摘要:
GLIGEN 是面向开放集定位式文生图 的创新方法,基于冻结权重的预训练 latent diffusion 模型 构建,通过门控自注意力机制 新增可训练层注入边界框、关键点、深度图 等多模态定位条件,在完全保留原模型概念知识的前提下实现精准空间可控生成;
介绍:
虽然现在文生图模型取得了很大的进步,但现存的大规模文本-图像生成模型不能以文本以外的其他输入形式为条件,因此缺乏精确定位概念、使用参考图像或其他条件输入来控制生成过程的能力。当前的输入,即自然语言本身,限制了信息的表达方式。例如,很难使用文本来描述对象的精确位置,而如果使用边界框/关键点等就可以很容易地实现这一点。
此外,先前的生成模型都是在特定任务的数据集上独立训练的,但在图像识别领域,使用大规模数据集预训练已经成为经典做法。文章想借鉴这种做法,在已经训练好的扩散模型上进行续训,赋予他们新的输入。
于是,本文的方法被提出,在保留文本标题作为输入之外,也支持其他输入模式如:边界框,参考图像关键点等。为了保留已经训练好的扩散模型已有的知识,作者选择冻结原始模型权重,并添加新的可训练门控Transformer层,这些层接收新的输入。
Open-set Grounded Image Generation
作者保留了扩散模型的文本编码器,保证开集,没训练过的也能生成。文本编码器除了对基础实体的语义信息编码外,还会对后加入的信息进行编码。
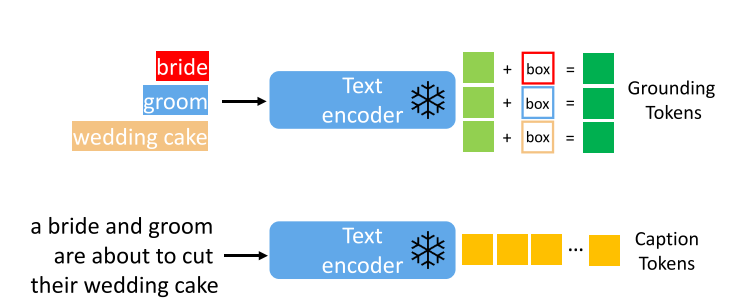
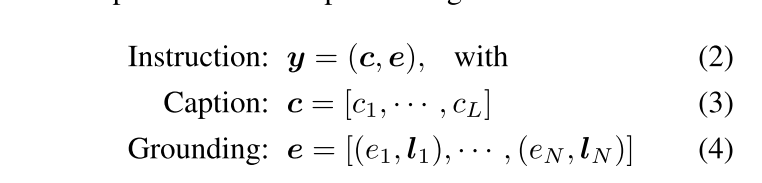
其中,c代表基础实体的语义信息,e代表所有要定位的物体列表,其中的e1--eN是物体描述,l代表该物体的位置信息。组合成为模型输入的文本信息。e中位置信息的处理方式为边界框坐标做傅里叶编码;
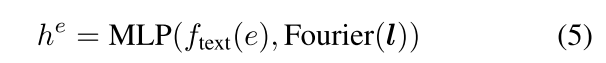
模型的损失函数变化不大,总体宗旨是**:让模型(原模型不动,只训新加的定位层),根据'文本 + 定位信息',预测出和真实噪声几乎一样的噪声,这样生成的图片又准又清晰,** 其中所有新参数表示为θ'。
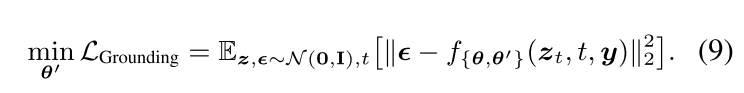
Continual Learning for Grounded Generation
为了保留模型已有的知识,在不调整模型已有权重的基础上,在两层注意力机制之间加入一个新的门控Transformer层。
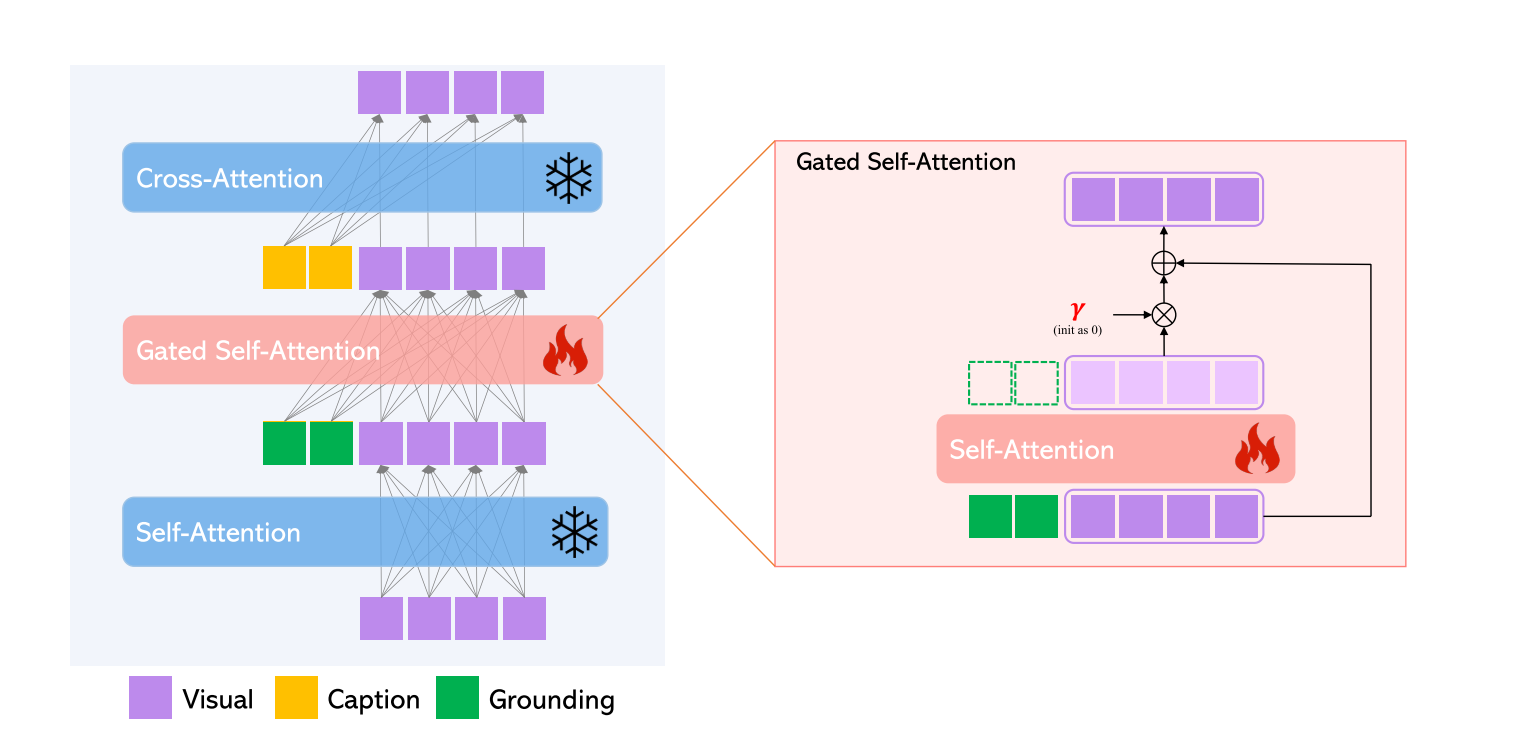
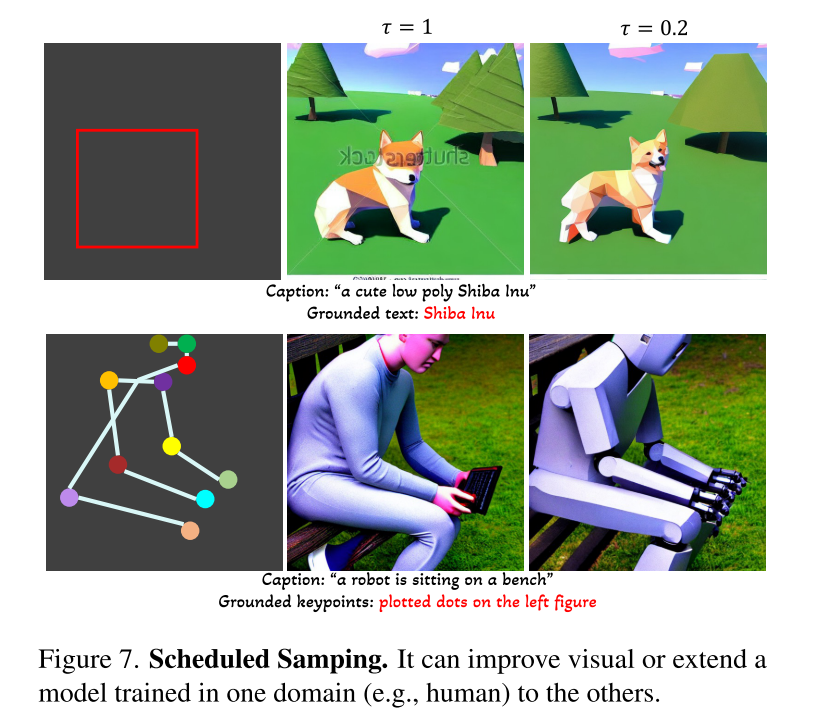
原本的模型结果如公式6,7;现加入新的一层,具体实现如公式8,其中TS是仅考虑视觉token的token选择操作,而γ是初始化为0的可学习标量。在整个训练过程中,β被设置为1,并且仅在推理期间的计划抽样时改变,也就是在这个阶段,额外加入的文本和位置信息被注入模型:
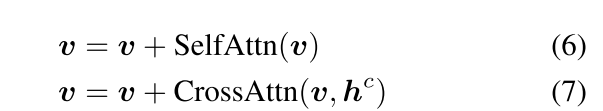
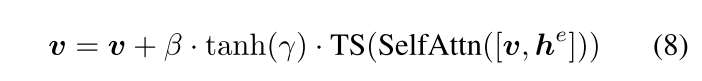
计划抽样就是为了解决定位准但画质差问题,让模型分两段生成,第一阶段β设为1,让物体的位置信息与文本信息被模型接收,让模型定位并确定物体的信息;定位结束之后,β设为0,让模型退化为原本的扩散模型,让模型画得更精细;
实验:
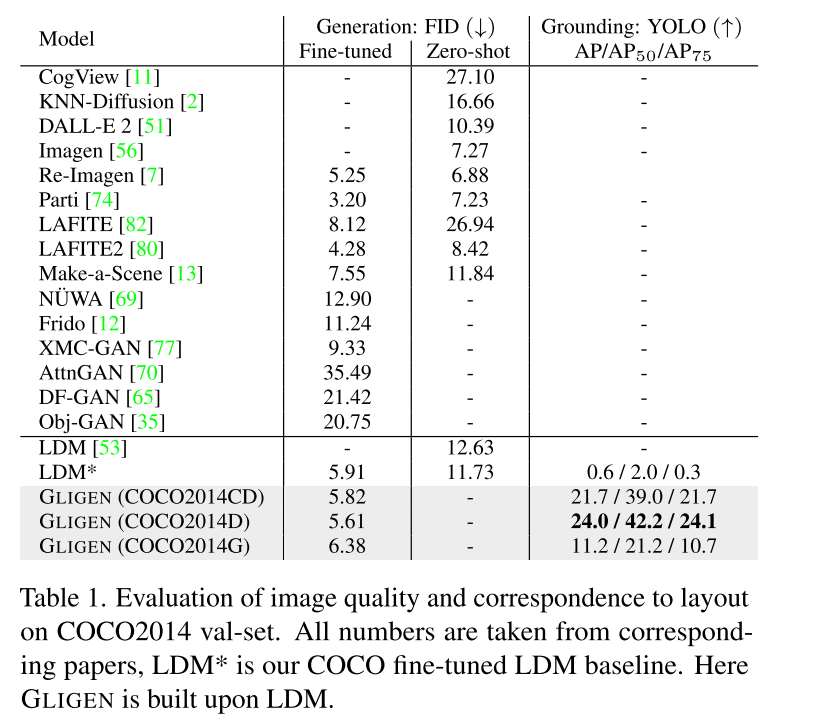
闭集文生图
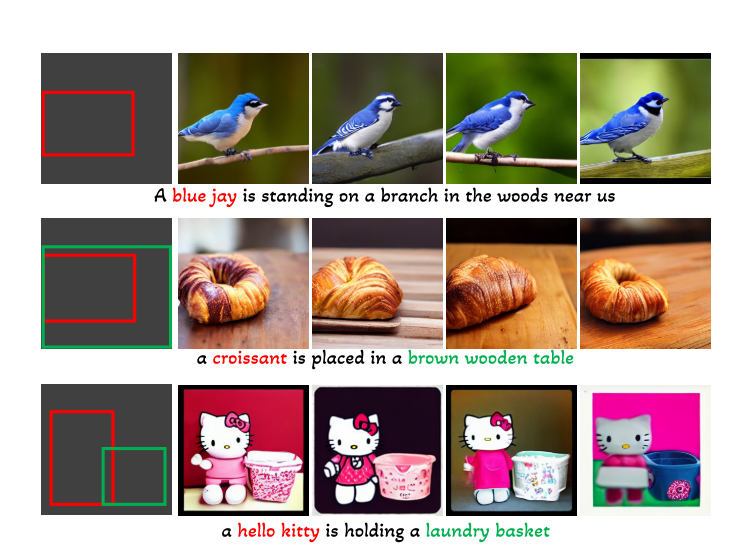
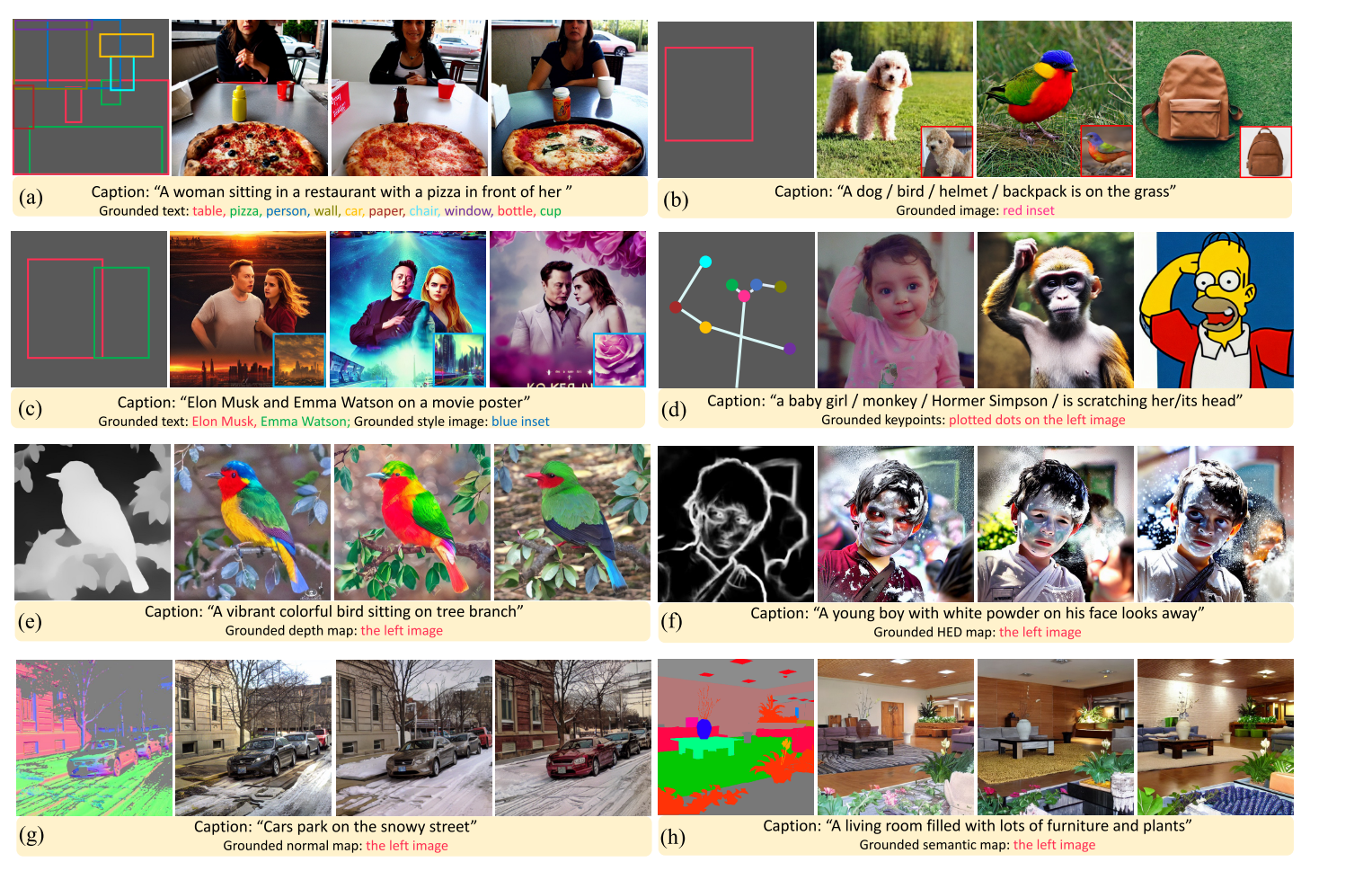
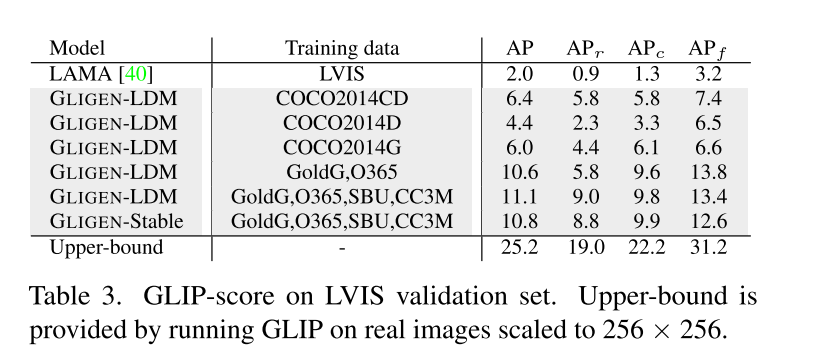
开集文生图
计划抽样的作用(τ=1时不启用)