一、BILSTM、BILSTM_CRF介绍
BiLSTM 和 BiLSTM-CRF 都是 NLP(自然语言处理)里处理序列数据的经典模型,主要用来做序列标注(给句子里的每个词打标签)。
1.1BiLSTM 模型(双向长短期记忆网络)
作用: 提取上下文特征,理解词语在句子中的语义。
结构:由两个 LSTM组成
前向 LSTM:从左到右读句子,捕捉过去的信息
后向 LSTM:从右到左读句子,捕捉未来的信息
输出:把两个方向的结果拼接,得到完整上下文表示

核心优势
解决传统 RNN 的梯度消失问题,能记住长距离依赖
双向理解,能判断歧义(如 "苹果" 是水果还是公司)
缺点
只能独立预测每个词的标签,不考虑标签之间的逻辑约束
容易输出非法序列(如:人名中间突然接地名开头)
1.2BiLSTM-CRF 模型(BiLSTM + 条件随机场)
作用: 在 BiLSTM 基础上,保证标签序列的合法性,是序列标注(NER)的黄金标准。
结构
Embedding 层:词→向量
BiLSTM 层:提取上下文特征
全连接层:输出每个词对应各标签的发射分数
CRF 层:
学习标签转移矩阵(如:B-PER → I-PER 概率高,B-PER → B-LOC 概率低)
用Viterbi 算法找出全局最优、合法的标签序列
核心优势
BiLSTM:强大的上下文语义提取
CRF:强制标签符合语法规则,杜绝非法序列
比纯 BiLSTM准确率更高、结果更合理
1.3两者对比
BiLSTM:只看单个词,不管前后标签是否合理
BiLSTM-CRF:全局看整个句子,保证标签连贯合法
1.4典型应用场景
命名实体识别(NER):识别人名、地名、机构名
例:B-PER李I-PER明O在B-LOC北I-LOC京
词性标注(POS):给每个词标词性(名词、动词等)
分词 / 语义角色标注
总结:BiLSTM 是基础特征提取器,BiLSTM-CRF 是工业界最常用、效果最好的序列标注模型。这个项目我们使用BILSTM作为基线模型,BILSTM_CRF作为项目使用的序列标注模型。
二、CRF介绍
第六章中我们详细介绍了BILSTM模型,这里我详细介绍一下CRF模型
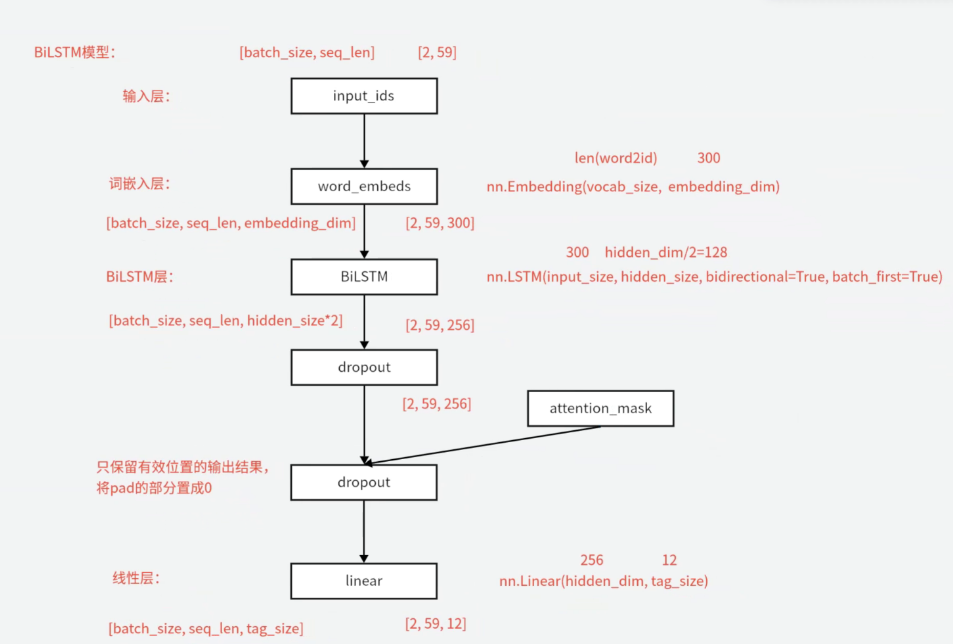
线性层的输出:(D*num_laycrs,seq_len,tag_size)
CRF接收的数据类型分为训练、测试
- 训练时候的输入:线性层的输出、mask、真实标签
- 测试时候的输入:线性层的输出、mask
mask的作用:因为神经网络同一批次的数据要求长度相同,所以需要使用mask把补齐序列使用的无效字符转换为0,避免影响到预测结果。
训练CRF模型的时候最重要的是计算损失(先使用CRF得出预测标签,再和真实标签计算损失)
CRF的输出:(D*num_layces,seq_len)+预测的标签序列
三、BiLSTM模型预测序列
BiLSTM_CRF.py
pip install TorchCRF
import torch
import torch.nn as nn
from TorchCRF import CRF
from P03_NER.LSTM_CRF.config import Config
from P03_NER.LSTM_CRF.utils.data_loader import word2id, get_data
class NERLSTM_CRF(nn.Module):
def __init__(self, embedding_dim, hidden_dim, tag2id, word2id, dropout=0.2):
'''
模型初始化
:param embedding_dim: 嵌入层维度 300
:param hidden_dim: BiLSTM输出时的维度
:param tag2id: tag2id字典
:param word2id: word2id字典
:param dropout: 随机失活比例
'''
super(NERLSTM_CRF, self).__init__()
self.name = "BiLSTM_CRF"
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.tag_size = len(tag2id)
self.vocab_size = len(word2id)
# 词嵌入层
self.embedding = nn.Embedding(self.vocab_size, self.embedding_dim)
# BiLSTM层
self.lstm = nn.LSTM(input_size=self.embedding_dim, hidden_size=self.hidden_dim//2, bidirectional=True, batch_first=True)
# 随机失活
self.dropout = nn.Dropout(dropout)
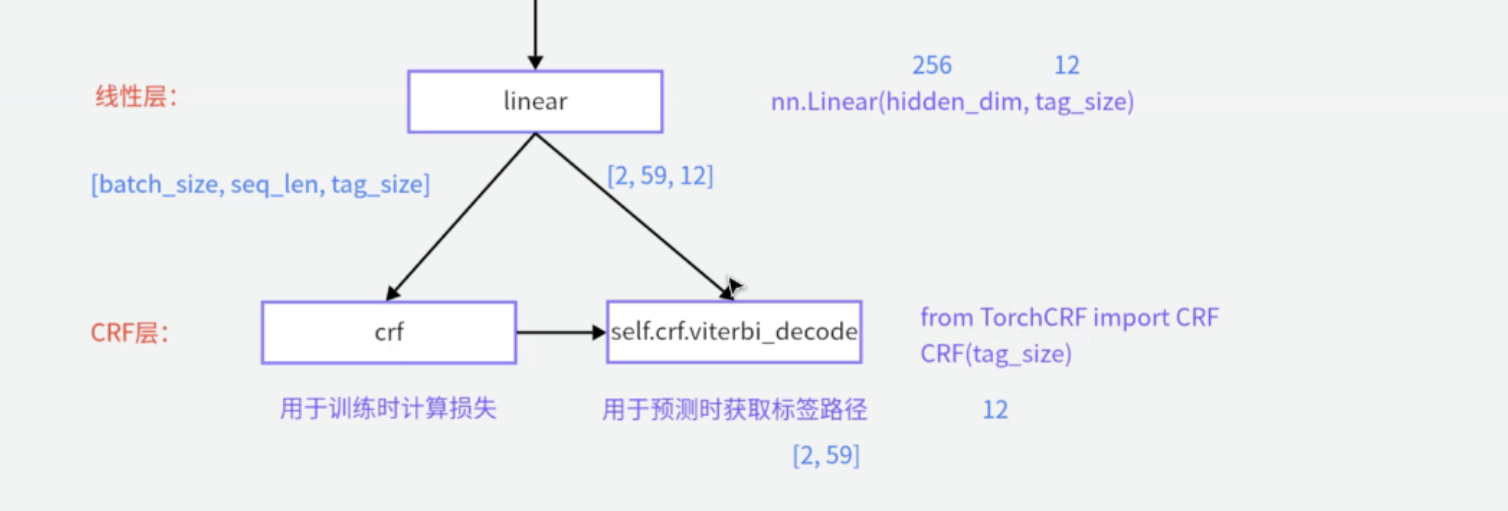
# 线性层
self.hidden2tag = nn.Linear(self.hidden_dim, self.tag_size)
# CRF层
self.crf = CRF(self.tag_size)
def get_emission_score(self, input_ids, attention_mask):
# print(f'input_ids: {input_ids.shape}')
# print(f'attention_mask: {attention_mask.shape}')
# 送入词嵌入层
word_embeds = self.embedding(input_ids)
# 送入BiLSTM层
lstm_out, _ = self.lstm(word_embeds)
# 送入随机失活层
dropout_out = self.dropout(lstm_out)
# print(f'dropout_out: {dropout_out.shape}')
# 对位相乘,只保留有效位置的输出结果,将pad的部分置成0
attention_mask = attention_mask.unsqueeze(-1)
multi_out = dropout_out * attention_mask # 自动广播并相乘
# print(f'multi_out: {multi_out.shape}')
# 送入线性层
final_out = self.hidden2tag(multi_out)
return final_out
# 使用forward方法实现预测
def forward(self, input_ids, attention_mask):
# 获取发射得分
emission_score = self.get_emission_score(input_ids, attention_mask)
# 使用viterbi解码获取标签路径
predict_result = self.crf.viterbi_decode(emission_score, attention_mask)
return predict_result
# 计算损失的函数
def log_likelihood(self, input_ids, labels, attention_mask):
# 获取发射得分
emission_score = self.get_emission_score(input_ids, attention_mask)
# 计算损失【将发射分数、真实标签、attention_mask直接输入给模型,就可以得到对数似然损失,加上负号就可以得到真正的需求求解的损失函数】
loss = - self.crf(emission_score, labels, attention_mask.bool())
return loss
if __name__ == '__main__':
conf = Config()
model = NERLSTM_CRF(conf.embedding_dim, conf.hidden_dim, conf.tag2id, word2id, conf.dropout)
print(model)
train_dataloader, val_dataloader = get_data()
for input_ids, labels, attention_mask in train_dataloader:
result = model(input_ids, attention_mask)
print(f'result: {result}')
# 计算损失
loss = model.log_likelihood(input_ids, labels, attention_mask)
print(f'loss: {loss}')
break执行结果:每个字符预测的标签对应的id;
可以很明显的发现预测的序列长度是不一样的,这是因为mask把之前补齐的长度变成了无效长度,帮助BILSTM只预测有效的标签。