一、树
1.**树的概念与结构 **
树是一种非线性的数据结构 ,它是由 n(n ≥ 0) 个有限结点组成的、具有层次关系的集合。
- 当
n = 0时,称为空树。 - 当
n > 0时,有且仅有一个特殊结点,称为根结点Root。除根结点外,其余结点可分为m(m ≥ 0)个互不相交 的有限集合,每个集合本身又是一棵树,称为根的子树 - ⼦树是不相交的
- 除了根结点外,每个结点有且仅有⼀个⽗结点
- ⼀棵
N个结点的树有N-1条边
2.树的相关术语
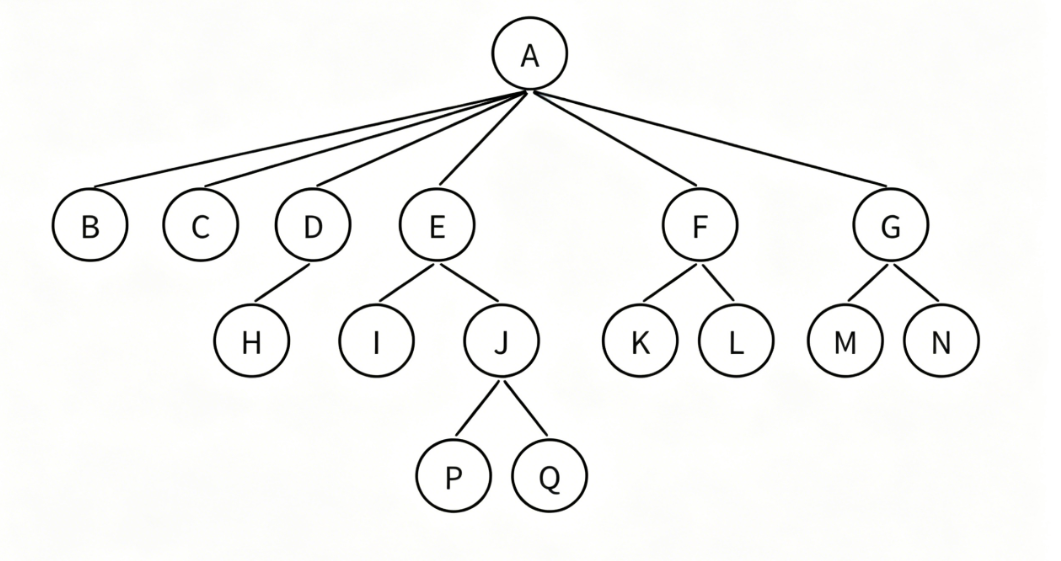
- 父节点/双亲结点:若一个结点含有子结点,则这个结点称为其子结点的父节点,如A 是 B、C、D、E、F、G 的父结点
- 子结点/孩子结点:一个结点含有子树的根节点,称为该结点的子结点,如B、C、D、E、F、G 是 A 的孩子结点
- 兄弟结点:具有相同父结点的结点,互称为兄弟结点(亲兄弟),如B、C、D、E、F、G 互为兄弟(父结点都是 A)
- 结点的度:一个结点拥有的子结点数量,就是该结点的度,如A 的度 = 6(有 6 个孩子:B/C/D/E/F/G)
- 树的度:一棵树中,所有结点的度的最大值,就是树的度 ,如A 的度是 6,是全树最大的,因此这棵树的度
= 6 - 叶子结点 / 终端结点:度为 0 的结点(没有子结点的结点),如B、C、H、I、K、L、M、N、P、Q,共 10 个叶子结点
- 分支结点 / 非终端结点:度不为 0 的结点(有子结点的结点),如A、D、E、F、G、J,共 6 个分支结点
- 结点的层次:从根结点开始计数,根为第 1 层,根的子结点为第 2 层,以此类推 ,如
第 1 层:A,第 2 层:B、C、D、E、F、G,第 3 层:H、I、J、K、L、M、N,第 4 层:P、Q - 树的高度 / 深度:树中结点的最大层次数 ,如最大层次是 4(P、Q 在第 4 层),因此树的高度
= 4 - 结点的祖先:从根结点到该结点,路径上经过的所有结点,都是该结点的祖先,如Q 的祖先:A、E、J,H 的祖先:A、D
- 子孙结点:以某结点为根的子树中,任意结点都称为该结点的子孙,如E 的子孙:I、J、P、Q
- 路径:从树中任意结点出发,沿「父结点→子结点」的连接,到达另一结点的结点序列,如A 到 Q 的路径:A → E → J → Q
- 森林:由
m(m>0)棵互不相交的树组成的集合,称为森林 ,简单来说就是把一棵树的根结点删掉,剩下的子树集合就是一个森林(比如删掉 A,剩下 B、C、D 为根的子树,就是一个森林
3. 树的表示方法
3.1 双亲表示法
核心思想:
用数组 存储所有节点,每个节点只记录自己的值和父节点的下标
优点:查找父节点极快(O (1))
缺点:查找子节点需要遍历整个数组
适用:只需要快速找父节点的场景
双亲表示法结点结构
c
// 双亲表示法 节点结构
typedef struct PTNode{
// 节点数据
int data;
// 父节点在数组中的下标,根节点为 -1
int parent;
} PTNode;3.2 孩子表示法
核心思想:
用数组 存所有节点,每个节点带一个链表 ,存储所有子节点的下标
优点:查找子节点极快
缺点:查找父节点需要遍历
适用:文件目录、多叉树
孩子链表的节点
c
// 孩子链表的节点(存子节点下标)
typedef struct ChildNode {
int index; // 子节点在数组中的下标
struct ChildNode *next; // 下一个子节点
} ChildNode;3.3 双亲孩子表示法
核心思想:
孩子表示法和每个节点记录父节点下标
优点:找父、找子都极快
缺点:结构稍复杂
适用:需要双向查找的树
双亲孩子表示法的结点
c
typedef struct PCTNode{
int data;
int parent; // 父节点下标
ChildNode *first;
} PCTNode;3.4 孩子兄弟表示法
核心思想:
任意树转化为二叉树 ,每个节点只存两个指针:
firstChild:指向第一个子节点
nextSibling:指向右边的兄弟节点
优点:所有树都能转二叉树,代码极简
缺点:理解稍难
适用:二叉树、红黑树、B 树、文件系统
结点结构
c
typedef struct CSNode {
int data;
struct CSNode *firstChild; // 第一个子节点
struct CSNode *nextSibling; // 右兄弟节点
} CSNode;3.5 二叉树专用表示法
二叉树是度最多为 2的树,结构最简单、用途最广
结点结构
c
// 二叉树节点
typedef struct BiTNode {
int data;
struct BiTNode *lchild, *rchild; // 左、右孩子
} BiTNode;| | |
| 表示法 | 存储结构 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 双亲表示法 | 数组 | 找父极快 | 找子慢 | 并查集 |
| 孩子表示法 | 数组 + 链表 | 找子极快 | 找父慢 | 文件目录 |
| 双亲孩子 | 数组 + 链表 | 父子都快 | 结构复杂 | 通用树 |
| 孩子兄弟 | 纯链表 | 万能,转二叉树 | 理解稍难 | 所有树、二叉树、红黑树 |
二、二叉树
1.概念与结构
-
定义:二叉树是每个节点最多有两个子节点的树形结构
-
两个子节点分别称为:左孩子
left child右孩子right child -
特点:子树有左右之分,顺序不能随意交换
可以是空树 ,每个节点度
≤ 2
2. 特殊二叉树
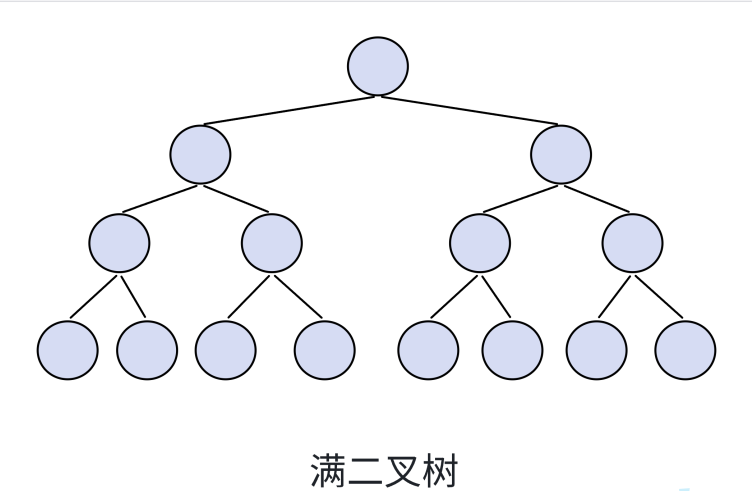
2.1 满二叉树
- 每一层节点都达到最大值
- 所有叶子结点都在最底层加粗样式
- 高度
h,节点总数 =2^h -1
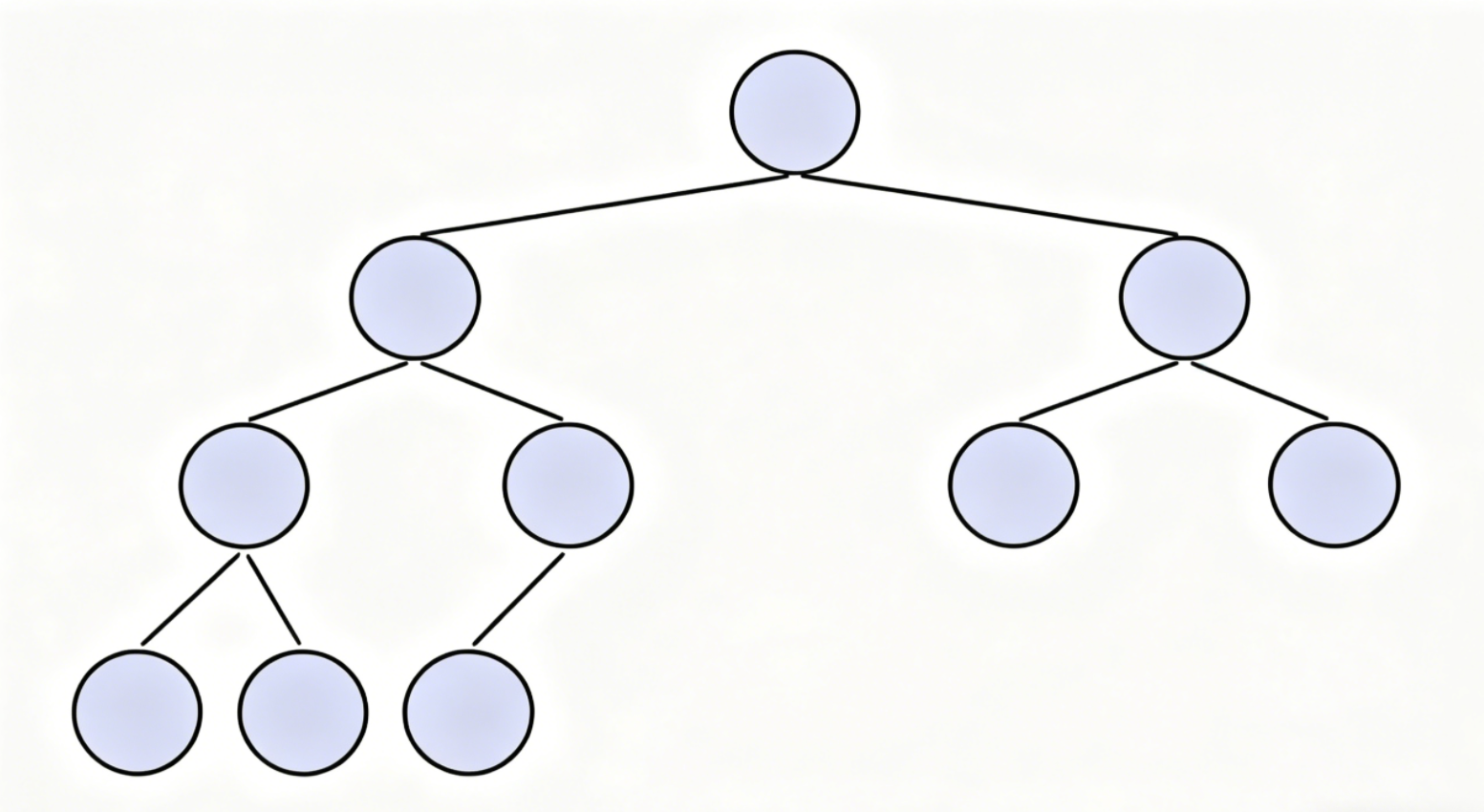
2.2 完全二叉树
- 除最后一层外,其他层节点都满
- 最后一层节点靠左连续排列
3.二叉树性质
根据满⼆叉树的特点可知:
- 若规定根结点的层数为
1,则⼀棵⾮空⼆叉树的第i层上最多 有2i−1个结点 - 若规定根结点的层数为
1,则深度为 h 的⼆叉树的最⼤结点数 是2h − 1 - 若规定根结点的层数为
1,具有 n 个结点的满⼆叉树的深度h = log(n+1)( log以2为底, n+1 为对数)
4.二叉树的存储结构
⼆叉树⼀般可以使⽤两种结构存储,⼀种顺序结构 ,⼀种链式结构
4.1 顺序结构
二叉树的顺序存储结构 是指采用数组 对二叉树进行存储。该存储方式仅适用于完全二叉树 ;若用于存储非完全二叉树,会因数组中产生大量空闲位置导致存储空间严重浪费,因此完全二叉树是最适合采用顺序存储的二叉树类型。
在实际应用中,堆(数据结构中的堆) 通常采用数组实现顺序存储 。需要明确区分:数据结构中的堆是一种特殊的完全二叉树结构,与操作系统虚拟进程地址空间中用于动态内存分配的堆区是两个完全不同的概念,二者不可混淆。
4.2 链式结构
二叉树的链式存储结构 是通过链表来表示一棵二叉树,利用链表指针反映节点之间的逻辑层次关系。通常情况下,链表中的每个节点包含三个域:一个数据域和两个指针域 。其中,数据域用于存储节点数据;两个指针域分别用于存储指向该节点左孩子和右孩子的节点地址。
三、顺序结构二叉树--堆
⼀般堆使⽤顺序结构的数组来存储数据,堆是⼀种特殊的⼆叉树,具有⼆叉树的特性的同时,还具备其他的特性
1.堆的基本概念
堆是一种完全二叉树结构 的优先队列,不是内存里的堆内存
2.堆必须同时满足两个条件
结构条件:是一棵完全二叉树
堆序性质:父节点与子节点满足大小关系(大根堆 / 小根堆)
3.堆的两种类型
3.1 大根堆(最大堆 Max Heap)
根节点值最大 ,任意父节点 ≥ 左右孩子,节点从上到下递减
3.2 小根堆(最小堆 Min Heap)
根节点值最小,任意父节点 ≤ 左右孩子,节点从上到下递增
注意:堆不要求左右子树有序,只要求父子有序
4.二叉树的性质
对于具有 n 个结点的完全⼆叉树,如果按照从上⾄下从左⾄右的数组顺序对所有结点从0 开始编号,则对于序号为 i 的结点有:
- 若
i>0,i位置结点的双亲序号:(i-1)/2;i=0,i为根结点编号,⽆双亲结点 - 若
2i+1<n,左孩⼦序号:2i+1,2i+1>=n否则⽆左孩⼦ - 若
2i+2<n,右孩⼦序号:2i+2,2i+2>=n否则⽆右孩⼦