算力 ARM 边缘盒 | 边缘端解码后,主动将视频帧推送到中心 RTMP 服务器,解决 NAT 穿透和多播跨网段问题 |
| 国标级联 | 政务/大型园区 | 基于 SIP 协议的设备级联,符合 GB28181 标准 |
3.2 ZLMediaKit 流媒体集群
平台集成了高性能的 ZLMediaKit 框架。在异构部署中,ZLM 节点可以独立部署在拥有 GPU 硬件编码能力的服务器上,负责转码和分发;也可以部署在普通 ARM 服务器上,仅负责信令交互和简单的流媒体转发。
四、 总结
YiheCode Server 通过"容器化后端 + 插件化边缘代理"的架构,完美解决了安防行业最大的痛点------硬件碎片化 。
它不仅是一个视频播放器,更是一个异构计算调度器 。对于寻求私有化部署 的企业,这套架构省去了繁琐的环境配置过程;对于需要国产化替代的项目,它提供了从 x86 平滑过渡到 ARM 的路径。通过将硬件适配工作封装在边缘层,让企业的研发团队能够专注于上层业务逻辑,真正实现文档中所述的"减少约 95% 的开发成本"。
如果你正在寻找一套能够兼容老旧设备、支持多品牌 NPU 并具备高扩展性的视频底座,这套源码级的解决方案值得你深入研究。
架构师建议 :
在部署大规模异构集群时,建议将 ZLMediaKit 流媒体节点 与 Java 业务节点 物理分离。对于 ARM 边缘盒子,务必在 Dockerfile 中指定对应的 ARM 基础镜像(如
arm64v8/openjdk),并确保 NPU 驱动已正确挂载到容器内。