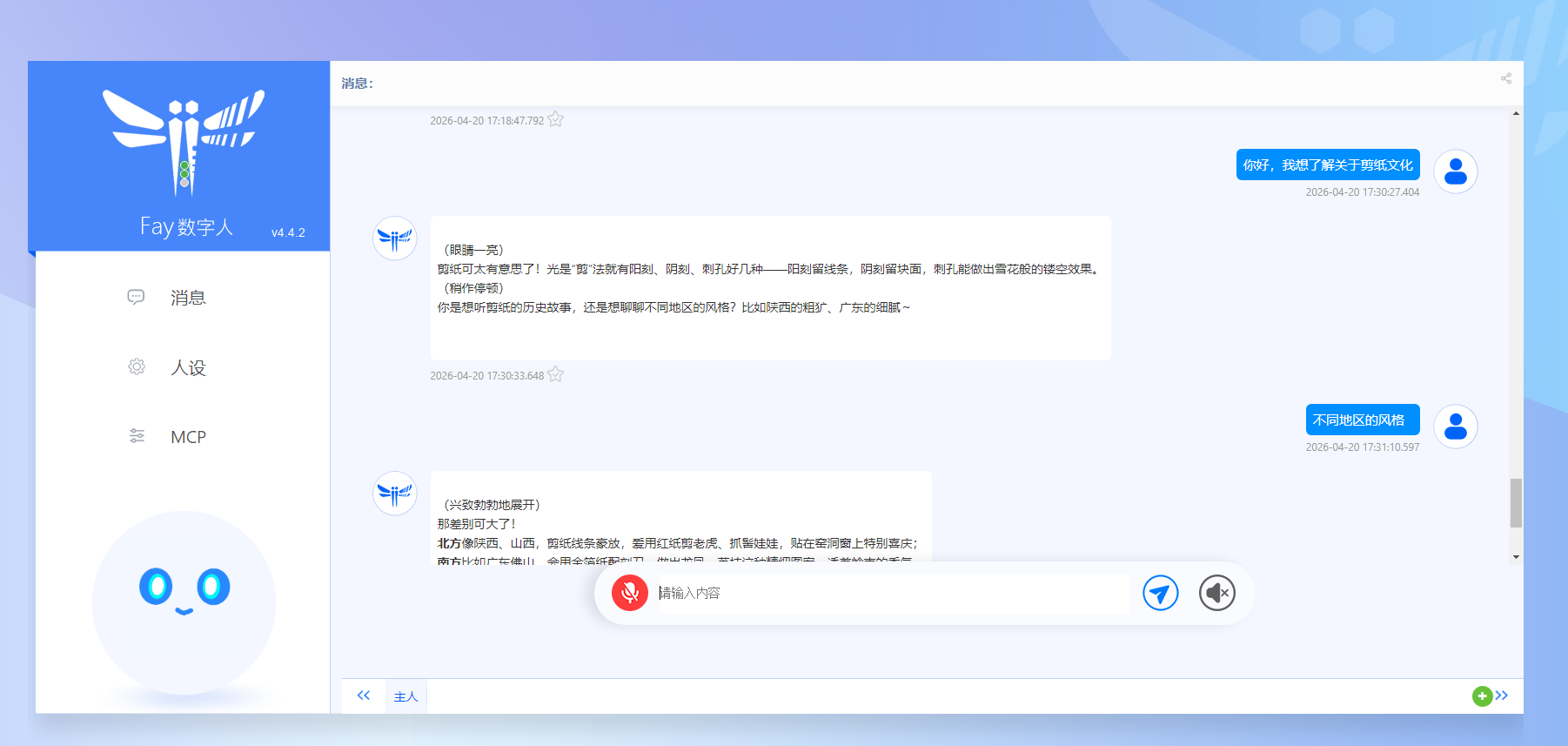
历时三天终于部署成功fay且更换了数字人形象,对此做一个复盘总结。
成果展示

1.到Fay的Gitee仓库克隆源码
以下是官方教程的步骤:
# 1. 克隆 Fay 源码
bashgit clone https://gitee.com/xszyou/fay.git cd fay
# 2. 配置 system.conf
# 如果没有 system.conf,从备份创建: cp system.conf.bak system.conf
# 然后编辑 system.conf,填入 LLM 地址和 Key
# 3. 创建虚拟环境并安装依赖
bashpython -m venv venv venv\Scripts\activate
# Windows
bashpip install -r requirements.txt
# 4. 启动 Fay python main.py # 启动后: # - Web控制面板自动打开 # - WebSocket 服务监听 ws://127.0.0.1:10002 # - 在控制面板配置 TTS 和 LLM
运行后端时控制面板显示websocket连接上:10003,和官方文档不一致,这个不用担心,只要web端连接10002和前端一致就好,最重要的是config文件。
下载好之后打开fay,找到system.conf文件,打开
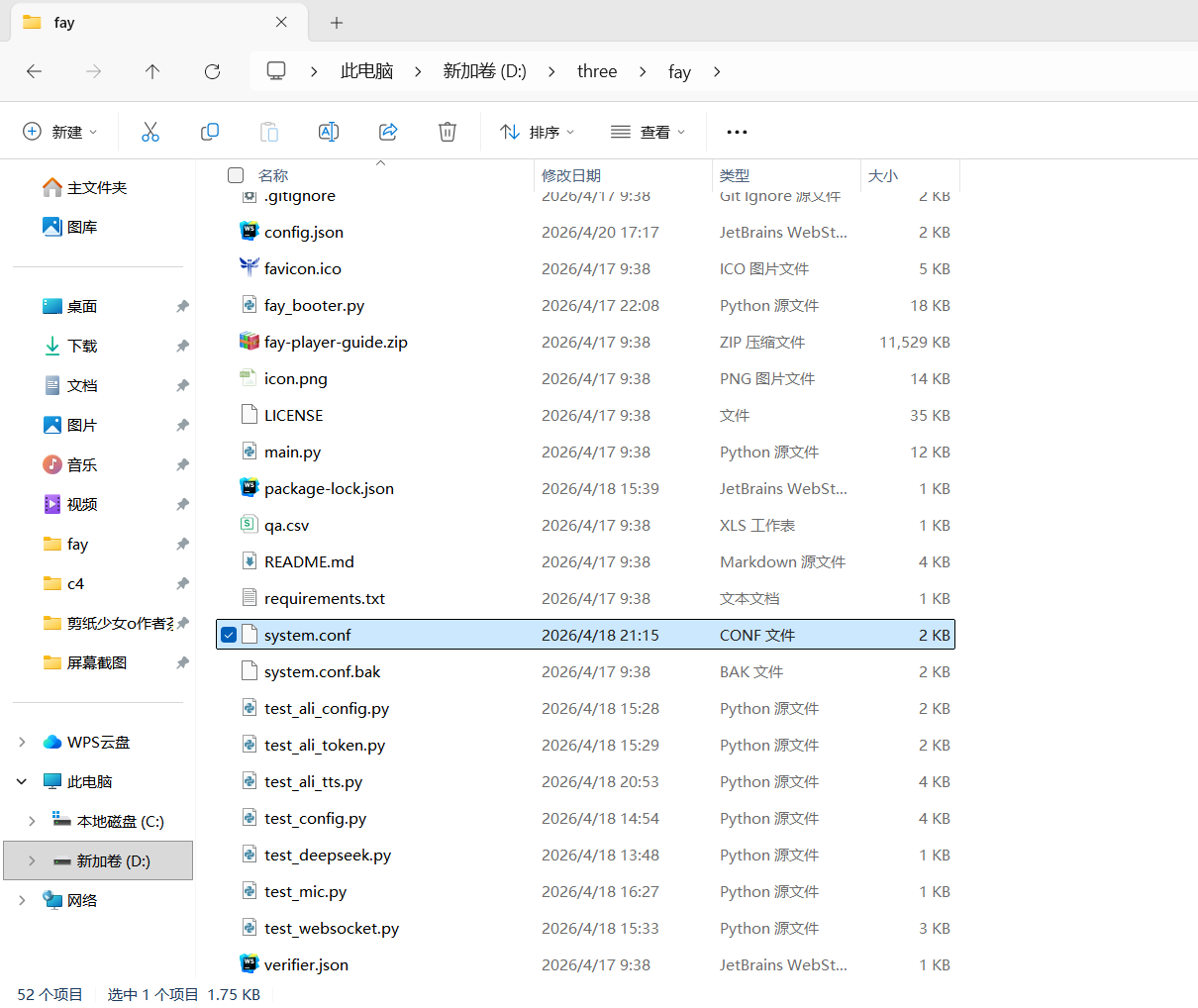
bash
[key]
# ========== 阿里云服务配置 ==========
# ASR(语音识别)
ali_nls_key_id=
ali_nls_key_secret=
ali_nls_app_key=
ASR_mode = ali
# TTS(语音合成)
ali_tss_key_id=
ali_tss_key_secret=
ali_tss_app_key=
tts_module = ali
# ========== LLM 配置(二选一,不要同时保留)==========
gpt_api_url = https://api.deepseek.com/v1
gpt_api_key = sk-
gpt_model_engine = deepseek-chat
gpt_base_url = https://api.deepseek.com
# ========== 其他配置 ==========
proxy_config=
start_mode=common
[asr]
# 语音识别引擎(ali、funasr、whisper、edge)
engine = none
auto_record = true
[llm]
# LLM 引擎(openai、deepseek、ollama)
engine = deepseek
model = deepseek-chat
api_url = https://api.deepseek.com/v1
api_key = sk
temperature = 0.7
llm_json_mode = false
enable_struct_answer = false
enable_emotion_score = false
enable_dialogue_state_lock = false
enable_auto_schedule = false
extract_json_enable = false
prompt = 你是一个亲切自然的AI数字人,正常和用户聊天对话,回复简短口语化,直接回答用户问题,不要输出任何json、不要特殊格式、不要多余符号。
[network]
web_port=10002
human_port=10002
web_control_port=10003
web_enable=true
[tts]
# 语音合成引擎(ali、azure、volcano、edge)
engine = ali
voice = zh-CN-XiaoxiaoNeural
speed = 1.0
#[embedding]
api_key =
api_url =
model =
# 服务器主动地址
fay_url=http://127.0.0.1:5000注意:以上文件是我不停改bug后的最终版本,实际上经历过几十次修改,项目启动过程会遇到各种问题,耐心看控制台报错不断修改调试运行就好。
2.申请api key
我使用的ASR,TTS来自ali,有新手免费额度,申请一下填入system.conf文件中,LLM用的deepseek,这个需要充值,我冲了10元,但是!!!在这个项目里有embedding记忆模块,deepseek接口不支持,所以慎用!
关于申请api,具体流程都有官网介绍,一步步照做就好,就是需要保留好当时页面给的key,否则需要重新生成
https://platform.deepseek.com/api_keys
给出这两个官网链接
3.启动fay
进入fay后台,输入venv\Scripts\activate进入虚拟运行环境,还需要下载各种东西,比如
报错信息:
Traceback (most recent call last): File "D:\three\fay\main.py", line 176, in <module> from PyQt5 import QtGui ModuleNotFoundError: No module named 'PyQt5' 2026-04-17 17:21:54.1系统 程序退出,正在清理资源... 2026-04-17 17:21:54.1系统 正在停止所有线程... 2026-04-17 17:21:54.1系统 所有线程已停止 2026-04-17 17:21:54.1系统 资源清理完成
就是PyQt5 依赖没安装,安装即可
bashpip install pyqt5启动项目
bashpython main.py
4.报错信息与调整
4.1.无法录制语音
在所有问题里,我遇到最棘手的是无法录制语音
2026-04-17 19:20:42,623 INFO connection open 2026-04-17 19:20:42.6系统 websocket连接上:10002 2026-04-17 19:20:43.2User 聆听中... 2026-04-17 19:20:44.5User 语音处理中... 2026-04-17 19:20:44.5User 录音失败: socket is already closed
解决办法
1.修改system.conf文件内容
2.调试每一个部分
我在fay目录下添加了test文件,用于检测每一个部分是否连接成功
(venv) D:\three\fay>python test_deepseek.py ❌ API调用失败,错误原因: Error code: 401 - {'error': {'message': 'Authentication Fails, Your api key: ****4636 is invalid', 'type': 'authentication_error', 'param': None, 'code': 'invalid_request_error'}}这个是因为api无效,需要重新申请一下,一定要试一试重新申请,我当时懒得重新申请找了好久的bug找不到,以为是代码的问题
最后成功了

4.2.无内容输出问题
一直输出抱歉我现在太忙了
解决办法
根据控制台日志不断调整
在检测到错误消息时返回 "GENERATION ERROR" 触发重试机制
python
def gpt_request(...):
# ... API 调用 ...
if content and content.strip().startswith('{'):
data = json.loads(content)
if len(data) == 1 and "Item 1" in data:
content = "你好!我是你的智能助手。"
# 检测错误消息触发重试
if any(word in content for word in ["太忙了", "休息一会"]):
return "GENERATION ERROR"
return content4.3每个部分都调试完但是依旧无法录音识别
音频采样率不匹配,我的麦克风 44100Hz,阿里云 ASR 要求 16000Hz
解决办法:
在 __process_audio_data() 中添加重采样逻辑
python
def __process_audio_data(self, data, channels):
# ... 转单声道 ...
if self.sample_rate == 44100:
step = 44100 / 16000
indices = np.arange(0, len(mono_data), step).astype(int)
indices = indices[indices < len(mono_data)]
mono_data = mono_data[indices]
return mono_data4.4端口不匹配
修改 Fay 后台端口,把 10003 改为 10002
在system.conf里,修改web_port,这样就能与前端数字人human_port保持一致了
bash
[network]
web_port=10002
human_port=10002
web_control_port=10003
web_enable=true以上就是我的经验总结,谢谢观看!