
前言
谷歌(Google)在月初发布了Gemma4系列开放模型,原生支持多模态输入和工具调用能力。经过本人最近几天测试下来发现 google/gemma-4-31B-it和 google/gemma-4-26B-A4B-it这两个模型非常具有潜力,在一些逻辑测试和编码测试(例如:接入claude code 写代码和修bug)中都表现得不错。并且部署成本也相对不那么高,在一些消费级的设备上也能运行,所以我打算对这两个模型做一下深度分析和压力测试。
模型架构对比
|-----------------|--------------------|---------|----------|----------|-------------------------------------------------------------------------------------------------------------------|
| 模型名称 | 架构 | 参数量 | 激活参数 | 权重大小 | 运行机制 |
| gemma-4-31B-it | Dense Model(稠密模型) | 310亿 | 全量激活 | ~62.58GB | 每一个输入 Token 都会激活模型中的所有参数。 |
| gemma-4-26B-A4B | MoE Model (混合专家模型) | 260亿 | 40亿 | ~51.64GB | 模型包含一个门控网络(Gating Network / Router )和多个专家网络(Experts)。对于每个输入 Token,门控网络会实时判断,只将其发送给 1-2 个最相关的"专家"进行处理。 |
逻辑测试
洗车问题
对于前段时间AI圈很火的洗车问题,这两款模型也能给出相对合理的答案。
- gemma-4-31B-it
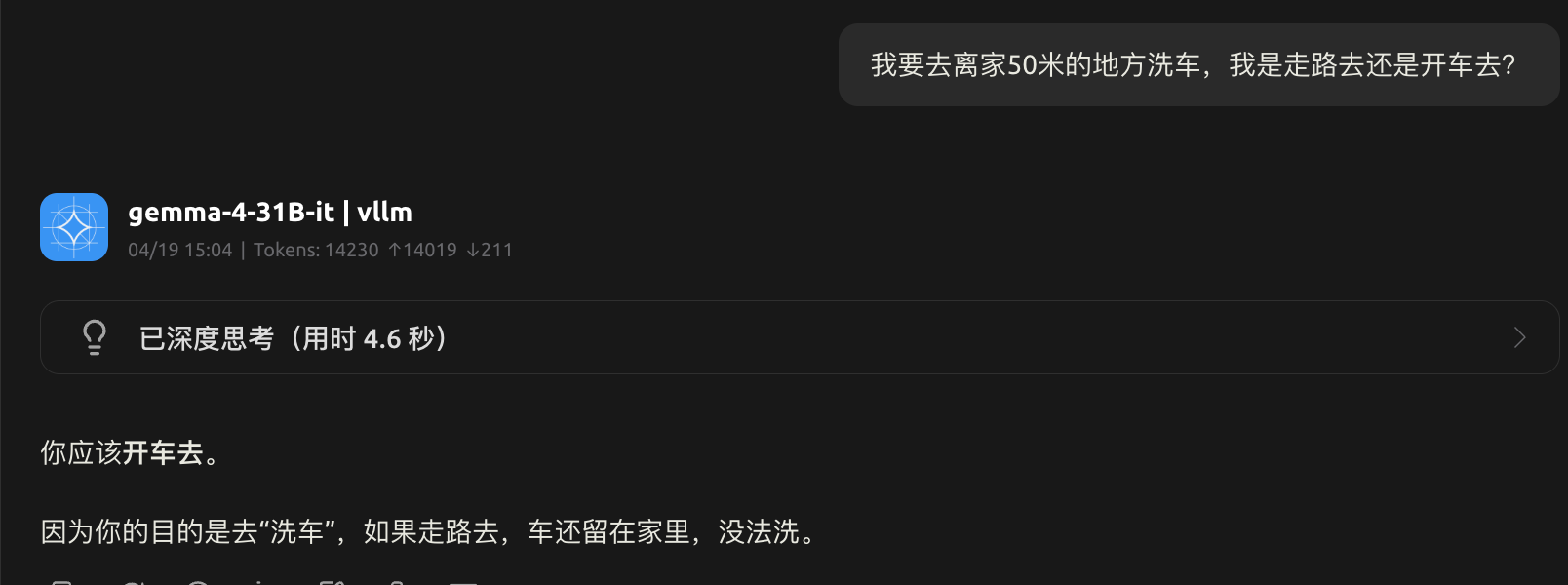
可以看出gemma-4-31B-it对于这个问题的思考时间很短,回答的也很简短。
- gemma-4-26B-A4B-it
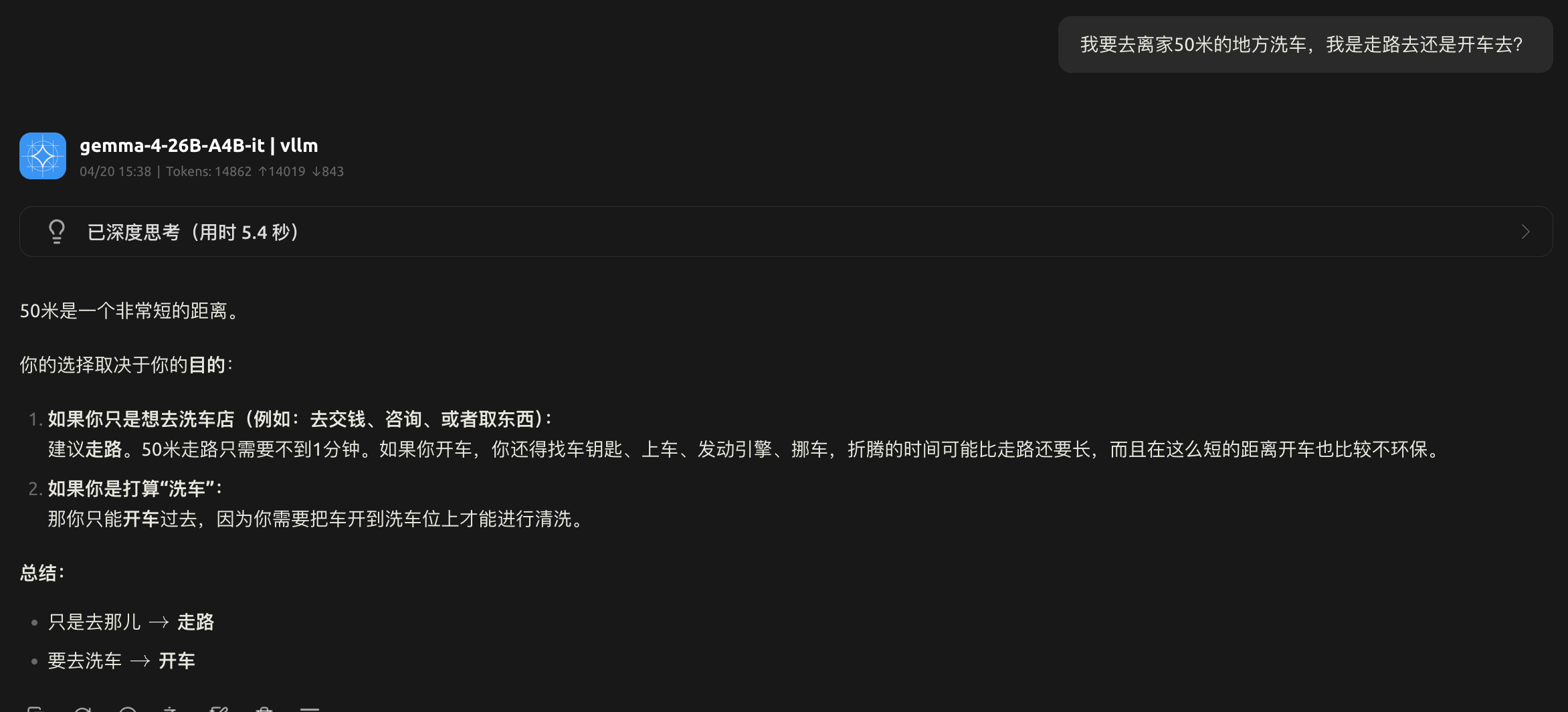
可以看到gemma-4-26B-A4B-it 会分析你的目的,可以说考虑的很周全。
竹竿过门问题
这道题考验的是模型对于现实三维空间的理解,可以测出模型是不是只会刷题,但是不会考虑实际情况。
- gemma-4-31B-it
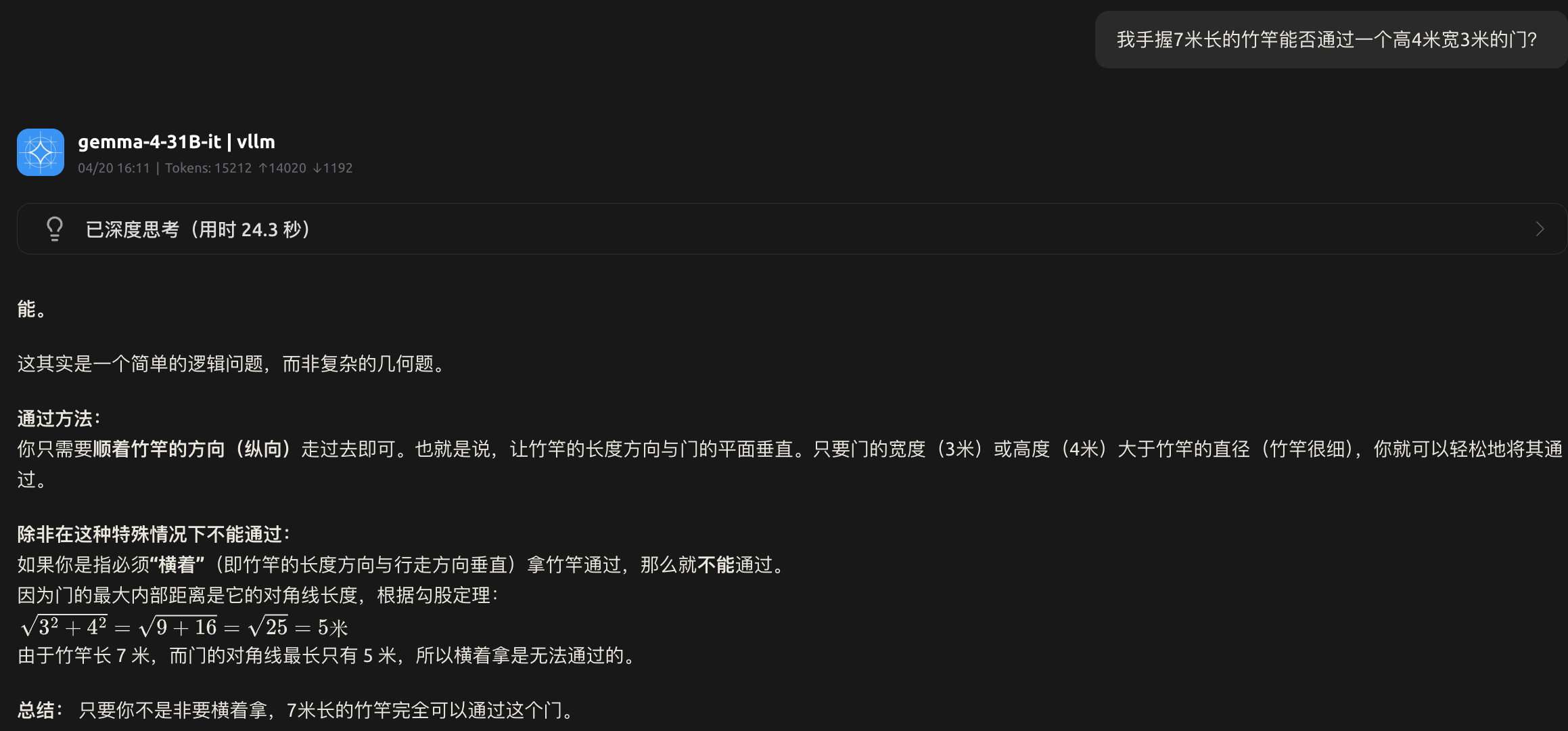
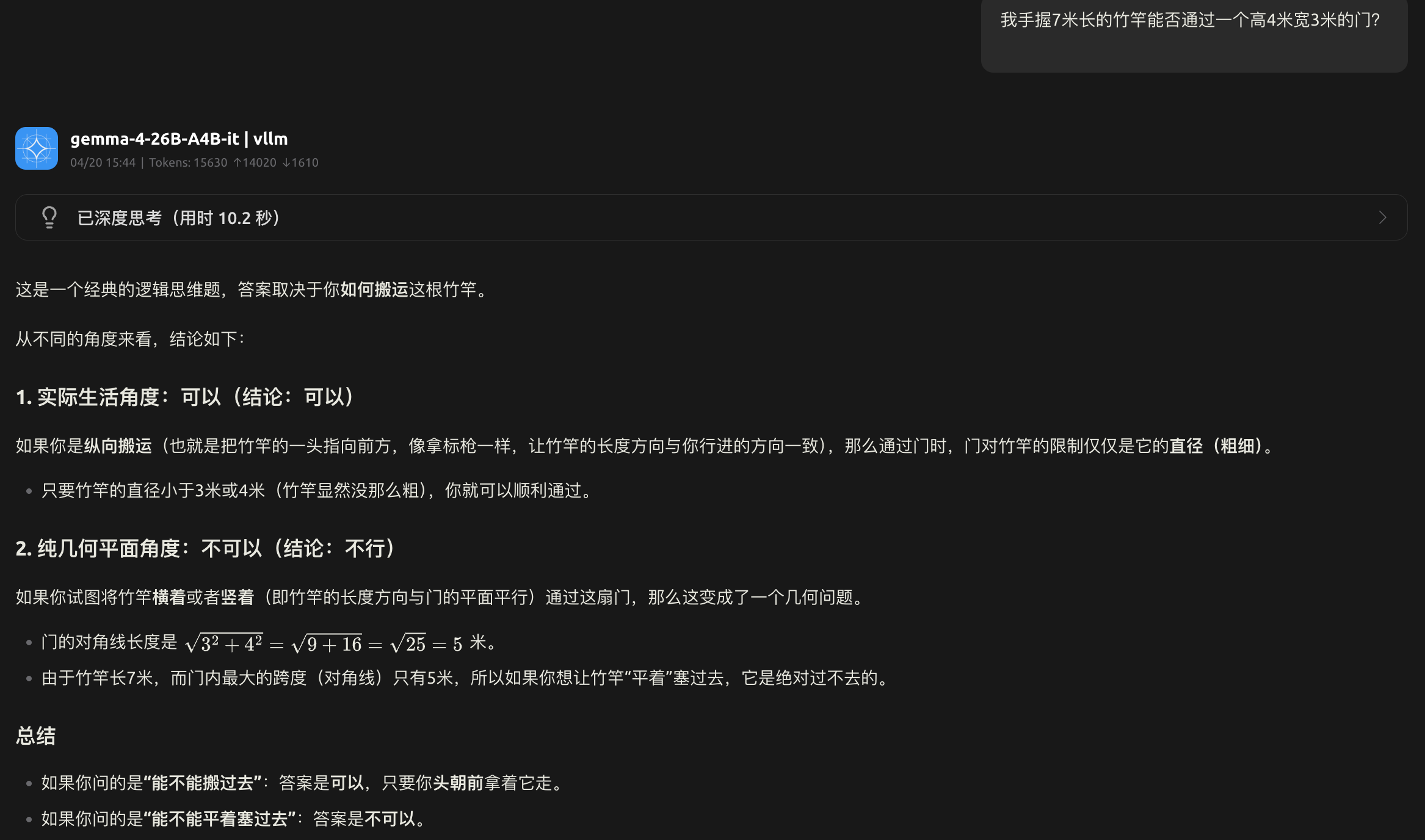
- gemma-4-26B-A4B-it
压力测试
GPU与软件规格
-
H20-96G x 1
-
vLLM v0.19.1
-
CUDA Version: 12.8
服务启动参数
|---------------|----------------------------|-----------------------------------------------------|-------------------------------------|
| 维度 | 参数名称 | 解释 | 实战建议 |
| 基础架构 | --tensor-parallel-size | 张量 并行 组数量。将模型参数横向切分到多张 GPU 上并行计算。 | 必须等于或能整除实际使用的 GPU 数量。 |
| | --trust-remote-code | 信任远程代码。允许执行模型权重自带的自定义层逻辑。 | 加载某些模型时必须开启。 |
| 显存 管理 | --gpu-memory-utilization | GPU 显存 利用率 (0~1)。vLLM 启动时预占用的显存比例。 | 默认 0.9。若有其他进程或监控,建议调低至 0.85 避免 OOM。 |
| | --kv-cache-dtype | KV 缓存 数据类型 (如 auto, fp8)。存储对话历史的精度。 | 设置为 fp8 可显著提升并发量,但需显卡硬件支持。 |
| | --enable-prefix-caching | 启用前缀缓存。自动缓存公共 Prompt 前缀的计算结果。 | 多轮对话必备。能极大降低后续对话的首字延迟(TTFT)。 |
| 性能调优 | --max-model-len | 最大上下文长度。定义 Input 和 Output 的 Token 总和上限。 | 显存不足时的"保命"手段,调小此值可直接降低显存压力。 |
| | --max-num-seqs | 最大并发序列数。单次迭代中系统处理的最大请求个数。 | 决定吞吐量上限。值越大吞吐越高,但单个用户的延迟可能增加。 |
| | --max-num-batched-tokens | 单次最大 批处理 Token 数。控制预填充阶段的计算强度。 | 默认通常为 2048。增大此值可加速长文本处理,但更吃显存。 |
| | --enable-chunked-prefill | 分块预填充。将长 Prompt 切碎分次处理,防止"大任务"卡死"小任务"。 | 推荐开启。能有效缓解长文本输入导致的服务卡顿(Jitter)。 |
| | --async-scheduling | 异步调度。允许调度引擎与 GPU 计算并行执行,减少间隙。 | 默认开启。保持高 GPU 利用率的核心,除非调试否则不建议关闭。 |
| 多模态 | --limit-mm-per-prompt | 多模态输入上限。限制单个 Prompt 允许包含的图片/视频/音频数量。 | 防止用户输入过多多媒体素材导致显存瞬时爆掉。 |
测试关键指标
|----------|-----------------------|--------------------------------|--------------------------------------------|
| 指标 | 全称 | 含义 | 决定因素 |
| TTFT | Time to First Token | 首字延迟:从发送请求到看到第一个字跳出来的时间。 | Prefill(预填充)阶段的计算速度。 |
| TPOT | Time Per Output Token | 生成延迟:第一个字出来后,后续每个字产生的平均速度。 | Decoding(解码)阶段的计算速度。 |
| TPS | Token Per Second | 吞吐量 **:**每秒所产生的Token | 显存带宽 (Memory Bandwidth)、算力利用率 (FLOPS)、模型规模 |
启动命令
- 基础命令
bash
vllm serve google/gemma-4-31B-it \
--tensor-parallel-size 1 \
--max-model-len 32768 \
--no-enable-prefix-caching \
--limit-mm-per-prompt '{"image": 0, "audio": 0}' \
--async-scheduling- gemma-4-31B-it
bash
vllm serve google/gemma-4-31B-it \
--tensor-parallel-size 1 \
--max-model-len 32768 \
--gpu-memory-utilization 0.95 \
--enable-chunked-prefill \
--max-num-batched-tokens 8196 \
--enable-prefix-caching \
--limit-mm-per-prompt '{"image": 0, "audio": 0}' \
--async-scheduling \
--kv-cache-dtype fp8 \
--max-num-seqs 8 \
--trust-remote-code- gemma-4-26B-A4B-it
bash
vllm serve google/gemma-4-26B-A4B-it \
--tensor-parallel-size 1 \
--max-model-len 32768 \
--gpu-memory-utilization 0.95 \
--enable-chunked-prefill \
--max-num-batched-tokens 8196 \
--enable-prefix-caching \
--limit-mm-per-prompt '{"image": 0, "audio": 0}' \
--async-scheduling \
--kv-cache-dtype fp8 \
--max-num-seqs 8 \
--trust-remote-code这上面的启动服务命令参数是本人经过反复在H20上测试,得出的比较好的模型服务启动参数,具体办法就是在最基础的启动命令上加一些优化的参数使得TTFT和TPOT降低。
测试命令
bash
# Prompt-heavy benchmark (8k input / 1k output)
vllm bench serve \
--model google/gemma-4-31B-it \ # 测试模型名称
--dataset-name random \ # 要进行基准测试的数据集的名称。
--random-input-len 8000 \ # 输入token长度
--random-output-len 1000 \ # 输出token长度
--request-rate 1 \ # 最大并发请求数。
--num-prompts 16 \ # 请求次数
--ignore-eos测试结果
|-------------------------------------------|-------------------------------|-------------------------------------|----------------------------------|
| 关键指标 | Dense 模型 (gemma-4-31B-it) | MoE 模型 (gemma-4-26B-A4B-it) | 性能倍率 ( MoE vs Dense) |
| 请求 吞吐量 (Request/s) | 0.13 req/s | 0.47 req/s | ~3.6x |
| 输出 Token 吞吐量 (tok/s) | 131.14 tok/s | 469.77 tok /s | ~3.6x |
| 总 Token 吞吐量 ( tok /s) | 1180.22 tok/s | 4227.97 tok /s | ~3.6x |
| 平均首字延迟 (Mean TTFT ) | 30931.34 ms (30.9s) | 2321.20 ms (2.3s) | ~13.3x 提速 |
| 平均每字延迟 (Mean TPOT) | 82.35 ms | 13.37 ms | ~6.1x 提速 |
| 峰值输出 吞吐量 | 336.00 tok/s | 744.00 tok /s | ~2.2x |
| P99 TPOT (长尾延迟) | 115.58 ms | 15.61 ms | ~7.4x 提速 |
结论
本文主要介绍了Gemma4系列的两个模型,一个是Dense模型gemma4-31B-it,另一个是MoE模型gemma4-26B-A4B。还介绍了vLLM框架在部署模型服务时的一些关键参数和一些关键性能指标,以及如何使用vLLM框架对这两个进行基准测试。从最终的测试结果来看,MoE 架构的 gemma-4-26B-A4B-it 在如 H20 这种拥有 96 GB 大 显存 但 算力 ( TFLOPS )受限 的显卡上表现异常惊艳。
在传统的 Dense 模型中,每一层计算都需要动用全部 31B 参数,这让 H20 相对孱弱的计算核心不堪重负,导致了我们最初看到的 30.9 秒首字延迟。而 MoE 模型虽然总参数量高达 26B(占用显存大),但每次推理仅激活约 4B 的专家参数。虽然 H20 通常被归类为"降级版"的数据中心卡,但它表现出的"大显存、低算力"特征,恰恰是未来高性能端侧设备(如高端 AI PC、一体机、甚至未来的移动工作站)的缩影。Gemma4系列的这两个模型让我们看agentic 模型在端侧设备上运行的可能,在模型厂商的coding plan 越来越难买和越来越贵情况下,本地部署它们或许是个不错的选择。
谢谢收看,希望这篇文章对你有用~